- Изучаем процессы в Linux
- Содержание
- Введение
- Атрибуты процесса
- Жизненный цикл процесса
- Рождение процесса
- Состояние «готов»
- Состояние «выполняется»
- Перерождение в другую программу
- Состояние «ожидает»
- Состояние «остановлен»
- Завершение процесса
- Состояние «зомби»
- Забытье
- Благодарности
- Переменная PATH в Linux
- Переменная PATH в Linux
- Выводы
- Как получить путь к процессу в Unix / Linux
- 10 ответов
- Understanding file paths and how to use them in Linux | Opensource.com
- If you’re used to drag-and-drop environments, then file paths may be frustrating. Learn here how they work, and some basic tricks to make using them easier.
- Subscribe now
- Practice makes perfect
- When in doubt, drag and drop
- dolphin-file-path.jpg
- terminal-drag-drop.jpg
- Tab is your friend
- This isn’t your grandma’s autocompletion
- zsh-simple.jpg
- Practice more
Изучаем процессы в Linux

В этой статье я хотел бы рассказать о том, какой жизненный путь проходят процессы в семействе ОС Linux. В теории и на примерах я рассмотрю как процессы рождаются и умирают, немного расскажу о механике системных вызовов и сигналов.
Данная статья в большей мере рассчитана на новичков в системном программировании и тех, кто просто хочет узнать немного больше о том, как работают процессы в Linux.
Всё написанное ниже справедливо к Debian Linux с ядром 4.15.0.
Содержание
Введение
Системное программное обеспечение взаимодействует с ядром системы посредством специальных функций — системных вызовов. В редких случаях существует альтернативный API, например, procfs или sysfs, выполненные в виде виртуальных файловых систем.
Атрибуты процесса
Процесс в ядре представляется просто как структура с множеством полей (определение структуры можно прочитать здесь).
Но так как статья посвящена системному программированию, а не разработке ядра, то несколько абстрагируемся и просто акцентируем внимание на важных для нас полях процесса:
- Идентификатор процесса (pid)
- Открытые файловые дескрипторы (fd)
- Обработчики сигналов (signal handler)
- Текущий рабочий каталог (cwd)
- Переменные окружения (environ)
- Код возврата
Жизненный цикл процесса
Рождение процесса
Только один процесс в системе рождается особенным способом — init — он порождается непосредственно ядром. Все остальные процессы появляются путём дублирования текущего процесса с помощью системного вызова fork(2) . После выполнения fork(2) получаем два практически идентичных процесса за исключением следующих пунктов:
- fork(2) возвращает родителю PID ребёнка, ребёнку возвращается 0;
- У ребёнка меняется PPID (Parent Process Id) на PID родителя.
После выполнения fork(2) все ресурсы дочернего процесса — это копия ресурсов родителя. Копировать процесс со всеми выделенными страницами памяти — дело дорогое, поэтому в ядре Linux используется технология Copy-On-Write.
Все страницы памяти родителя помечаются как read-only и становятся доступны и родителю, и ребёнку. Как только один из процессов изменяет данные на определённой странице, эта страница не изменяется, а копируется и изменяется уже копия. Оригинал при этом «отвязывается» от данного процесса. Как только read-only оригинал остаётся «привязанным» к одному процессу, странице вновь назначается статус read-write.
Состояние «готов»
Сразу после выполнения fork(2) переходит в состояние «готов».
Фактически, процесс стоит в очереди и ждёт, когда планировщик (scheduler) в ядре даст процессу выполняться на процессоре.
Состояние «выполняется»
Как только планировщик поставил процесс на выполнение, началось состояние «выполняется». Процесс может выполняться весь предложенный промежуток (квант) времени, а может уступить место другим процессам, воспользовавшись системным вывозом sched_yield .
Перерождение в другую программу
В некоторых программах реализована логика, в которой родительский процесс создает дочерний для решения какой-либо задачи. Ребёнок в данном случае решает какую-то конкретную проблему, а родитель лишь делегирует своим детям задачи. Например, веб-сервер при входящем подключении создаёт ребёнка и передаёт обработку подключения ему.
