- How to restart CentOS or RHEL server safely
- Restarting CentOS or RHEL server safely over ssh
- Best way to gracefully restart CentOS or RHEL
- Understanding reboot or ‘systemctl reboot’ or ‘shutdown -r now’ commands
- When should I use the old shutdown command?
- linux-notes.org
- Перезагрузка/выключение компьютера из командной строки
- Перезагрузка компьютера из командной строки
- Выключение компьютера из командной строки
- Добавить комментарий Отменить ответ
- 🐧 Как безопасно перезапустить сервер CentOS или RHEL
- Безопасный перезапуск сервера CentOS или RHEL через ssh
- Лучший способ правильно перезапустить CentOS или RHEL
- Что такое перезагрузка, команды systemctl reboot или shutdown -r now
- Когда следует использовать старую команду shutdown?
- Как узнать дату и время перезагрузки системы CentOS / RHEL?
- Заключение
- Red Hat Customer Portal
- Log in to Your Red Hat Account
- Red Hat Account
- Customer Portal
- Select Your Language
- How to distinguish between a crash and a graceful reboot in RHEL 7 or RHEL 8
- (1) Inspect wtmp with last -x
- (2) Inspect auditd logs with ausearch
- (3) Create a custom service unit
- (4) Inspect previous boots in persistent systemd journal with journalctl
- Записки Джоя: процесс загрузки Red Hat Linux
- Power-On Self Test
- Главная загрузочная запись
- Загрузчик
- Стадии GRUB
- Stage1
- Stage1_5
- Stage2
- /boot/grub/grub.conf
- Загрузка вручную с использованием автодополнения GRUB
- Уровни исполнения
- Login
How to restart CentOS or RHEL server safely
There is no graceful shutdown or restart. However, modern Linux distro does an outstanding job when you need to reboot the server powered by CentOS or RHEL. Let us different options to restart the CentOS/RHEL 7/8 server.
| Tutorial details | |
|---|---|
| Difficulty level | Easy |
| Root privileges | Yes |
| Requirements | RHEL or CentOS |
| Est. reading time | 2m |
Restarting CentOS or RHEL server safely over ssh
RHEL/CentOS Linux commands that we can use to restart the server carefully:
- shutdown command : All in one command to halt, power-off or reboot the machine.
- systemctl command : Systemd’s systemctl command can reboot or shutdown your server too.
- reboot command : Symbolic link and aliased to /sbin/systemctl to restart the CentOS/RHEL.
- halt command : Again, symbolic link and alias set to /sbin/systemctl to halt the CentOS/RHEL. Shut down and halt the system. You still need to press the power-off button manually.
- poweroff command : Symlink or soft link to /sbin/systemctl to power off your CentOS/RHEL box. Shut down and poweroff the system complety. Please note that there is no need to press the power off button.
The last three command acts as a shortcut to a longer command and saves some typing. Instead of typing “ sudo shutdown -r now “, we can type “ sudo reboot “.
Best way to gracefully restart CentOS or RHEL
The procedure is:
- Synchronize cached writes to persistent storage as root user by flushing everything to avoid problem with PostgreSQL/MySQL/MariaDB, run:
# sync;sync - Restart the CentOS/RHEL server, run:
# shutdown -r now - An alternative and recommended way is to type as shutdown/reboot is soft link to /sbin/systemctl:
# systemctl reboot
OR
# systemctl poweroff # complete power off - Personally, if I were you, I would shutdown the database server before issuing the reboot command. Hence:
# sync;sync
# systemctl stop postgresql
# systemctl stop mysql # MySQL/MariDB
# systemctl reboot
Understanding reboot or ‘systemctl reboot’ or ‘shutdown -r now’ commands
Open the terminal and run the following command:
ls -l /sbin/
Modern CentOS/RHEL symlinked to systemctl
Please do not pass the —force option to the systemct as it will reboot the box immediately without terminating any processes or unmounting any file systems. This will result in data loss for sure. Therefore avoid the following:
# systemctl —force —force reboot
# systemctl —force —force shutdown
So why —force option provided? It can be used in an emergency when the CentOS/RHEL system manager has crashed, and you need to shutdown the server. Hence, keeping verified backups are important for your systems.
When should I use the old shutdown command?
The shutdown command has additional options, including backward compatibility. For instance, display a message:
Источник
linux-notes.org

Перезагрузка/выключение компьютера из командной строки
Хотелось бы рассказать как правильно выключать/перезапускать компьютер или сервер с командной строки. Некоторые могут сказать что есть всего пару команд которые позволяют это сделать, но я постараюсь привести как можно больше готовых примеров. Некоторые, знают не все возможности Unix/Linux. В этой статье «Перезагрузка/выключение компьютера из командной строки» я приведу готовые примеры по выключению и перезагрузки серверов под управлением ОС Unix и Linux.
