- Как проверить размер файла в сценариях оболочки Linux / Unix bash
- Как проверить размер файла в unix с помощью команды wc
- Как узнать размер файла в сценарии bash, используя команду stat
- Примеры команды du
- Найдите пример команды
- Размер файла в Linux
- Размер файла в Linux
- 1. Nautilus
- 2. Команда ls
- 3. Утилита stat
- 4. Утилита du
- 5. Утилита ncdu
- 6. Утилита find
- Выводы
- Опция wc -c для подсчета байтов в Linux
- Как подсчитать байты в Linux с помощью wc -c:
- Как подсчитать байты в Linux с помощью du:
- Заключение:
- Как отобразить размер файла в удобочитаемом формате (КБ, МБ, ГБ) в терминале Linux
- Как я могу получить размер файла в bash-скрипте?
Как проверить размер файла в сценариях оболочки Linux / Unix bash
 Я новый пользователь сценариев оболочки bash. Как узнать размер файла в моем сценарии оболочки bash и сохранить этот размер файла в переменной оболочки bash?
Я новый пользователь сценариев оболочки bash. Как узнать размер файла в моем сценарии оболочки bash и сохранить этот размер файла в переменной оболочки bash?
Вы не можете получить размер файла в сценарии bash, используя внутреннюю или встроенную команду. Вам понадобятся несколько команд, включая stat. Командная строка stat отображает информацию о файле, включая его размер. Другой вариант — использовать команду wc, которая может подсчитывать количество байтов в каждом заданном файле. Давайте посмотрим, как использовать эти две команды для проверки размера файла в Linux или Unix-подобной системе.
Как проверить размер файла в unix с помощью команды wc
Команда wc показывает количество строк, слов и байтов, содержащихся в файле. Для получения размера файла, используйте синтаксис, который выглядит следующим образом:
Примеры возможных выводов данных:
Вы может с легкостью извлечь первое поле, используя или команду cut или команду awk:
Примеры возможных выводов данных:
или присвоить этот размер переменной bash:
Как узнать размер файла в сценарии bash, используя команду stat
Команда stat показывает информацию о файле. Используйте следующий синтаксис для того, чтобы узнать размер файла на GNU/Linux с помощью команды stat:
Чтобы присвоить этот размер переменной bash:
Используйте следующий синтаксис для того, чтобы узнать размер файла на BSD/MacOS с помощью команды
Обратите внимание, что если файл является символьной ссылкой, вы получите размер этой ссылки только с помощью команды stat.
Примеры команды du
Синтаксис выглядит следующим образом
Примеры возможных выводов данных указанных выше команд:
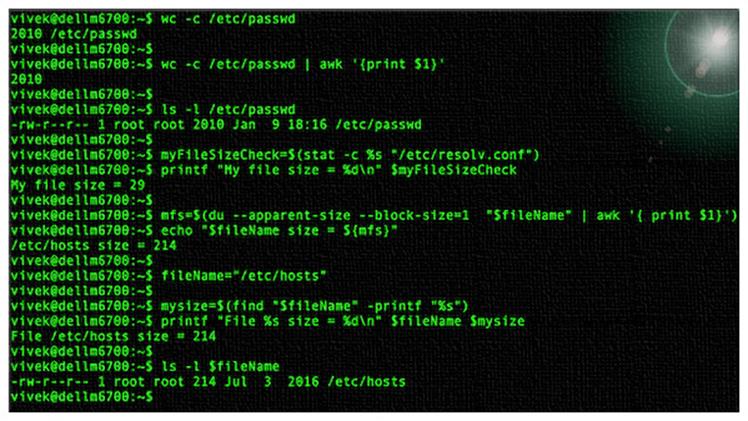 Рисунок 01: Как проверить размер файла с помощью оболочки bash/ksh/zsh/sh/tcsh?
Рисунок 01: Как проверить размер файла с помощью оболочки bash/ksh/zsh/sh/tcsh?
Найдите пример команды
Синтаксис выглядит следующим образом:
Источник
Размер файла в Linux
В этой небольшой статье мы поговорим о том, как узнать размер файла в Linux с помощью различных утилит. Проще всего узнать этот параметр в графическом интерфейсе, но многим часто приходится работать в терминале и надо знать как эта задача решается там.
Вы узнаете как посмотреть размер файла через файловый менеджер, утилиту ls, а также du. Об этих утилитах у нас есть отдельные статьи, но эта будет нацелена именно на просмотр размера конкретного файла.
Размер файла в Linux
1. Nautilus
Чтобы посмотреть размер файла в файловом менеджере сначала найдите нужный файл и кликните по нему правой кнопкой мыши. В открывшемся меню выберите Свойства:

Программа откроет окно, в котором будут указаны свойства файла, среди них будет и размер:

2. Команда ls
Для того чтобы утилита ls отображала размер файлов в удобном для чтения формате необходимо использовать параметр -h. Например:

Здесь размер отображается в пятой колонке. Чтобы увидеть размер определённого файла надо передать его имя утилите:
ls -lh ‘Снимок экрана от 2020-08-10 20-22-50.png’

Можно ещё вручную указать единицы измерения для показа размера. Для этого используйте опцию —block-size. Например, мегабайты:
ls -l —block-size=M
Вместо ls можно использовать команду ll, её вывод полностью аналогичен команде ls -l:

3. Утилита stat
Программа stat кроме метаданных позволяет выводить размер файла в байтах. Например:
stat ‘Снимок экрана от 2020-08-10 20-22-50.png’
Если нужно показать только размер, используйте опцию -с с указанием формата %s:
stat -c %s ‘Снимок экрана от 2020-08-10 20-22-50.png’
4. Утилита du
Программа du специально предназначена для просмотра размера файлов в папке. Вы можете просмотреть размер конкретного файла, например:
du -h ‘Снимок экрана от 2020-08-10 20-22-50.png’
Опция -h включает вывод размера в удобном для чтения формате. Если вы хотите посмотреть размеры для всех файлов в папке, просто передайте путь к папке:

А чтобы узнать размер папки в Linux используйте опцию -s. Она суммирует размеры всех объектов:

5. Утилита ncdu
Программа ncdu позволяет анализировать дисковое пространство занимаемое файлами и каталогами. Но она не поставляется вместе с системой. Для её установки выполните:
sudo apt install ncdu
Затем просто укажите в параметрах каталог, размер которого вы хотите посмотреть:
Все файлы будут отсортированы по размеру, а в самом низу будет отображен общий размер этой папки:
6. Утилита find
С помощью этой утилиты вы не можете узнать размер файла, зато можете найти файлы с определённым размером. С помощью параметра size можно указать границы размера файлов, которые надо найти. Например, больше чем 2000 килобайт, но меньше чем 2500 килобайт:
/Изображения/ -size +2000k -size -2500k
Размер можно ещё указывать в мегабайтах для этого используйте приставку M, или в байтах, тогда никакой приставки не нужно.
Выводы
В этой небольшой статье мы разобрались как узнать размер файлов linux, а также как посмотреть размер каталога и всех файлов в нём с помощью различных утилит. А какие способы просмотра размера используете вы? Напишите в комментариях!
Источник
Опция wc -c для подсчета байтов в Linux
Главное меню » Linux » Опция wc -c для подсчета байтов в Linux

