- InterMaster.com.ru
- Как я меняю в проектах концы строк с CRLF на LF
- Еще записи по теме
- [bash] Замена переводов строк «unix2dos»
- Re: [bash] Замена переводов строк «unix2dos»
- Re: [bash] Замена переводов строк «unix2dos»
- Re: [bash] Замена переводов строк «unix2dos»
- Re: [bash] Замена переводов строк
- Re: [bash] Замена переводов строк «unix2dos»
- Re: [bash] Замена переводов строк «unix2dos»
- Re: [bash] Замена переводов строк
- Re: [bash] Замена переводов строк
- Re: [bash] Замена переводов строк
- Re: [bash] Замена переводов строк
- Конвертировать CRLF в перевод строки в Linux
- Linux преобразовать перенос строки
- Команда tr и ее синтаксис
- 1) Заменить все строчные буквы на заглавные
- 2) Удаление символов с помощью tr
- 3) Удаление ила змена символов НЕ в наборе
- 4) Замена пробелов на табуляцию
- 5) Удаление повторений символов
- 6) Заменить символы из набора на перенос строки
- 7) Генерируем список уникальных слов из файла
- 8) Кодируем символы с помошью ROT
- Вывод
InterMaster.com.ru
О бизнесе в интернете, отдыхе в реале и просто о жизни…
Как я меняю в проектах концы строк с CRLF на LF
Иногда бывает такая ситуация – получаешь от заказчика движок для его дальнейшего «допиливания». Пытаешься положить его в репозиторий Git – и получаешь кучу варнингов типа:
Это понятно — файлы в исходнике писались/правились до меня разными людьми и на разных операционных системах. Поэтому в файлах наблюдается полная мешанина в вопросе формата окончания строк.
Небольшая справка для тех, кто не в курсе. В разных операционных системах принят разный формат символов, обозначающий перевод строк:
- Windows — \r\n или CRLF (код 0D0A)
- Unix — \n или LF (код 0A)
- Mac — \r или CR (код 0D).
Такую разносортицу в своем проекте мне держать не хочется, поэтому я предпочитаю перед началом работ приводить все окончания строк к единому виду — \n, он же LF. Почему так? Большинство серверов работают под управлением систем на базе Unix, поэтому, на мой взгляд, логично использовать nix’овые окончания строк и для файлов движка сайта.
Теперь опишу свой способ приведения конца строк к единому виду. Описывать работу буду на примере графической оболочки Git – Git GUI. Так проще и нагляднее.
- Кладу все файлы движка в папку – например, Original.
- Удаляю всякие временные файлы и прочий мусор.
- В пустые папки, которые тем не менее необходимы для работы сайта, кладу файл readme.txt. Это надо по той причине, что Git отслеживает только файлы, а не папки. Поэтому если закоммитить в Git движок с пустыми папками, то потом при выгрузке движка этих пустых, но нужных папок мы не увидим.
- Открываю пункт меню «Редактировать» -> «Настройки» и указываю имя пользователя, email и кодировку файлов проекта.
- В файлах настроек Git – gitconfig — для параметра core прописываю:
- autocrlf = input
- safecrlf = warn
или выполнить команды:
- $ git config —global core.autocrlf input
- $ git config —global core.safecrlf warn
Первый параметр дает команду Git заменить все окончания строк с CRLF в LF при записи в репозиторий.
Второй – выдает предупреждения о конвертации специфических бинарников, если вдруг такие окажутся в движке.
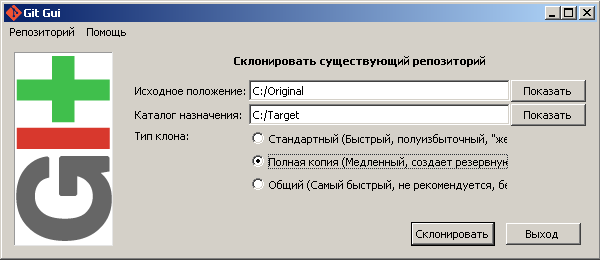
- В результате этой манипуляции у нас на диске C появилась папка Target, в которой лежат файлы из репозитория папки Original. Т.е. в папке Target все концы строк приведены к формату LF или CR.