Для начала, нужно открыть консоль (терминал). После чего, выполнить одну из команд что ниже.
Перезагрузка компьютера из командной строки
Самый простой способ перезапустить сервер, использовать следующую команду:
Вас попросят ввести пароль от пользователя с правами «суперпользователя» или «root» и после чего сервер перезапустится.
Существует утилита под названием shutdown, которую тоже можно использовать для перезапуска:
Запланировать выключение системы на 09 часа 09 минут:
Для отмены запланированного выключения служит команда:
Так же, можно перезапустить ПК еще одной командой:
Выключение компьютера из командной строки
Самый простой способ выключить ПК или сервер с командной строки — это использовать утилиту shutdown:
Можно указать время через которое он выключиться сам ( минуты), я укажу 120 мин (2ч) в качестве примера:
Есть и другой способ выключить сервер, для этого служит еще одна команда:
Вот еще один вариант выключить свой сервер/ПК:
Если нужно выключить вашу ОС, можно использовать:
Запланируем выключение сервера или своего ПК на нормальное (корректное) выключение, скажем, на 23:59 и отправим задание в фоновый режим:
Тоже способ выключения системы:
Тема «Перезагрузка/выключение компьютера из командной строки» завершена. Надеюсь было познавательно.
Добавить комментарий Отменить ответ
Этот сайт использует Akismet для борьбы со спамом. Узнайте, как обрабатываются ваши данные комментариев.
Источник
🐧 Как безопасно перезапустить сервер CentOS или RHEL
Я использую команду reboot, чтобы перезагрузить сервер PostgreSQL, работающий на RHEL 7.
У нас также есть сервер разработки, работающий на CentOS 7.
Однако иногда я замечал повреждение базы данных или проблемы с файлами.
Есть ли такая команда безопасной перезагрузки, которая выполнит плавную перезагрузку нашего сервера CentOS или RHEL 7 без каких-либо проблем?
Как лучше всего перезапустить CentOS / RHEL через ssh?
Вообще нету корректного выключения или перезапуска.
Однако современный дистрибутив Linux отлично справляется с задачей, когда вам нужно перезагрузить сервер на базе CentOS или RHEL.
Давайте рассмотрим разные варианты перезапуска сервера CentOS / RHEL 7/8.
Безопасный перезапуск сервера CentOS или RHEL через ssh
- Команды RHEL / CentOS Linux, которые мы можем использовать для осторожного перезапуска сервера:
- Команда shutdown : все в одной команде для остановки, выключения или перезагрузки машины.
- Команда systemctl: команда Systemd systemctl также может перезагрузить или выключить ваш сервер.
- Команда reboot: символическая ссылка и алиас /sbin/systemctl для перезапуска CentOS / RHEL.
- Команда halt: опять же, символическая ссылка и алиас установлены на /sbin/systemctl, чтобы остановить CentOS / RHEL. Выключает и останавливает систему. Вам все равно нужно нажать кнопку выключения вручную.
- Команда poweroff: символическая ссылка или софт ссылка на /sbin/systemctl для выключения вашего CentOS / RHEL. Выключает и полностью отключает систему. Обратите внимание, что нет необходимости нажимать кнопку выключения питания.
Лучший способ правильно перезапустить CentOS или RHEL
Порядок действий такой:
Чтобы избежать проблем с PostgreSQL / MySQL / MariaDB, синхронизируйте кэшированные записи в постоянное хранилище от имени пользователя root, выполнив:
Перезагрузите сервер CentOS / RHEL, запустите:
Альтернативный и рекомендуемый способ, поскольку выключение / перезагрузка – это софт ссылка на /sbin/systemctl:
# systemctl reboot
или
# systemctl poweroff # полное выключение
Лично я на вашем месте я бы выключил сервер базы данных перед командой перезагрузки:
Что такое перезагрузка, команды systemctl reboot или shutdown -r now
Откройте терминал и выполните следующую команду:
Все вышеперечисленные команды будут:
- Останавливать все запущенные процессы/службы.
- Отключать все файловые системы.
- Стирать временные файлы на диске
- Система перезагрузится.
Пожалуйста, не передавайте параметр –force для systemctl, так как он немедленно перезагрузит компьютер без завершения каких-либо процессов или размонтирования каких-либо файловых систем.
Это обязательно приведет к потере данных.
Поэтому избегайте следующего:
Когда следует использовать старую команду shutdown?