Однако, если нужно запустить другую программу, то необходимо прибегнуть к системному вызову execve(2) :
или библиотечным вызовам execl(3), execlp(3), execle(3), execv(3), execvp(3), execvpe(3) :
Все из перечисленных вызовов выполняют программу, путь до которой указан в первом аргументе. В случае успеха управление передаётся загруженной программе и в исходную уже не возвращается. При этом у загруженной программы остаются все поля структуры процесса, кроме файловых дескрипторов, помеченных как O_CLOEXEC , они закроются.
Как не путаться во всех этих вызовах и выбирать нужный? Достаточно постичь логику именования:
- Все вызовы начинаются с exec
- Пятая буква определяет вид передачи аргументов:
- l обозначает list, все параметры передаются как arg1, arg2, . NULL
- v обозначает vector, все параметры передаются в нуль-терминированном массиве;
- Далее может следовать буква p, которая обозначает path. Если аргумент file начинается с символа, отличного от «/», то указанный file ищется в каталогах, перечисленных в переменной окружения PATH
- Последней может быть буква e, обозначающая environ. В таких вызовах последним аргументом идёт нуль-терминированный массив нуль-терминированных строк вида key=value — переменные окружения, которые будут переданы новой программе.
Семейство вызовов exec* позволяет запускать скрипты с правами на исполнение и начинающиеся с последовательности шебанг (#!).
Есть соглашение, которое подразумевает, что argv[0] совпадает с нулевым аргументов для функций семейства exec*. Однако, это можно нарушить.
Любопытный читатель может заметить, что в сигнатуре функции int main(int argc, char* argv[]) есть число — количество аргументов, но в семействе функций exec* ничего такого не передаётся. Почему? Потому что при запуске программы управление передаётся не сразу в main. Перед этим выполняются некоторые действия, определённые glibc, в том числе подсчёт argc.
Состояние «ожидает»
Некоторые системные вызовы могут выполняться долго, например, ввод-вывод. В таких случаях процесс переходит в состояние «ожидает». Как только системный вызов будет выполнен, ядро переведёт процесс в состояние «готов».
В Linux так же существует состояние «ожидает», в котором процесс не реагирует на сигналы прерывания. В этом состоянии процесс становится «неубиваемым», а все пришедшие сигналы встают в очередь до тех пор, пока процесс не выйдет из этого состояния.
Ядро само выбирает, в какое из состояний перевести процесс. Чаще всего в состояние «ожидает (без прерываний)» попадают процессы, которые запрашивают ввод-вывод. Особенно заметно это при использовании удалённого диска (NFS) с не очень быстрым интернетом.
Состояние «остановлен»
В любой момент можно приостановить выполнение процесса, отправив ему сигнал SIGSTOP. Процесс перейдёт в состояние «остановлен» и будет находиться там до тех пор, пока ему не придёт сигнал продолжать работу (SIGCONT) или умереть (SIGKILL). Остальные сигналы будут поставлены в очередь.
Завершение процесса
Ни одна программа не умеет завершаться сама. Они могут лишь попросить систему об этом с помощью системного вызова _exit или быть завершенными системой из-за ошибки. Даже когда возвращаешь число из main() , всё равно неявно вызывается _exit .
Хотя аргумент системного вызова принимает значение типа int, в качестве кода возврата берется лишь младший байт числа.
Состояние «зомби»
Сразу после того, как процесс завершился (неважно, корректно или нет), ядро записывает информацию о том, как завершился процесс и переводит его в состояние «зомби». Иными словами, зомби — это завершившийся процесс, но память о нём всё ещё хранится в ядре.
Более того, это второе состояние, в котором процесс может смело игнорировать сигнал SIGKILL, ведь что мертво не может умереть ещё раз.