В этой статье объясняется, как подсчитать байты файла с помощью команд wc и du. Прочитав эту статью, вы узнаете, как легко подсчитывать байты, строки и слова в Linux.
Как подсчитать байты в Linux с помощью wc -c:
Синтаксис довольно прост; в примере ниже показана команда wc -c, используемая для подсчета байтов файла с именем andreyexsignal.c.
Как вы можете видеть на выходе, файл имеет 106 байт.
Команда wc -c также может использоваться для подсчета нескольких байтов файла, как показано в примере ниже, в котором подсчитываются байты для andreyexsignal.c и wp-downgrade.zip.
Wc печатает байты каждого файла и общую сумму.
Вы также можете реализовать подстановочный знак для подсчета всех файлов в каталоге, как показано ниже.
Используя подстановочный знак, wc распечатает все файлы и их количество байтов.
Команда wc полезна не только для подсчета байтов. Эта команда также полезна для подсчета строк, слов и символов в файле или нескольких файлах.
Если вы запустите wc без флагов, за которым следует только имя файла, он напечатает 3 столбца.
Первый столбец показывает количество строк. Второй столбец показывает количество слов, а третий столбец показывает байты.
Конечно, вы также можете посчитать каждую характеристику отдельно.
Вам нужно добавить флаг -l для подсчета номера строки.
Как видите, файл содержит 11 строк.
В приведенном ниже примере показано, как выполнить подсчет слов с помощью команды wc с флагом -w.
В следующем примере показано, как реализовать конвейер для объединения команд ls и wc, чтобы получить общее количество файлов для подсчета в каталоге.
Вы можете прочитать все функции wc, запустив:
Как подсчитать байты в Linux с помощью du:
Команду du также можно использовать для подсчета байтов. Запустив команду du, за которой следует флаг -b и имя файла, вы можете получить количество байтов.
Как и в случае с командой wc, с помощью команды du вы также можете определить несколько файлов для подсчета, как показано на снимке экрана ниже. Разница с выводом wc в том, что команда du не показывает общую сумму.
Как было сказано ранее, разница с wc заключается в том, что на выходе не отображается общее количество байтов. Чтобы получить общую сумму с помощью du, вам нужно добавить флаг -c, как показано ниже.
Теперь предположим, что вам нужен вывод не в байтах, а в удобочитаемом формате; для этого вы можете реализовать флаг -h (человек).
Теперь вывод удобен для человека.
Команду du можно использовать для печати размеров файлов в любых единицах измерения. В приведенном ниже примере показано, как распечатать размер в килобайтах с помощью флага -k.
Очень важно уточнить, что команда du не может предоставить общий объем в килобайтах или мегабайтах, если размер файла не соответствует точной единице; в таком случае команда du вернет ближайшее значение заданного вами формата единиц измерения.
Кроме того, вы можете распечатать размер файлов в мегабайтах с помощью флага -m, как показано ниже.
Результат в мегабайтах, а не точный объем в мегабайтах, а более близкий к реальному значению в байтах.
Заключение:
Как видите, подсчет байтов с помощью команды wc -c довольно прост. Linux предлагает разные способы решения этой задачи; В этом руководстве основное внимание уделяется 2 наиболее распространенным командам для подсчета размера файлов в байтах. Как видите, при подсчете байтов нет значимой разницы между командами wc и du. Единственное отличие, описанное в этой статье (помимо флагов), – это общая сумма байтов в выходных данных. Команду wc также полезно реализовать с конвейерами и другими командами, отображающими дополнительную информацию.
Спасибо, что прочитали это руководство по команде wc для подсчета байтов. Следите за нами, чтобы получить больше советов и статей по Linux.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Как отобразить размер файла в удобочитаемом формате (КБ, МБ, ГБ) в терминале Linux
Главное меню » Linux » Как отобразить размер файла в удобочитаемом формате (КБ, МБ, ГБ) в терминале Linux

