- Логирование в Python
- Создаем простой логгер
- Логи в Python. Настройка и централизация
- Введение
- Основы
- Базовый пример
- Подробности
- Конфигурирование
- fileConfig
- Логирование исключений
- Перехват необработанных исключений
- Унификация
- Логирование в JSON
- Пользовательские атрибуты
- Логи и другие источники данных
- Заключение
- 8 продвинутых возможностей модуля logging в Python, которые вы не должны пропустить
- Основы модуля logging
- Логгер
- Форматировщик и обработчик
- 1. Создавайте заданные пользователем атрибуты объектов класса LogRecord, используя класс LoggerAdapter
- Новый атрибут с фиксированным значением
- Новый атрибут с динамическим значением
- 2. Создавайте определенные пользователем атрибуты объектов класса LogRecord, используя класс Filter
- 3. Многопоточность с модулем logging
- 4. Многопроцессная обработка с модулем logging — QueueHandler
- QueueHandler + «процесс-потребитель»
- QueueHandler + QueueListener
- SocketHandler
- 5. По умолчанию не генерируйте какие-либо журнальные записи библиотеки — NullHandler
- Почему нам нужно отделять записи библиотеки от записей приложения?
- 6. Делайте ротацию своих файлов журнала — RotatingFileHandler, TimedRotatingFileHandler
- 7. Исключения в процессе журналирования
- 8. Три разных способа конфигурирования своего логгера
- используйте код
- use dictConfig
- используйте fileConfig
Логирование в Python

Python предлагает весьма сильную библиотеку логирования в стандартной библиотеке. Многие программисты используют оператор print для лечения багов (в том числе и я), но вы можете использовать логирование для этих целей. Использование лога также более чистый метод, если вы не хотите просматривать весь свой код, чтобы удалить все операторы print. В данном разделе мы рассмотрим следующее:
- Создание простого логгера;
- Использование нескольких модулей для логирования;
- Форматирование лога;
- Настройки лога
К концу данного раздела вы сможете уверенно создавать логи для своих приложений. Приступим!
Создаем простой логгер
Создание лога при помощи модуля logging это очень просто. Для начала, будет проще взглянуть на часть кода и объяснить его:
Как и ожидалось, чтобы получит доступ к модулю logging, для начала нужно импортировать модуль. Простейший способ создания лога – это использовать функцию basicConfig модуля logging и передать ей несколько ключевых аргументов. Функция принимает следующее: filename, filemode, format, datefmt, level и stream. В нашем примере, мы передадим её названию файла и уровню логирования, что мы и настроим в INFO.
Существует пять уровней логирования (в порядке возрастания): DEBUG, INFO, WARNING, ERROR и CRITICAL. По умолчанию, если вы запустите этот код несколько раз, он добавится в лог, если он существует. Если вы хотите, чтобы ваш логгер перезаписывал лог, передайте его filemode=”w”, как было указано в комментарии к коду. Говоря о запуске кода, вы должны получить следующий результат, после запуска:
Источник
Логи в Python. Настройка и централизация

Dec 21, 2019 · 9 min read

Введение
Встроенный в Python модуль логирования разработан для того, чтобы дать вам детальное представление о приложениях с минимальными настройками. Начинаете ли вы работу или уже работаете, в руководстве вы увидите, как настроить этот модуль, чтобы помочь найти нужную строку кода.
В этом посте мы покажем вам, как:
- Настроить приоритет и расположение журналов.
Создать пользовательские настройки, включающие несколько логгеров и адресатов. - Добавить трассировку исключений в логи.
- Отформатировать логи в JSON и централизовать их.
Основы
Модуль logging включен в стандартную библиотеку Python . Метод basicConfig() — самый быстрый способ настройки. Тем не менее в документации рекомендуется создавать логгер для каждого модуля приложения, а значит, может быть сложно конфигурировать логгер для каждого модуля, используя только basicConfig() . Поэтому большинство приложений (включая веб-фреймворки, например, Django) автоматически ведут журналы на основе файлов или словаря. Если вы хотите начать с одного из этих методов, мы рекомендуем сразу перейти к нужному разделу.