Команда shutdown имеет дополнительные параметры, включая обратную совместимость.
Например, отобразить сообщение:
«now» означает немедленно.
Мы можем передать строку времени в формате «чч: мм» для часа/минут, указав время для выполнения выключения, указанное в 24-часовом формате.
В качестве альтернативы, это может быть синтаксис «+ m», относящийся к установленному количеству минут m с этого момента.
Обратите внимание, что «now» является алиасом для «+0», т.е. запускает немедленное завершение работы.
Если аргумент времени не указан, подразумевается «+1»:
Мы можем отменить отложенное завершение работы.
Это может использоваться для отмены эффекта вызова выключения с аргументом времени, который не равен «+0» или «now»:
sudo shutdown -c
Как узнать дату и время перезагрузки системы CentOS / RHEL?
Заключение
Вы узнали о правильном способе выключения или перезапуска вашего CentOS / RHEL, и мы также рекомендуем вам хранить проверенные резервные копии, чтобы избежать потери данных.
Источник
Red Hat Customer Portal
Log in to Your Red Hat Account
Your Red Hat account gives you access to your profile, preferences, and services, depending on your status.
If you are a new customer, register now for access to product evaluations and purchasing capabilities.
Need access to an account?
If your company has an existing Red Hat account, your organization administrator can grant you access.
Red Hat Account
Customer Portal
For your security, if you’re on a public computer and have finished using your Red Hat services, please be sure to log out.
Select Your Language
How to distinguish between a crash and a graceful reboot in RHEL 7 or RHEL 8
How can you distinguish between a system crash and a graceful reboot or shutdown in RHEL 7 or RHEL 8? This article outlines 4 approaches:
(1) Inspect wtmp with last -x
With a simple last -Fxn2 shutdown reboot command, the system wtmp file reports the two most recent shutdowns or reboots. reboot denotes the system booting up; whereas, shutdown denotes the system going down.
A graceful shutdown would show up as a reboot line followed by shutdown line, as in the following example:
Note: events from last are printed in descending chronological order, with most recent at the top.
An ungraceful shutdown can be inferred by the omission of shutdown; instead there will either be a single reboot line (if the wtmp file had been truncated/rotated prior to the crash) or 2 reboot lines in a row, as in this example:
(2) Inspect auditd logs with ausearch
auditd is great and all the different events that it logs can be seen by checking ausearch -m . Apropos to the problem at hand, it logs system shutdown and system boot as above. The command ausearch -i -m system_boot,system_shutdown | tail -4 will report the 2 most recent shutdowns or boots. If this reports a SYSTEM_SHUTDOWN followed by a SYSTEM_BOOT, all is well; however, if it reports 2 SYSTEM_BOOT lines in a row or only a single SYSTEM_BOOT line, then the system did not shutdown gracefully.
Graceful shutdown:
Note: as the timestamps should make clear, events from ausearch are printed in ascending chronological order, with oldest at the top.
Ungraceful shutdown:
Another ungraceful shutdown:
Presence of only one SYSTEM_BOOT record could be explained by the system being up for so long prior to the crash that audit logs of the previous reboot had been rotated out . so that the only result is from when the system was just booted.
(3) Create a custom service unit
Note: If you’re trying to diagnose a potential crash right now, this will not help. You need to set it up first.
This approach is great because it allows for complete control. Here’s an example of how to do it.
Create a service that runs only at shutdown
(Optionally customize the service name and the graceful_shutdown file)
Create a service that runs only at startup and only IF the graceful_shutdown file created by the above service exists
(Optionally customize the service name and ensure the graceful_shutdown file matches the above service)
Any time after a graceful reboot, systemctl is-active check_graceful would be able to confirm the previous reboot was graceful.
Example output:
After a crash or otherwise ungraceful shutdown, the following would be seen:
(4) Inspect previous boots in persistent systemd journal with journalctl
Note: If you’re trying to diagnose a potential crash right now, this will not help unless you have previously configured systemd to persist the journal to disk.
Configure systemd-journald to keep a persistent journal on-disk
Either update /etc/systemd/journald.conf or create the dir yourself as follows
Optionally use journalctl —list-boots to get a list of boots in ascending chronological order
0 refers to current runtime logs since the system was booted; -1 covers logs from the previous boot; -2 the boot before that, etc
Example:
Use journalctl -b -1 -n to look at the last 10 lines of the previous boot
The following example output shows that the previous system reboot was graceful
Note from the author: In my experiences troubleshooting RHEL 7 problems for customers in Red Hat support (in the years leading up to 2016 when I wrote this article), this was somewhat less reliable than the other methods. When bad things happen, it was definitely possible for the indexing in journald to get so bad that the journalctl -b -1 command only gives an error. I’m unsure if this has been improved in later versions of RHEL 7 and RHEL 8.
