- Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- Re: Перекодировка имен файлов
- проблемы с кодировкой в названии файлов
- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- Перекодировка файлов в Unix
- Перекодировка названий файлов
- Перекодировка содержимого файлов
- Перекодировка содержимого файла в транслит
- Recode и enconv: как перекодировать файлы в UTF-8 из windows-1251, koi-8 и других
- Как перекодировать файлы из/в utf-8, cp1251, koi8 и т. д. рекурсивно в поддиректориях
Перекодировка имен файлов
Подскажите пожалуйста: Distr: SUSE 10 1) подмонтировал FAT32 раздел без указания кодировки 2) скопировал туда с RaiserFS раздела файлы с рус. именами 3) под Windows закарлючки, под Linux если монтировать, не указывая iocharset — нормальные рус. имена, если указать utf-8 — закарлючки.
Использую программу convmv (из FAQ прочитал), какие кодировки указывать, что бы под Windows стало читаемо?

Re: Перекодировка имен файлов
а у тебя системная локаль в SuSE какая?
ко всему прочему, указывать надо, вроде не «utf-8» а «utf8».
попробуй подмонтировать без указания iocharset и сконвертировать потом из utf8 в cp1251.

Re: Перекодировка имен файлов
Основная кодировка кириллицы windows — это CP1251.
Re: Перекодировка имен файлов
В СуСе локаль UTF8. Монтировал не указывая кодировки, тогда в Линуксе читабильно. Пробовал перекодировать из utf8 в cp1251 — винда не читает.
Странно, что если при монтировании указать iocharset=utf8 то в Линуксе не читаемые символы получаются.

Re: Перекодировка имен файлов
> Основная кодировка кириллицы windows — это CP1251.
Не знаешь — не говори. Названия файлов в виндовс — в кодировке cp866
Re: Перекодировка имен файлов
>Названия файлов в виндовс — в кодировке cp866
шоб ты знал — cp866 это кодовая страница для монитора
Re: Перекодировка имен файлов
> шоб ты знал — cp866 это кодовая страница для монитора
Вау. А я думал, что для мыши. Ещё раз прошу: не знаешь — не советуй.

Re: Перекодировка имен файлов
В винде для файлов на FAT и сетевой ФС используется т.н. OEM кодировка. В русской локали это cp866.
Re: Перекодировка имен файлов
ага ср1251 — для мыши, а utf8 — для процессора
Re: Перекодировка имен файлов
>Ещё раз прошу: не знаешь — не советуй.
ну ладно-ладно. Перекурил седня:) чо сразу злиЦЦо то?:)
Re: Перекодировка имен файлов
Смонтируй без ничего, скопируй файлы к себе, смонтируй с iocharset=utf8,codepage=866, скопируй обратно.
Или попробуй входную utf8, выходную cp866.
Re: Перекодировка имен файлов
Ага, так и сделал. Смонтировал без ничего, скопировал к себе на др. раздел. Подмонтировал с iocharset=utf8 и обратно залил. Все исправислос.
Источник
проблемы с кодировкой в названии файлов
Перенес файлы с одного сервера на другой. Некоторые символы в названиях файлов стали отображаться как квадраты, например «№». Причем с этими файлами нельзя ничего сделать через файлменеджер, ни удалить, ни переименовать, т.к. пишет что файл не сущетвует (а его видно).
Вопрос в том, что сделать, чтобы названии таких файлов корректно отображались все символы?

Можно сделать по номеру inode через find. Вменяемого решения проблемы в целом не могу сказать, не ясно что там приключилось в процессе переноса — как переносили файлы, какая ОС\локали там и там?

