- Получаем информацию о железе сервера в Linux
- Информация об оперативной памяти (RAM) в Linux
- Как узнать информацию о процессоре (CPU) в Linux?
- Информация о жестких дисках сервера в Linux
- Утилита dmidecode: получения информации о материнской плате, BIOS и др.
- Linux: How to get CPU and memory information
- How to show the Linux CPU/processor
- How to show Linux memory information
- Linux processor command output
- Linux memory information command
- Summary: Linux processor and memory commands
- 5 commands to check memory usage on Linux
- Memory Usage
- 1. free command
- 2. /proc/meminfo
- 3. vmstat
- 4. top command
- 5. htop
- RAM Information
- Summary
- 66 thoughts on “ 5 commands to check memory usage on Linux ”
- Как Linux работает с памятью. Семинар в Яндексе
- Термины
- Страницы памяти
- Memory Zones и NUMA
- Page Cache
- Память процесса
- Выделение памяти
- Работа с файлами и с памятью
- Readahead
- Источники пополнения Free List
Получаем информацию о железе сервера в Linux
Вы можете узнать, какое железо установлено в вашем сервере из BIOS/UEFI, или через отдельный управляющий интерфейс сервера, который есть у большинства промышленных серверов (HPE ILO, Dell iDRAC, IBM BMC, IPMI и т.д.). А что делать, если у сервера нет интерфейса управления (или он не доступен), а перезагружать сервер перезагружать не желательно? В этой статье на примере CentOS мы рассмотрим основные команды и утилиты Linux, которые позволят получить подробные сведения об аппаратном обеспечении сервера: оперативной памяти, процессоре, жестких дисках, материнской плате и настройках BIOS.
Информация об оперативной памяти (RAM) в Linux
Вы можете получить информацию о количестве оперативной памяти на сервере с помощь встроенных средств Linux CentOS (данные команды не дают подробной информации, но вполне приемлемы для быстрой оценки).
Первая покажет количество памяти в мегабайтах, вторая в гигабайтах (информация о количестве оперативной памяти указано в значении Mem: total).
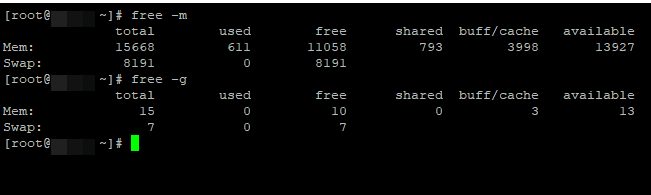
Тут же будет и показан размер swap.
Также вы можете получить информацию о RAM из файла /proc/meminfo:
# grep MemTotal /proc/meminfo
# grep SwapTotal /proc/meminfo
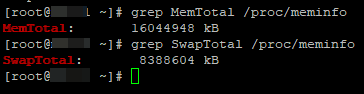
Первый вариант на мой взгляд удобнее, так как вы сразу видите и используемую память, и свободную.
Так же существует еще несколько вариантов проверки количества ОЗУ на сервере:
Vmstat показывает не только физическую память сервера, но и всю статистику по виртуальной памяти.
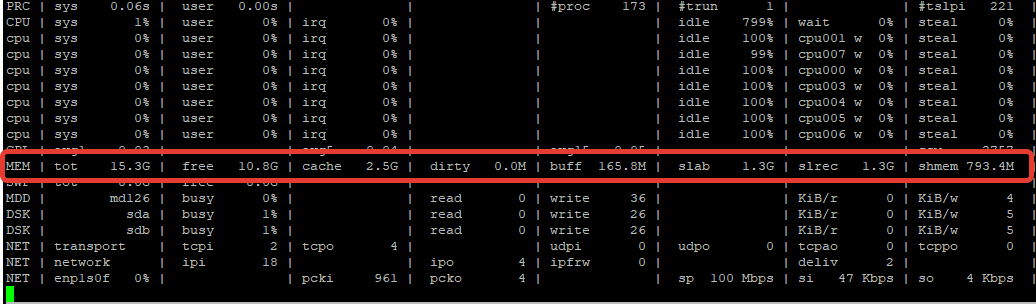
Либо запустите команду top и посмотрите информацию о RAM в самом верхнем блоке:
Так же, есть удобная утилита atop, которая покажет вам количество ОЗУ на сервере, а также информацию по занятой, кешированной и свободной памяти.
Вы можете установить утилиту atop из EPEL репозитория с помощью yum (dnf):
# yum install atop -y
Должна быть в вашем арсенале и не менее удобная утилита nmon. Установите ее на сервер:
# yum install nmon -y
Выполните команду nmon, и для проверки ОЗУ нажмите m:
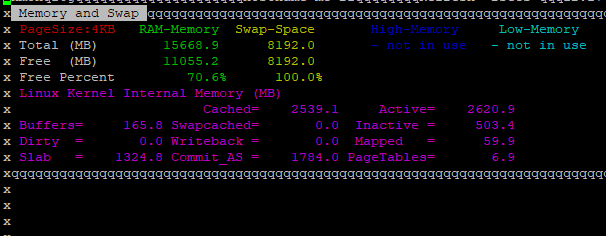
Но все вышеперечисленные утилиты, показывают лишь объем памяти, а модель скорость и другие характеристики нет. Если нужна более подробная информация о бланках памяти (производитель, тип, частота), можно воспользоваться утилитой dmidecode:
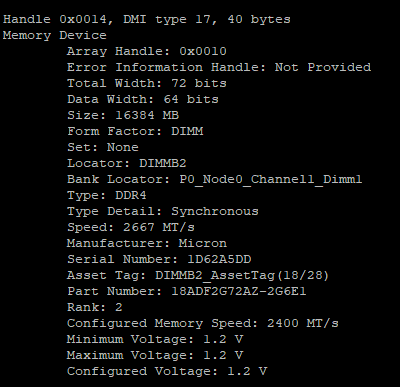
Как видите, dmidecode выводит более подробную информацию о установленных модулях памяти.
