- Отображение всех символов ascii в консоли linux (сборка NASM)
- [прошу сильно не бить] Как grep’ом найти символы второй половины таблицы ASCII?
- Ну я и кретин!
- Фигвам!
- 12.5. Консольные редакторы ASCII-файлов
- Читайте также
- Пример: преобразование символов из ASCII в Unicode
- Преобразование символов из кодировки ASCII в Unicode
- 12.6. Редакторы ASCII-файлов для графического режима
- 13.5.1 Терминалы ASCII
- 14.5.2 Пересылка текста ASCII
- Глава 20 Консольные инструменты управления пакетами
- Консольные фронэнды
- 2.15. Преобразование символов в коды ASCII и обратно
- 4.2. Кодировки в пост-ASCII мире
- Консольные команды Windows XP (восстановление реестра)
- Как найти таблицу ASCII в Linux —
- Способ 1: из терминала
- Способ 2: с помощью инструмента графических страниц справочника
- Способ 3: с помощью сценария оболочки
- Способ 4: с помощью текстового файла
- Способ 5: с помощью команды showkey
Отображение всех символов ascii в консоли linux (сборка NASM)
Я прочитал учебник по nasm, и есть пример кода, который отображает весь набор символов ascii. Я понимаю почти все, кроме того, почему мы нажимаем ecx и popping ecx, поскольку я не вижу, как это относится к остальной части кода. Ecx имеет значение 256, так как мы хотим все символы, но не знаем, где и как его использовать. Что именно происходит, когда мы нажимаем и поп-экк? Почему мы перемещаем адрес ачара в dx? Я не вижу, чтобы мы использовали dx для чего-либо. Я понимаю, что нам нужно увеличить адрес ачара, но я запутался, как приращение относится к ecx и dx. Я был бы признателен за понимание.
Хорошо, тогда вы скорее опережаете меня. (хотя из ваших дальнейших комментариев вы узнаете о других нечувствительных вещах в этом коде:)).
почему мы нажимаем ecx и popping ecx, поскольку я не вижу, как это относится к остальной части кода. Ecx имеет значение 256, так как мы хотим все символы, но не знаем, где и как его использовать.
Используется LOOP (это не очень хорошая идея: Почему это медленная инструкция цикла?), она уменьшится ecx и скачком, когда значение окажется выше нуля, т.е. механизм цикла обратного отсчета.
Поскольку для вызова службы int 0x80 требуется ecx для значения адреса памяти, счетчик сохраняется/восстанавливается с помощью push / pop . Более эффективный способ заключается в том, чтобы поместить значение счетчика в некоторый запасной регистр, например, esi , и сделать dec esi jnz next . Еще более эффективный способ состоял бы в том, чтобы повторно использовать значение символа, если выход начнется с нулевого значения, а не с нулевой цифрой, тогда флаг нуля после inc byte [achar] можно использовать для обнаружения условия цикла.
Мне непонятно, почему «отображать все символы ASCII» начинается с цифры 0 (значение 48 ), кажется мне странным, я начинаю с нуля. Но у этого есть еще одно предостережение, linux console I/O encoding устанавливается средой, а в любой общей установке Linux это UTF8 в настоящее время, поэтому допустимые печатные однобайтовые символы имеют значения только 32-126 (которые идентичны обычным 7 битной кодировкой ASCII, что делает эту часть примера хорошо работать), а значения 0-31 и 127 являются непечатаемыми управляющими символами, также идентичными общему кодированию ASCII 7b. Значения 128-255 указывают в многобайтовом символе с кодировкой UTF8 (пример: ř — это два байта 0xC5 0x99 ), а в виде одиночных байтов они являются недопустимой последовательностью байтов, поскольку отсутствует оставшаяся часть байтов «кодовой точки UTF8».
В эпоху DOS вы могли написать код, записывающий прямо в видеопамять VGA в текстовом режиме, все 8-битные значения, идущие от нуля до 255, и каждый отличное графическое представление, вы можете указать в пользовательском шрифте VGA или известную кодовую страницу для определенных символов, это также иногда называют расширенным ASCII, но общая установка DOS отличалась от ссылки в вашей комментарии, имеющие еще много символов рисования. Это включало в себя управляющие символы \r и \n , которые для VGA — это еще один символ глифа, а не строковые и новые строки управления (это значение создается вызовом службы BIOS/DOS, который вместо вывода \n символ переместит внутренний курсор на следующую строку и отбросит вывод char).