У basicConfig() три основных параметра:
- level: минимальный уровень логирования. Доступны уровни: DEBUG , INFO , WARNING , ERROR и CRITICAL . Уровень по умолчанию — WARNING, то есть фильтруются сообщения уровней DEBUG и INFO .
- handler: определяет, куда направить логи. Если не указано иное, используется StreamHandler для направления сообщений в sys.stderr .
- format: формат, по умолчанию он такой:
В следующем разделе мы покажем, как настроить его, чтобы включить метки времени и другую полезную информацию.
Поскольку по умолчанию пишутся только журналы WARNING и более высокого уровня, вам может не хватать логов с низким приоритетом. Кроме того, вместо StreamHandler или SocketHandler для потоковой передачи непосредственно на консоль или во внешнюю службу по сети, вам лучше использовать FileHandler , чтобы писать в один или несколько файлов на диске.
Если при передаче по сети возникнут проблемы, то у вас не будет свободного доступа к этим логам: они будут храниться на каждом сервере локально. Логирование в файл позволяет создавать разные типы логов и объединять их службой мониторинга.
Базовый пример
В следующем примере используется basicConfig() , чтобы сконфигурировать приложение для логирования DEBUG и выше на диск, и указывается на наличие даты, времени и серьёзности в строке лога:
Если на входе будет недоступный файл, в лог запишется это:
Благодаря новой конфигурации сообщения отладки не фильтруются и, кроме сообщения об ошибке, дают информацию о дате, местном времени и уровне важности:
- %(asctime)s : дата и местное время.
- %(levelname)s : уровень.
- %(message)s : сообщение.
Здесь информация о стандартных атрибутах. В примере выше логирование не включает трассировку, затрудняя определение источника проблемы. Ниже мы покажем логирование трассировки исключений.
Подробности
Что делать, когда приложение разрастается? Вам нужна надёжная, масштабируемая конфигурация и имя логгера как часть каждого лога. В этой части мы:
- Настроим множественное логирование с отображением имени лога.
- Используем fileConfig , чтобы реализовать пользовательское логирование и роутинг.
- Запишем в лог трассировку и необработанные исключения.
Конфигурирование
Следуя лучшим практикам, используем метод получения имени лога модуля:
__name__ ссылается на полное имя модуля, из которого вызван метод getLogger . Это вносит ясность. Например, приложение включает lowermodule.py , вызываемый из uppermodule.py . Тогда getLogger(__name__) выведет имя ассоциированного модуля. Пример с форматом лога, включающим его имя:
Последовательный запуск uppermodule.py для существующего и не существующего файлов даст такой вывод:
Имя модуля логгера следует сразу за временной меткой. Если вы не использовали getLogger , имя модуля отображается как root , затрудняя определение источника. uppermodule.py отображается как __main__ (основной) потому, что это модуль верхнего уровня.
Сейчас два лога настраиваются двумя вызовами basicConfig . Далее мы покажем, как настроить множество логов с одним вызовом fileConfig.
fileConfig
fileConfig и dictConfig позволяют реализовать более гибкое логирование на основе файлов или словаря. Оно используется в Django и Flask. В файле конфигурации должны быть три секции:
- [loggers] — имена логгеров.
- [handlers] — типы обработчиков: fileHandler , consoleHander .
- [formatters] — форматы логов.
Каждая секция должна иметь списки. Уточняющие секции ключей (например, для определённого типа обработчика) должны иметь такой формат: [ _ ] . Файл logging.ini может выглядеть так:
Документация рекомендует прикреплять каждый обработчик к одному логу, прописывать основные настройки в корневом (root) логе и уточнять их в дочерних, а не дублировать одно и то же в дочерних логах. Подробнее в документации. В этом примере мы указали в root настройки для обоих логов, что избавило нас от дублирования кода.
Вместо logging.basicConfig(level=logging.DEBUG, format=’%(asctime)s %(name)s %(levelname)s:%(message)s’) в каждом модуле мы можем сделать так:
Этот код отключает существующие не корневые логгеры, включенные по умолчанию. Не забудьте импортировать logging.config . Кроме того, посмотрите в документацию логирования на основе словаря.