Как узнать информацию о процессоре (CPU) в Linux?
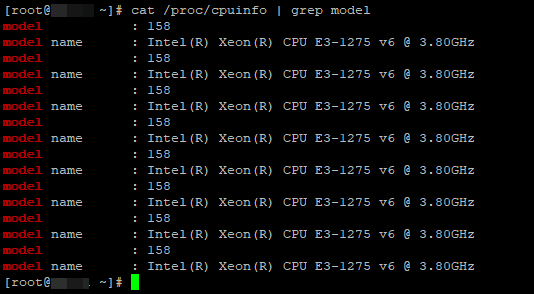
Информацию о процессоре в Linux можно получить несколькими способами. Начнем с самого простого — получение информации из файла /proc/cpuinfo:
# cat /proc/cpuinfo | grep model
Чтобы узнать количество ядер, выполните:
# cat /proc/cpuinfo | grep processor
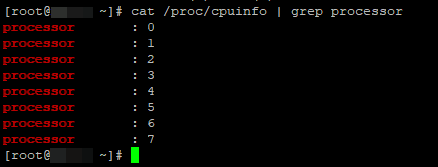
В моем случае на сервере 8 ядер.
Более подробную информацию о процессоре, можно узнать командой lscpu:
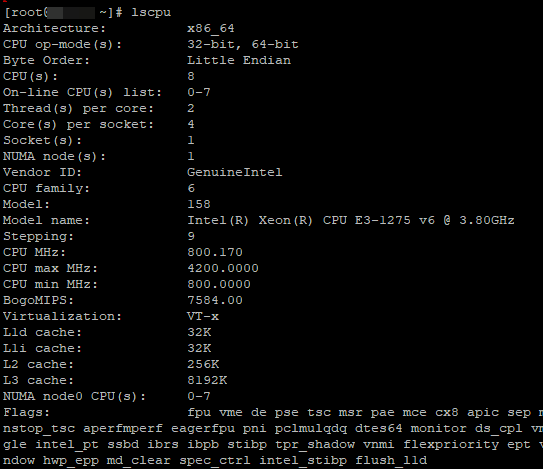
Утилита lscpu покажет вам количество ядер, модель процессора, максимальную частоту, рамеры кэшей CPU, ноды NUMA и многое другое.
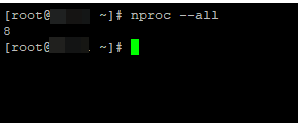
Количество ядер, так же можно узнать запустив команду atop или nproc —all:

Для отображения подробной информации, можно дополнительно установить утилиту cpuid:
# yum install cpuid -y
После установки запустите командой:
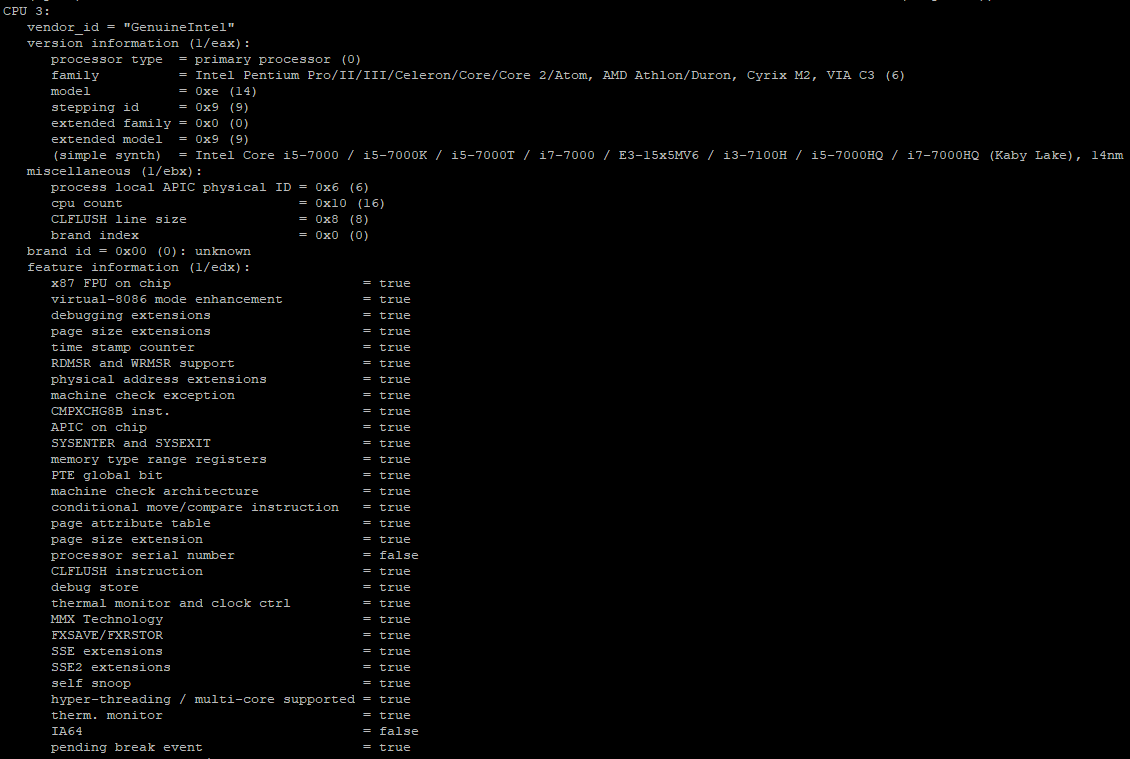
Вы получите информацию не только о модели процессора, но тип и семейство процессора, конфигурацию кеша, функцию управления питанием и другое.