Невозможно воссоздать это с помощью linux console I/O (если шрифт UTF8 не содержит всех странных DOS-глифов, и вы будете выводить их правильную кодировку UTF8 вместо одиночных байтов).
Заключение заключается в том, что пример начинается со значения ‘0’ ( 48 ) и до значения 126 выводит правильные печатные символы ASCII, после 126 выводит «что-то», и поскольку эти байты будут иногда формируют недействительные кодировки UTF8, я бы технически назвал это «фиктивным» выходом с поведением undefined, вы можете получить, вероятно, разные результаты для разных версий Linux и настроек консоли.
Также уведомление в стиле NASM: поместите двоеточие после ярлыков, т.е. achar: db ‘0’ , что спасет вас, если вы случайно используете меткометы команд, например loop: или dec: db ‘d’ .
dx больше не используется, поэтому это бесполезная инструкция.
Флаги из этого сравнения также не используются никоим образом, поэтому это тоже бесполезно.
Итак, скорректированный пример может выглядеть так:
Но было бы разумнее сначала подготовить весь вывод в памяти и вывести его за один раз, как этот:
Все примеры были проверены с помощью nasm 2.11.08 на 64b linux (дистрибутив KDE neon на основе Ubuntu 16.04) и построены командами:
Источник
[прошу сильно не бить] Как grep’ом найти символы второй половины таблицы ASCII?
Сижу сейчас, перевожу все комментарии в своем велосипеде на английский («по многочисленным просьбам»). Хочу найти, может, где пропустил чего.
grep [^[:alnum:]] считает русские буквы символами.
grep [а-яА-Я] не работает (т.к. буквы, все-таки, не по алфавиту в таблице — КОИ8-Р у меня).


> КОИ8-Р у меня
Допрыгался, курилка. Говорили тебе — кои8 до добра не доведёт.
Ну не 866 или 1251 же держать!

Прошу не разводить срачи вокруг совершенно ненужного для русского человека юникода, а ответить по существу.
Ну я и кретин!
Все решается элементарно:
Фигвам!
Оно так еще кучу мусора выдает

> ненужного для русского человека юникода
Ага. Только с ним этого топика бы не было.
дело только в том, что юникод, общепринятый международный стандарт, и все, кто еще хоть как-то шевелится, на него переезжают.
Причем utf-8 даже не требует дополнительных байтиков, при использовании наиболее распространенного в компьютерном мире, английского языка.

Enjoy your koi8-r… В этом говне ещё русские буквы не по порядку.
Источник
12.5. Консольные редакторы ASCII-файлов
12.5. Консольные редакторы ASCII-файлов
Начнем с рассмотрения редакторов текстового режима, т. е. работающих в консоли. Говоря о таких редакторах просто нельзя не упомянуть о редакторах vi и Emacs, но более основательно будет рассмотрен встроенный редактор оболочки Midnight Commander — Cooledit.
