- How to Fix “can’t read superblock” Error on Linux (ext4 & Btrfs)
- The Structure of Hard Disk Drive
- Physical Sector Size vs Logical Sector Size
- Partition Alignment
- SSD Partition Alignment
- Blocks in Filesystem
- Superblock
- Can’t read superblock
- Recover superblock on ext4 filesystem
- Recover superblock on btrfs filesystem
- Backing Up Files on your Disk
- Wrapping Up
- Linux read block no
- Things to note
- read(3) — Linux man page
- Prolog
- Synopsis
- Description
- Return Value
- Errors
- Examples
- Reading Data into a Buffer
- Application Usage
- Rationale
- Input and Output
- Future Directions
- See Also
How to Fix “can’t read superblock” Error on Linux (ext4 & Btrfs)
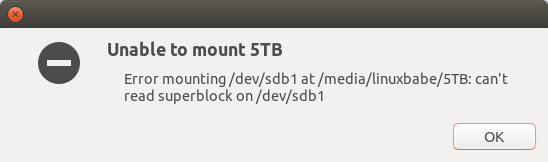
Recently my Linux desktop computer can’t mount my 5TB external hard disk drive (HDD), and the file manager displays the “can’t read superblock” error on the screen. I’m going to share with you what I did to fix the error, so if you are in the same situation, this article may help you.
But before doing that, I want to explain some basic knowledge about hard disk drives and filesystems on Linux, so you will really know what you are doing. If you don’t care about those details, you can jump directly to the solution. A hard disk drive (HDD) is magnetic disk. A solid-state drive (SSD) is electronic disk.
The Structure of Hard Disk Drive
A hard disk drive usually has several circular platters stacked vertically with a spindle that rotates the disk in the center. Each platter is coated with a magnetizable material to record data. Each platter surface is divided into tens of thousands of tracks. It’s like running tracks in sports.

Hint: Hard disk drives are very complex devices and can be easily damaged if you drop them to the ground.
Each track is divided into sectors. There are typically hundreds of sectors per track and each sector usually has the same length. A sector is the smallest unit for reading data from the disk. That is to say, even if you just need a portion of the data from a sector, the read-write head will read the entire sector to retrieve the data. Traditionally one sector stores 512 bytes of data. In 2009 the industry devised the 4K sector size format known as the advanced format to improve disk reliability and increase capacity. After January 2011, most new hard drives store 4096 bytes of data in one sector.
Physical Sector Size vs Logical Sector Size
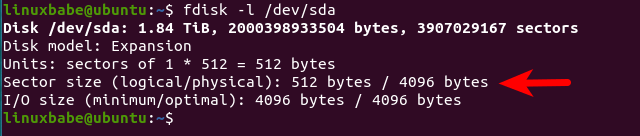
Although new hard drives use the 4K advanced format, operating systems still expect a 512 bytes sector size, so the firmware on the HDD divides a 4K physical sector into several logical sectors, typically 512 bytes. On Linux, you can check the physical sector size and logical sector size of an HDD with the fdisk command.
You can see from the screenshot that the physical sector size of my hard disk is 4096 bytes and the logical sector size is 512 bytes. I/O size is the minimal chunks of data the operating system reads from a disk.
Partition Alignment
Using firmware to produce a logical sector can degrade performance, especially when file system partitions are not aligned with physical sectors. There are two requirements for partition alignment:
- The number of sectors on each partition must be in multiples of 8 because a physical sector contains 8 logical sectors.
- The start sector of each partition must be the first logical sector in a physical sector. Since sector 0 is the first sector of the entire disk, this means the start sector of each partition should be a multiple of 8, sector 0, sector 8, sector 16, etc.
When you create partitions on a hard disk drive, you should be aware of the following two partition tables.
- MBR: Master Boot Record.
- GPT: GUID Partition Table.
If you buy a new hard disk, it’s recommended to use the newer GPT format to partition your hard disk. Both MBR and GPT will use some sectors at the beginning of the disk, so you should leave some empty space (like 1MiB) before the first partition. To create partitions that will be aligned with the physical sector, use sector as the unit when you partition your disk.