Включить однобайтную локаль. Например, KOI8-R. Тогда отдельные байты распарсятся без ошибок. Хоть и смысла в итоговых именах может быть никакого. Но, зато с файлами можно будет легко проводить операции — переименовывать, удалять. и т.д.
Переносил rsync, с ubuntu 12.04 (cp1251) на ubuntu 14.04(utf8). С локального компьютера, где стоит ubuntu 14.04, подключаюсь через файловый менеджер к старому серверу и тоже вижу квадраты. Т.е. проблема возникла не во время переноса
подскажите, пожалуйста, что для этого нужно)
Если имена файлов уже в cp1251, то выставить лучше cp1251. Для этого надо выполнить
После этого, кстати, можно будет пройтись по файлам скриптом, автоматически переименовывая их в UTF-8. Например, таким:
/cp1251toutf8. Тогда можно просто перейти в директорию с файлами и выполнить
После переименования можно будет вернуть обратно UTF-8.
не хотелось бы выставлять cp1251. в названии файлов, думаю кириллицы нет, только с символами типа «№» проблемы почему то(
rsync не меняет кодировку имен файлов, как записано, так и сохраняет. Вот и остались в однобайтной CP1251. Для перекодирования можно использовать утилиту convmv:
Потому, что этих символов нет в ASCII. Соответственно, для однобайтной cp1251 их коды больше чем 127. Что для парсера юникода включает _последовательности_ из ряда байтов. При этом, поскольку, эти байты никто не подбирал, чтобы они создавали корректные для UTF-8 последовательности, местами получаются невалидные для UTF-8 последовательности (да, в UTF-8 есть такое). И парсеры юникода ломаются.
Для парсеров же однобайтных кодировок любые последовательности байт валидны, поскольку каждый отдельный байт воспринимается как отдельный указатель на один из 256-ти символов.
юзал без ключа «—notest», сам затупил. Очень много нервных клеток вы мне съэкономили)
Источник
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
Для того, чтобы вывести список всех доступных опций, введите:
Конвертирование файлов из UTF-8 в ASCII
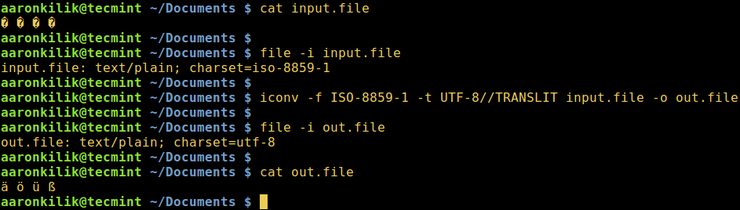
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
Перекодировка файлов в Unix
 Иногда, я бы даже сказал достаточно часто приходится заниматься перекодировкой файлов или названий файлов в ОС Unix. Хорошо когда у вас есть графический интерфейс и редактор типа kate, который позволяет без проблем конвертировать кодировки файлов. А если надо перекодировать название файлов? Или перекодировать само содержание файлов без графического интерфейса? Тут уже в помощь приходят команды Unix. И поверьте, набрать команду в консоле намного быстрее чем запускать какие-то редакторы кодировок и графические перекодировщики. А если для наиболее популярных перекодировок файлов написать исполняемые файлы с названием типа win2utf, то жизнь за консолью вам покажется очень простой 🙂
Иногда, я бы даже сказал достаточно часто приходится заниматься перекодировкой файлов или названий файлов в ОС Unix. Хорошо когда у вас есть графический интерфейс и редактор типа kate, который позволяет без проблем конвертировать кодировки файлов. А если надо перекодировать название файлов? Или перекодировать само содержание файлов без графического интерфейса? Тут уже в помощь приходят команды Unix. И поверьте, набрать команду в консоле намного быстрее чем запускать какие-то редакторы кодировок и графические перекодировщики. А если для наиболее популярных перекодировок файлов написать исполняемые файлы с названием типа win2utf, то жизнь за консолью вам покажется очень простой 🙂
Перекодировка названий файлов
В данном примере приведу перекодировку из UTF8 в KOI8-R.
Скачиваем и устанавливаем программу convmv. Если в вашем репозитории данного пакета не обнаружилось, то скачать исходники можно отсюда.
Переходим в каталог, где нам надо изменить название файлов и вводим команду
Смотрим что получилось:
Если после выполнения команды можно прочесть название файлов, тогда делаем окончательную перекодировку, добавляя в конец команды “–notest”. Сделано это для того чтобы пользователь еще больше не закодировал итак непонятные символы. А вдруг вы ошиблись в исходной или конечной кодировке?
Теперь команда будет выглядеть
Если надо перекодировать рекурсивно каталоги, то добавляем в строку ключик -r и тогда можно за один проход перекодировать всю директорию с вложенными папками и подпапками. Остальные ключи программы можно посмотреть через команду
Перекодировка содержимого файлов