Но, к сожалению, длинный список показывает размер файла в блоках, и для нас, людей, от этого мало пользы.
Хорошо, что вы можете комбинировать опцию lс -h, чтобы показать размер файла в удобочитаемом формате.
Как видите, размер файла лучше отображать в удобочитаемом формате.
Как видите, размеры файлов теперь отображаются в K (для КБ), M для (МБ). Если размер файла указан в байтах, он не отображается с суффиксом. В приведенном выше примере char.sh размер составляет 140 байт.
Вы обратили внимание на размер каталога new_dir? Это 4 КБ. Если вы используете ls -lhкоманду для каталогов, она всегда показывает размер каталога как 4,0 К.
Вам нужно будет использовать команду du, чтобы получить реальный размер каталога в Linux.
По умолчанию размер блока в большинстве систем Linux составляет 4096 байт или 4 КБ. Каталог в Linux – это просто файл с информацией о расположении в памяти всех файлов в нем.
Вы можете заставить команду ls отображать размер файла в МБ с помощью флага –block-size.
Проблема с этим подходом заключается в том, что все файлы размером менее 1 МБ также будут отображаться с размером файла 1 МБ.
Команда ls также может -sотображать размер. Вы должны объединить с,-h, чтобы показать размер файла в удобочитаемой форме.
Вы также можете использовать команду stat в Linux, чтобы проверить размер файла.
Мы надеемся, что этот быстрый совет поможет вам увидеть размер файла в Linux.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Как я могу получить размер файла в bash-скрипте?
Как я могу получить размер файла в bash-скрипте?
Как мне присвоить это переменной bash, чтобы я мог использовать ее позже?
Ваш лучший выбор, если в системе GNU:
ПРИМЕЧАНИЕ: см . Ответ @ chbrown о том, как использовать stat в терминале в Mac OS X.
Проблема с использованием stat заключается в том, что это расширение GNU (Linux). du -k и cut -f1 определяются POSIX и поэтому переносимы на любую систему Unix.
Солярис, например, поставляется с Bash, но не с stat . Так что это не совсем гипотетически.
ls имеет аналогичную проблему в том, что точный формат вывода не указан, поэтому анализ его вывода не может быть выполнен переносимым. du -h также расширение GNU.
Придерживайтесь переносных конструкций, где это возможно, и в будущем вы сделаете чью-то жизнь проще. Может быть, ваш собственный.
Вы также можете использовать команду «подсчет слов» ( wc ):
Проблема в wc том, что он добавит имя файла и сделает отступ. Например:
Если вы хотите избежать создания цепочки полностью интерпретируемого языка или потокового редактора просто для того, чтобы получить счетчик размера файла, просто перенаправьте ввод из файла, чтобы wc никогда не видеть имя файла:
Эта последняя форма может использоваться с подстановкой команд, чтобы легко получить значение, которое вы искали, как переменную оболочки, как упомянуто Жилем ниже.
У BSD (Mac OS X) stat есть другой флаг аргумента формата и другие спецификаторы поля. От man stat(1) :
- -f format : Отображение информации в указанном формате. Смотрите раздел FORMATS для описания допустимых форматов.
- . раздел ФОРМАТЫ .
- z : Размер файла в байтах.
Итак, все вместе сейчас:
Зависит от того, что вы подразумеваете под размером .
даст вам количество байтов, которые можно прочитать из файла. IOW, это размер содержимого файла. Тем не менее, он будет читать содержимое файла (за исключением случаев, когда файл является обычным файлом или символической ссылкой на обычный файл в большинстве wc реализаций в качестве оптимизации). Это может иметь побочные эффекты. Например, для именованного канала, то, что было прочитано, больше не может быть прочитано снова, а для таких вещей, как /dev/zero или /dev/random которые имеют бесконечный размер, это займет некоторое время. Это также означает, что вам нужно read разрешение на файл, и последняя отметка времени доступа к файлу может быть обновлена.
Это стандартно и переносимо, однако обратите внимание, что некоторые wc реализации могут включать начальные пробелы в этом выводе. Один из способов избавиться от них — использовать:
или чтобы избежать ошибки о пустом арифметическом выражении в dash или yash когда wc ничего не выводится (например, когда файл не может быть открыт):
ksh93 имеет wc встроенную функцию (при условии, что вы ее включите, вы также можете вызывать ее как command /opt/ast/bin/wc ), что делает ее наиболее эффективной для обычных файлов в этой оболочке.
Различные системы имеют команду с именем , stat что это интерфейс к stat() или lstat() системным вызовам.
