- COREUTILS. Команда uniq. Вывод уникального содержимого
- Использование команды uniq в Linux (10 примеров)
- Утилита uniq в Linux
- 1. Удаление повторяющихся строк из вывода
- 2. Вывод информации о количестве дубликатов каждой из строк
- 3. Вывод лишь повторяющихся строк
- 4. Пропуск начальных фрагментов строк
- 5. Вывод всех строк с разделением групп повторяющихся строк
- 6. Вывод лишь не повторяющихся строк
- 7. Пропуск заданного количества символов в начале строк
- 8. Указание количества символов для сравнения
- 9. Сравнение строк без учета регистра
- 10. Использование завершающего нулевого символа вместо символа перехода на новую строку
- Заключение
- Команда uniq Linux
- Синтаксис uniq
- Опции uniq
- Примеры использования uniq
- Выводы
COREUTILS. Команда uniq. Вывод уникального содержимого
Общий синтаксис программы uniq в linux предельно простой:
unic [OPTIONS] [INPUT [OUTPUT]]
Тоесть, чтобы вывести уникальные строки, например в тестовом файле my_text_file, нужно команде uniq передать его имя в качестве аргумента
Нельзя, разумеется, забывать, что вы должны находится именно в той дирректории, где и лежит файл my_text_file. Иначе uniq необходимо передать полный путь до файла в linux:
Неуникальные строки можно посчитать. Для этого передайте quic в качестве опции ключ «-c».
unic -c /home/user/my_text_file
В выводе вы получите таблицу из 2-х колонок, в первой будет указано количество повторяющихся строк, во второй их значение.
В linux uniq также можно попросить печатать только те строки, которые имеют дубликаты, для этого нужно использовать ключ «-d»:
uniq -d /home/user/my_text_file
Опции можно комбинировать, и чтобы посчитать только строки которые имеют дубликаты, следует ввести такую команду:
uniq -d -с /home/user/my_text_file
В противовес ключу «-d» есть ключ «-u», заставляющий uniq выводить только строки, не имеющие дубликата:
uniq -u /home/user/my_text_file
Однако, как мы и освещали в вводой части, uniq работает только последовательно, следовательно строки, содержащиеся в файле, например:
не будут считаться уникальными. Чтобы разрешить эту проблему можно использовать в linux команду uniq совместно с командой sort, перенаправляя вывод одной команды на ввод другой:
sort -n my_text_file | uniq
или же просто использовать sort с ключом «-u»
sort -n -u my_text_file
Возможности и примеры использования утилиты sort мы уже освещали в статье COREUTILS. Команда sort. Сортировка вывода программ
Источник
Использование команды uniq в Linux (10 примеров)
Оригинал: Linux Uniq Command Tutorial for Beginners (10 examples)
Автор: Himanshu Arora
Дата публикации: 23 мая 2017 г.
Перевод: А.Панин
Дата перевода: 24 мая 2017 г.
Если вы являетесь пользователем интерфейса командной строки Linux и ваша работа связана с редактированием текстовых файлов, вы должны знать (если уже не знаете) о существовании огромного количества утилит с интерфейсом командной строки, которые могут помочь вам в различных ситуациях. Например, одной из таких утилит является утилита uniq , выводящая или удаляющая из вывода повторяющиеся строки, находящиеся в текстовом файле.
В данной статье мы будем обсуждать методику использования утилиты uniq на основе простых для понимания примеров. Но перед тем, как приступить к рассмотрению примеров стоит упомянуть о том, что все примеры и инструкции из данной статьи были протестированы в системе Ubuntu 16.04 LTS.
Утилита uniq в Linux
Как уже говорилось ранее, утилита uniq осуществляет вывод или удаление из вывода повторяющихся строк. А это синтаксис соответствующей команды:
А это описание функций утилиты с ее страницы руководства: «Утилита осуществляет фильтрацию идентичных строк из ВХОДНОГО ФАЙЛА (или из стандартного потока ввода) и выводит информацию в ВЫХОДНОЙ ФАЙЛ (или стандартный поток вывода). При вызове без параметров идентичные строки объединяются в рамках первых найденных экземпляров строк.»
Ниже приведен ряд примеров, которые помогут вам лучше понять принцип работы рассматриваемой утилиты.
1. Удаление повторяющихся строк из вывода
Предположим, что в нашем распоряжении имеется файл со следующими строками:
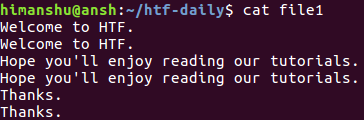
Несложно заметить, что каждая из строк повторяется. Теперь применим утилиту uniq по отношению к этому файлу и посмотрим, к чему это приведет.