Читайте также
Пример: преобразование символов из ASCII в Unicode
Пример: преобразование символов из ASCII в Unicode Программа 2.4 достраивает программу 1.3, в которой использовалась вспомогательная функция CopyFile. С копированием файлов вы уже знакомы, поэтому в данном примере эта операция дополняется преобразованием файла к кодировке Unicode в
Преобразование символов из кодировки ASCII в Unicode
Преобразование символов из кодировки ASCII в Unicode Измерения выполнялись для восьми программ, каждая из которых преобразовывала файл размером 12,8 Мбайт в файл размером 25,6 Мбайт. Соответствующие результаты представлены в табл. В.2.1. Программа atou (программа 2.4) сопоставима с
12.6. Редакторы ASCII-файлов для графического режима
12.6. Редакторы ASCII-файлов для графического режима Очевидно, что было бы очень удобно, если бы редактирование ASCII-файлов в графическом режиме осуществлялось с помощью тех же редакторов, которые применяются в консольном режиме. Тогда не пришлось бы заучивать другие
13.5.1 Терминалы ASCII
13.5.1 Терминалы ASCII Терминалы ASCII используются с Unix и компьютерами VAX компании Digital Equipment Corporation. Эти терминалы обеспечивают:? Удаленную эхо-печать (remote echoing) каждого символа. Т.е. каждый посланный удаленному хосту символ возвращается назад, до того как будет отображен на
14.5.2 Пересылка текста ASCII
14.5.2 Пересылка текста ASCII Хотя текст ASCII является стандартным, компьютеры интерпретируют его по-разному из-за различия в кодах конца строки. Системы Unix используют для этого , компьютеры PC — , a Macintosh — .Для устранения этих различий FTP превращает
Глава 20 Консольные инструменты управления пакетами
Глава 20 Консольные инструменты управления пакетами Считается, и вполне оправданно, что набрать одну команду в терминале сильно проще, чем кликать мышкой по GUI инструментам. Кроме того, основой Linux всё-таки является терминал. Поэтому я никак не могу обойти описание работы с
Консольные фронэнды
Консольные фронэнды Из консольных утилит в первую очередь выделим mp3c (рис. 3.41), которую можно найти на сайте проекта http://mp3c.wspse.de/ или установить пакет из репозитария Ubuntu. Рис. 3.41. Программа mp3cВ последних версиях для кодирования mp3c использует кодек lame (ранее mp3enc); пакет,
2.15. Преобразование символов в коды ASCII и обратно
2.15. Преобразование символов в коды ASCII и обратно В Ruby символ представляется целым числом. Это поведение изменится в версии 2.0, а возможно и раньше. В будущем предполагается хранить символы в виде односимвольных строк.str = «Martin»print str[0] # 77Если в конец строки дописывается
4.2. Кодировки в пост-ASCII мире
4.2. Кодировки в пост-ASCII мире «Век ASCII» прошел, хотя не все еще осознали этот факт. Многие допущения, которые программисты делали в прошлом, уже несправедливы. Нам необходимо новое мышление.Есть две идеи, которые, на мой взгляд, являются основополагающими, почти аксиомами.
Консольные команды Windows XP (восстановление реестра)
Консольные команды Windows XP (восстановление реестра) Этой статьей мы продолжаем серию консольных команд, в которой понимаем под консольной командой также консольные утилиты. В данной части рассмотрим восстановление системы в практических случаях и их решением, примерами.
Источник
Как найти таблицу ASCII в Linux —
Если вы разрабатываете приложения для смартфонов или являетесь веб-разработчиком, может настать время, когда вам понадобится дополнительная информация о том, как приложения взаимодействуют с отдельными персонажами. Хотя мы рассматриваем символы как буквы, цифры и символы, базовый системный код видит их только как последовательность числовых значений. Программирование приложения или создание веб-страницы может быть проще, если вы знаете конкретные числовые значения, которые сопоставлены с различными символами. Эти числовые значения более или менее независимы от платформы, поэтому, если вы создаете свой собственный код для Linux для использования на другой платформе, знание этих значений внутри Linux все еще стоит.
Linux имеет ряд встроенных программных инструментов для решения подобных проблем, но они в значительной степени скрыты от современных пользователей. Эта технология все еще весьма полезна, особенно в мире, который требует все большего развития мобильных платформ. После того, как вы узнаете хитрости доступа к этой информации, вы обнаружите, что это намного быстрее, чем искать ее в Интернете или искать настоящее руководство по программированию.
Способ 1: из терминала
Если вы уже находитесь в среде CLI Linux, работающей из оболочки Bash, то вы можете использовать встроенное Руководство программиста Linux, не пропуская ритм. В командной строке Bash введите команду man ascii и нажмите клавишу ввода. Вас встретит техническое определение того, что такое ASCII, а затем таблица из 128 символов, которые составляют надлежащий стандарт ASCII.
Скорее всего, вы привыкли искать страницы справочника по командам с помощью команды CLI man, но вы, возможно, не так привыкли к встроенному Руководству для программиста Linux. Многие страницы руководства, на которые иначе не могли бы ссылаться имена команд, могут быть доступны таким же образом.