С помощью утилиты demidecodev вы так же можете узнать всю информацию об установленных на сервере процессорах:
# dmidecode —type processor
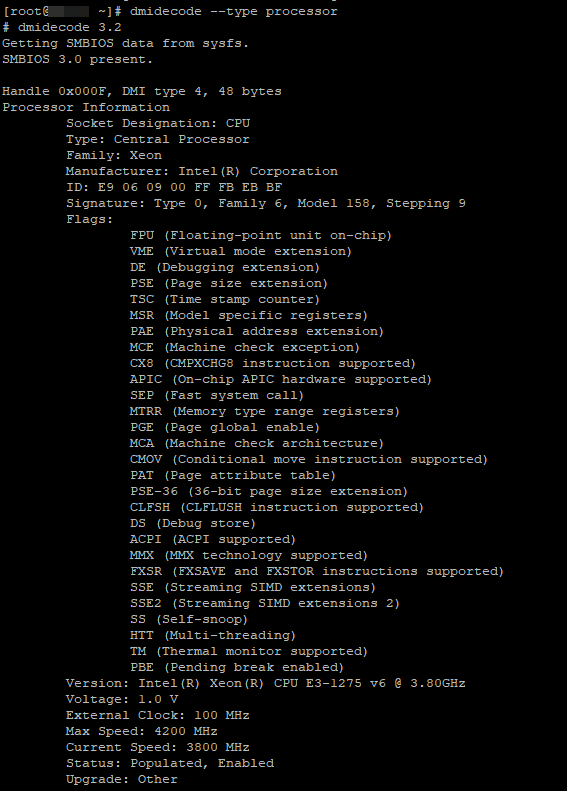
И, пожалуй, последняя утилита для проверки процессора inxi. Это скрипт на bash, который покажет вам модель процессора, размер кеша, частоту и дополнительные возможности процессора. Установим его:
# yum install inxi -y

Информация о жестких дисках сервера в Linux
Чтобы получить информацию о жестких дисках в системе, я обычно использую утилиту hdparm. Сначала нужно установить ее из репозитория:
# yum install hdparm -y
Чтобы получить инфу по жесткому диску, нужно указать название устройства:
# hdparm -I /dev/sdb
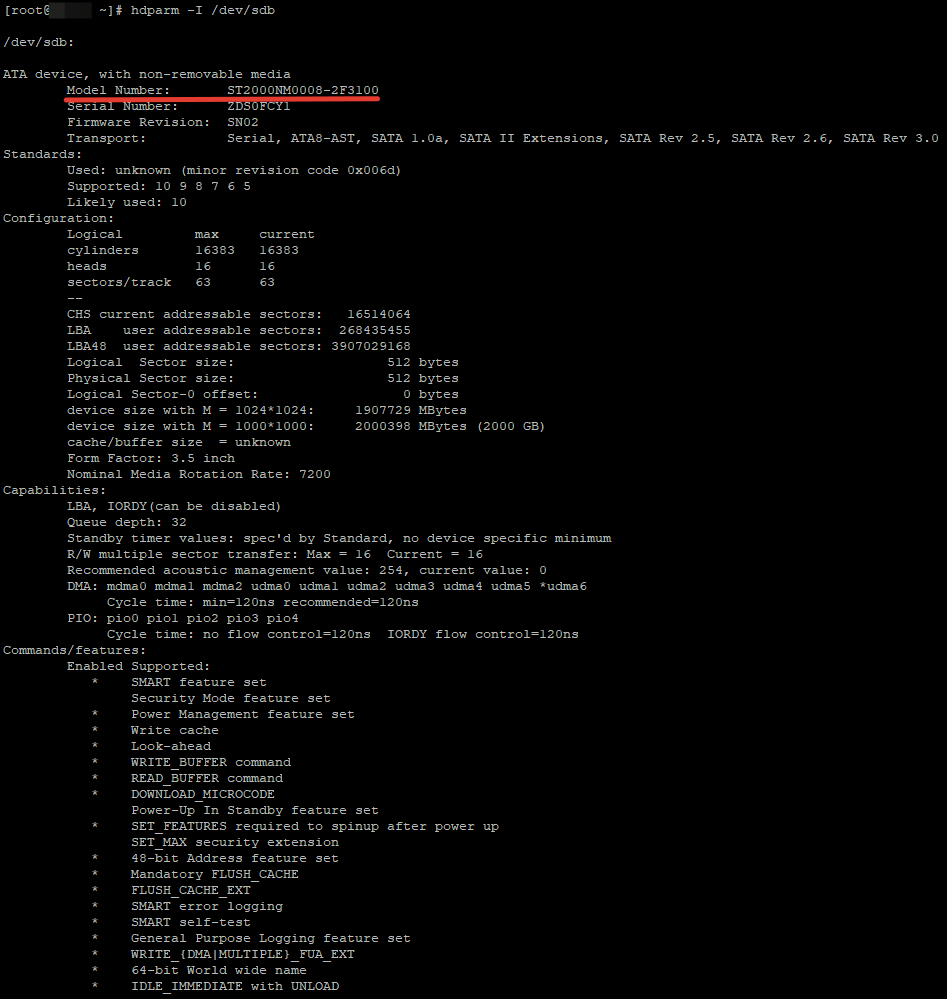
Как видите, при проверке отображается модель диска, серийный номер, версия прошивки диска, цилиндрах, rpm, поддерживаемые функции и ряд другой информации.