Логирование исключений
Чтобы logging.error перехватывала трассировку, установите sys.exc_info в True . Ниже пример с включенным и отключенным параметром:
Вывод для несуществующего файла:
Первая строка — вывод без трассировки, вторая и далее — с трассировкой. Кроме того, с помощью logger.exception вы можете логировать определённое исключение без дополнительных вмешательств в код.
Перехват необработанных исключений
Вы не можете предвидеть и обработать все исключения, но можете логировать необработанные исключения, чтобы исследовать их позже.
Необработанное исключение возникает вне try. except или, когда вы не включаете нужный тип исключения в except . Например, если приложение обнаруживает TypeError , а ваш except обрабатывает только NameError , исключение передаётся в другие try , пока не встретит нужный тип.
Если ничего не встретилось, исключение становится необработанным. Интерпретатор вызывает sys.excepthook с тремя аргументами: класс исключения, его экземпляр и трассировка. Эта информация обычно появляется в sys.stderr , но если вы настроили свой лог для вывода в файл, traceback не логируется.
Вы можете использовать стандартную библиотеку traceback для форматирования трассировки и её включения в лог. Перепишем word_count() так, чтобы она пыталась записать количество слов в файл. Неверное число аргументов в write() вызовет исключение:
При выполнении этого кода возникнет TypeError , не обрабатываемое в try-except . Однако оно логируется благодаря коду, включенному во второе выражение except :
Логирование трассировки обеспечивает критическую видимость ошибок в реальном времени. Вы можете исследовать, когда и почему они произошли.
Многострочные исключения легко читаются, но если вы объединяете свои журналы с внешним сервисом, то далее можно преобразовать их в JSON, чтобы гарантировать корректный анализ. Теперь мы покажем, как использовать для этого python-json-logger .
Унификация
В этом разделе мы покажем, как форматировать журналы в JSON, добавлять пользовательские атрибуты, а также централизовывать и анализировать данные.
Логирование в JSON
Со временем поиск лога станет сложной задачей, особенно если логи распределены между серверами, сервисами и файлами. Если вы централизовали логи с помощью, то будете знать, где искать, а не входить вручную на каждый сервер.
JSON — лучшая практика для централизации с помощью сервиса управления: компьютеры легко анализируют этот стандартный структурированный формат. В JSON логах легко обращаться с атрибутами: не нужно обновлять конвейеры обработки при их добавлении или удалении.
Сообщество Python разработало библиотеки, конвертирующие логи в JSON. Используем python-json-logger . Установка:
Теперь обновите файл конфигурации для настройки существующего модуля форматирования или добавления нового, ( [formatter_json] в примере ниже). Он должен использовать pythonjsonlogger.jsonlogger.JsonFormatter . В разделе format можно указать атрибуты, необходимые каждой записи:
Консольные логи по-прежнему соответствуют simpleFormatter для удобства чтения, но логи, созданные логгером lowermodule , теперь пишутся в JSON.
При включении pythonjsonlogger.jsonlogger.JsonFormatter в конфигурацию функция fileConfig() должна иметь возможность создавать JsonFormatter , пока выполняется код из среды, где импортируется pythonjsonlogger .
Если вы не используете файловую конфигурацию, нужно импортировать python-json-logger , а также определить обработчик и модуль форматирования, как описано в документации:
Почему JSON предпочтительнее, особенно когда речь идёт о сложных или подробных записях? Вернёмся к примеру многострочной трассировки:
Этот лог легко читать в файле или в консоли. Но если он обрабатывается платформой управления и правила многострочного агрегирования не настроены, то каждая строка может отображаться как отдельный лог. Это затруднит точное восстановление событий. Теперь, когда мы логируем трассировку исключений в JSON, приложение создаёт единый журнал:
Сервис логирования может легко интерпретировать этот JSON и показать всю информацию о трассировке, включая exc_info :

Пользовательские атрибуты
Еще одно преимущество — добавления атрибутов, анализируемых внешним сервисом управления автоматически. Ранее мы настроили format для стандартных атрибутов. Можно логировать пользовательские атрибуты, используя поле python-json-logs . Ниже мы создали атрибут, отслеживающий продолжительность операции в секундах:
В системе управления атрибуты анализируются так:
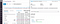
Если вы используете платформу мониторинга, то можете построить график и предупредить о большом run_duration . Вы также можете экспортировать этот график на панель мониторинга, когда захотите визуализировать его рядом с производительностью:
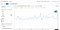
Используете вы python-json-logger или другую библиотеку для форматирования, вы можете легко настроить логи для включения информации, анализируемой внешней платформой управления.