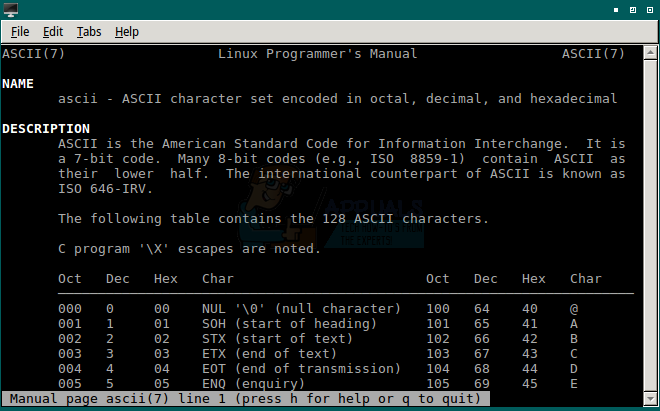
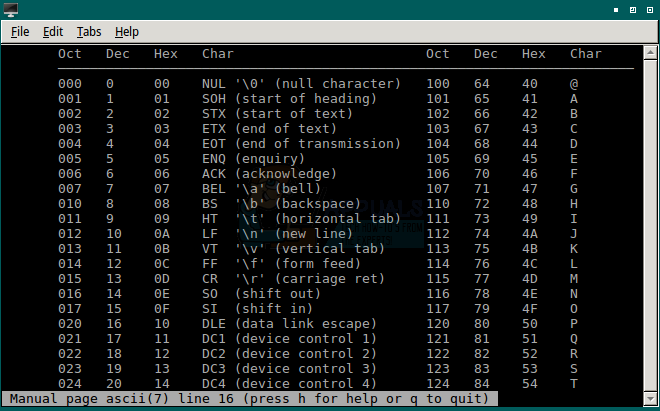
Прокрутите вниз с помощью колеса прокрутки мыши, нажав клавишу Page Down или клавишу со стрелкой вниз на клавиатуре. Вы можете изучить очень подробную страницу, которая содержит несколько полных таблиц ASCII. Просто проведите мышью, чтобы выделить текст, а затем, удерживая клавиши CTRL и SHIFT, нажмите C, чтобы скопировать; любая скопированная информация может быть вставлена в другое окно.
Способ 2: с помощью инструмента графических страниц справочника
Удерживая нажатой клавишу Windows или Super, нажмите R, чтобы открыть диалоговое окно запуска. Введите xman в поле и затем нажмите ввод или нажмите OK, чтобы продолжить.
Как только вы это сделаете, появится маленькое диалоговое окно под названием xman. Нажмите на «Страницу руководства» внутри этой совершенно белой коробки.
Появится окно справки Xman, объясняющее, как это инструмент ручного просмотра системы X Window. Игнорируйте этот текст, вместо этого нажмите «Опции» и выберите функцию «Поиск».
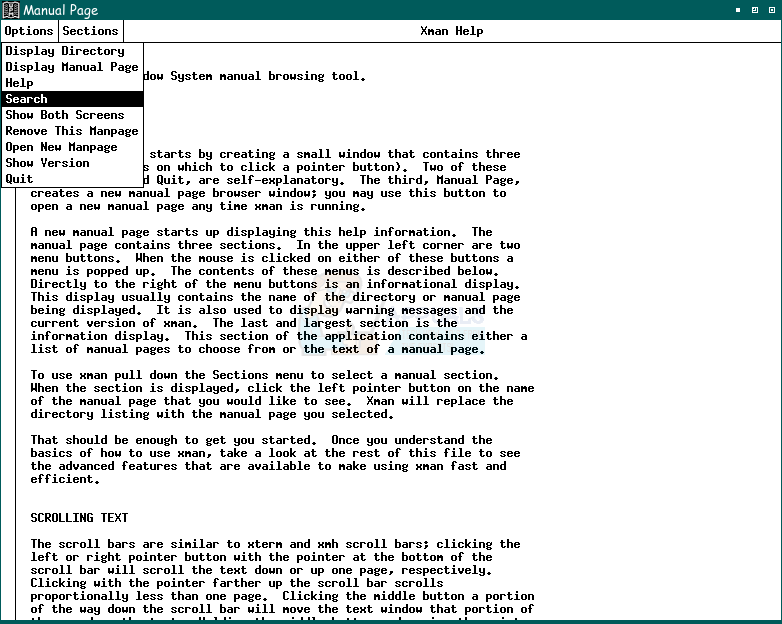
Окно поиска появится отдельно от экрана объяснения страницы руководства. Введите ascii в поле поиска и нажмите кнопку «Страница руководства».