Источник
Записки Джоя: процесс загрузки Red Hat Linux
Чтобы эффективно решать проблемы системы Linux, возникающие в процессе загрузки, очень важно хорошо этот процесс понимать. Например, в предыдущую смену кто-то выполнил незадокументированные изменения критического файла, которые оказывают влияние на процесс загрузки. Теперь, в свою смену, вы останавливаете машину для обновления аппаратной части. При последующей загрузке система терпит крах, и вы ничем больше не можете заниматься, пока не решите проблему. Изучение шагов загрузки и понимание того, что происходит во время каждой фазы, поможет вам быстро диагностировать любые возникающие неполадки.
Многие современные дистрибутивы прячут процесс загрузки от пользователя, используя экран-заставку (splash screen), который, как правило, можно сбросить, нажав клавишу или ещё какую-то комбинацию клавиш в то время, когда заставка отображается; также может потребоваться удалить фрагмент rhgb quiet (для дистрибутивов, основанных на Red Hat) из строки kernel в /boot/grub/grub.conf . Поскольку дистрибутивов Linux существует великое множество, вам нужно уточнить процедуру сброса заставки (если в этом есть необходимость) в документации к вашему дистрибутиву.
Не лишним будет заметить: вы должны познакомиться с процессом загрузки до того, как проблемы возникнут. В процесс загрузки включено несколько важных файлов, и ошибки, скажем, в /boot/grub/grub.conf , /etc/fstab или /etc/inittab наверняка приведут к возникновению проблем. Так что, дополнительно к пониманию процесса загрузки, неплохо бы действительно изучить и эти файлы.
Предупреждение: если вы что-то делаете с /boot/grub/grub.conf или другим критически важным конфигурационным файлом, выполняйте это только на тестовом компьютере (в «песочнице»), пока вы полностью не начнёте понимать суть изменений. Я, чтобы приобрести опыт восстановления системы, моделируя различные проблемы загрузки, использую программу виртуализации Virtualbox.
[Когда работаете с важными файлами и у вас нет полной уверенности в ваших действиях, создание резервных копий не раз вас спасёт. Как минимум, следует сделать копию (а ещё лучше — серию копий) такого файла до того, как вы начнёте его изменять (например, grub.conf.3.orig для grub.conf ), поскольку иногда критические ошибки некоторое время остаются незамеченными. — прим.ред.]
Power-On Self Test
 Первое, с чего начинается процесс загрузки — это самотестирование оборудования (POST), которое выполняется базовой системой ввода-вывода (BIOS) компьютера при включении питания. Задача этого самотестирования — внутренняя проверка компонентов системы. Способ, которым оно осуществляется, может отличаться для разных архитектур, но цель одна и та же. Обычно эта проверка распространяется на память системы (RAM), процессор, видеокарту, жёсткие диски и другие компоненты материнской платы. Многие платы расширения, такие как RAID-контроллеры, проводят собственную самопроверку. При возникновении ошибки генерируется или выводится на панель или консоль то или иное предупреждение; для сообщения об определённых ошибках POST использует последовательности звуковых сигналов. Если всё проходит нормально, BIOS считывает главную загрузочную запись (MBR) с жёсткого диска и загружает программу, которая там будет обнаружена, в память.
Первое, с чего начинается процесс загрузки — это самотестирование оборудования (POST), которое выполняется базовой системой ввода-вывода (BIOS) компьютера при включении питания. Задача этого самотестирования — внутренняя проверка компонентов системы. Способ, которым оно осуществляется, может отличаться для разных архитектур, но цель одна и та же. Обычно эта проверка распространяется на память системы (RAM), процессор, видеокарту, жёсткие диски и другие компоненты материнской платы. Многие платы расширения, такие как RAID-контроллеры, проводят собственную самопроверку. При возникновении ошибки генерируется или выводится на панель или консоль то или иное предупреждение; для сообщения об определённых ошибках POST использует последовательности звуковых сигналов. Если всё проходит нормально, BIOS считывает главную загрузочную запись (MBR) с жёсткого диска и загружает программу, которая там будет обнаружена, в память.
[Если говорить точнее, то MBR считывается не обязательно с жёсткого диска. В настройках BIOS можно задать последовательность проверки загрузочных устройств (жёсткий диск, CD-привод, дискета и т.п.), и программа-загрузчик будет считана с первого устройства, на котором она будет обнаружена — прим.перев.]
