- Linux прочитать первые 10 строк файла
- Операции с файлами и фильтрация
- cat, tail, head, tee: Команды для вывода содержимого файлов
- grep: Поиск строк в файлах
- wc: Подсчёт элементов в файлах
- sort: Сортировка содержимого файла
- linux-notes.org
- Утилита head в примерах Unix/Linux.
- Просмотр содержимого файлов в командной строке Linux
- Команда cat
- Команда nl
- Команда less
- Команда more
- Команда head
- Команда tail
- Заключение
Linux прочитать первые 10 строк файла
Библиотека сайта rus-linux.net
Операции с файлами и фильтрация
Chapter 5. Утилиты командной строки
Операции с файлами и фильтрация
Основная часть работы в командной строке ведётся с файлами. В этом разделе мы рассмотрим, как просматривать и фильтровать содержимое файлов, извлекать из файлов нужную информацию при помощи одной команды и сортировать их содержимое.
cat, tail, head, tee: Команды для вывода содержимого файлов
Эти команды имеют почти один и тот же синтаксис: имя_команды [опции] [файл(ы)], и могут быть использованы в каналах. Все они используются для вывода части файла согласно определенным критериям.
Утилита cat объединяет файлы и выводит результат на стандартный вывод. Это одна из наиболее широко используемых команд. Вы можете использовать:
для вывода, например, содержимого файла с журналом почтового демона на стандартный вывод [14] . Команда cat имеет очень полезную опцию ( -n ), которая позволяет вам выводить номера строк.
Некоторые файлы, типа журналов демонов (если они запущены) обычно имеют довольно большой размер [15] и полный их вывод на экран будет не очень полезным. Часто вам нужно увидеть только несколько строк из файла. Для этого вы можете воспользоваться командой tail . Следующая команда выведет (по умолчанию) последние 10 строк из файла /var/log/mail/info :
Вы можете использовать опцию -n для вывода последних N строк файла. Например, для вывода последних 2-х строк наберите:
Команда head похожа на tail , но она выводит первые строки файла. Следующая команда выведет (по умолчанию) первые 10 строк файла /var/log/mail/info :
Как и в случае с tail вы можете использовать опцию -n для указания количества выводимых строк. Например, для вывода первых 2-х строк наберите:
Также вы можете использовать эти две команды совместно. Например, если вы хотите увидеть только строки 9 и 10, вы можете воспользоваться командой, в которой head выберет первые 10 строк из файла и передаст их по каналу в команду tail.
Затем вторая часть команды отберет последние 2 строки и выведет их на экран. Таким же способом вы можете выбрать 20-ю от конца файла строку:
В этом примере мы говорим команде tail выбрать последние 20 строк файла и передать их по каналу в head. Затем команда head выводит на экран первую строку из полученных данных.
Допустим, что результат последнего примера нам нужно одновременно вывести на экран и сохранить его в файл results.txt . В этом нам может поможет утилита tee . Ее синтаксис:
Теперь мы можем изменить предыдущую команду следующим образом:
Давайте рассмотрим еще один пример. Нам нужно выбрать последние 20 строк, сохранить их в файл results.txt , а на экран вывести только первую из них. Тогда мы должны ввести следующее:
У команды tee есть полезная опция ( -a ), которая позволяет вам дописать данные в конец существующего файла.
Давайте вернемся назад к команде tail . Такие файлы как журналы обычно динамически изменяются, т.к. демон постоянно добавляет в них отчет о совершенных действиях или событиях. Поэтому, если вам нужно наблюдать за изменениями в лог-файле в режиме реального времени, тогда вам нужно воспользоваться преимуществами опции -f :
В этом случае все изменения в файле /var/log/mail/info будут немедленно выводиться на экран. Использование команды tail с опцией -f весьма полезно, когда вам нужно знать, как работает ваша система. Например, наблюдая за файлом журнала /var/log/messages , вы сможете всегда получать обновленную информацию о системных сообщенях и различных демонах.