Забытье
Код возврата и причина завершения процесса всё ещё хранится в ядре и её нужно оттуда забрать. Для этого можно воспользоваться соответствующими системными вызовами:
Вся информация о завершении процесса влезает в тип данных int. Для получения кода возврата и причины завершения программы используются макросы, описанные в man-странице waitpid(2) .
Передача argv[0] как NULL приводит к падению.
Бывают случаи, при которых родитель завершается раньше, чем ребёнок. В таких случаях родителем ребёнка станет init и он применит вызов wait(2) , когда придёт время.
После того, как родитель забрал информацию о смерти ребёнка, ядро стирает всю информацию о ребёнке, чтобы на его место вскоре пришёл другой процесс.
Благодарности
Спасибо Саше «Al» за редактуру и помощь в оформлении;
Спасибо Саше «Reisse» за понятные ответы на сложные вопросы.
Они стойко перенесли напавшее на меня вдохновение и напавший на них шквал моих вопросов.
Источник
Переменная PATH в Linux
Когда вы запускаете программу из терминала или скрипта, то обычно пишете только имя файла программы. Однако, ОС Linux спроектирована так, что исполняемые и связанные с ними файлы программ распределяются по различным специализированным каталогам. Например, библиотеки устанавливаются в /lib или /usr/lib, конфигурационные файлы в /etc, а исполняемые файлы в /sbin/, /usr/bin или /bin.
Таких местоположений несколько. Откуда операционная система знает где искать требуемую программу или её компонент? Всё просто — для этого используется переменная PATH. Эта переменная позволяет существенно сократить длину набираемых команд в терминале или в скрипте, освобождая от необходимости каждый раз указывать полные пути к требуемым файлам. В этой статье мы разберёмся зачем нужна переменная PATH Linux, а также как добавить к её значению имена своих пользовательских каталогов.
Переменная PATH в Linux
Для того, чтобы посмотреть содержимое переменной PATH в Linux, выполните в терминале команду:
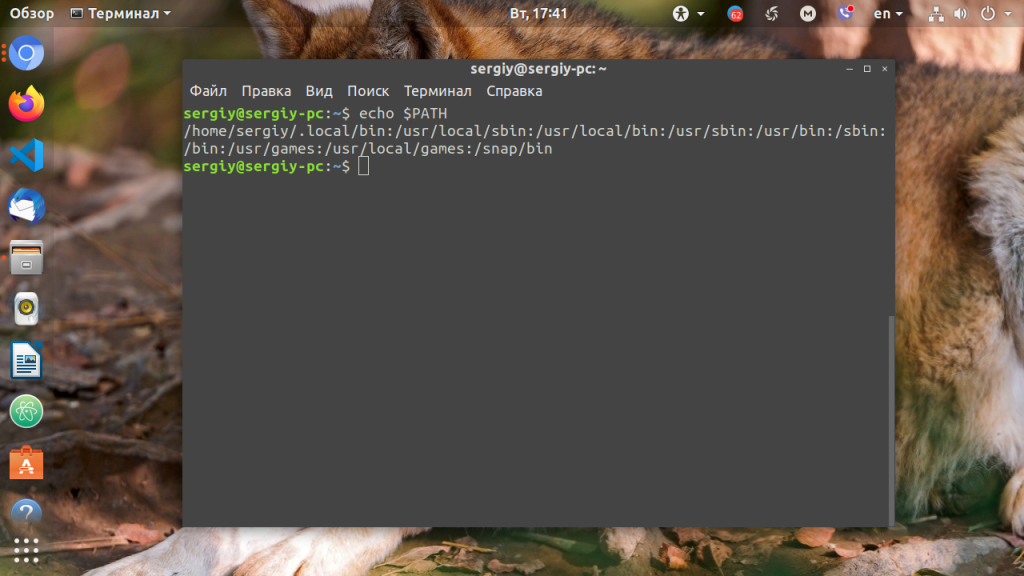
На экране появится перечень папок, разделённых двоеточием. Алгоритм поиска пути к требуемой программе при её запуске довольно прост. Сначала ОС ищет исполняемый файл с заданным именем в текущей папке. Если находит, запускает на выполнение, если нет, проверяет каталоги, перечисленные в переменной PATH, в установленном там порядке. Таким образом, добавив свои папки к содержимому этой переменной, вы добавляете новые места размещения исполняемых и связанных с ними файлов.