Главная загрузочная запись
 Главная загрузочная запись (MBR) — это первые 512 байт загрузочного устройства, которые BIOS считывает в оперативную память. (Предполагается, что мы используем архитектуру x86.) Первые 446 байт из этих 512-ти обычно содержат низкоуровневый загрузочный код, ссылающийся на программу-загрузчик, размещаемую где-то в другом месте диска; он может даже указывать на другой диск. Следующие 64 байта содержат таблицу разделов диска (четыре 16-байтных записи, известных как схема основных разделов, или IBM Partition Table Scheme). Наконец, оставшиеся 2 байта — это так называемое «магическое число», используемое для обнаружения ошибок [по этой сигнатуре BIOS также определяет, является ли устройство загрузочным — прим.перев.].
Главная загрузочная запись (MBR) — это первые 512 байт загрузочного устройства, которые BIOS считывает в оперативную память. (Предполагается, что мы используем архитектуру x86.) Первые 446 байт из этих 512-ти обычно содержат низкоуровневый загрузочный код, ссылающийся на программу-загрузчик, размещаемую где-то в другом месте диска; он может даже указывать на другой диск. Следующие 64 байта содержат таблицу разделов диска (четыре 16-байтных записи, известных как схема основных разделов, или IBM Partition Table Scheme). Наконец, оставшиеся 2 байта — это так называемое «магическое число», используемое для обнаружения ошибок [по этой сигнатуре BIOS также определяет, является ли устройство загрузочным — прим.перев.].
Загрузчик
Назначение загрузчика — загрузить операционную систему. Существует множество загрузчиков, однако для Linux наиболее распространены LILO и GRUB. В Windows есть свой загрузчик — New Technology Loader (NTLDR). Временами вы можете сталкиваться с сообщением » NTLDR missing » — это сообщение об ошибке загрузчика Windows.
Независимо от того, какой именно загрузчик используется, важно помнить, что загрузчики очень сложны, и неопытный пользователь с правами root легко может привести его в неработоспособное состояние. На мой взгляд, экспериментировать и оттачивать свои навыки лучше всего только на машине, которую вы используете в качестве «песочницы», или в виртуальной среде. Одна-единственная опечатка при работе, скажем, с grub.conf , — и вы можете потерять больше времени на попытки исправить вашу ошибку, чем ожидали. Однако, если это происходит в «песочнице» и у вас есть время, вы приобретёте отличный опыт.
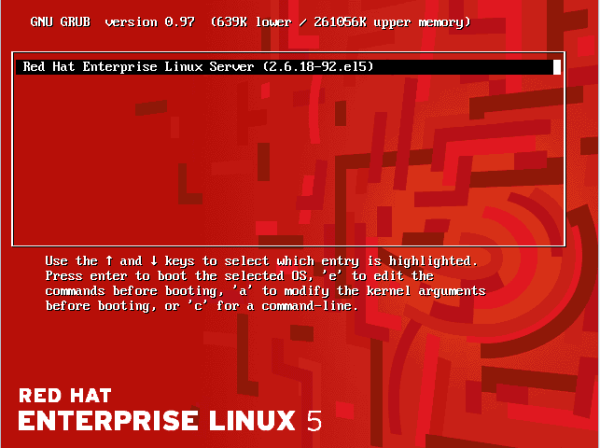 Наиболее распространённый загрузчик, используемый сегодня в современных системах Linux, — это GRand Unified Bootloader (GRUB). Именно о нём мы и будем здесь говорить. GRUB — это программа, которая записывается в MBR и раздел /boot жёсткого диска и загружает операционную систему. Код загрузчика должен помещаться в 446 байт в MBR, но из-за постоянно повышающейся сложности операционных систем и необходимости загружать практически любую ОС, он значительно разросся в размерах. На данный момент часть кода загрузчика записывается в MBR, а оставшаяся — на раздел /boot . Кроме того, загрузчик GRUB имеет модульный дизайн и выполняет свою работу поэтапно, в несколько стадий, которые я рассмотрю лишь поверхностно.
Наиболее распространённый загрузчик, используемый сегодня в современных системах Linux, — это GRand Unified Bootloader (GRUB). Именно о нём мы и будем здесь говорить. GRUB — это программа, которая записывается в MBR и раздел /boot жёсткого диска и загружает операционную систему. Код загрузчика должен помещаться в 446 байт в MBR, но из-за постоянно повышающейся сложности операционных систем и необходимости загружать практически любую ОС, он значительно разросся в размерах. На данный момент часть кода загрузчика записывается в MBR, а оставшаяся — на раздел /boot . Кроме того, загрузчик GRUB имеет модульный дизайн и выполняет свою работу поэтапно, в несколько стадий, которые я рассмотрю лишь поверхностно.