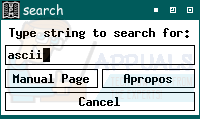
Теперь вы увидите ту же страницу Руководства для программиста Linux, которая была бы, если бы вы использовали функцию CLI. Прокрутите колесико мыши, чтобы просмотреть таблицы ASCII, или нажмите клавишу «F» или пробел, чтобы перемещаться вниз по странице за раз.
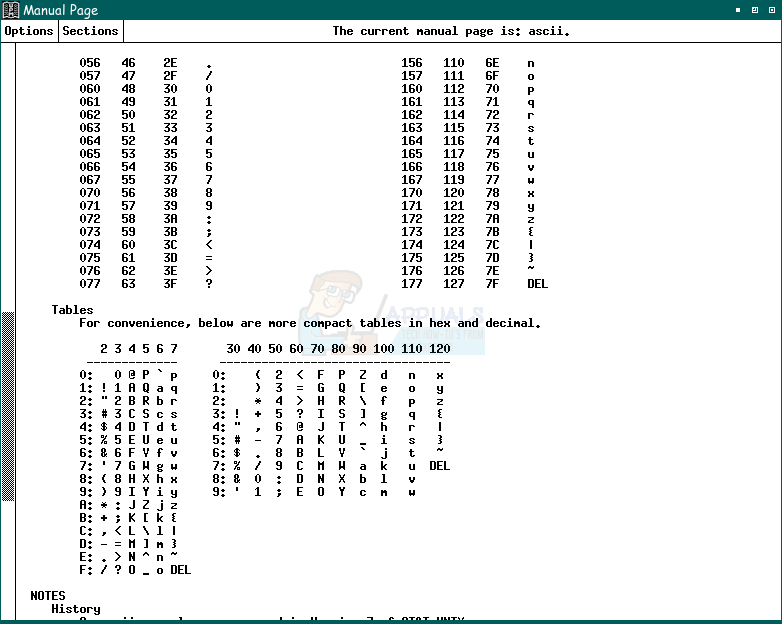
Хотя команда xman в значительной степени устарела, она все еще включена в XFree, и вы можете теоретически использовать ее для поиска любой команды или встроенной справочной страницы Linux Programmer’s Manual, следуя этому же процессу. Вы также можете использовать его для просмотра каждой man-страницы, установленной в вашей системе, используя ту же систему подсказок меню, которую вы использовали для доступа к странице программиста ASCII.
Способ 3: с помощью сценария оболочки
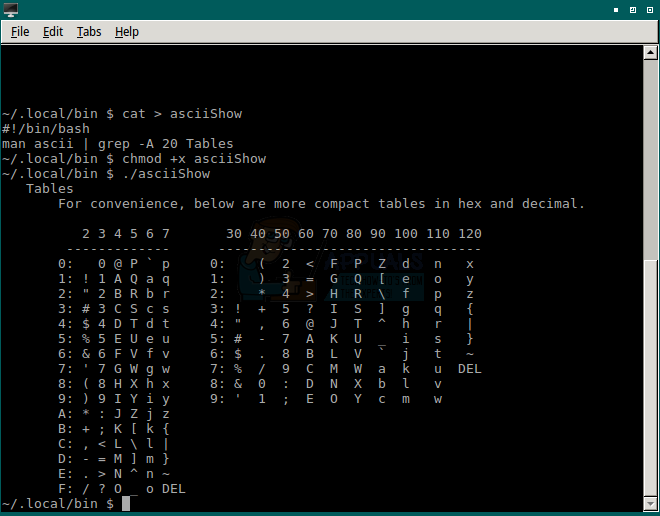
Если вы обнаружите, что становитесь зависимыми от этой таблицы для задач программирования, вы можете автоматизировать процесс поиска таблиц с помощью сценария оболочки Bash. В интерфейсе командной строки Linux используйте команду cd, чтобы найти себя в логическом месте. Например, вы можете использовать cd
/ .local / bin, чтобы поместить ваш скрипт в область, где он будет легко доступен независимо от того, где вы находитесь. Когда вы захотите создать сценарий, введите cat> asciiShow и нажмите enter. Затем введите #! / Bin / bash, затем введите, а затем man ascii | grep -A 20 таблиц с последующим вводом. Затем нажмите CTRL и D одновременно. Вернувшись к обычному приглашению, введите chmod + x asciiShow, чтобы сделать ваш новый скрипт исполняемым, нажмите enter, а затем введите ./asciiShow и затем enter, чтобы запустить его.