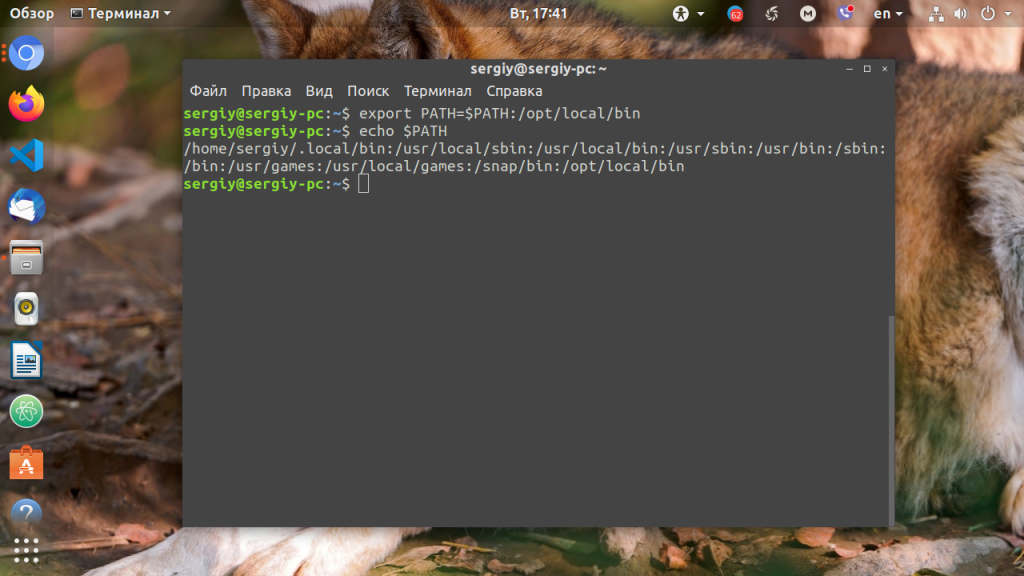
Для того, чтобы добавить новый путь к переменной PATH, можно воспользоваться командой export. Например, давайте добавим к значению переменной PATH папку/opt/local/bin. Для того, чтобы не перезаписать имеющееся значение переменной PATH новым, нужно именно добавить (дописать) это новое значение к уже имеющемуся, не забыв о разделителе-двоеточии:
Теперь мы можем убедиться, что в переменной PATH содержится также и имя этой, добавленной нами, папки:
Вы уже знаете как в Linux добавить имя требуемой папки в переменную PATH, но есть одна проблема — после перезагрузки компьютера или открытия нового сеанса терминала все изменения пропадут, ваша переменная PATH будет иметь то же значение, что и раньше. Для того, чтобы этого не произошло, нужно закрепить новое текущее значение переменной PATH в конфигурационном системном файле.