Стадии GRUB
Работа GRUB делится на несколько стадий, называемых Stage1, Stage1_5 и Stage2. Ниже коротко рассматривается каждая из них.
Stage1
Код stage1 записывается в MBR. Из-за ограничений размера, stage1 обычно лишь указывает на следующую стадию GRUB — stage1_5 или stage2. GRUB может загружать или не загружать stage1_5, в зависимости от типа используемых файловых систем.
Stage1_5
Stage1_5 является промежуточным этапом между stage1 и stage2. Если вы посмотрите на содержимое каталога /boot/grub , то увидите различные файлы stage1_5, связанные с различными файловыми системами. Каждый файл Stage1_5 имеет дело с определённым типом файловой системы. Этот код позволяет правильно распознавать ФС и работать с ней.
В моём каталоге /boot/grub размещаются следующие stage1_5-файлы:
Stage2
Это основной образ GRUB, обычно размещающийся в файловой системе раздела /boot как файл /boot/grub/stage2 . Он считывает файл /boot/grub/grub.conf , чтобы получить конфигурационную информацию, указывающую, как будет загружаться ядро. [Конфигурационный файл также может называться menu.lst — прим.перев.] Он также поддерживает интерактивный интерфейс, позволяющий вам устранять проблемы, переустанавливать загрузчик или изменять поведение GRUB. Stage2 предоставляет пользователю графическое меню загрузки. Если за отведённое время не будет нажата соответствующая клавиша для входа в скрытое меню или ничего не будет выбрано за заданный в настройках промежуток времени, GRUB загрузит пункт по умолчанию.
GRUB имеет действительно полезную функцию автодополнения клавишей , помогающую запустить систему, если, к примеру, она перестала загружаться из-за ошибки в соответствующей строке вашего файла grub.conf . Мне много раз приходилось пользоваться этой возможностью, чтобы вновь заставить работать незагружающуюся систему.
/boot/grub/grub.conf
Этот файл определяет, какое ядро должно загружаться, а также файл образа initrd со всеми модулями, необходимыми для загрузки вашей системы.
Вот типичный для Red Hat Linux файл grub.conf :
Редактировать этот файл довольно просто, тем не менее, это довольно распространённый источник ошибок.
Ничего, кроме приглашения GRUB — и что теперь с этим делать? Если вы выполняете какие-нибудь изменения в этом файле, не забывайте сперва распечатывать его и делать резервную копию. Это спасёт вас, если вы сделаете опечатку. Бумажную копию можно будет использовать для повторного вызова опций, необходимых для того, чтобы загрузить вашу машину и исправить ошибку. Ошибки бывают разные, и имеет смысл хорошо познакомиться с некоторыми из наиболее распространённых, такими как неправильно заданное имя ядра или ошибочно определённый корневой раздел. Если вы всё же видите это приглашение GRUB, задайте себе следующий вопрос: «Что я должен сделать для восстановления системы?» Если на этот момент у вас нет никаких идей, но вы управляете системами Linux, вероятно, будет неплохо взять тестовую машину, смоделировать несколько ошибок в grub.conf и изучить ваш загрузчик. Ниже рассматривается, что нужно делать в подобной ситуации (обратите внимание на то, где я нажимаю клавишу , чтобы просмотреть доступные опции).
Загрузка вручную с использованием автодополнения GRUB
Строка root (hd0,0) определяет первый диск и первый раздел на этом диске. В строке kernel вы можете ввести ‘ / ‘, нажать и просмотреть доступные опции, затем выбрать одну из них, напечатать несколько букв (достаточных для однозначного определения опции), и пусть GRUB сам дополнит команду. Дополнительная опция » ro root=LABEL=/ » обусловлена моим опытом работы с системами Red Hat; ваш опыт может подсказывать вам иное, так что вам нужно будет проверить эти опции в вашем файле grub.conf . Аналогично поступаем со строкой initrd : после ‘ / ‘ нажимаете , чтобы GRUB отобразил все доступные варианты. Также у вас может возникнуть необходимость определить некоторые модули и дополнительные опции.