Логи и другие источники данных
После такой централизации вы можете начать изучать логи вместе с распределенными трассировками запросов и метриками инфраструктуры. Такие службы, как Datadog, могут соединять журналы с метриками и данными мониторинга производительности, чтобы помочь вам увидеть полную картину.
Если вы обновите формат для включения dd.trace_iddd.span_id , система управления автоматически сопоставит журналы и трассировки каждого запроса. Это означает, что при просмотре трассировки вы можете просто щелкнуть вкладку “логи” в представлении трассировки, чтобы просмотреть все логи, созданные во время конкретного запроса:
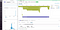
Можно перемещаться в другом направлении: от журнала к трассировке создавшего журнал запроса. Смотрите нашу документацию для получения более подробной информации об автоматической корреляции логов и трассировок для быстрого устранения неполадок.
Заключение
Мы рассмотрели рекомендации по настройке стандартной библиотеки логирования Python для создания информативных логов, их маршрутизации и перехвата трассировок исключений. Также мы увидели, как централизовать и анализировать логи в JSON с помощью платформы управления логами.
Источник
8 продвинутых возможностей модуля logging в Python, которые вы не должны пропустить
Понимайте свою программу без ущерба для производительности

Журналирование — это очень важная часть разработки ПО. Оно помогает разработчикам лучше понимать выполнение программы и судить о дефектах и непредвиденных сбоях. Журнальное сообщение может хранить информацию наподобие текущего статуса программы или того, в каком месте она выполняется. Если происходит ошибка, то разработчики могут быстро найти строку кода, которая вызвала проблему, и действовать с учетом этого.
Python предоставляет довольно мощный и гибкий встроенный модуль logging со множеством возможностей. В этой статье я хочу поделиться восемью продвинутыми возможностями, которые будут полезны при разработке ПО.
Основы модуля logging
Прежде чем приступить к рассмотрению продвинутых возможностей, давайте убедимся, что у нас есть базовое понимание модуля logging.
Логгер
Экземпляр, который мы создаем для генерации записей, называют логгером. Он инстанциируется через logger = logging.getLogger(name). Лучшая практика — это использовать name в качестве имени логгера. name включает в себя имя пакета и имя модуля. Имя будет появляться в журнальном сообщении, что поможет разработчикам быстро находить, где оно было сгенерировано.
Форматировщик и обработчик
У любого логгера есть несколько конфигураций, которые могут быть модифицированы. Более продвинутые конфигурации мы обсудим позже, а наиболее ходовые — это форматировщик (прим. пер.: formatter) и обработчик (прим. пер.: handler).
Форматировщик устанавливает структуру журнального сообщения. Каждое журнальное сообщение — это объект класса LogRecord с несколькими атрибутами (имя модуля — один из них). Когда мы определяем форматировщик, мы можем решить, как должно выглядеть журнальное сообщение вместе с этими атрибутами и, возможно, с атрибутами, созданными нами. Стандартный форматировщик выглядит так:
Кастомизированный форматировщик может выглядеть так:
Обработчик задает целевое местонахождение журнальных сообщений. Журнальное сообщение может быть отправлено в более чем одно место. Собственно говоря, модуль logging предоставляет довольно много стандартных обработчиков. Самые популярные — FileHandler, который отправляет записи в файл, и StreamHandler, который отправляет записи в потоки, такие как sys.stderr или sys.stdout. Экземпляр логгера поддерживает ноль или более обработчиков. Если никакие обработчики не определены, тогда он будет отправлять записи в sys.stderr. Если определен более чем один обработчик, тогда целевое местонахождение журнального сообщения зависит от его уровня и от уровня обработчика.