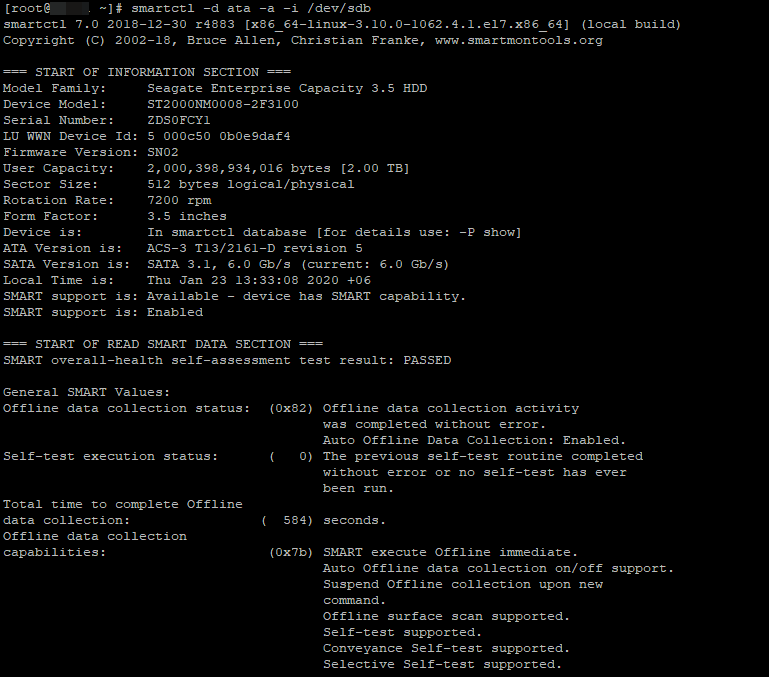
Вторая не менее популярная утилита это smartctl (она по умолчанию уже установлена в системе). Чтобы вывести информацию о диске, выполните:
# smartctl -d ata -a -i /dev/sdb
Информация будет предоставлена так же подробно:
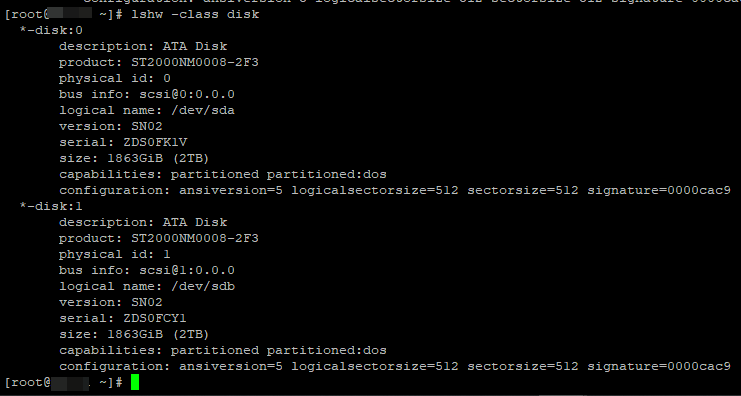
Очередная, очень удобная утилита lshw. Установите ее:
# yum install lshw -y
# lshw -class disk
Утилита dmidecode: получения информации о материнской плате, BIOS и др.
В данном разделе я приведу примеры более расширенного использования утилиты dmidecode. Dmidecode позволяет получить информацию об аппаратном обеспечении сервера на основе данных из BIOS по стандарту SMBIOS/DMI.
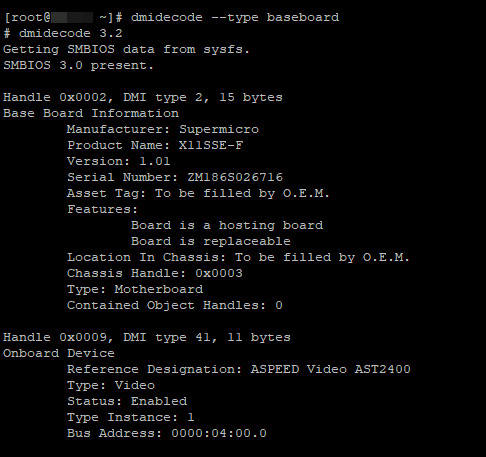
С помощью dmidecode мы можем получить информацию о материнской плате, bios, шасси и слотах сервера. Например:
# dmidecode —type baseboard – получим информацию о материнской плате.
# dmidecode —type bios – информация о BIOS (версия, поддерживаемые функции).
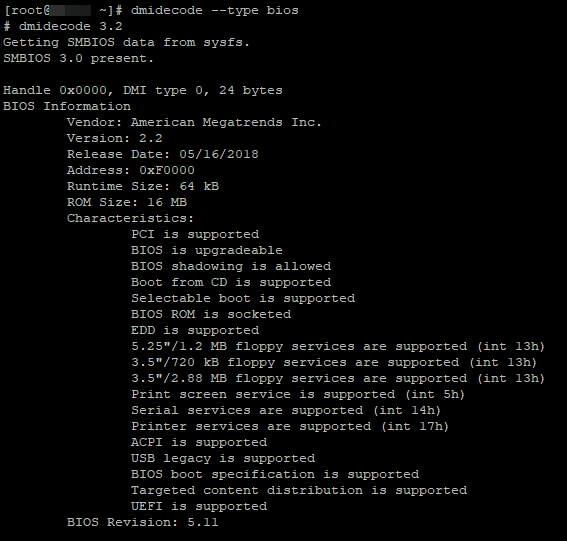
# dmidecode —type chassis – сведения о корпусе (шасси) сервера.
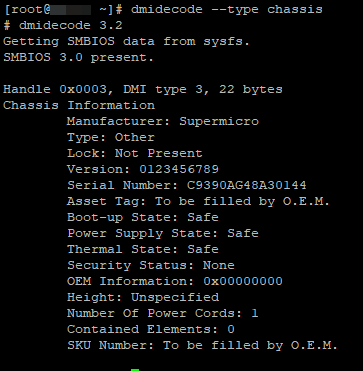
# dmidecode —type slot – сведения о используемых слотах на материнской плате.
Чтобы собрать вообще всю информацию о железе вашего сервера Linux, можно воспользоваться ранее указанную утилиту lshw:
# lshw -html > server_info.html
Вся информация будет выгружена в html файл.
Итак, мы рассмотрели, как получить информацию о аппаратном обеспечении вашего сервера. Надеюсь, информация будет полезна многим пользователям, а может и администраторам.
Источник
Linux: How to get CPU and memory information
Linux FAQ: How can I find Linux processor and memory information? (Also written as, How can I find Linux CPU information?, How can I find Linux RAM information?)
How to show the Linux CPU/processor
To see what type of processor/CPU your computer system has, use this Linux command:
As you can see, all you have to do is use the Linux cat command on a special file on your Linux system. (See below for sample processor output.)
How to show Linux memory information
To see your Linux memory information and memory stats use this command:
(See below for sample output.)
Linux processor command output
When I issue that Linux processor information command on my current hardware system, I see this output:
From that output I can see my current system is a two-processor Intel system, with additional information about the Intel CPU (CPUs, actually).
Linux memory information command
When I issue the Linux memory information command, I see the following output:
As you can see, my current Linux system has 2 GB RAM, with all the additional memory information shown there.
Summary: Linux processor and memory commands
I hope these Linux processor and memory commands have been helpful. When you have some spare time, take a look at the /proc filesystem on your Linux system for other system information you can find, including /proc/loadavg , /proc/vmstat , and much more.
Источник
5 commands to check memory usage on Linux
Memory Usage
On linux, there are commands for almost everything, because the gui might not be always available. When working on servers only shell access is available and everything has to be done from these commands. So today we shall be checking the commands that can be used to check memory usage on a linux system. Memory include RAM and swap.
It is often important to check memory usage and memory used per process on servers so that resources do not fall short and users are able to access the server. For example a website. If you are running a webserver, then the server must have enough memory to serve the visitors to the site. If not, the site would become very slow or even go down when there is a traffic spike, simply because memory would fall short. Its just like what happens on your desktop PC.
1. free command
The free command is the most simple and easy to use command to check memory usage on linux. Here is a quick example
The m option displays all data in MBs. The total os 7976 MB is the total amount of RAM installed on the system, that is 8GB. The used column shows the amount of RAM that has been used by linux, in this case around 6.4 GB. The output is pretty self explanatory. The catch over here is the cached and buffers column. The second line tells that 4.6 GB is free. This is the free memory in first line added with the buffers and cached amount of memory.
Linux has the habit of caching lots of things for faster performance, so that memory can be freed and used if needed.
The last line is the swap memory, which in this case is lying entirely free.
2. /proc/meminfo
The next way to check memory usage is to read the /proc/meminfo file. Know that the /proc file system does not contain real files. They are rather virtual files that contain dynamic information about the kernel and the system.
Check the values of MemTotal, MemFree, Buffers, Cached, SwapTotal, SwapFree.
They indicate same values of memory usage as the free command.
3. vmstat
The vmstat command with the s option, lays out the memory usage statistics much like the proc command. Here is an example
The top few lines indicate total memory, free memory etc and so on.
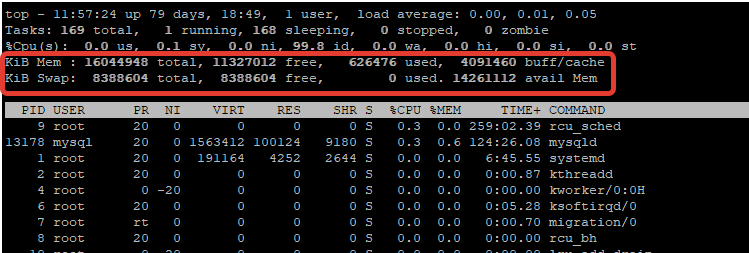
4. top command
The top command is generally used to check memory and cpu usage per process. However it also reports total memory usage and can be used to monitor the total RAM usage. The header on output has the required information. Here is a sample output
Check the KiB Mem and KiB Swap lines on the header. They indicate total, used and free amounts of the memory. The buffer and cache information is present here too, like the free command.