В ОС Ubuntu значение переменной PATH содержится в файле /etc/environment, в некоторых других дистрибутивах её также можно найти и в файле /etc/profile. Вы можете открыть файл /etc/environment и вручную дописать туда нужное значение:
sudo vi /etc/environment
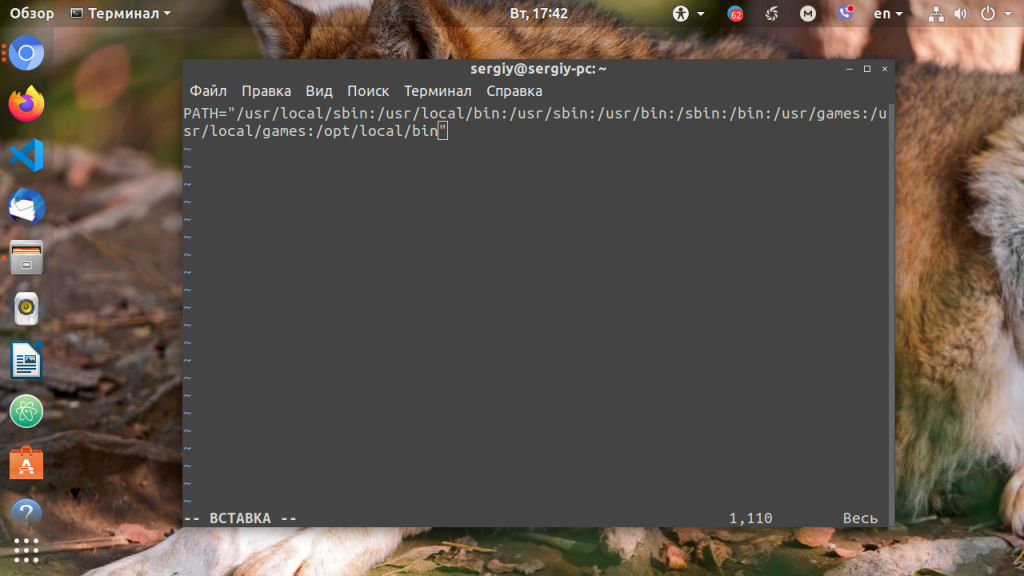
Можно поступить и иначе. Содержимое файла .bashrc выполняется при каждом запуске оболочки Bash. Если добавить в конец файла команду export, то для каждой загружаемой оболочки будет автоматически выполняться добавление имени требуемой папки в переменную PATH, но только для текущего пользователя:
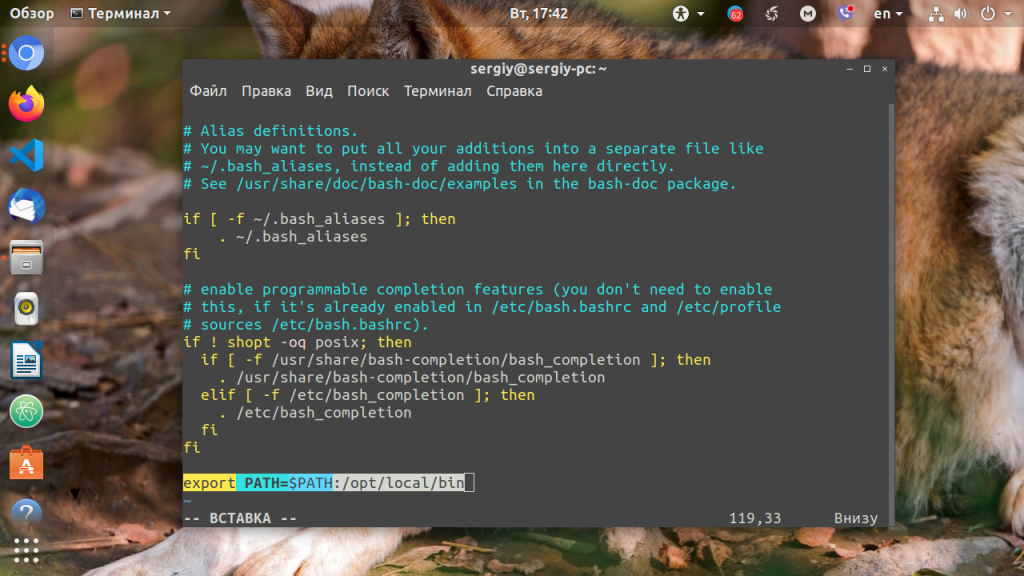
Выводы
В этой статье мы рассмотрели вопрос о том, зачем нужна переменная окружения PATH в Linux и как добавлять к её значению новые пути поиска исполняемых и связанных с ними файлов. Как видите, всё делается достаточно просто. Таким образом вы можете добавить столько папок для поиска и хранения исполняемых файлов, сколько вам требуется.
