- Команда uniq Linux
- Синтаксис uniq
- Опции uniq
- Примеры использования uniq
- Выводы
- Вывести в bash только дубликаты строк из файлов?
- Найдите строки с одинаковым значением в столбце в двух файлах
- 2 ответа
- bash найти дубли в файлах
- HackWare.ru
- Этичный хакинг и тестирование на проникновение, информационная безопасность
- Азы работы в командной строке Linux (часть 3)
- Стандартный вывод и стандартный ввод. Перенаправление вывода
- cat – для отображения содержимого файлов
- wc – для подсчёта строк, слов и байт
- grep – вывод строк, соответствующих шаблону
- uniq – сообщает о повторяющихся строках или удаляет их
- Различия между > и |
- less – для просмотра содержимого больших файлов
- head — Вывод только начала текстового файла
- tail — Вывод только конца текстового файла
- Ввод имён файлов в Linux
- Связанные статьи:
- Рекомендуется Вам:
- 2 комментария to Азы работы в командной строке Linux (часть 3)
Команда uniq Linux
Команда uniq предназначена для поиска одинаковых строк в массивах текста. При этом с найденными совпадениями пользователь может совершать множество действий — например, удалять их из вывода либо наоборот, выводить только их.
Работа команды осуществляется как с текстовыми файлами (в том числе, записями скриптов), так и с текстом, напечатанным в командной строке терминала.
Синтаксис uniq
Запись команды осуществляется следующим образом:
$ uniq опции файл_источник файл_для_записи
Файл источник указывает откуда надо читать данные, а файл для записи — куда писать результат. Но их указывать не обязательно. В примерах мы будем набирать текст, который нуждается в редактировании, прямо в командную строку терминала, воспользовавшись ещё одной командой — echo, и применив к ней опцию -e. Это будет выглядеть так:
echo -e [текст, слова в котором разделены управляющей последовательностью\\n] | uniq
Эта управляющая последовательность нужна, чтобы указать утилите, что каждое слово выводится в новой строке. Если указано только название файла источника, результат выполнения команды появится прямо в окне терминала. А при наличии выходного файла текст будет напечатан в теле документа.
Опции uniq
У команды uniq есть такие основные опции:
- -u (—unique) — выводит исключительно те строки, у которых нет повторов.
- -d (—repeated) — если какая-либо строка повторяется несколько раз, она будет выведена лишь единожды.
- -D — выводит только повторяющиеся строки.
- —all-repeated[=МЕТОД] — то же самое, что и -D, но при использовании этой опции между группами из одинаковых строк при выводе будет отображаться пустая строка. [=МЕТОД] может иметь одно из трех значений — none (применяется по умолчанию), separate или prepend.
- —group[=МЕТОД] — выводит весь текст, при этом разделяя группы строк пустой строкой. [=МЕТОД] имеет значения separate (по умолчанию), prepend, append и both, среди которых нужно выбрать одно.
Вместе с основными опциями могут применяться дополнительные. Они нужны для более тонких настроек работы команды:
- -f (—skip-fields=N) — будет проведено сравнение полей, начиная с номера, который следует после указанного вместо буквы N. Поля — это слова, хотя, называть их словами в прямом смысле слова нельзя, ведь словом команда считает любую последовательность символов, отделенную от других последовательностей пробелом либо табуляцией.
- -i (—ignore-case) — при сравнении не будет иметь значение регистр, в котором напечатаны символы (строчные и заглавные буквы).
- -s (—skip-chars=N) — работает по аналогии с -f, однако, игнорирует определенное количество символов, а не строк.
- -c (—count) — в начале каждой строки выводит число, которое обозначает количество повторов.
- -z (—zero-terminated) — вместо символа новой строки при выводе будет использован разделитель строк NULL.
- -w (—check-chars=N) — указание на то, что нужно сравнивать только первые N символов в строках.
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq

После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -c

Теперь применим команду к тексту, который находится в файле.
uniq —all-repeated=prepend text-example.txt

Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.

Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.
echo -e небо исполосовано молниями\\nоблака на небе\\nоблака разогнал ветер\\nоблака закрыли солнце\\nсолнце светит ярко\\nзвезды кажутся огромными | uniq -w5

Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -u

Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».
echo -e небо\\nоблака перистые\\nоблака перистые\\nоблака белые\\nсолнце\\nзвезды | uniq —skip-chars=6

А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq —group=both

Тогда как append не добавило пустую строку перед текстом:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq —group=append

Выводы
Команда uniq linux пригодится тем, кто часто и много работает с массивами текста, не имея возможности вычитывать их самостоятельно. Следует заметить, что не все версии uniq работают исправно, поэтому иногда результат выдачи может отличаться от ожидаемого.
Свои вопросы относительно использования команды, а также замечания и пожелания оставляйте в комментариях.
Источник
Вывести в bash только дубликаты строк из файлов?
Здраствуйте,
требуется вывести из двух файлов только строки которые имеются в обоих файлах
Пример содержимого файлов:
вот как пробую, в результате получаю только 33, в каталоге содержится только два .txt файла:
cat *.txt | uniq -d
33
подскажите что пропустил.
- Вопрос задан 21 окт. 2020
- 130 просмотров
Можно ещё comm -12


Saboteur,
1. да, точно прочитал и даже протестировал.
2. на этом примере ваш вариант работает, но формально постановке задачи не соответствует. Топикстартер может ошибаться. Любой может ошибаться. И я в том числе. Если я ошибаюсь, покажите где и докажите как я сейчас покажу вашу ошибку в вашем решении. Ничего плохого в ошибках нет, если их исправлять.
3. Вы не поняли суть моей претензии.
Смотрите:
На этом примере строка 55 в двух экземпоярах есть в первом файле. Из-за того, что она там встречается дважды (а такое вполне может быть, о чем свидетельствует 33), 55 будет выдана в числе прочих вашим первым методом. А 55 нет во втором файле.
Источник
Найдите строки с одинаковым значением в столбце в двух файлах
У меня два файла (миллионы столбцов)
File1.txt ,
File2.txt ,
Когда есть точное совпадение между столбцом 2 в File1.txt и столбцом 3 в File2.txt , я хочу распечатать определенные строки из обоих файлов.
Я пробовал это (забыл написать) но не работает
2 ответа
Допустим, ваш набор данных велик в обоих измерениях — строках и столбцах. Тогда вы хотите использовать join . Чтобы использовать join , вы должны сначала отсортировать данные. Что-то в этом роде:
sort -k2,2 означает «сортировать целые строки так, чтобы значения второго столбца располагались в порядке возрастания». join -1 2 означает «ключ в первом файле — второй столбец».
Если ваши файлы больше, чем, скажем, 100 МБ, стоит выделить дополнительную память для sort с помощью параметра -S . Эмпирическое правило состоит в том, чтобы назначить в 1,3 раза больший размер ввода, чтобы избежать подкачки диска с помощью sort . Но только если ваша система справится с этим.
Если один из ваших файлов данных очень маленький (скажем, до 100 строк), вы можете подумать о том, чтобы сделать что-то вроде
Чтобы избежать sort , но тогда вам придется искать «ключи» в этом файле.
Решение, какой из них использовать, очень похоже на «хеш-соединение» и «объединение слиянием» в мире баз данных.
Вам нужно исправить свою программу awk
Чтобы распечатать все записи в файле2, если поле 1 (файл1) существует в поле 3 (файл2): —
Чтобы напечатать только поле 1 в файле2, если поле 1 (файл1) существует в поле 3 (файл2): —
Источник
bash найти дубли в файлах
как бы убрать из 1.txt эти 20 дублирующихся строк, которые присутствуют в 2.txt ?
grep -vf 2.txt 1.txt >3.txt
mv 3.txt 1.txt