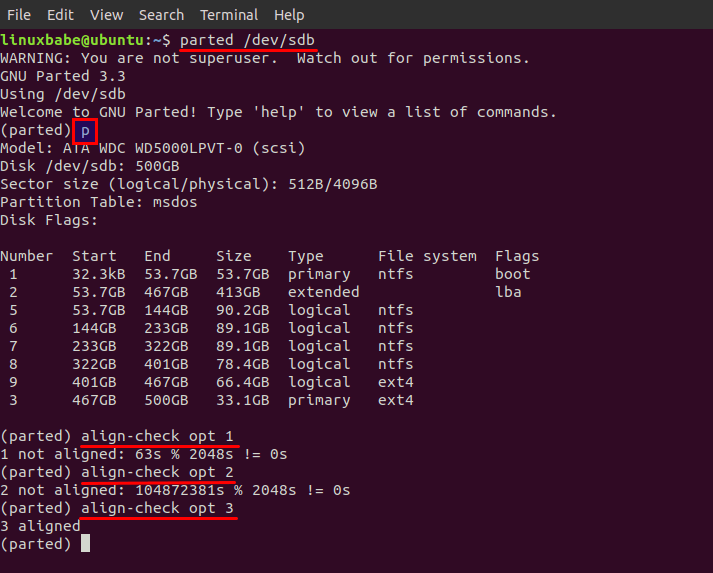
You can quickly check if your disk partitions are aligned with physical sectors with the parted (partition editor) utility. parted is a disk partition editor that supports multiple partition table formats, including MBR and GPT.
First, tell parted to use your disk. I use my /dev/sdb as an example.
Then type p to print the partition table on the disk. And run the following command to check partition alignment.
As you can see from the screenshot below, the first two partitions are not properly aligned. The third partition is aligned.
SSD Partition Alignment
Note that the structure of SSD is very different than that of an HDD. The smallest unit of an SSD module is called a cell. Consecutive cells form a page, many of which are organized into a block. Read and write operations are executed at the page level. The page size of an SSD varies from manufacturer to manufacturer and from model to model. There’s no straightforward way to check page size using the Linux command line, because the flash translation layer makes the OS think the SSD is a traditional hard disk. The OS doesn’t understand SSD pages and still uses sectors to describe locations on SSD.
Common page sizes are 8KiB, 16KiB, 32KiB. It’s also very important to have aligned partitions on SSD. If partitions are misaligned, then there will always be one extra page to read or write. Not only will it degrade performance, but also decreases the life span of SSD. To properly align partitions on SSD, all you need to do is to leave one empty page at the start of SSD and make sure the size of every partition on SSD is multiples of the page size.
Blocks in Filesystem
There’s a concept in filesystem called block, which is similar to a sector on disk drives. Many folks are confused by these two concepts. It’s not really that hard to understand the difference. When you create a partition on a disk, you can use sectors to define its size. If you format a partition with a file system, blocks will be created.
Operating system and file system access data on the disk in blocks rather than in sectors. A block is usually a multiple of sector. So why don’t we just access data in sectors? Well, the block can abstract away the physical details of the disk. If you address a sector (find out the address of a sector), you need to use the CHS scheme (cylinder-head-sector). This is because a hard disk drive has multiple platters. You need to know which platter and track the sector is located at. If you address a block, you just use block 0, block 1, block 2, etc, without having to know the physical details of the disk. Each block is mapped to a sector (or several sectors) with the logical block addressing (LBA) scheme.
Superblock
The first block of a disk or of a partition is called the superblock, and it’s the primary superblock. Superblock can be damaged like in a sudden power outage, so there are backup copies of the superblock in a block group.
- primary superblock
- backup superblock
Can’t read superblock
There can be several reasons why your OS can’t read the superblock on your HDD.
- The HDD is dropped to the ground and the superblock is damaged. This is usually physical damage to the corresponding sectors on the disk.
- There’s a sudden power outage. Because the superblock is cached in RAM, if a power outage happens, there might be important changes to the superblock that hasn’t been written to the disk.