В следующем разделе мы рассмотрим, как можно использовать утилиту grep в качестве фильтра для отделения сообщений Postfix от сообщений других служб.
grep: Поиск строк в файлах
Ни имя команды, ни ее аббревиатура (“General Regular Expression Parser” — синтаксический анализатор общих регулярных выражений) не слишком интуитивны, но ее действие и ее использование довольно просты для понимания: grep выполняет поиск в одном или нескольких файлах по шаблону, заданному в качестве аргумента. Ее синтаксис:
Если указано несколько файлов, в отображаемом результате их имена будут выводиться перед каждой найденной строкой. Для предотвращения вывода этих имен используйте опцию -h ; используйте опцию -l для вывода только имен файлов с найденными совпадениями. Шаблон — это регулярное выражение, хотя в большинстве случаев он состоит просто из одного слова. Наиболее часто используемые опции:
- -i : поиск без учета регистра (т.е. игнорирование разницы между верхним и нижним регистром);
- -v : обратный поиск. Вывод строк, которые не соответствуют шаблону;
- -n : вывод номера строки для каждой из найденных строк;
- -w : сообщает grep’у, что шаблон должен совпадать со всем словом.
Итак, давайте теперь вернемся к анализу лог-файла почтового демона. Нам необходимо найти все строки в файле /var/log/mail/info , содержащие шаблон “postfix”. Для этого мы вводим такую команду:
Команда grep может быть использована в канале. Так мы можем получить такой же результат, что и в предыдущем примере, при помощи следующего:
Если нам нужно найти все строки, не содержащие шаблона “postfix”, нам надо будет воспользоваться опцией -v :
Давайте предположим, что нам необходимо найти все сообщения об успешно отправленных письмах. В этом случае мы должны отфильтровать все строки, добавленные почтовым демоном в файл журнала (содержащие шаблон “postfix”), и они должны содержать сообщение об успешной отправке (“status=sent”):
В этом случае команда grep использована дважды. Это разрешается, но не совсем красиво. Мы можем получить тот же результат при помощи утилиты fgrep . Сначала нам нужно создать файл, содержащий шаблоны, записанные в столбик. Такой файл может быть создан следующим образом (мы используем patterns.txt в качестве имени файла):
Затем мы вызываем следующую команду, в которой мы используем файл patterns.txt со списком шаблонов и утилиту fgrep вместо “двойного вызова” команды grep:
Файл ./patterns.txt может содержать сколько угодно шаблонов. Каждый из них должен быть введен в виде одной строки. Например, для выборки сообщений о письмах, успешно отправленных на адрес peter@mandrakesoft.com , достаточно будет добавить адрес этого электронного ящика в наш файл ./patterns.txt , выполнив следующую команду:
Понятное дело, что вы можете комбиноровать команду grep с tail и head . Если нам нужно найти сообщения о предпоследнем электроном письме, отправленном на адрес peter@mandrakesoft.com , мы используем:
Здесь мы применили описанный выше фильтр и отправили результат через канал в команды tail и head. Они выбрали из данных предпоследнее значение.
wc: Подсчёт элементов в файлах
Команда wc (Word Count — подсчёт слов) используется для подсчёта числа строк и слов в файлах. Она также полезна для подсчёта байтов, символов и длины самой длинной строки. Её синтаксис:
Список полезных опций:
- -l : вывод количества новых строк;
- -w : вывод количества слов;
- -m : вывод общего количества символов;
- -c : вывод количества байт;
- -L : вывод длины самой длинной строки в заданном тексте.