Например, у меня есть FileHandler с уровнем WARNING (прим. пер.: предупреждение) и StreamHandler с уровнем INFO (прим. пер.: информация). Если я напишу в журнал сообщение об ошибке, то оно будет отправлено как в sys.stdout, так и в файл журнала.
Например:
В этом примере мы создали main.py, package1.py, и app_logger.py. Модуль app_logger.py содержит функцию get_logger, которая возвращает экземпляр логгера. Экземпляр логгера включает в себя кастомный форматировщик и два обработчика: StreamHandler с уровнем INFO и FileHandler с уровнем WARNING. Важно установить базовый уровень в INFO или DEBUG (уровень журналирования по умолчанию — WARNING), в противном случае любые записи журнала по уровню ниже, чем WARNING, будут отфильтрованы. И main.py, и package1.py, используют get_logger, чтобы создавать свои собственные логгеры.

Диаграмма Xiaoxu Gao
Записи с уровнем INFO отправляются как в консольный вывод (sys.stdout), так и в файл журнала, а записи с уровнем WARNING пишутся только в файл журнала. Если вы можете полностью понять, что и почему происходит в этом примере, то мы готовы приступить к более продвинутым возможностям.
1. Создавайте заданные пользователем атрибуты объектов класса LogRecord, используя класс LoggerAdapter
Как я упоминал ранее, у LogRecord есть несколько атрибутов. Разработчики могут выбрать наиболее важные атрибуты и использовать в форматировщике. Помимо того, модуль logging также предоставляет возможность добавить в LogRecord определенные пользователем атрибуты.
Один из способов сделать это — использовать LoggerAdapter. Когда вы создаете адаптер, вы передаете ему экземпляр логгера и свои атрибуты (в словаре). Этот класс предоставляет тот же интерфейс, что и класс Logger, поэтому вы все еще можете вызывать методы наподобие logger.info.
Новый атрибут с фиксированным значением
Если вы хотите иметь что-то вроде атрибута с фиксированным значением в журнальном сообщении, например имя приложения, то вы можете использовать стандартный класс LoggerAdapter и получать значение атрибута при создании логгера (прим. пер.: вероятно, получать откуда-либо, чтобы затем передать конструктору). Не забывайте добавлять этот атрибут в форматировщик. Местоположение атрибута вы можете выбрать по своему усмотрению. В следующем коде я добавляю атрибут app, значение которого определяется, когда я создаю логгер.
Новый атрибут с динамическим значением
В других ситуациях вам, возможно, понадобятся динамические атрибуты, например что-то вроде динамического идентификатора. В таком случае вы можете расширить базовый класс LoggerAdapter и создать свой собственный. Метод process() — то место, где дополнительные атрибуты добавляются к журнальному сообщению. В коде ниже я добавляю динамический атрибут id, который может быть разным в каждом журнальном сообщении. В этом случае вам не нужно добавлять атрибут в форматировщик.
2. Создавайте определенные пользователем атрибуты объектов класса LogRecord, используя класс Filter
Другой способ добавления определенных пользователем атрибутов — использование кастомного Filter. Фильтры предоставляют дополнительную логику для определения того, какие журнальные сообщения выводить. Это шаг после проверки базового уровня журналирования, но до передачи журнального сообщения обработчикам. В дополнение к определению, должно ли журнальное сообщение двигаться дальше, мы также можем вставить новые атрибуты в методе filter().
Диаграмма из официальной документации Python
В этом примере мы добавляем новый атрибут color (прим. пер.: цвет) в методе filter(), значение которого определяется на основе имени уровня в журнальном сообщении. В этом случае имя атрибута снова должно быть добавлено в форматировщик.