- Заходим в папку Target, видим в ней папку .git – удаляем эту папку.
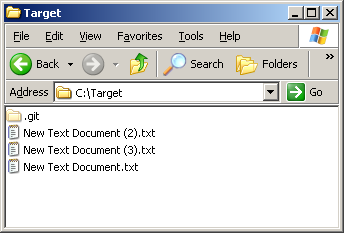
- Открываем редактор Notepad++, выбираем пункт меню «Вид» -> «Отображение символов» -> отмечаем «Отображать символ Конец строки». Теперь редактор будет нам показывать символы конца строк.
- Выбираем пункт меню «Поиск» -> «Искать в файлах». В настройках поиска выбираем:
- Режим поиска – Расширенный
- Папка – C:\Target
- Найти — \r

- В итоге мы найдем все файлы, которые имеют концы строк в формате Mac, т.е.\r или CR. Вряд ли их будет много, но иногда встречаются. Открываем каждый файл по очереди в том же редакторе Notepad++. Мы сможем визуально увидеть, что у файла концы строк в формате Mac:
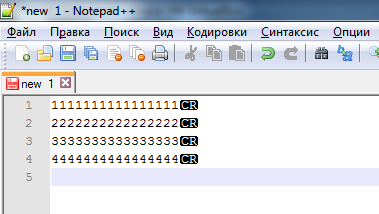
- Преобразуем его в Unix формат. Выбираем «Правка» -> «Формат Конца Строк» -> «Преобразовать в UNIX-формат»
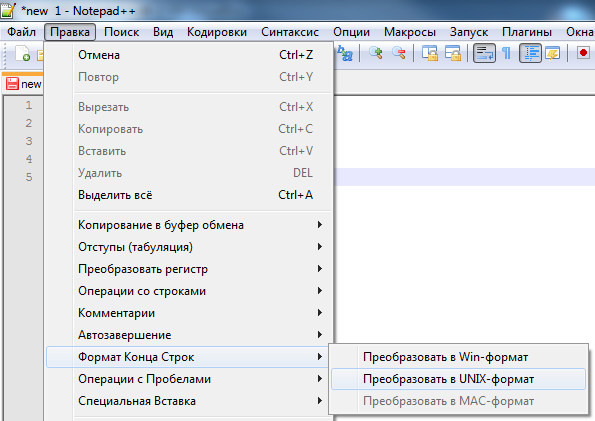
- В итоге файл преобразуется в UNIX-формат.
- Сохраняем файл и выполняем аналогичное преобразование для всех оставшихся файлов в формате Mac. В итоге в папке Target мы будем иметь движок, все файлы которого будут иметь конец строк Unix-формата LF.
Теперь движок можно класть в репозиторий Git. И не забудьте в редакторе, которым выпотом будете править файлы, выставить по умолчанию концовку строк LF, чтобы опять не возникла мешанина.

















Еще записи по теме
Такую петлю через git пришлось делать потому что CRLF концов много? Если я правильно понял, во всех файлах можно было сделать «Правка» -> «Формат Конца Строк» -> «Преобразовать в Win-формат»
Admin: да, можно в каждом файле отдельно формат концов строк поменять. Но т.к. файлов очень много, то пока не придумал ничего лучше такого вот «пакетного» изменения сразу во всех файлах.