If the primary superblock is damaged, you can’t mount the filesystem, and the operating system will probably tell you that it “can’t read superblock” if you try to mount the filesystem. We need to recover the bad superblock from backup copies. The following instructions show how to recover superblock for ext4 and Btrfs file system. My HDD is an external hard disk. If the damaged filesystem is your root file system, you need to boot your computer from a Linux Live USB stick.
Recover superblock on ext4 filesystem
Find out the device name of the damaged partition.
Determine the location of the backup superblocks.
It will tell you that the partition contains an ext4 file system, press y to continue. Don’t worry the -n option tells mke2fs not to create a file system.
At the bottom, you can see the location of backup superblocks. Next, restore the superblock from the first backup copy.
Now you should be able to mount your ext4 partition.
Recover superblock on btrfs filesystem
Find out the device name of the damaged partition.
Install a Btrfs utility.
Then run the following command to recover superblock.
If it tells you “All supers are valid, no need to recover”, then check the syslog.
You might find the following message, which indicates the log tree is corrupted, so it can’t replay the log.
Then you need to run the following command to clear the filesystem log tree.
![]()
Now you should be able to mount your Btrfs file system.
If there’s periodic IO failure for your Btrfs file system, you can add a crontab job to automatically clear the file system log tree once a day.
Add the following line at the end of the crontab file.
Save and close the file.
Backing Up Files on your Disk
To prevent data loss, it’s recommended to use a tool like Duplicati to automatically back up your files to cloud storage. Duplicati will encrypt your files to prevent prying eyes.
Wrapping Up
I hope this tutorial helped you fix the “can not read superblock” error on Linux. As always, if you found this post useful, then subscribe to our free newsletter to get more tips and tricks. Take care 🙂
Источник
Linux read block no
The result of O_NONBLOCK and O_NDELAY is to make I/O into non-blocking mode (non-blocking). When no data is read or the write buffer is full, it will return immediately without shelving program actions until There is data or writing is complete.
The difference between them is that setting up O_NDELAY will cause the I/O function to return 0 immediately, but another problem arises, because when the end of the file is read, the return is also 0, so it is impossible to know which situation is; therefore, O_NONBLOCK is generated, it will return -1 when the data cannot be read, and set errno to EAGAIN.
However, it should be noted that O_NDELAY in GNU C is only for compatibility with BSD programs. In fact, O_NONBLOCK is used as a macro definition, and O_NONBLOCK can be set at open in addition to being used in ioctl.
When opening the serial port without adding O_NODELAY, the second method below can be used to set blocking/non-blocking
Things to note
The effect on the read() function in raw mode:
c_cc[VTIME] The timeout time for reading in non-standard mode (unit: hundred milliseconds). It can be understood that it starts counting from the next byte after it is received. If it times out, exit READ
c_cc[VMIN] The minimum number of characters when reading in non-standard mode, set to 0 for non-blocking, if set to other values, block until the corresponding data is read
iFd = open(cSerialName, O_RDWR | O_NOCTTY);
Through the above settings, if there is no data in len=read(fd, tmp,124);, READ will exit after 3 seconds, but if the serial port has read data, it will return immediately
c_cc[VMIN], like a threshold, for example, set to 8. If only 3 data are received, then it will not return. Only after 8 data are collected will READ return, and it will be blocked there.
If you set it in this way, it will be completely blocked. Only when the serial port receives at least 8 data will it immediately return to READ, or when it is less than 8 data, it will return after 3 seconds of timeout.
Источник
read(3) — Linux man page
Prolog
Synopsis
Description
The read() function shall attempt to read nbyte bytes from the file associated with the open file descriptor, fildes, into the buffer pointed to by buf. The behavior of multiple concurrent reads on the same pipe, FIFO, or terminal device is unspecified.
Before any action described below is taken, and if nbyte is zero, the read() function may detect and return errors as described below. In the absence of errors, or if error detection is not performed, the read() function shall return zero and have no other results.
On files that support seeking (for example, a regular file), the read() shall start at a position in the file given by the file offset associated with fildes. The file offset shall be incremented by the number of bytes actually read.
Files that do not support seeking-for example, terminals-always read from the current position. The value of a file offset associated with such a file is undefined.