Очевидно, что вывод не содержит дубликатов строк. Обратите внимание на то, что содержимое оригинального файла с именем file1 в нашем случае осталось неизменным. Вы можете перенаправить вывод утилиты в другой файл в том случае, если вам нужно сохранить вывод для дальнейшей обработки.
2. Вывод информации о количестве дубликатов каждой из строк
Если вам нужно, вы можете использовать утилиту uniq для вывода информации о количестве повторений каждой из строк файла. Это может быть сделано с помощью параметра командной строки -c . Например, команда
будет генерировать следующий вывод:

Несложно заметить, что перед каждой из строк выводится число, соответствующее количеству ее повторений.
3. Вывод лишь повторяющихся строк
Для того, чтобы утилита uniq выводила лишь повторяющиеся строки, следует использовать параметр -D командной строки. Например, предположим, что файл с именем файл file1 теперь содержит дополнительную строку в конце (обратите внимание на то, что эта строка не повторяется).
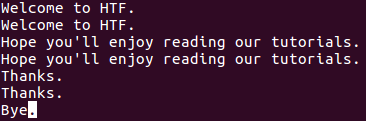
Теперь при исполнении команды
будет генерироваться следующий вывод:
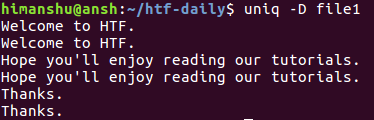
Как вы видите, параметр -D сообщает утилите uniq о необходимости вывода всех повторяющихся строк, включая их повторы. Для лучшей читаемости вы можете активировать режим вывода пустой строки после каждой из групп повторяющихся строк с помощью параметра —all-repeated .
Данный параметр требует от пользователя обязательного указания метода добавления разделителя. Строки могут добавляться к разделителю (то есть, пустой строке) с помощью метода prepend или разделяться с помощью него с помощью метода append . Например, в данном случае используется метод prepend .
![]()
Более того, если вам нужно, чтобы утилита выводила лишь по одному экземпляру каждой из повторяющихся строк, вы можете воспользоваться параметром -d . Это пример его использования:

Очевидно, что в выводе приводится лишь по одному экземпляру строки из каждой группы.
4. Пропуск начальных фрагментов строк
Иногда, в зависимости от ситуации, совпадение двух строк может быть установлено по совпадению определенных частей этих строк. Например, рассмотрим следующий файл:
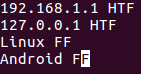
Теперь предположим, что строки должны считаться совпадающими или не совпадающими на основании совпадения или несовпадения их вторых полей (то есть HTF или FF) и вам нужно сделать так, чтобы утилита uniq использовала такой же критерий сравнения, чего несложно добиться с помощью параметра командной строки -f .
Параметр -f требует от вас обязательной передачи числа, которое соответствует количеству полей, которые нужно пропустить. Например, в нашем случае мы передаем в качестве значения параметр -f значение 1, так как мы хотим, чтобы утилита uniq пропустила лишь первое поле:

Из вывода очевидно, что утилита uniq посчитала первую и третью строку повторяющимися исключительно на основе их вторых полей.
5. Вывод всех строк с разделением групп повторяющихся строк
При необходимости вывода всех строк с разделением групп повторяющихся строк с помощью пустой строки вы можете использовать параметр —group . Как и в случае описанного выше параметра —all-repeated , параметр —groups требует от пользователя обязательного указания позиции пустой строки ( prepend , append или both ).
Это пример использования рассматриваемого параметра:
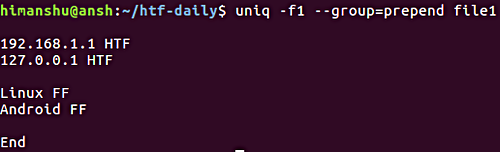
Обратите внимание на параметр -f , который обсуждался в предыдущем разделе.
6. Вывод лишь не повторяющихся строк
Вы уже наверняка поняли, что утилита uniq по умолчанию выводит лишь повторяющиеся строки. Но если вам нужно, вы можете сообщить ей о необходимости вывода лишь не повторяющихся или уникальных строк. Это делается с помощью параметра командной строки -u .
В нашем случае команда будет выглядеть следующим образом:
Это пример ее использования:

Обратите внимание на параметр -f , который обсуждался в разделе 4.
7. Пропуск заданного количества символов в начале строк
В одном из предыдущих разделов мы обсуждали методику пропуска полей строк при использовании утилиты uniq. Однако, при необходимости вы можете сообщить утилите о необходимости пропуска не начальных полей, а начальных символов строк. Для доступа к соответствующей функции может использоваться параметр командной строки -s .
Например, предположим, что наш файл содержит следующие строки:
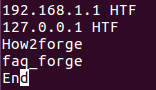
Теперь, если вы захотите, чтобы uniq пропустила первые 4 символа каждой строки перед их сравнением, вы сможете воспользоваться следующей командой:
А это приведенная выше команда в действии:
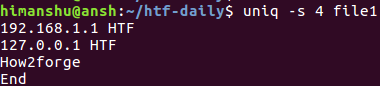
Несложно заметить, что четвертая строка (faq_forge) из оригинального файла была пропущена. Это объясняется тем, что после пропуска первых четырех символов третья и четвертая строки становятся идентичными для утилиты uniq и она выводит лишь первую из них.
8. Указание количества символов для сравнения
По аналогии с пропуском символов, вы можете сообщить утилите uniq о необходимости сравнения лишь заданного количества символов строк. Для этой цели вам придется использовать параметр командной строки -w .
Например, предположим, что файл содержит следующие строки:
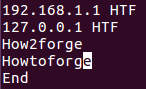
Теперь при необходимости ограничения диапазона символов строк для сравнения тремя первыми символами, может использоваться следующая команда:
Это приведенная выше команда в действии:
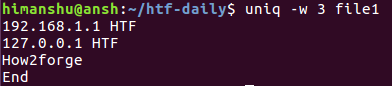
Так как первые три символа третьей и четвертой строк совпадают, эти строки считаются утилитой идентичными. По этой причине в выводе находится лишь третья строка.
9. Сравнение строк без учета регистра
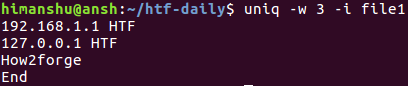
По умолчанию утилита uniq осуществляет сравнение строк с учетом регистра символов. Однако, вы можете активировать режим сравнения строк без учета регистра символов с помощью параметра командной строки -i .
Например, предположим, что мы будем использовать файл с содержимым, аналогичным рассмотренному в предыдущем разделе, но теперь четвертая строка будет начинаться с символов H, O и W в верхнем регистре.
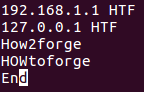
Теперь, если вы попытаетесь выполнить рассмотренную в предыдущем разделе команду, вы получите отличный вывод:
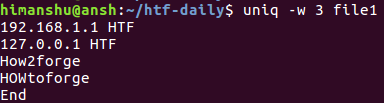
Это объясняется тем, что первые три символа третьей и четвертой строк отличны для утилиты uniq ввиду их регистра. В подобных ситуациях вы можете активировать режим сравнения строк без учета регистра с помощью параметра командной строки -i .
10. Использование завершающего нулевого символа вместо символа перехода на новую строку
По умолчанию утилита uniq генерирует вывод с завершающим символом перехода на новую строку. Однако, при необходимости вы можете активировать режим использования завершающего нулевого символа (полезный при вызове uniq из сценариев). Для этого следует использовать параметр командной строки -z :
Заключение
Мы рассмотрели практически все поддерживаемые утилитой uniq параметры командной строки, поэтому вам остается лишь самостоятельно испытать их в работе для того, чтобы лучше понять их принцип работы и функции. И как обычно, в случае каких-либо сомнений и вопросов следует обращаться к странице руководства утилиты .