5. htop
Similar to the top command, the htop command also shows memory usage along with various other details.
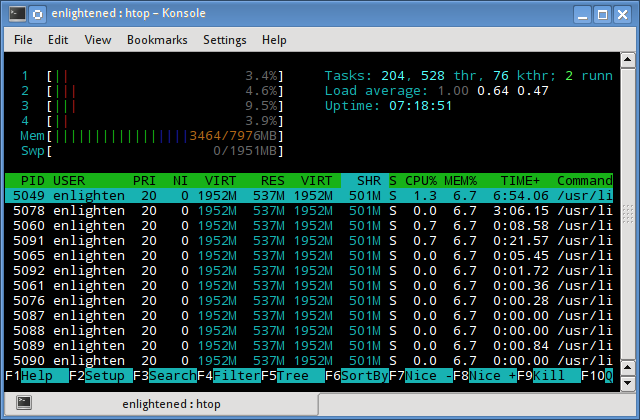
The header on top shows cpu usage along with RAM and swap usage with the corresponding figures.
RAM Information
To find out hardware information about the installed RAM, use the demidecode command. It reports lots of information about the installed RAM memory.
Provided information includes the size (2048MB), type (DDR2) , speed(667 Mhz) etc.
Summary
All the above mentioned commands work from the terminal and do not have a gui. When working on a desktop with a gui, it is much easier to use a GUI tool with graphical output. The most common tools are gnome-system-monitor on gnome and
ksysguard on KDE. Both provide resource usage information about cpu, ram, swap and network bandwidth in a graphical and easy to understand visual output.
A Tech Enthusiast, Blogger, Linux Fan and a Software Developer. Writes about Computer hardware, Linux and Open Source software and coding in Python, Php and Javascript. He can be reached at [email protected] .
66 thoughts on “ 5 commands to check memory usage on Linux ”
You have explained the topic very well. Thanks for sharing a nice article.
Thanks for these commands. It saved a lots of time.
How about explaining what we are looking for? Most people would know these commands. Waste of time.
Please correct the typo in “RAM Information” section. The command for viewing hardware info about RAM is “dmidecode” and not “demidecode”.
And it also requires root privileges.
Источник
Как Linux работает с памятью. Семинар в Яндексе
Привет. Меня зовут Вячеслав Бирюков. В Яндексе я руковожу группой эксплуатации поиска. Недавно для студентов Курсов информационных технологий Яндекса я прочитал лекцию о работе с памятью в Linux. Почему именно память? Главный ответ: работа с памятью мне нравится. Кроме того, информации о ней довольно мало, а та, что есть, как правило, нерелевантна, потому что эта часть ядра Linux меняется достаточно быстро и не успевает попасть в книги. Рассказывать я буду про архитектуру x86_64 и про Linux-ядро версии 2.6.32. Местами будет версия ядра 3.х.
Эта лекция будет полезна не только системным администраторам, но и разработчикам программ высоконагруженных систем. Она поможет им понять, как именно происходит взаимодействие с ядром операционной системы.
Термины
Резидентная память – это тот объем памяти, который сейчас находится в оперативной памяти сервера, компьютера, ноутбука.
Анонимная память – это память без учёта файлового кеша и памяти, которая имеет файловый бэкенд на диске.
Page fault – ловушка обращения памяти. Штатный механизм при работе с виртуальной памятью.
Страницы памяти
Работа с памятью организована через страницы. Объём памяти, как правило, большой, присутствует адресация, но операционной системе и железу не очень удобно работать с каждым из адресов отдельно, поэтому вся память и разбита на страницы. Размер страницы – 4 KБ. Также существуют страницы другого размера: так называемые Huge Pages размером 2 MБ и страницы размером 1 ГБ (о них мы говорить сегодня не будем).
Виртуальная память – это адресное пространство процесса. Процесс работает не с физической памятью напрямую, а с виртуальной. Такая абстракция позволяет проще писать код приложений, не думать о том, что можно случайно обратиться не на те адреса памяти или адреса другого процесса. Это упрощает разработку приложений, а также позволяет превышать размер основной оперативной памяти за счёт описанных ниже механизмов. Виртуальная память состоит из основной памяти и swap-устройства. То есть объём виртуальной памяти может быть в принципе неограниченного размера.
Для управления виртуальной памятью в системе присутствует параметр overcommit . Он следит за тем, чтобы мы не переиспользовали размер памяти. Управляется через sysctl и может быть в следующих трех значениях:
- 0 – значение по умолчанию. В этом случае используется эвристика, которая следит за тем, чтобы мы не смогли выделить виртуальной памяти в процессе намного больше, чем есть в системе;
- 1 – говорит о том, что мы никак не следим за объёмом выделяемой памяти. Это полезно, например, в программах для вычислений, которые выделяют большие массивы данных и работают с ними особым способом;
- 2 – параметр, который позволяет строго ограничивать объем виртуальной памяти процесса.
Посмотреть, сколько у нас закоммичено памяти, сколько используется и сколько мы можем ещё выделить, можно в строках CommitLimit и Commited_AS из файла /proc/meminfo .