По умолчанию команда wc выводит количество новых строк, слов и символов. Вот несколько примеров использования:
Если нам нужно определить число пользователей в нашей системе, мы можем ввести:
Если нам нужно узнать число CPU в нашей системе, мы пишем:
В предыдущем разделе мы получили список сообщений об успешно отправленных письмах на адреса, перечисленные в нашем файле ./patterns.txt . Если нам нужно узнать количество таких сообщений, мы можем перенаправить наш отфильтрованный результат через канал в команду wc :
sort: Сортировка содержимого файла
Ниже представлен синтаксис этой можно утилиты для сортировки [16] :
Давайте отсортируем часть файла /etc/passwd . Как видите сам по себе этот файл не отсортирован:
Если нам нужно отсортировать его по полю login , мы набираем:
По умолчанию команда sort сортирует информацию по первому полю в порядке возрастания (в нашем случае по полю login ). Если нам нужно отсортировать данные в порядке убывания, мы используем опцию -r :
Для каждого пользователья имеется свой собственный UID , записанный в файле /etc/passwd . Давайте отсортируем этот файл в порядке возрастания по полю UID :
Здесь мы используем следующие опции sort:
- -t»:» : сообщает sort ‘у, что разделителем полей является символ «:» ;
- -k3 : означает, что сортировка должна быть выполнена по по третьему столбцу;
- -n : сообщает, что выполняется сортировка числовых данных, а не буквенных.
То же самое может быть выполнено в обратном порядке:
Обратите внимание, что sort обладает двумя важными опциями:
- -u : строгая сортировка: исключаются повторяющиеся поля сортировки;
- -f : игнорирование регистра (строчные символы обрабатываются так же, как и прописные).
И в заключение, если нам нужно найти пользователя с наивысшим UID , мы можем воспользоваться этой командой:
, где мы сортируем файл /etc/passwd в порядке возрастания по столбцу UID и прогоняем результат по каналу через команду tail , которая выводит первое значение из отсортированного списка.
[14] Некоторые примеры в этом разделе основаны на реальной работе с файлами журналов некоторых серверов (служб, демонов). Убедитесь, что у вас запущен syslogd (разрешает журналирование демонов), соответствующий демон (в нашем случае Postfix), и что вы в работаете под root ‘ом. И, естественно, вы всегда можете применять наши примеры к другим файлам.
[15] Например, файл /var/log/mail/info содержит информацию обо всех отправленных письмах, сообщениях о выборке почты пользователями по протоколу POP и т.д.
[16] Здесь мы только вкратце рассмотрим sort , потому что о её возможностях можно написать целую книгу.
Источник
linux-notes.org

Команда «head» в Unix или Linux системах используется для печати «N» линии из файла в терминал. Синтаксис команды head является таким:
Параметры команды head:
- c : Выводит первые «N» байт файла; С ведущим «-«, печатает все, кроме последних N байт файла.
- n : Выводит первые N строк; С ведущим «-«, печатает все, но последние N строк каждого файла.
Утилита head в примерах Unix/Linux.
В этой статье «Утилита head в примерах Unix/Linux» я расскажу как использовать утилиту head и на готовых примерах покажу как это работает.
Создайте следующий файл use_head.txt в операционной системе Linux или Unix для практикующих примеров со следующим содержанием:
Вывод первых 10 строк.
По умолчанию, команда head выводит первые 10 строк из файла:
Показать первые N строк.
Используйте опцию «-n», чтобы напечатать первые «N» строк из файла. Следующий пример выведет первые 2 строки из файла:
Пропустить последние N строк.
Вы можете пропустить последние N строк из файла и распечатать оставшиеся линии. В следующем примере я пропущу последние 2 строки и выведу оставшиеся строки:
Распечатать первые N байт.
Используйте опцию «-c», чтобы напечатать первые N байт из файла. Следующий пример печатает первые 4 байта из файла:
Пропустить вывод последних N байт.
Используйте ведущий параметр «-«, чтобы пропустить вывод последних N байт:
Вывести строки между М и N линиями.
Вы можете комбинировать команду head и выводить строки с определенным диапазоном M и N. Следующая команда выведет строки между 4-й и 9-й строкой:
Моя тема «Утилита head в примерах Unix/Linux» подошла к завершению.
Источник
Просмотр содержимого файлов в командной строке Linux

Рассмотрим несколько команд, которые используются для просмотра содержимого текстовых файлов в командной строке Linux.
Команда cat
Команда cat выводит содержимое файла, который передается ей в качестве аргумента.
Это самый простой и наиболее часто используемый способ для вывода содержимого текстовых файлов. Но выводить большие файлы через cat не всегда удобно.