Те сообщают информацию, найденную в inode. Одной из этих сведений является st_size атрибут. Для обычных файлов это размер контента (сколько данных можно прочитать из него при отсутствии ошибок (это то, что большинство wc -c реализаций используют при оптимизации)). Для символических ссылок это размер в байтах целевого пути. Для именованных каналов, в зависимости от системы, это либо 0, либо количество байтов, находящихся в данный момент в буфере канала. То же самое для блочных устройств, где в зависимости от системы вы получаете 0 или размер в байтах базового хранилища.
Вам не нужно разрешение на чтение файла, чтобы получить эту информацию, только разрешение на поиск в каталоге, с которым он связан.
По хронологическому порядку есть:
возвращает st_size атрибут $file ( lstat() ) или:
То же самое, за исключением случаев, когда $file это символическая ссылка, и в этом случае это st_size файл после разрешения символической ссылки.
zsh stat Встроенный (теперь также известный как zstat ) в zsh/stat модуле (загружен с zmodload zsh/stat ) (1997):
или хранить в переменной:
очевидно, это самый эффективный в этой оболочке.
GNU stat (2001); также в BusyBox stat с 2005 года (скопировано из GNU stat ):
(обратите внимание, что значение -L обратное по сравнению с IRIX или zsh stat .
Или вы можете использовать stat() / lstat() функцию некоторых скриптовых языков, таких как perl :
В AIX также есть istat команда, которая будет выгружать всю информацию stat() (нет lstat() , поэтому не будет работать с символическими ссылками) и которую вы могли бы обработать, например:
(размер после разрешения символической ссылки)
Задолго до того, как GNU представила свою stat команду, того же можно добиться с помощью find команды GNU с ее -printf предикатом (уже в 1991 году):
Одна проблема , хотя в том , что не работает , если $file начинается с — или в find предикат (например ! , ( . ).
Стандартная команда для получения информации stat() / . lstat() ls
POSIXly, вы можете сделать:
и добавить -L то же самое после разрешения символической ссылки. Это не работает для файлов устройств, хотя 5- е поле — это номер устройства, а не его размер.
Для блочных устройств системы, где stat() возвращается 0 для st_size , обычно имеют другие API-интерфейсы для сообщения о размере блочного устройства. Например, Linux имеет BLKGETSIZE64 ioctl() , и большинство дистрибутивов Linux теперь поставляются с blockdev командой, которая может использовать ее:
Однако для этого вам нужно разрешение на чтение файла устройства. Обычно можно получить размер другими способами. Например (все еще в Linux):
Должно работать за исключением пустых устройств.
Подход, который работает для всех доступных для поиска файлов (включая обычные файлы, большинство блочных устройств и некоторые символьные устройства), заключается в открытии файла и поиске до конца:
С zsh (после загрузки zsh/system модуля):
Для именованных каналов мы видели, что некоторые системы (по крайней мере, AIX, Solaris, HP / UX) делают объем данных в буфере канала доступным в stat() ‘s st_size . Некоторые (например, Linux или FreeBSD) этого не делают.
По крайней мере, в Linux вы можете использовать FIONREAD ioctl() после открытия канала (в режиме чтения + записи, чтобы избежать его зависания):
Однако обратите внимание, что хотя он не читает содержимое канала, простое открытие именованного канала может иметь побочные эффекты. fuser Сначала мы используем, чтобы проверить, что какой-то процесс уже имеет открытую трубу, чтобы облегчить это, но это не является надежной задачей, так как fuser не может проверить все процессы.
Пока что мы рассматривали только размер первичных данных, связанных с файлами. Это не учитывает размер метаданных и всю вспомогательную инфраструктуру, необходимую для хранения этого файла.
Другой атрибут inode, возвращаемый stat() is st_blocks . Это количество 512-байтовых блоков, которое используется для хранения данных файла (а иногда и некоторых его метаданных, таких как расширенные атрибуты в файловых системах ext4 в Linux). Это не включает в себя сам индекс или записи в каталогах, с которыми связан файл.
Размер и использование диска не обязательно тесно связаны как сжатие, разреженность (иногда некоторые метаданные), дополнительная инфраструктура, например косвенные блоки в некоторых файловых системах, влияют на последнюю.
Это обычно то, что du используется, чтобы сообщить об использовании диска. Большинство команд, перечисленных выше, смогут получить эту информацию.
- POSIXLY_CORRECT=1 ls -sd — «$file» | awk ‘
‘ - POSIXLY_CORRECT=1 du -s — «$file» (не для каталогов, где это будет включать в себя использование диска файлов внутри).
- GNU find — «$file» -printf ‘%b\n’
- zstat -L +block — $file
- GNU stat -c %b — «$file»
- BSD stat -f %b — «$file»
- perl -le ‘print((lstat shift)[12])’ — «$file»
Источник