No data transfer shall occur past the current end-of-file. If the starting position is at or after the end-of-file, 0 shall be returned. If the file refers to a device special file, the result of subsequent read() requests is implementation-defined.
If the value of nbyte is greater than
When attempting to read from an empty pipe or FIFO: * If no process has the pipe open for writing, read() shall return 0 to indicate end-of-file. * If some process has the pipe open for writing and O_NONBLOCK is set, read() shall return -1 and set errno to [EAGAIN]. * If some process has the pipe open for writing and O_NONBLOCK is clear, read() shall block the calling thread until some data is written or the pipe is closed by all processes that had the pipe open for writing.
When attempting to read a file (other than a pipe or FIFO) that supports non-blocking reads and has no data currently available: * If O_NONBLOCK is set, read() shall return -1 and set errno to [EAGAIN]. * If O_NONBLOCK is clear, read() shall block the calling thread until some data becomes available. * The use of the O_NONBLOCK flag has no effect if there is some data available.
The read() function reads data previously written to a file. If any portion of a regular file prior to the end-of-file has not been written, read() shall return bytes with value 0. For example, lseek() allows the file offset to be set beyond the end of existing data in the file. If data is later written at this point, subsequent reads in the gap between the previous end of data and the newly written data shall return bytes with value 0 until data is written into the gap.
Upon successful completion, where nbyte is greater than 0, read() shall mark for update the st_atime field of the file, and shall return the number of bytes read. This number shall never be greater than nbyte. The value returned may be less than nbyte if the number of bytes left in the file is less than nbyte, if the read() request was interrupted by a signal, or if the file is a pipe or FIFO or special file and has fewer than nbyte bytes immediately available for reading. For example, a read() from a file associated with a terminal may return one typed line of data.
If a read() is interrupted by a signal before it reads any data, it shall return -1 with errno set to [EINTR].
If a read() is interrupted by a signal after it has successfully read some data, it shall return the number of bytes read.
For regular files, no data transfer shall occur past the offset maximum established in the open file description associated with fildes.
If fildes refers to a socket, read() shall be equivalent to recv() with no flags set.
If the O_DSYNC and O_RSYNC bits have been set, read I/O operations on the file descriptor shall complete as defined by synchronized I/O data integrity completion. If the O_SYNC and O_RSYNC bits have been set, read I/O operations on the file descriptor shall complete as defined by synchronized I/O file integrity completion.
If fildes refers to a shared memory object, the result of the read() function is unspecified.
If fildes refers to a typed memory object, the result of the read() function is unspecified.
A read() from a STREAMS file can read data in three different modes: byte-stream mode, message-nondiscard mode, and message-discard mode. The default shall be byte-stream mode. This can be changed using the I_SRDOPT ioctl() request, and can be tested with I_GRDOPT ioctl(). In byte-stream mode, read() shall retrieve data from the STREAM until as many bytes as were requested are transferred, or until there is no more data to be retrieved. Byte-stream mode ignores message boundaries.
In STREAMS message-nondiscard mode, read() shall retrieve data until as many bytes as were requested are transferred, or until a message boundary is reached. If read() does not retrieve all the data in a message, the remaining data shall be left on the STREAM, and can be retrieved by the next read() call. Message-discard mode also retrieves data until as many bytes as were requested are transferred, or a message boundary is reached. However, unread data remaining in a message after the read() returns shall be discarded, and shall not be available for a subsequent read(), getmsg(), or getpmsg() call.
How read() handles zero-byte STREAMS messages is determined by the current read mode setting. In byte-stream mode, read() shall accept data until it has read nbyte bytes, or until there is no more data to read, or until a zero-byte message block is encountered. The read() function shall then return the number of bytes read, and place the zero-byte message back on the STREAM to be retrieved by the next read(), getmsg(), or getpmsg(). In message-nondiscard mode or message-discard mode, a zero-byte message shall return 0 and the message shall be removed from the STREAM. When a zero-byte message is read as the first message on a STREAM, the message shall be removed from the STREAM and 0 shall be returned, regardless of the read mode.
A read() from a STREAMS file shall return the data in the message at the front of the STREAM head read queue, regardless of the priority band of the message.