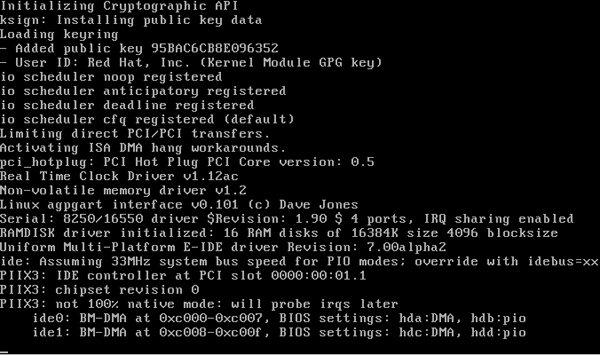 Когда загрузчик передаёт управление ядру и ядро начинает загружаться, на экран выводится масса разнообразной информации. В системах, основанных на Red Hat, этот вывод можно убрать, добавив в строке kernel опцию » rhgb quiet «. Она означает «тихую графическую загрузку» и будет подавлять загрузочные сообщения ядра. Когда мне нужно увидеть эти сообщения, я прерываю цикл GRUB нажатием клавиши , нажимаю для входа в режим редактирования (подсказка по модификации аргументов ядра есть внизу экрана GRUB) и изменяю строку kernel . Удаление » rhgb quiet » позволяет мне видеть сообщения ядра, так что я могу определить, есть ли среди них относящиеся, скажем, к панике ядра или подобным проблемам.
Когда загрузчик передаёт управление ядру и ядро начинает загружаться, на экран выводится масса разнообразной информации. В системах, основанных на Red Hat, этот вывод можно убрать, добавив в строке kernel опцию » rhgb quiet «. Она означает «тихую графическую загрузку» и будет подавлять загрузочные сообщения ядра. Когда мне нужно увидеть эти сообщения, я прерываю цикл GRUB нажатием клавиши , нажимаю для входа в режим редактирования (подсказка по модификации аргументов ядра есть внизу экрана GRUB) и изменяю строку kernel . Удаление » rhgb quiet » позволяет мне видеть сообщения ядра, так что я могу определить, есть ли среди них относящиеся, скажем, к панике ядра или подобным проблемам.
На этом этапе ядро тестирует ваше оборудование и подстраивается под него. Ядро также подгружает модули из образа initrd , которые требуются для работы с вашим оборудованием. Учтите, что эта информация очень быстро пробегает по экрану, так что если вы считаете, что ваша проблема лежит на уровне ядра, смотрите очень внимательно, и вы наверняка получите подсказку о том, где её искать. Когда ядро завершает свою инициализацию, оно запускает первый системный процесс — /sbin/init .
[Большая часть загрузочной информации доступна в файле /var/log/dmesg сразу после загрузки. — прим.ред.]
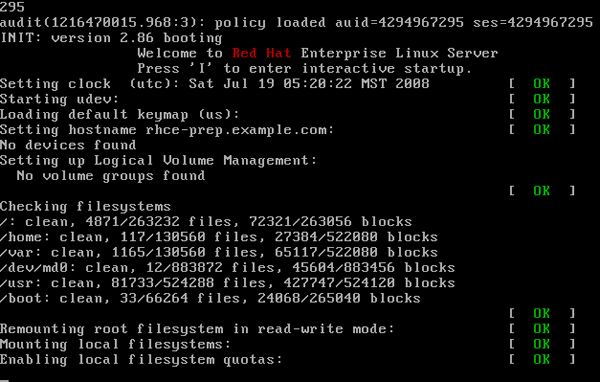 Init — это первый процесс, который запускается в вашей системе. Он считывает файл /etc/inittab , исполняет /etc/rc.d/rc.sysinit , затем переходит на уровень исполнения, определённый в /etc/inittab .
Init — это первый процесс, который запускается в вашей системе. Он считывает файл /etc/inittab , исполняет /etc/rc.d/rc.sysinit , затем переходит на уровень исполнения, определённый в /etc/inittab .
Init получает идентификатор процесса (PID), равный 1. На показанном выше рисунке есть строка » INIT: version 2.86 booting «. В этой точке процесса загрузки на сцену и выходит /sbin/init . В строке, следующей сразу за этой, видны сообщения, отображаемые сценарием командной оболочки /etc/rc.d/rc.sysinit ; фактически, весь экран занят сообщениями этого сценария, так что вы можете получить представление о функциях, которые он выполняет. Кроме того, init обычно запускает несколько копий /sbin/getty или /sbin/mingetty , которые обеспечивают работу ваших виртуальных терминалов. Благодаря им вы можете нажать комбинацию клавиш с + + по и попасть в соответствующий виртуальный терминал.
Теперь давайте рассмотрим файл /etc/inittab — конфигурационный файл для процесса init.