Спасибо. Долго искал. Изощрённый метод однако
Как раз с данной ошибкой (LF will be replaced by CRLF ) столкнулся, но смотрю что в Нетбинсе «Правка»->»Замена», выбираем что регулярка и пишем с \r\n на \n и оно во всех файлах приведет к линуксовскому виду, ну типа того что вы добились гитом
Все тоже самое что и в статье, только проще, в Notepad++
CTRL-F >> ‘Найти в файлах’
1. Выбираем ‘Режим поиска’ >> ‘Расширенный’
2. В поле ‘Папка’ выбираем папку с проектом
3. В поле ‘Найти’ пишем ‘\r\n’
4. В поле ‘Заменить на’ пишем ‘\n’
5. Жмем ‘Заменить в файлах’
6. После замены возвращаемся к шагу #3 и пишем ‘\r’, жмем заменить
Источник
[bash] Замена переводов строк «unix2dos»
Re: [bash] Замена переводов строк «unix2dos»

Re: [bash] Замена переводов строк «unix2dos»
Э. А чем штатный /usr/bin/unix2dos не подходит?
Re: [bash] Замена переводов строк «unix2dos»
dos2unix vs unix2dos
Re: [bash] Замена переводов строк
Re: [bash] Замена переводов строк «unix2dos»
З.Ы. по теме: переноси файлы из винды в *них через фтп в режиме ascii, a не binary

Re: [bash] Замена переводов строк «unix2dos»
Re: [bash] Замена переводов строк
>bash: unix2dos: команда не найдена
$ qfile `which unix2dos`
app-text/unix2dos (/usr/bin/unix2dos)
$ eix app-text/unix2dos
[I] app-text/unix2dos
Available versions: 2.2-r1
Installed versions: 2.2-r1(15:46:40 28.09.2008)
Homepage: I HAVE NO HOME 🙁
Description: UNIX to DOS text file format converter
Re: [bash] Замена переводов строк
Re: [bash] Замена переводов строк
rpm -qf /usr/bin/unix2dos unix2dos-2.2-26.2.2
это в RH. Поищи в репозитории этот пакет или похожий. Наверняка есть. Поставь. И все проблемы как рукой снимет.
Re: [bash] Замена переводов строк
опять лоханулся с форматирование 🙂 Вобщем пакеты (их 2 оказалось. Я-то думал обе команды в одном будут) в RH называются unix2dos и второй dos2unix
Источник
Конвертировать CRLF в перевод строки в Linux
Какой лучший способ конвертировать CRLF в перевод строки в файлах в Linux?
Я видел команды sed , но есть ли что-нибудь попроще?
Используйте эту команду:
Эти команды находятся в пакете tofrodos (в большинстве последних дистрибутивов), который также предоставляет две оболочки — unix2dos и dos2unix, которые имитируют старые инструменты unix с тем же именем.
dos2unix — Конвертер форматов текстовых файлов DOS / MAC в UNIX
» как «не». 🙂 но нет, не следую за тобой, хотя я, кажется, сталкиваюсь с тобой часто.
Я предпочитаю Perl :
Но это хорошо подходит для моих целей, и мне очень легко запомнить. Не во всех системах есть команда dos2unix, но большинство, над которыми я работаю, имеют интерпретатор perl.
Другой — перекодирование , мощная замена для dos2unix и iconv; он доступен в пакете «recode» в репозиториях Debian:
Для фанатов awk :
. и sed :
И теперь, только чуть-чуть менее запутанно, чем удаление CR вручную в шестнадцатеричном редакторе, прямо от одного из наших друзей stackoverflow.com , который можно использовать с интерпретатором beef (находится в вашем дружественном соседнем репозитории Debian),
dos2unix в Brainfuck !
Большое спасибо JK за потраченный час его жизни, чтобы написать это!
шарлатан: вот в чем дело: это не проще. это то же самое для вашего Perl ответа. u2d или fromdos / todos — правильные ответы, потому что они проще, чем любые вещи, выраженные на любом другом языке программирования.
Я думаю, что вы также можете использовать tr (хотя у меня нет забавных файлов формата, чтобы попробовать):
Я нашел очень простой способ . Открыть файл с помощью nano: ## nano file.txt
нажмите Ctrl + O для сохранения, но перед нажатием Enter нажмите: Alt + D для переключения между окончаниями строк DOS и Unix / Linux или: Alt + M для переключения между окончаниями Mac и Unix / Linux, затем нажмите Enter для сохранения и Ctrl + X, чтобы выйти.