Источник
Команда uniq Linux
Команда uniq предназначена для поиска одинаковых строк в массивах текста. При этом с найденными совпадениями пользователь может совершать множество действий — например, удалять их из вывода либо наоборот, выводить только их.
Работа команды осуществляется как с текстовыми файлами (в том числе, записями скриптов), так и с текстом, напечатанным в командной строке терминала.
Синтаксис uniq
Запись команды осуществляется следующим образом:
$ uniq опции файл_источник файл_для_записи
Файл источник указывает откуда надо читать данные, а файл для записи — куда писать результат. Но их указывать не обязательно. В примерах мы будем набирать текст, который нуждается в редактировании, прямо в командную строку терминала, воспользовавшись ещё одной командой — echo, и применив к ней опцию -e. Это будет выглядеть так:
echo -e [текст, слова в котором разделены управляющей последовательностью\\n] | uniq
Эта управляющая последовательность нужна, чтобы указать утилите, что каждое слово выводится в новой строке. Если указано только название файла источника, результат выполнения команды появится прямо в окне терминала. А при наличии выходного файла текст будет напечатан в теле документа.
Опции uniq
У команды uniq есть такие основные опции:
- -u (—unique) — выводит исключительно те строки, у которых нет повторов.
- -d (—repeated) — если какая-либо строка повторяется несколько раз, она будет выведена лишь единожды.
- -D — выводит только повторяющиеся строки.
- —all-repeated[=МЕТОД] — то же самое, что и -D, но при использовании этой опции между группами из одинаковых строк при выводе будет отображаться пустая строка. [=МЕТОД] может иметь одно из трех значений — none (применяется по умолчанию), separate или prepend.
- —group[=МЕТОД] — выводит весь текст, при этом разделяя группы строк пустой строкой. [=МЕТОД] имеет значения separate (по умолчанию), prepend, append и both, среди которых нужно выбрать одно.
Вместе с основными опциями могут применяться дополнительные. Они нужны для более тонких настроек работы команды:
- -f (—skip-fields=N) — будет проведено сравнение полей, начиная с номера, который следует после указанного вместо буквы N. Поля — это слова, хотя, называть их словами в прямом смысле слова нельзя, ведь словом команда считает любую последовательность символов, отделенную от других последовательностей пробелом либо табуляцией.
- -i (—ignore-case) — при сравнении не будет иметь значение регистр, в котором напечатаны символы (строчные и заглавные буквы).
- -s (—skip-chars=N) — работает по аналогии с -f, однако, игнорирует определенное количество символов, а не строк.
- -c (—count) — в начале каждой строки выводит число, которое обозначает количество повторов.
- -z (—zero-terminated) — вместо символа новой строки при выводе будет использован разделитель строк NULL.
- -w (—check-chars=N) — указание на то, что нужно сравнивать только первые N символов в строках.
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq

После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -c

Теперь применим команду к тексту, который находится в файле.
uniq —all-repeated=prepend text-example.txt

Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.

Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.
echo -e небо исполосовано молниями\\nоблака на небе\\nоблака разогнал ветер\\nоблака закрыли солнце\\nсолнце светит ярко\\nзвезды кажутся огромными | uniq -w5

Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -u

Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».
echo -e небо\\nоблака перистые\\nоблака перистые\\nоблака белые\\nсолнце\\nзвезды | uniq —skip-chars=6

А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq —group=both

Тогда как append не добавило пустую строку перед текстом:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq —group=append

Выводы
Команда uniq linux пригодится тем, кто часто и много работает с массивами текста, не имея возможности вычитывать их самостоятельно. Следует заметить, что не все версии uniq работают исправно, поэтому иногда результат выдачи может отличаться от ожидаемого.
Свои вопросы относительно использования команды, а также замечания и пожелания оставляйте в комментариях.
Источник