Чтобы не использовать графические редакторы можно использовать консольную программу перекодировщик, например такую как recode. Я считаю, что данная программа имеет очень логичный интерфейс и достаточно хорошо справляется с возложенной на нее задачей. Сначала установим программу recode, т.к. данная программа не входит в обязательный набор программ многих дистрибутивов.
Вот пример перекодировки файла из кодировки windows 1251 в utf8.
Опасность действий с recode поджидает тех, кто невнимателен, т.к. содержимое файла изменяется сразу же после команды. Заранее делайте копию перекодируемого файла, или делайте обратную перекодировку в том случае если ошиблись.
Также для перекодировки содержимого файла можно использовать команду iconv. Синтаксис данной команды немного посложнее. Пример перекодировки из windows 1251 в utf8.
Обратите внимание на то, что в команде recode надо использовалась указание кодировки windows1251 слитно, а в iconv надо писать через дефис.
Преимущество команды iconv в том, что она есть почти в каждом дистрибутиве unix и возможность создать новый выходной файл.
Ну и напоследок приведу пример скрипта, с помощью которого можно перекодировать название файлов из koi8r в utf8 с помощью recode.
Перекодировка содержимого файла в транслит
Инсталлируем пакет yudit. Из всего пакета нам потребуется только утилита uniconv. Данная утилита имеет не совсем привычный синтаксис, но вполне подойдет для наших целей если задействовать вокруг неё команды unix
На выходе получаем файл с латиницей, а входной файл был в кодировке KOI8-R.
Многие действия команд convmv, recode, iconv и uniconv имеют много общего и фактически делают одно и то же. Так что используйте их в зависимости от вашего настроения и ситуации. И не забывайте про составление скриптов из этих команд.
Источник
Recode и enconv: как перекодировать файлы в UTF-8 из windows-1251, koi-8 и других
В общем случае, перекодировать можно в любом направлении, не обязательно именно в utf-8. Можно перекодировать между кириллическими кодировками, например, из koi-8 в cp1251, из utf-8 в koi-8, из utf-8 в cp1251 и обратно. Также рассмотрим ситуацию когда нужно изменить кодировку файлов не только в текущей директории, но и во вложенных.
В Linux перекодировку файлов удобно делать утилитами recode или enconv. Есть и другие перекодировщики, но про них пусть кто-то другой напишет.
Для использования enconv нужно установить пакет enca:
Обе команды — recode и enconv — имеют кучу возможных опций, в простейших случаях для перекодирования одного или нескольких файлов в одной директории использование такое:
На что следует обратить внимание: для команды recode надо указать направление перекодировки (как минимум, исходную кодировку, в примере это cp1251; если не указана конечная кодировка, то программа заглянет в переменные окружения LC_ALL, LC_CTYPE, LANG). Для enconv указывать направление перекодировки необязательно вообще: программа способна определить исходную кодировку, проанализировав текст файла, а конечная кодировка будет взята из переменных окружения.
То есть, если надо перекодировать файлы в вашу «обычную» кодировку, используемую в системе, примеры могут выглядеть так:
Для того, чтобы программа enconv точнее могла определить исходную кодировку файла, ей можно помочь, подсказав, на каком языке написан текст в файле. В нашем примере указан русский язык: «-L russian».
Список языков, известных программе, можно посмотреть так:
enca — это не опечатка. Программа enconv является частью пакета enca.
Как перекодировать файлы из/в utf-8, cp1251, koi8 и т. д. рекурсивно в поддиректориях
Для рекурсивного изменения кодировки файлов надо привлечь команду find, затем перекодировать то, что она нашла.
Среди множества опций команды find имеется набор для выполнения действий над найденными файлами. Нас интересует опция «-exec command <> ;».
command — команда, которую надо выполнить для каждого найденного файла;
<> — вместо скобок будет подставлено имя файла, найденного командой find;
; — точка с запятой указывает для команды find, в каком месте заканчиваются параметры команды command.
Надо иметь в виду, что «<>» и «;» может понадобиться экранировать с помощью одинарных кавычек или «\», чтобы предотвратить интерпретацию командной оболочкой (shell expansion).
Собираем всё вместе. Чтобы перекодировать из cp1251 (windows-1251) в utf-8 рекурсивно в поддиректориях все файлы, имена которых заканчиваются на ‘.txt’, надо выполнить:
Источник