3. Многопоточность с модулем logging
Модуль logging на самом деле реализован потокобезопасным способом, поэтому нам не нужны дополнительные усилия. Код ниже показывает, что MainThread и WorkThread разделяют один и тот же экземпляр логгера без проблемы состояния гонки. Также есть встроенный атрибут threadName для форматировщика.
Под капотом модуль logging использует threading.RLock() практически везде. Отличия между RLock от Lock:
Lock может быть получен только один раз и больше не может быть получен до тех пор, пока он не будет освобожден. С другой стороны, RLock может быть получен неоднократно до своего освобождения, но он должен быть освобожден столько же раз.
Lock может быть освобожден любым потоком, а RLock — только тем потоком, который его удерживает.
Любой обработчик, который наследуется от класса Handler, обладает методом handle(), предназначенным для генерации записей. Ниже представлен блок кода метода Handler.handle(). Как видите, обработчик получит и освободит блокировку до и после генерации записи соответственно. Метод emit() может быть реализован по-разному в разных обработчиках.
4. Многопроцессная обработка с модулем logging — QueueHandler
Несмотря на то, что модуль logging потокобезопасен, он не процессобезопасен. Если вы хотите, чтобы несколько процессов вели запись в один и тот же файл журнала, то вы должны вручную позаботиться о доступе к вашему файлу. В соответствии с учебником по logging, есть несколько вариантов.
QueueHandler + «процесс-потребитель»
Один из вариантов — использование QueueHandler. Идея заключается в том, чтобы создать экземпляр класса multiprocessing.Queue и поделить его между любым количеством процессов. В примере ниже у нас есть 2 «процесса-производителя», которые отправляют записи журнала в очередь и «процесс-потребитель», читающий записи из очереди и пишущий их в файл журнала.
У записей журнала в очереди будут, вероятно, разные уровни, так что в функции log_processor мы используем logger.log(record.levelno, record.msg) вместо logger.info() или logger.warning(). В конце (прим. пер.: функции main) мы отправляем сигнал, чтобы позволить процессу log_processor остановиться. Деление экземпляра очереди между множеством процессов или потоков — не новшество, но модуль logging как бы помогает нам справиться с этой ситуацией.
QueueHandler + QueueListener
В модуле logging.handlers есть особый класс с именем QueueListener. Этот класс создает экземпляр слушателя с очередью журнальных сообщений и списком обработчиков для обработки записей журнала. QueueListener может заменить процесс, который мы создали в предыдущем примере, поместив его в переменную listener. При этом будет использовано меньше кода.
SocketHandler
Другое решение, предлагаемое учебником, — отправлять записи из нескольких процессов в SocketHandler и иметь отдельный процесс, который реализует сокет-сервер, читающий записи и отправляющий их в место назначения. В этих источниках есть довольно подробная реализация.
Все эти решения, в основном, следуют одному принципу: отправлять записи из разных процессов в централизованное место — либо в очередь, либо на удаленный сервер. Получатель на другой стороне ответственен за их запись в места назначения.
5. По умолчанию не генерируйте какие-либо журнальные записи библиотеки — NullHandler
На данный момент мы упомянули несколько обработчиков, реализованных модулем logging.
Другой полезный встроенный обработчик — NullHandler. В реализации NullHandler практически ничего нет. Тем не менее, он помогает разработчикам отделить библиотечные записи журнала от записей приложения.
Ниже приведена реализация обработчика NullHandler.
Почему нам нужно отделять записи библиотеки от записей приложения?
Сторонняя библиотека, которая использует logging, по умолчанию не должна выбрасывать вывод журналирования, так как он может быть не нужен разработчику/пользователю приложения, которое использует библиотеку.
Наилучшая практика — по умолчанию не генерировать библиотечные записи журнала и давать пользователю библиотеки возможность решить, хочет ли он получать и обрабатывать эти записи в приложении.
В роли разработчика библиотеки нам нужна только одна строка кода внутри init.py, чтобы добавить NullHandler. Во вложенных пакетах и модулях логгеры остаются прежними. Когда мы устанавливаем этот пакет в наше приложение через pip install, мы по умолчанию не увидим библиотечные записи журнала.