By default, STREAMs are in control-normal mode, in which a read() from a STREAMS file can only process messages that contain a data part but do not contain a control part. The read() shall fail if a message containing a control part is encountered at the STREAM head. This default action can be changed by placing the STREAM in either control-data mode or control-discard mode with the I_SRDOPT ioctl() command. In control-data mode, read() shall convert any control part to data and pass it to the application before passing any data part originally present in the same message. In control-discard mode, read() shall discard message control parts but return to the process any data part in the message.
In addition, read() shall fail if the STREAM head had processed an asynchronous error before the call. In this case, the value of errno shall not reflect the result of read(), but reflect the prior error. If a hangup occurs on the STREAM being read, read() shall continue to operate normally until the STREAM head read queue is empty. Thereafter, it shall return 0.
The pread() function shall be equivalent to read(), except that it shall read from a given position in the file without changing the file pointer. The first three arguments to pread() are the same as read() with the addition of a fourth argument offset for the desired position inside the file. An attempt to perform a pread() on a file that is incapable of seeking shall result in an error.
Return Value
Upon successful completion, read() and pread() shall return a non-negative integer indicating the number of bytes actually read. Otherwise, the functions shall return -1 and set errno to indicate the error.
Errors
The read() and pread() functions shall fail if: EAGAIN The O_NONBLOCK flag is set for the file descriptor and the process would be delayed. EBADF The fildes argument is not a valid file descriptor open for reading. EBADMSG The file is a STREAM file that is set to control-normal mode and the message waiting to be read includes a control part. EINTR The read operation was terminated due to the receipt of a signal, and no data was transferred. EINVAL The STREAM or multiplexer referenced by fildes is linked (directly or indirectly) downstream from a multiplexer. EIO The process is a member of a background process attempting to read from its controlling terminal, the process is ignoring or blocking the SIGTTIN signal, or the process group is orphaned. This error may also be generated for implementation-defined reasons. EISDIR The fildes argument refers to a directory and the implementation does not allow the directory to be read using read() or pread(). The readdir() function should be used instead. EOVERFLOW The file is a regular file, nbyte is greater than 0, the starting position is before the end-of-file, and the starting position is greater than or equal to the offset maximum established in the open file description associated with fildes.
The read() function shall fail if: EAGAIN or EWOULDBLOCK
The file descriptor is for a socket, is marked O_NONBLOCK, and no data is waiting to be received. ECONNRESET A read was attempted on a socket and the connection was forcibly closed by its peer. ENOTCONN A read was attempted on a socket that is not connected. ETIMEDOUT A read was attempted on a socket and a transmission timeout occurred.
The read() and pread() functions may fail if: EIO A physical I/O error has occurred. ENOBUFS Insufficient resources were available in the system to perform the operation. ENOMEM Insufficient memory was available to fulfill the request. ENXIO A request was made of a nonexistent device, or the request was outside the capabilities of the device.
The pread() function shall fail, and the file pointer shall remain unchanged, if: EINVAL The offset argument is invalid. The value is negative. EOVERFLOW The file is a regular file and an attempt was made to read at or beyond the offset maximum associated with the file. ENXIO A request was outside the capabilities of the device. ESPIPE fildes is associated with a pipe or FIFO.
The following sections are informative.
Examples
Reading Data into a Buffer
The following example reads data from the file associated with the file descriptor fd into the buffer pointed to by buf.
Application Usage
Rationale
This volume of IEEE Std 1003.1-2001 does not specify the value of the file offset after an error is returned; there are too many cases. For programming errors, such as [EBADF], the concept is meaningless since no file is involved. For errors that are detected immediately, such as [EAGAIN], clearly the pointer should not change. After an interrupt or hardware error, however, an updated value would be very useful and is the behavior of many implementations.
Note that a read() of zero bytes does not modify st_atime. A read() that requests more than zero bytes, but returns zero, shall modify st_atime.
Implementations are allowed, but not required, to perform error checking for read() requests of zero bytes.