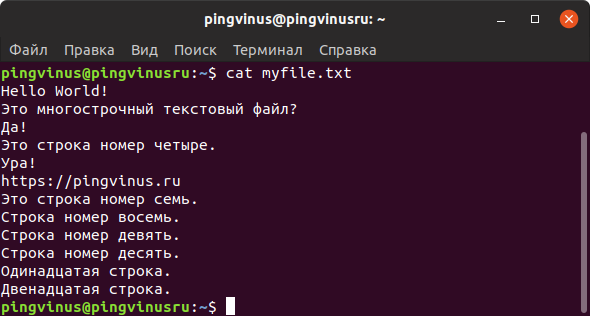
Команда nl
Команда nl действует аналогично команде cat , но выводит еще и номера строк в столбце слева.
Команду nl удобно применять для просмотра программного кода или поиска строк в файлах конфигурации.
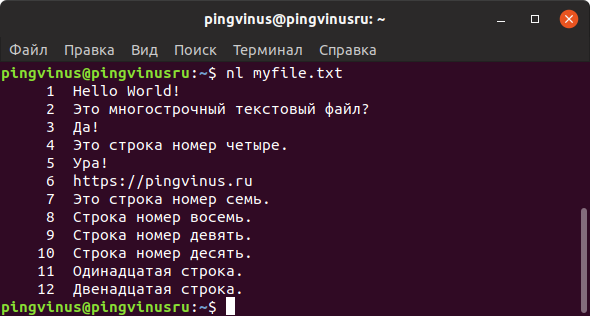
Команда less
Утилита less выводит содержимое файла, но отображает его только в рамках текущего окна в режиме просмотра.
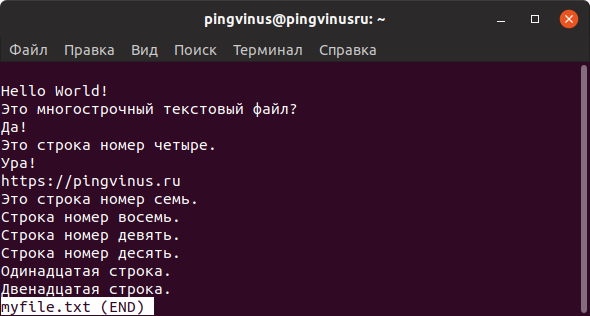
Вы можете прокручивать текст файла клавишами стрелок или перелистывать страницы клавишами w и z .
Для поиска текста внутри файла нажмите / .
Для просмотра списка доступных горячих клавиш нажмите h
Чтобы выйти из режима просмотра используется клавиша q .
Очень удобно, что после выхода окно терминала остается чистым и не содержит текст файла.
Команда more
Команда more очень похожа на команду less . Она также выводит файл в терминале в режиме просмотра, но имеет некоторые отличия от команды less.
Например, less в конце файла выводит сообщение (END) (или EOF — End Of File) и ожидает нажатия клавиши q чтобы закрыть режим просмотра, а more по достижении конца файла сразу возвращает управление в терминал.
Также more после своей работы оставляет текст файла в терминале, а less работает «чисто» и не сохраняет текст в терминале.
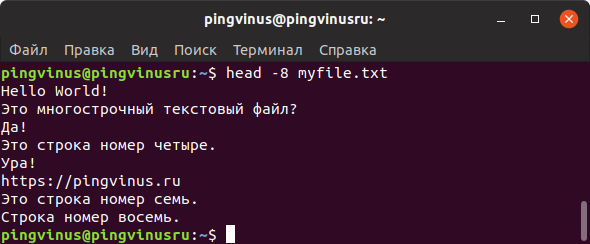
Команда head
Команда head выводит на экран только первые 10 строк файла.
Используя опцию -n можно задать количество строк, которое нужно вывести. Например, чтобы вывести 15 строк используется команда:
Вместо -n можно просто использовать знак минус — , за которым сразу указывается количество строк.
Команда tail
Команда tail аналогична команде head , но выводит последние 10 строк файла.
Заключение
Команды, которые мы рассмотрели, имеют дополнительные возможности и области применения. Для получения справки по каждой команде можно воспользоваться Man-страницами.
Источник