Memory Zones и NUMA
В современных системах вся виртуальная память делится на NUMA-ноды. Когда-то у нас были компьютеры с одним процессором и одним банком памяти (memory bank). Называлась такая архитектура UMA (SMP). Всё было предельно понятно: одна системная шина для общения всех компонентов. В последствии это стало неудобно, начало ограничивать развитие архитектуры, и, как следствие, была придумана NUMA.

Как видно из слайда, у нас есть два процессора, которые общаются между собой по какому-то каналу, и у каждого из них есть свои шины, через которые они общаются со своими банками памяти. Если мы посмотрим на картинку, то задержка от CPU 1 к RAM 1 в NUMA-ноде будет в два раза меньше, чем от CPU 1 на RAM 2. Получить эти данные и прочую информацию мы можем, используя команду numactl hardware .
Мы видим, что сервер имеет две ноды и информацию по ним (сколько в каждой ноде свободной физической памяти). Память выделяется на каждой ноде отдельно. Поэтому можно потребить всю свободную память на одной ноде, а другую — недогрузить. Чтобы такого не было (это свойственно базам данных), можно запускать процесс с командой numactl interleave=all. Это позволяет распределять выделение памяти между двумя нодам равномерно. В противном случае ядро выбирает ноду, на которой был запланирован запуск этого процесса (CPU scheduling) и всегда пытается выделить память на ней.
Также память в системе поделена на Memory Zones. Каждая NUMA-нода делится на какое-то количество таких зон. Они служат для поддержки специального железа, которое не может общаться по всему диапазону адресов. К примеру, ZONE_DMA – это 16 MБ первых адресов, ZONE_DMA32 – это 4 ГБ. Смотрим на зоны памяти и их состояние через файл /proc/zoneinfo .
Page Cache
Через Page Cache в Linux по умолчанию идут все операции чтения и записи. Он динамического размера, то есть именно он съест всю вашу память, если она свободна. Как гласит старая шутка, если вам нужна свободная память в сервере, просто вытащите ее из сервера. Page Cache делит все файлы, которые мы читаем, на страницы (страница, как мы сказали, – 4 KБ). Посмотреть, есть ли в Page Cache какие-то страницы какого-то конкретного файла, можно с помощью системного вызова mincore() . Или с помощью утилиты vmtouch, которая написана с использованием этого системного вызова.
Как же происходит запись? Любая запись происходит на диск не сразу, а в Page Cache, и делается это практически моментально. Тут можно увидеть интересную «аномалию»: запись на диск идет намного быстрее, чем чтение. Дело в том, что при чтении (если данной странички файла в Page Cache нет) мы пойдем в диск и будем синхронно ждать ответа, а запись в свою очередь пройдет моментально в кеш.
Минусом такого поведения является то, что на самом деле данные никуда не записались, — они просто находятся в памяти, и когда-то их нужно будет сбросить на диск. У каждой странички при записи проставляется флажок (он называется dirty). Такая «грязная» страничка появляется в Page Cache. Если накапливается много таких страничек, система понимает, что пора их сбросить на диск, а то можно их потерять (если внезапно пропадет питание, наши данные тоже пропадут).
Память процесса
Процесс состоит из следующих сегментов. У нас есть stack, который растет вниз; у него есть лимит дальше котрого он расти не может.
Затем идет регион mmap: там находятся все отображенные на память файлы процесса, которые мы открыли или создали через системный вызов mmap() . Далее идет большое пространство невыделенной виртуальной памяти, которую мы можем использовать. Снизу вверх растет heap – это область анонимной памяти. Внизу идут области бинарника, который мы запускаем.
Если мы говорим о памяти внутри процесса, то работать со страницами тоже неудобно: как правило, выделение памяти внутри процесса происходит блоками. Очень редко требуется выделить одну-две странички, обычно нужно выделить сразу какой-то промежуток страниц. Поэтому в Linux существует такое понятие, как область памяти (virtual memory area, VMA), которая описывает какое-то пространство адресов внутри виртуального адресного пространства этого процесса. На каждую такую VMA есть свои права (чтения, записи, исполнения) и области видимости: она может быть приватная или общая (которая «шарится (share)» с другими процессами в системе).
Выделение памяти
Выделение памяти можно поделить на четыре случая: есть выделение приватной памяти и памяти, которой можем с кем-то поделиться (share); двумя другими категорями являются разделение на анонимную память и ту, у которая связана с файлом на диске. Самые частые функции выделения памяти – это malloc и free. Если мы говорим о glibc malloc() , то он выделяет анонимную память таким интересным способом: использует heap для аллокации маленьких объемов (менее 128 KБ) и mmap() для больших объемов. Такое выделение необходимо для того, чтобы память расходовалась оптимальнее и её можно было запросто отдавать в систему. Если в heap не хватает памяти для выделения, вызывается системный вызов brk() , который расширяет границы heap. Системный вызов mmap() занимается тем, что отображает содержимое файла на адресное пространство. munmap() в свою очередь освобождает отображение. У mmap() есть флаги, которые регулируют видимость изменений и уровень доступа.
На самом деле, Linux не выделяет всю запрошенную память сразу. Процесс выделения памяти — Demand Paging — начинается с того, что мы запрашиваем у ядра системы страничку памяти, и она попадает в область Only Allocated. Ядро отвечает процессу: вот твоя страница памяти, ты можешь её использовать. И больше ничего происходит. Никакой физической аллокации не происходит. А произойдет она только в том случае, если мы попробуем в эту страницу произвести запись. В этот момент пойдёт обращение в Page Table – эта структура транслирует виртуальные адреса процесса в физические адреса оперативной памяти. При этом будут задействованы также два блока: MMU и TLB, как видно из рисунка. Они позволяют ускорять выделение и служат для трансляции виртуальных адресов в физические.