Источник
Как получить путь к процессу в Unix / Linux
в среде Windows существует API для получения пути, по которому выполняется процесс. Есть ли что-то подобное в Unix / Linux?
или есть какой другой способ сделать это в подобных условиях?
10 ответов
в Linux, символьная ссылка /proc/
/exe имеет путь к исполняемому файлу. Используйте команду readlink -f /proc/
/exe чтобы получить значение.
в AIX, этот файл не существует. Вы могли бы сравнить cksum и cksum /proc/
вы можете легко найти exe этими способами, просто попробуйте сами.
немного поздно, но все ответы были специфичны для Linux.
Если Вам также нужен unix, то вам нужно это:
редактировать: Исправлена ошибка, о которой сообщил Марк лаката.
замените 786 своим PID или именем процесса.
в Linux каждый процесс имеет свою собственную папку в /proc . Так что вы могли бы использовать getpid() чтобы получить pid запущенного процесса, а затем присоединиться к нему с помощью path /proc чтобы получить папку, которую вы, надеюсь, нужна.
вот краткий пример в Python:
вот пример в ANSI C, а также:
скомпилируйте его с помощью:
эта команда будет извлекать путь процесса из того места, где он выполняется.
нет метода «гарантированно работать в любом месте».
Шаг 1-проверить argv[0], если программа была запущена по полному пути, это (обычно) будет иметь полный путь. Если он был запущен относительным путем, то же самое выполняется (хотя для этого требуется получить текущий рабочий каталог, используя getcwd().
Шаг 2, Если ни один из вышеперечисленных не выполняется, должен получить имя программы, а затем получить имя программы из argv[0], а затем получить путь пользователя из окружающая среда и пройти через это, чтобы увидеть, если есть любой исполняемый файл с тем же именем.
обратите внимание, что argv[0] устанавливается процессом, который выполняет программу, поэтому он не является 100% надежным.
спасибо : Kiwy
с AIX:
вы также можете получить путь на GNU / Linux с (не полностью протестирован):
Если вы хотите, чтобы каталог исполняемого файла, возможно, изменил рабочий каталог на каталог процесса (для media/data /etc), вам нужно удалить все после последнего/:
Источник
Understanding file paths and how to use them in Linux | Opensource.com
If you’re used to drag-and-drop environments, then file paths may be frustrating. Learn here how they work, and some basic tricks to make using them easier.
Subscribe now
Get the highlights in your inbox every week.
A file path is the human-readable representation of a file or folder’s location on a computer system. You’ve seen file paths, although you may not realize it, on the internet: An internet URL, despite ancient battles fought by proprietary companies like AOL and CompuServe, is actually just a path to a (sometimes dynamically created) file on someone else’s computer. For instance, when you navigate to example.com/index.html, you are actually viewing the HTML file index.html, probably located in the var directory on the example.com server. Files on your computer have file paths, too, and this article explains how to understand them, and why they’re important.
When computers became a household item, they took on increasingly stronger analogies to real-world models. For instance, instead of accounts and directories, personal computers were said to have desktops and folders, and eventually, people developed the latent impression that the computer was a window into a virtual version of the real world. It’s a useful analogy, because everyone is familiar with the concept of desktops and file cabinets, while fewer people understand digital storage and memory addresses.
As it turns out, the creators of UNIX had the same instinct, only they called these units of organization directories or folders. All files on your computer’s drive are in the system’s base (root) directory. Even external drives are brought into this root directory, just as you might place important related items into one container if you were organizing your office space or hobby room.
Files and folders on Linux are given names containing the usual components like the letters, numbers, and other characters on a keyboard. But when a file is inside a folder, or a folder is inside another folder, the / character shows the relationship between them. That’s why you often see files listed in the format /usr/bin/python3 or /etc/os-release. The forward slashes indicate that one item is stored inside of the item preceding it.
Every file and folder on a POSIX system can be expressed as a path. If I have the file penguin.jpg in the Pictures folder within my home directory, and my username is seth, then the file path can be expressed as /home/seth/Pictures/penguin.jpg.