В зависимости от выполняемых действий на экран выводятся обычные диагностические сообщения, то есть [ OK ] или [Failed] , чтобы можно было решить возникающие проблемы. Вы, возможно, обратили внимание на сообщение » Press ‘I’ to enter interactive startup » (в системах на базе Red Hat). Оно говорит о выполнении rc.sysinit и предоставляет оператору определённый уровень контроля над находящейся в процессе загрузки системой. Работа rc.sysinit завершается переходом на уровень исполнения, который определён в /etc/inittab как уровень по умолчанию. Это ещё одно место возникновения ошибок, поскольку на серверах строка » id:5:initdefault: » обычно выставлена в 3, так что машина загружается на уровень 3 вместо 5. Ещё одна точка потенциальных ошибок — строка » ca::ctraltdel:/sbin/shutdown -t3 -r now «, закомментированная, чтобы избежать перезагрузки сервера «комбинацией из трёх пальцев» ( + + ). Люди есть люди, и им свойственно ошибаться. Мне попадались опечатки в обоих местах, приводившие к проблемам. В отличие от команды » mount -a «, которая сообщит вам о наличии ошибок в определении точек монтирования в файле /etc/fstab , выполнение команды » init q » приводит к повторному считыванию /etc/inittab , но не проверяет ошибки в самих уровнях исполнения, так что лучший способ узнать, есть ли ошибки, — это изучить этот файл и быть очень, очень аккуратным, если вы решите вносить изменения в любой из файлов /etc/rc*/* .
Уровни исполнения
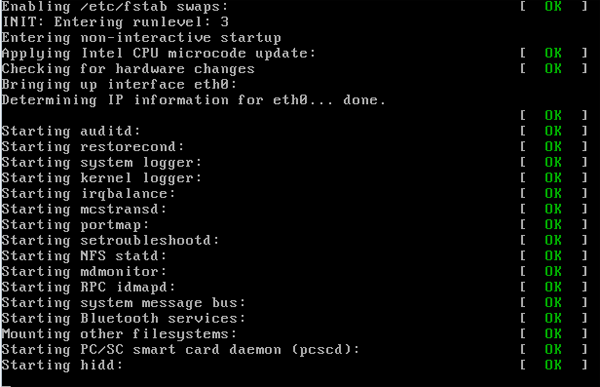 Когда система переходит на соответствующий уровень исполнения (runlevel), на экран продолжат выводиться сообщения процесса init (при условии, что ваша машина настроена на их вывод), опять-таки заканчивающиеся на [ OK ] или [Failed] , в зависимости от результата. Это сервисы, стартующие на ваших уровнях исполнения. Если вы посмотрите на свой файл /etc/inittab , вы найдёте там строку наподобие » id:5:initdefault: «. Это ваш уровень исполнения по умолчанию. На большинстве серверов он будет выставлен в 3, на рабочих станциях, конечно же, в 5, чтобы сеанс X Window System запускался сразу же после загрузки системы.
Когда система переходит на соответствующий уровень исполнения (runlevel), на экран продолжат выводиться сообщения процесса init (при условии, что ваша машина настроена на их вывод), опять-таки заканчивающиеся на [ OK ] или [Failed] , в зависимости от результата. Это сервисы, стартующие на ваших уровнях исполнения. Если вы посмотрите на свой файл /etc/inittab , вы найдёте там строку наподобие » id:5:initdefault: «. Это ваш уровень исполнения по умолчанию. На большинстве серверов он будет выставлен в 3, на рабочих станциях, конечно же, в 5, чтобы сеанс X Window System запускался сразу же после загрузки системы.
Чтобы узнать, какие процессы стартуют или останавливаются на том или ином уровне исполнения, следует заглянуть в каталог /etc/rcX.d (где X — интересующий вас уровень исполнения). Внутри этого каталога размещаются символьные ссылки на файлы в каталоге /etc/init.d . Имена файлов начинаются либо с ‘ K ‘, либо с ‘ S ‘ (означающих «останов» (kill) или «запуск» (start) соответствующего демона на этом уровне исполнения). Число сразу после этой буквы задаёт порядок выполнения сценария, так как они стартуют в алфавитном порядке. В системах, основанных на Red Hat, команда » chkconfig » изменяет символьные ссылки для запуска или останова демона на требуемом уровне. Соответственно, меняется буква ‘ S ‘ или ‘ K ‘, зачастую изменяется и следующее за ней число.
Login
Запуск этой утилиты подводит итог процессу загрузки типичной Linux-машины. На данном этапе вы должны уже лучше понимать, что происходит до того как на экране появится приглашение на вход в систему или диалоговое окно. В конце концов, всегда следует уделять внимание деталям: машина наверняка сама скажет вам, что не так, если у вас возникнут проблемы.
Источник