большое спасибо, солвед
Если задача именно в поиске дублей, а не в упражнениях на bash, рекомендую взглянуть на fdupes
да мне собственно нужно было результаты работы распарсить, убрать повторы которые вчера писал в старый файл
ОК, я так, к слову.
почему получается файл 0 размера?
поможет ли тут кстати fdupes? (судя по описанию — нет?)
вкратце — нужно выкинуть из words_sort.txt те строки, которые есть в oooold.txt и поместить результат в uuuniq.txt
что за бред? памяти что ли не хватает 🙁
ограничения в grep ? =(
более того, еще и грузит только 1 ядро.
Очевидно, строки в oooold.txt содержат спецсимволы, кот-е нужно экранировать.
Чтобы не ипать моск, можно написать это на питоне:
Да, нужен пистон >= 2.7.
еще раз спасибо, как раз питон начал осваивать
Источник
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Азы работы в командной строке Linux (часть 3)
Стандартный вывод и стандартный ввод. Перенаправление вывода
Для командной строки существует такое понятие как «стандартный вывод». Стандартным является вывод в консоль. Например, команда
выводит в консоль список файлов:
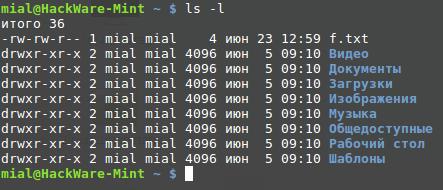
Стандартный вывод можно перенаправить – вместо отображения в консоли его можно:
- сохранить в файл;
- передать другой программе;
- безвозвратно уничтожить без вывода и сохранения куда-либо.
Для сохранения в файл используется символ >
После этого символа нужно указать имя файла. Например:
При этом на экран ничего не вывелось. Но если проверить файлы, то можно увидеть новый с именем files.txt.
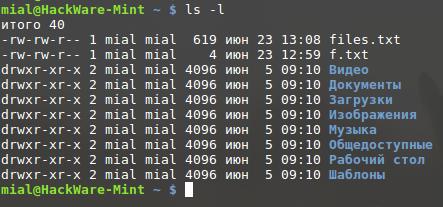
cat – для отображения содержимого файлов
Главной функцией cat является «склеивание» нескольких файлов. После неё можно указать название нескольких файлов, и она последовательно их выведет. Если вы указали название только одного файла, то будет отображён только он. Для показа только что созданного файла:
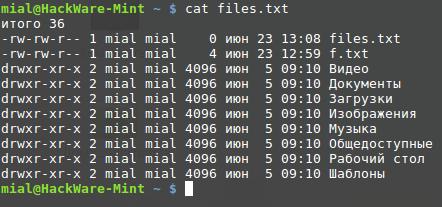
wc – для подсчёта строк, слов и байт
Программа wc считает, сколько ей передали строк, сколько слов и сколько байт.
После команды wc нужно указать имя файла, например:
Будет выведено что-то вроде:
- 11 – количество строк в файле
- 93 – количество слов в файле
- 619 – количество байт в файле
Если вы хотите, чтобы вывод ограничился количеством строк, то используйте ключ -l:
Там вы увидите, что если файл не задан, то читается стандартный вывод. Мы уже выяснили, что стандартный вывод – это то, что другие программы выводят в консоль. Если мы хотим передать вывод одной программы в другую, то используется символ |. Например:
Если программа принимает от другой программы вывод через символ |, то это называется стандартным вводом.
Мы также можем использовать различные опции, как с первой, так и со второй командой:
Можно воспользоваться стандартным выводом команды cat:
grep – вывод строк, соответствующих шаблону
Общий вид использования команды:
Означает искать в файле files.txt строки, соответствующие шаблону «txt».

Команда grep также поддерживает стандартный ввод:
Поиск по шаблону осуществляется с учётом регистра. Т.е. txt, Txt и TXT – это три разных шаблона и если вы указали txt, то строка, содержащая TXT будет считаться неподходящей. Для поиска без учёта регистра используется опция -i.
Чтобы было интереснее, скачайте или создайте текстовый файл. Если у вас нет своего файла, то скачайте словарик:
Примечание: wget и bunzip2 – это также команды Linux. Первая используется для получения файлов по сети, вторая для распаковки архивов. Пока мы не будем останавливаться на них подробно.
Итак, в результате работы этих двух команд мы скачали и распаковали текстовый файл. В текущей рабочей директории у нас присутствует файл rockyou.txt.
Поищем в этом файле строки, содержащие, например, шаблон «russia», чтобы поиск осуществлялся без учёта регистра, добавим ключ -i:
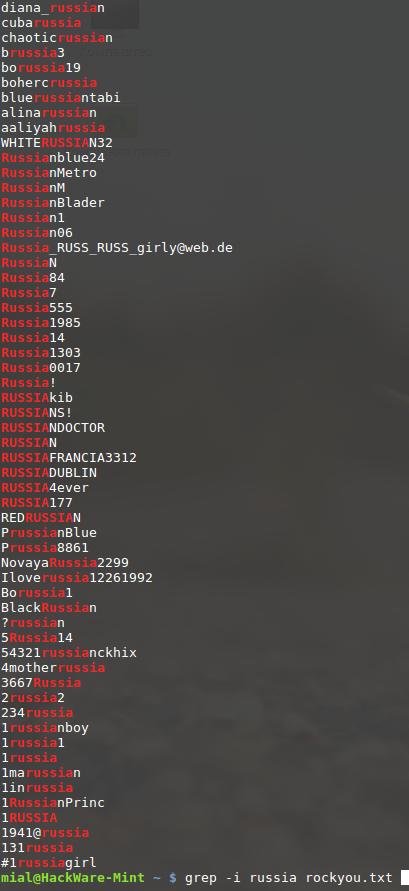
Как мы помним, команда grep может работать со стандартным вводом. Поэтому следующая команда абсолютно аналогична:
Будет найдено довольно много совпадений. А сколько именно? Легко:

Если вы немного запутались, поясню. Команда cat считывает файл rockyou.txt и выводит его в стандартный вывод, по стандартному вводу (символ |) стандартный вывод передаётся команде grep, которая без учёта регистра (-i) ищет все строки, содержащие слово russia, найденные строки по стандартному вводу (символ |) передаются команде wc, которая считает их количество, при этом считается только количество строк, а количество слов и количество байт не отображается (-l).
uniq – сообщает о повторяющихся строках или удаляет их
Команда uniq удаляет одинаковые строки или показывает их. Но она «видит» одинаковые строки только если они являются смежными (следуют друг за другом). Т.е. перед применением команды uniq, записи в файле нужно отсортировать. Для этого применяется команда sort.
Давайте начнём с того, что посчитаем общее количество строк в файле rockyou.txt. Для этого мы выведем его содержимое в стандартный вывод командой cat, а затем применим команду wc:
Теперь перед тем, как посчитать количество строк, мы их отсортируем (команда sort) и удалим одинаковые (команда uniq). Обе эти команды умеют работать со стандартным вводом (а также и с файлами). Далее показан пример при работе со стандартным вводом:

Как можно заметить, в файле rockyou.txt имеется почти три тысячи абсолютно одинаковых строк.
Задание для самостоятельной работы: посмотрите справку по командам uniq, sort и wc и удалите дубликаты из файла rockyou.txt без использования стандартного ввода. А затем посчитайте количество уникальный записей также без использования стандартного ввода.
У команды uniq имется ключ -d, который позволяет просмотреть одинаковые строки. Но вначале очистим словарь от нечитаемых символов:
iconv -f utf-8 -t utf-8 -c
Подробности о проблеме, которую решает предыдущая команда, вы найдёте в статье «Как из текстового файла найти и удалить символы, отличные от UTF-8».
А теперь выведем список дублирующихся строк:
Различия между > и |
Оба символа: > и | используются для перенаправления стандартного вывода. Но символ > отправляет данные в файл, а символ | (его ещё называют «труба») отправляет их другой программе. Если сделать так:
То этой командой вы пытаетесь переписать бинарный (исполнимый) файл программы sort тем, что выдаст cat. Если вы обычный пользователь, то система не позволит вам испортить файл программы. Но если вы работаете под учётной записью администратора, то таким образом вы навредите системе, результат будет совершенно другим от ожидаемого вами.
Если вы хотите очистить файл rockyou.txt от дублей и сохранить результат в новый файл, то нужно сделать так:
Здесь cleaned_rockyou.txt – это название нового файла без дублей.
less – для просмотра содержимого больших файлов
Вы могли обратить внимание, что когда мы вывели результаты поиска командой:
то вывод получил достаточно большим и пришлось прокручивать окно консоли вверх.
Что делать, если нужно просмотреть большой вывод или очень объёмный текстовый файл? Команда
в этом случае абсолютно бы не помогла, она только переполнит окно консоли, и вы даже не сможете просмотреть самые верхние строки файла.
Для таких случаев имеется команда less. Она может работать и с файлами и со стандартным вводом. Для просмотра файла:
Вы можете прокручивать большие файлы вверх и вниз.
Вы можете вводить команды для поиска и навигации по файлу:
| Команда | Действие |
|---|---|
| Page Up или b | Прокрутка назад на одну страницу |
| Page Down или пробел | Прокрутка вперёд на одну страницу |
| Стрелка вверх (↑) | Прокрутка вверх на одну строку |
| Стрелка вниз (↓) | Прокрутка вниз на одну строку |
| G | Перейти к концу файла |
| 1G или g | Перейти к началу файла |