Most users interact primarily with their home directory, so the tilde (
Practice makes perfect
Computers use file paths whether you’re thinking of what that path is or not. There’s not necessarily a reason for you to have to think of files in terms of a path. However, file paths are part of a useful framework for understanding how computers work, and learning to think of files in a path can be useful if you’re looking to become a developer (you need to understand the paths to support libraries), a web designer (file paths ensure you’re pointing your HTML to the appropriate CSS), a system administrator, or just a power user.
When in doubt, drag and drop
If you’re not used to thinking of the structure of your hard drive as a path, then it can be difficult to construct a full path for an arbitrary file. On Linux, most file managers either natively display (or have the option to) the full file path to where you are, which helps reinforce the concept on a daily basis:
dolphin-file-path.jpg
If you’re using a terminal, it might help to know that modern terminals, unlike the teletype machines they emulate, can accept files by way of drag-and-drop. When you copying a file to a server over SSH, for instance, and you’re not certain of how to express the file path, try dragging the file from your GUI file manager into your terminal. The GUI object representing the file gets translated into a text file path in the terminal:
terminal-drag-drop.jpg
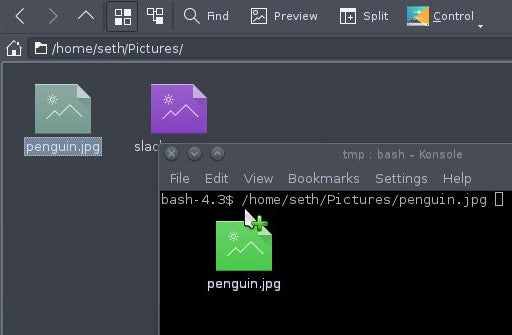
Don’t waste time typing in guesses. Just drag and drop.
Tab is your friend
On a system famous for eschewing three-letter commands when two or even one-letter commands will do, rest assured that no seasoned POSIX user ever types out everything. In the Bash shell, the Tab key means autocomplete, and autocomplete never lies. For instance, to type the example penguin.jpg file’s location, you can start with:
and then press the Tab key. As long as there is only one item starting with Pi, the folder Pictures autocompletes for you.
If there are two or more items starting with the letters you attempt to autocomplete, then Bash displays what those items are. You manually type more until you reach a unique string that the shell can safely autocomplete. The best thing about this process isn’t necessarily that it saves you from typing (though that’s definitely a selling point), but that autocomplete is never wrong. No matter how much you fight the computer to autocomplete something that isn’t there, in the end, you’ll find that autocomplete understands paths better than anyone.
Assume that you, in a fit of late-night reorganization, move penguin.jpg from your
/Pictures folder to your
/Spheniscidae directory. You fall asleep and wake up refreshed, but with no memory that you’ve reorganized, so you try to copy
/Pictures/penguin.jpg to your web server, in the terminal, using autocomplete.
No matter how much you pound on the Tab key, Bash refuses to autocomplete. The file you want simply does not exist in the location where you think it exists. That feature can be helpful when you’re trying to point your web page to a font or CSS file you were sure you’d uploaded, or when you’re pointing a compiler to a library you’re 100% positive you already compiled.
This isn’t your grandma’s autocompletion
If you like Bash’s autocompletion, you’ll come to scoff at it once you try the autocomplete in Zsh. The Z shell, along with the Oh My Zsh site, provides a dynamic experience filled with plugins for specific programming languages and environments, visual themes packed with useful feedback, and a vibrant community of passionate shell users:
zsh-simple.jpg
If you’re a visual thinker and find the display of most terminals stagnant and numbing, Zsh may well change the way you interact with your computer.
Practice more
File paths are important on any system. You might be a visual thinker who prefers to think of files as literal documents inside of literal folders, but the computer sees files and folders as named tags in a pool of data. The way it identifies one collection of data from another is by following its designated path. If you understand these paths, you can also come to visualize them, and you can speak the same language as your OS, making file operations much, much faster.
Источник