Чтобы сделать эти записи видимыми, нужно добавить обработчики в логгер библиотеки в своем приложении.
Если библиотека не использует NullHandler, но вы хотите отключить записи из библиотеки, то можете установить logging.getLogger(«package»).propagate = False. Если propagate установлен в False, то записи журнала не будут передаваться обработчикам.
6. Делайте ротацию своих файлов журнала — RotatingFileHandler, TimedRotatingFileHandler
RotatingFileHandler поддерживает ротацию файлов журнала, основанную на максимальном размере файла. Здесь должны быть определено два параметра: maxBytes и backupCount. Параметр maxBytes сообщает обработчику, когда делать ротацию журнала. Параметр backupCount — количество файлов журнала. У каждого «продолженного» файла журнала есть суффикс «.1», «.2» в конце имени файла. Если текущее журнальное сообщение вот-вот позволит файлу журнала превысить максимальный размер, то обработчик закроет текущий файл и откроет следующий.
Вот этот пример очень похож на пример из учебника. Должно получиться 6 файлов журнала.
Другой обработчик для ротации файлов — TimeRotatingFileHandler, который позволяет разработчикам создавать ротационные журналы, основываясь на истекшем времени. Условия времени включают: секунду, минуту, час, день, день недели (0=Понедельник) и полночь (журнал продлевается в полночь).
В следующем примере мы делаем ротацию файла журнала каждую секунду с пятью резервными файлами. В каждом резервном файле есть временная метка в качестве суффикса.
7. Исключения в процессе журналирования
Зачастую мы используем logger.error() или logger.exception() при обработке исключений. Но что если сам логгер генерирует исключение? Что случится с программой? Ну, зависит от обстоятельств.
Ошибка логгера обрабатывается, когда обработчик вызывает метод emit(). Это означает, что любое исключение, связанное с форматированием или записью, перехватывается обработчиком, а не поднимается. Если конкретнее, метод handleError() будет выводить трассировку в stderr, и программа продолжится. Если у вас есть кастомный обработчик, наследуемый от класса Handler, то вы можете реализовать свой собственный handleError().
В этом примере во втором журнальном сообщении слишком много аргументов. Поэтому в консольном выводе мы получили трассировку, и выполнение программы все еще могло быть продолжено.
Однако, если исключение произошло за пределами emit(), то оно может быть поднято, и программа остановится. Например, в коде ниже мы добавляем дополнительный атрибут id в logger.info без его обработки в LoggerAdapter. Эта ошибка не обработана и приводит к остановке программы.
8. Три разных способа конфигурирования своего логгера
Последний пункт, которым я хотел поделиться, — о конфигурировании своего логгера. Есть три способа конфигурирования логгера.
используйте код
Самый простой вариант — использовать код для конфигурирования своего логгера, так же, как во всех примерах, что мы видели ранее в этой статье. Но недостаток этого варианта в том, что любая модификация (прим. пер.: конфигурации) требует внесения изменений в исходном коде.
use dictConfig
Второй вариант — записывать конфигурацию в словарь и использовать logging.config.dictConfig, чтобы читать ее. Вы также можете сохранить словарь в JSON-файл и читать оттуда. Плюс в том, что этот файл может быть загружен как внешняя конфигурация, но он может способствовать появлению ошибок из-за своей структуры.
используйте fileConfig
И последний, но не менее важный, третий вариант — использовать logging.config.fileConfig Конфигурация записывается в отдельный файл формата .ini.
Есть возможность обновлять конфигурацию во время выполнения программы через сервер конфигурации. Учебник показывает пример как со стороны клиента, так и со стороны сервера. Конфигурация обновляется посредством подключения через сокет, а на стороне клиента мы используем c = logging.config.listen(PORT) c.start(), чтобы получать самую новую конфигурацию.
Надеюсь, эти советы и приемы, связанные с модулем logging, могут помочь вам создать вокруг вашего приложения хороший фреймворк для журналирования без ущерба для производительности. Если у вас есть что-нибудь, чем можно поделиться, пожалуйста, оставьте комментарий ниже!
Источник