Я предпочитаю Vim и :set fileformat=unix . Хотя и не самый быстрый, он дает мне предварительный просмотр. Это особенно полезно в случае файла со смешанными окончаниями.
Если вам нужен метод с графическим интерфейсом, попробуйте текстовый редактор Kate (другие продвинутые текстовые редакторы тоже могут с этим справиться). Откройте диалог поиска / замены ( Ctrl + R ) и замените \r\n на \n . (Примечание: вам нужно выбрать «Регулярное выражение» из выпадающего списка и отменить выбор «Только выбор» из опций.)
EDIT: Или, если вы просто хотите конвертировать в формат Unix, то используйте опцию меню Tools > End of Line > Unix .
Вставьте это в скрипт Python dos2unix.py .
Должен работать на любой платформе с установленным Python. Всеобщее достояние.
CR LF с LF использованием AWK :
-v RS=’\r?\n’ устанавливает переменную RS ( input r ecord s eparator) в \r?\n значение, означающее, что input читается строка за строкой, разделенная LF ( \n ), которой может ( ? ) предшествовать CR ( \r ).
1 скрипт, исполняемый awk Сценарий состоит из condition < action >. В этом случае 1 это условие, которое оценивается как истинное. Действие опущено, поэтому выполняется действие по умолчанию, что означает печать текущей строки (которая также может быть записана как
LF в CR LF : Вы можете установить переменную ORS ( о utput г ecord s eparator) , чтобы изменить концы линии выхода. Пример:
Я использовал этот скрипт для файлов, необходимых для экстренной передачи файлов из системы Windows в систему Unix.
Находит все файлы, рекурсивно в каталоге, из которого вы запускаете команду
Передайте его в файловую программу, чтобы получить анализ файла.
Мы хотим только вывод файла, который показывает CRLF.
Получите выход до цвета. откажитесь от всего остального. У нас должно быть только имя файла
Передайте имя файла программе dos2unix, используя xargs .
Источник
Linux преобразовать перенос строки

Команда tr (translate) используется в Linux в основном для преобразования и удаления символов. Она часто находит применение в скриптах обработки текста. Ее можно использовать для преобразования верхнего регистра в нижний, сжатия повторяющихся символов и удаления символов.
Команда tr требует два набора символов для преобразований, а также может использоваться с другими командами, использующими каналы (пайпы) Unix для расширенных преобразований.
В этой статье мы узнаем, как использовать команду tr в операционных системах Linux и рассмотрим некоторые примеры.
Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
\NNN -> восмеричные (OCT) символы NNN (1 до 3 цифр)
\\ -> обратный слеш (экранированный)
\n -> новая строка (new line)
\r -> перенос строки (return)
\t -> табуляция (horizontal tab)
[:alnum:] -> все буквы и цифры
[:alpha:] -> все буквы
[:blank:] -> все пробелы
[:cntrl:] -> все управляющие символы (control)
[:digit:] -> все цифры
[:lower:] -> все буквы в нижнем регистре (строчные)
[:upper:] -> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
Вот некоторые опции:
-c , -C , —complement -> удалить все символы, кроме тех, что в первом наборе
-d , —delete -> удалить символы из первого набора
-s , —squeeze-repeats -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы [:lower:] [:upper:] или «a-z» «A-Z» для замены всех символов.