| /символы | Поиск вперёд по файлу введённых символов |
| n | Поиск следующего вхождения предыдущего поиска |
| h | Показать справку |
| q | Выйти из less |
Для выхода из команды less используйте клавишу q.
head — Вывод только начала текстового файла
Команда head выводит только начало текстового файла. По умолчанию будет выведено первые 10 строк, например, чтобы вывести начало файла ZTE F2.txt:
Если вам нужно оставить только определённое число строк, то используйте опцию -n, после которой укажите желаемое число строк, например, чтобы вывести только одну первую строку файла:
Чтобы вывести первые 100 строк:
tail — Вывод только конца текстового файла
Эта команда похожа на head, но выводит конец файла.
По умолчанию выводятся последние 10 строк, но вы можете изменить их количество опцией -n:
Ввод имён файлов в Linux
Консоль поддерживает drag-and-drop, т.е. вы можете перетащить и бросить в консоль файл, после этого в консоли появится полный путь до файла.
Также используйте клавишу TAB для автодополнения имени файла и пути до него.
Будьте внимательны с файлами, у которых присутствуют в имени пробелы. Например, если вы хотите переименовать файл files.txt в файл new file.txt, то следующая команда завершиться шибкой:
Чтобы избежать ошибку, нужно:
- взять путь до файла, содержащий пробелы, в кавычки;
- экранировать пробел;
- вместо пробела использовать знак нижнего подчёркивания (_), который по общепринятому соглашению символизирует пробел.
Т.е. все следующие команды являются верными. Имя файла в кавычках:
Замена пробела на знак нижнего подчёркивания:
В Linux можно создавать файлы с именами, невозможными в Windows, например, в именах можно использовать слеши, двоеточие, нулевой байт и т.д. Будьте внимательны с такими файлами – в Windows вы не сможете их ни открыть, ни переименовать, ни удалить.
Связанные статьи:
- Регулярные выражения и команда grep (71.1%)
- Азы работы в командной строке Linux (часть 1) (51.9%)
- Азы работы в командной строке Linux (часть 2) (51.9%)
- Команда find: поиск в файловой системе по любым свойствам файла (51.9%)
- Как установить Guake в Kali Linux (51.9%)
- Логи Apache (ч. 1): Виды и модули журналов. Формат логов доступа Apache (RANDOM — 50%)

Рекомендуется Вам:
2 комментария to Азы работы в командной строке Linux (часть 3)
Всех приветсвую, можете подсказать в чем проблема.
Я скачал файл rockyou без проблем.
Но когда я делаю поиск дубликатов cat rockyou.txt | sort | uniq -d у меня ничего не выводится, показыает 0; Пробовал сразу удалить дубликаты cat rockyou | sort | uniq таже история, сколько файлов было столько и есть.
После я создал свой небольшой текстовый файл, где разместил одинаковые и неодинаковые строки. С помощью этих команд эти дубликаты находились…
А именно в документе rockyou по прежнему нет, я решил в самом документе вручную добавить пару дубликатов что бы посмотреть, найдет ли он их. И действительно нашел, но помимо моих дубликатов нашлись и все остальные, как это понимать, почему только после редактирования файла в ручную дубликаты возможно было обнаружить?
Приветствую! Важное наблюдение. Дело в том, что файл rockyou.txt имеет несколько строк с неверными, с точки зрения UTF-8 символами, из-за которых команда uniq с опцией -d терпит неудачу.
Очистим словарь от нечитаемых символов:
Подробности о проблеме, которую решает предыдущая команда, вы найдёте в статье «Как из текстового файла найти и удалить символы, отличные от UTF-8».
А теперь можно вывести список дубликатов (в новом правильном файле):
Ваши действия (пересохранение файла) приводили к тому, что редактор сам удалял неправильные символы и после этого uniq -d начинала работать как надо.
Источник