Input and Output
The use of I/O with large byte counts has always presented problems. Ideas such as lread() and lwrite() (using and returning longs) were considered at one time. The current solution is to use abstract types on the ISO C standard function to read() and write(). The abstract types can be declared so that existing functions work, but can also be declared so that larger types can be represented in future implementations. It is presumed that whatever constraints limit the maximum range of size_t also limit portable I/O requests to the same range. This volume of IEEE Std 1003.1-2001 also limits the range further by requiring that the byte count be limited so that a signed return value remains meaningful. Since the return type is also a (signed) abstract type, the byte count can be defined by the implementation to be larger than an int can hold.
The standard developers considered adding atomicity requirements to a pipe or FIFO, but recognized that due to the nature of pipes and FIFOs there could be no guarantee of atomicity of reads of
This volume of IEEE Std 1003.1-2001 requires that no action be taken for read() or write() when nbyte is zero. This is not intended to take precedence over detection of errors (such as invalid buffer pointers or file descriptors). This is consistent with the rest of this volume of IEEE Std 1003.1-2001, but the phrasing here could be misread to require detection of the zero case before any other errors. A value of zero is to be considered a correct value, for which the semantics are a no-op.
I/O is intended to be atomic to ordinary files and pipes and FIFOs. Atomic means that all the bytes from a single operation that started out together end up together, without interleaving from other I/O operations. It is a known attribute of terminals that this is not honored, and terminals are explicitly (and implicitly permanently) excepted, making the behavior unspecified. The behavior for other device types is also left unspecified, but the wording is intended to imply that future standards might choose to specify atomicity (or not).
There were recommendations to add format parameters to read() and write() in order to handle networked transfers among heterogeneous file system and base hardware types. Such a facility may be required for support by the OSI presentation of layer services. However, it was determined that this should correspond with similar C-language facilities, and that is beyond the scope of this volume of IEEE Std 1003.1-2001. The concept was suggested to the developers of the ISO C standard for their consideration as a possible area for future work.
In 4.3 BSD, a read() or write() that is interrupted by a signal before transferring any data does not by default return an [EINTR] error, but is restarted. In 4.2 BSD, 4.3 BSD, and the Eighth Edition, there is an additional function, select(), whose purpose is to pause until specified activity (data to read, space to write, and so on) is detected on specified file descriptors. It is common in applications written for those systems for select() to be used before read() in situations (such as keyboard input) where interruption of I/O due to a signal is desired.
The issue of which files or file types are interruptible is considered an implementation design issue. This is often affected primarily by hardware and reliability issues.
There are no references to actions taken following an «unrecoverable error». It is considered beyond the scope of this volume of IEEE Std 1003.1-2001 to describe what happens in the case of hardware errors.
Previous versions of IEEE Std 1003.1-2001 allowed two very different behaviors with regard to the handling of interrupts. In order to minimize the resulting confusion, it was decided that IEEE Std 1003.1-2001 should support only one of these behaviors. Historical practice on AT&T-derived systems was to have read() and write() return -1 and set errno to [EINTR] when interrupted after some, but not all, of the data requested had been transferred. However, the U.S. Department of Commerce FIPS 151-1 and FIPS 151-2 require the historical BSD behavior, in which read() and write() return the number of bytes actually transferred before the interrupt. If -1 is returned when any data is transferred, it is difficult to recover from the error on a seekable device and impossible on a non-seekable device. Most new implementations support this behavior. The behavior required by IEEE Std 1003.1-2001 is to return the number of bytes transferred.
IEEE Std 1003.1-2001 does not specify when an implementation that buffers read()ss actually moves the data into the user-supplied buffer, so an implementation may chose to do this at the latest possible moment. Therefore, an interrupt arriving earlier may not cause read() to return a partial byte count, but rather to return -1 and set errno to [EINTR].
Consideration was also given to combining the two previous options, and setting errno to [EINTR] while returning a short count. However, not only is there no existing practice that implements this, it is also contradictory to the idea that when errno is set, the function responsible shall return -1.
Future Directions
See Also
fcntl(), ioctl(), lseek(), open(), pipe(), readv(), the Base Definitions volume of IEEE Std 1003.1-2001, Chapter 11, General Terminal Interface, , ,
Источник