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
А сейчас сделаем замену из файла input.txt
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
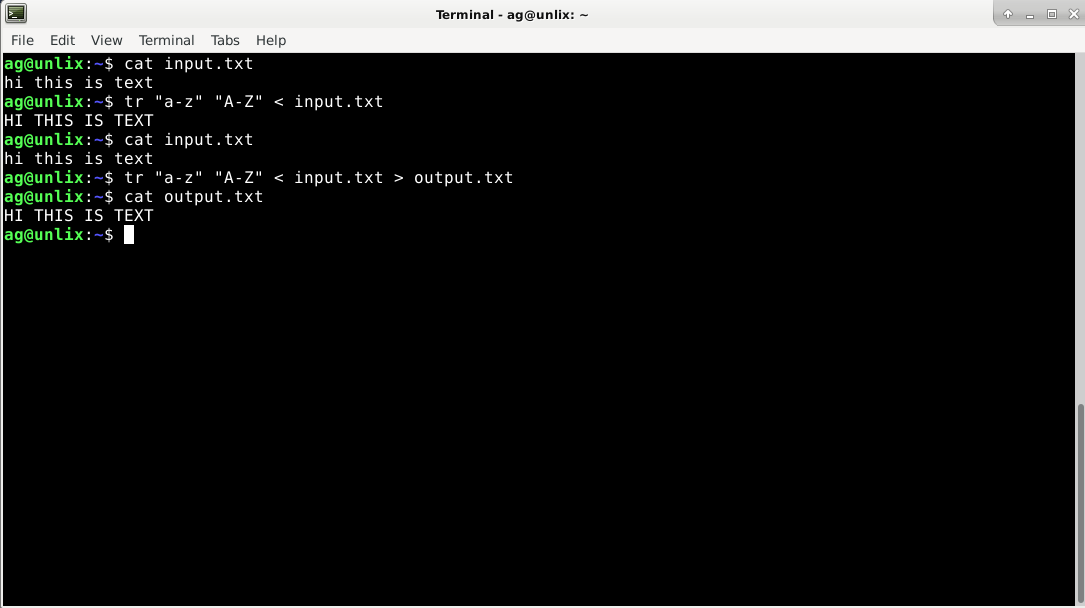
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
2) Удаление символов с помощью tr
Опция -d используется для удаления всех символов, которые указаны в наборе символов.
Следующая команда удалит все символы из этого набора ‘aei’.
Следующая команда удалит все цифры в тексте. Будем использовать набор [:digit:] , чтобы определить все цифры.
А вот пример команд, которыми можно удалить переносы на новые строки
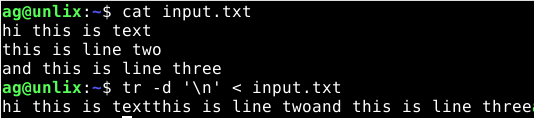
3) Удаление ила змена символов НЕ в наборе
С помощью параметра -c Вы можете сказать tr заменить все символы, которые Вы не указали в наборе. Приведем пример.
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)

4) Замена пробелов на табуляцию
Для указания пробелов используем — [:space:] , а для табуляции — \t.
5) Удаление повторений символов
Это делает параметр -s . Рассмотрим пример удаления повторов знаков.
Или заменим повторения на символ решетки
6) Заменить символы из набора на перенос строки
Сделаем так, чтобы все буквы были заменены на перенос новой строки:
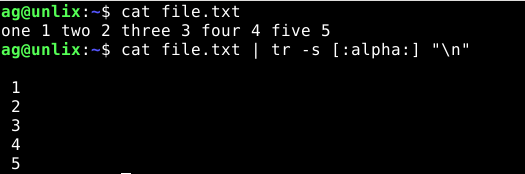
7) Генерируем список уникальных слов из файла
Это иногда очень полезная команда, когда необходимо определить количество повторений и вывести уникальные слова из файла:
8) Кодируем символы с помошью ROT
ROT (Caesar Cipher) — это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор [a-z] (это значит abcdefghijklmnopqrstuvwxyz). Второй набор [n-za-m] (который содержит pqrstuvwxyzabcdefghijklmn).
Простая команда для демонстрации вышеуказанной теории:
Полезно при шифровании электронных адресов:
Вывод
tr — это очень мощная команда линукс при использовании пайпов Unix и очень часто используется в скриптах. Дополнительную информацию об этой утилите всегда можно найти в man.
Если у Вас есть какие-либо дополнения, не стесняйтесь пишите в комментариях.
Источник