После того, как мы понимаем, что этой странице в Page Table ничего не соответствует, то есть нет связи с физической памятью, мы получаем Page Fault – в данном случае минорный (minor), так как отсутствует обращение в диск. После этого процесса система может производить запись в выделенную страницу памяти. Для процесса все это происходит прозрачно. А мы можем наблюдать увеличение счетчика минорных Page Fault для процесса на одну единицу. Также бывает мажорный Page Fault – в случае, когда происходит обращение в диск за содержимым страницы (в случае mmpa() ).
Один из трюков в работе с памятью в Linux – Copy On Write – позволяет делать очень быстрые порождения процессов (fork).
Работа с файлами и с памятью
Подсистема памяти и подсистема работы с файлами тесно связаны. Так как работа с диском напрямую очень медленна, ядро использует в качестве прослойки оперативную память.
malloc() использует больше памяти: происходит копирование в user space. Также потребляется больше CPU, и мы получаем больше переключений контекста, чем если бы мы работали с файлом через mmap() .
Какие выводы можно сделать? Мы можем работать с файлами, как с памятью. У нас есть lazy lоading, то есть мы можем замапить очень-очень большой файл, и он будет подгружаться в память процесса через Page Cache только по мере надобности. Всё также происходит быстрее, потому что мы используем меньше системных вызовов и, в конце концов, это экономит память. Ещё стоит отметить, что при завершении программы память никуда не девается и остается в Page Cache.
В начале было сказано, что вся запись и чтение идут через Page Cache, но иногда по какой-то причине, есть необходимость в отходе от такого поведения. Некоторые программные продукты работают таким способом, например MySQL с InnoDB.
Подсказать ядру, что в ближайшее время мы не будем работать с этим файлом, и заставить выгрузить страницы файла из Page Cache можно с помощью специальных системных вызовов:
- posix_fadvide();
- madvise();
- mincore().
Утилита vmtouch также может вынести страницы файла из Page Cache – ключ “e”.
Readahead
Поговорим про Readahead. Если читать файлы с диска через Page Cache каждый раз постранично, то у нас будет достаточно много Page Fault и мы будем часто ходить на диск за данными. Поэтому мы можем управлять размером Readahead: если мы прочитали первую и вторую страничку, то ядро понимает, что, скорее всего, нам нужна и третья. И так как ходить на диск дорого, мы можем прочитать немного больше заранее, загрузив файл наперёд в Page Cache и отвечать в будущем из него. Таким образом происходит замена будущих тяжёлых мажорных (major) Page Faults на минорные (minor) page fault.
Итак мы выдали всем память, все процессы довольны, и внезапно память у нас закончилась. Теперь нам нужно ее как-то освобождать. Процесс поиска и выделения свободной памяти в ядре называется Page Reclaiming. В памяти могут находится страницы памяти, которые нельзя забирать, – залокированные страницы (locked). Помимо них есть ещё четыре категории страниц. Cтраницы ядра, которые выгружать не стоит, потому что это затормозит всю работу системы; cтраницы Swappable – это такие страницы анонимной памяти, которые никуда, кроме как в swap устройство выгрузить нельзя; Syncable Pages – те, которые могут быть синхронизированы с диском, а в случае открытого файла только на чтение – такие страницы можно с лёгкостью выбросить из памяти; и Discardable Pages – это те страницы, от которых можно просто отказаться.
Источники пополнения Free List
Если говорить упрощённо, то у ядра есть один большой Free List (на самом деле, это не так), в котором хранятся страницы памяти, которые можно выдавать процессам. Ядро пытается поддерживать размер этого списка в каком-то не нулевом состоянии, чтобы быстро выдавать память процессам. Пополняется этот список за счёт четырех источников: Page Cache, Swap, Kernel Memory и OOM Killer.
Мы должны различать участки памяти на горячую и холодную и как-то пополнять за счет них наши Free Lists. Page Cache устроен по принципу LRU/2 очереди. Есть активный список страниц (Active List) и инактивный список (Inactive List) страничек, между которыми есть какая-то связь. В Free List прилетают запросы на выделение памяти (allocation). Система отдаёт страницы из головы этого списка, а в хвост списка попадают страницы из хвоста инактивного (inactive) списка. Новые страницы, когда мы читаем файл через Page Cache, всегда попадают в голову и проходят до конца инактивного списка, если в эти страницы не было еще хотя бы одного обращения. Если такое обращение было в любом месте инактивного списка, то страницы попадают сразу в голову активного списка и начинают двигаться в сторону его хвоста. Если же в этот момент опять к ним происходит обращение, то страницы вновь пробиваются в верх списка. Таким образом система пытается сбалансировать списки: самые горячие данные всегда находятся в Page Cache в активном списке, и Free List никогда не пополняется за их счет.
Также тут стоит отметить интересное поведение: страницы, за счет которых пополняется Free List, которые в свою очередь прилетают из инактивного списка, но до сих пор не отданные для аллокации, могут быть возвращены обратно в инактивный списка (в данном случае в голову инактивного списка).
Итого у нас получается пять таких листов: Active Anon, Inactive Anon, Active File, Inactive File, Unevictable. Такие списки создаются для каждой NUMA ноды и для каждой Memory Zone.
Источник