Способ 4: с помощью текстового файла
Вместо того, чтобы преодолевать трудности создания сценария, вы также можете перенаправить вывод этой команды в текстовый файл для проверки в любом текстовом редакторе, который вам необходим. Используйте команду cd, чтобы найти подходящее место для размещения вашего текстового файла. Например, вы можете захотеть набрать cd
/ Documents, чтобы попасть в вашу обычную папку документов. Когда-то наберите man ascii | grep -A 20 Таблицы> Asciitables и нажмите Enter.
Теперь вы можете редактировать этот файл с любым программным обеспечением, которое вам нравится. Вы можете ввести cat asciitables и затем нажать Enter, чтобы вывести его на терминал. Если вы перейдете к
/ Documents в графическом файловом менеджере и дважды щелкните там значок asciitables, вы можете открыть его в графическом текстовом редакторе.
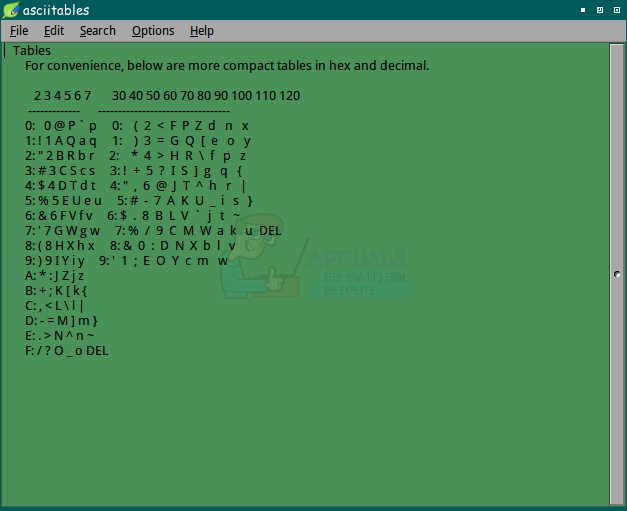
Способ 5: с помощью команды showkey
Если вам нужен конкретный код, вы можете получить интерактивный доступ к встроенным таблицам ASCII. Введите showkey -a в командной строке CLI Bash и нажмите ввод. Вас встретит сообщение «Нажмите любую клавишу — Ctrl-D завершит эту программу», за которым следует курсор. Нажмите любую нужную клавишу, чтобы увидеть числовые коды, чтобы получить запрошенный вывод, а затем нажмите одновременно клавиши CTRL и D для выхода.
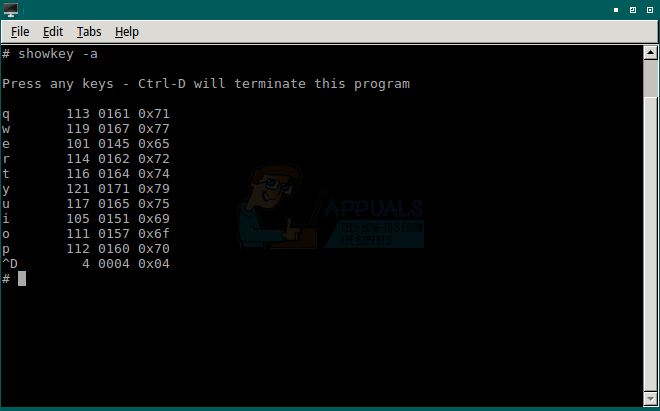
Это может быть отличным способом найти информацию о персонаже, пока вы пишете исходный код.
Источник



