- Поиск в Linux с помощью команды find
- Общий синтаксис
- Описание опций
- Примеры использования find
- Поиск файла по имени
- Поиск по дате
- По типу
- Поиск по правам доступа
- Поиск файла по содержимому
- С сортировкой по дате модификации
- Лимит на количество выводимых результатов
- Поиск с действием (exec)
- Чистка по расписанию
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Рекурсивно найти слово в файлах и папках Linux
- Найти фразу в файлах рекурсивно через консоль
- Поиск слова через Midnight Commander
- Команда Grep в Linux (поиск текста в файлах)
- Командный синтаксис grep
- Искать строку в файлах
- Инвертировать соответствие (исключить)
- Использование Grep для фильтрации вывода команды
- Рекурсивный поиск
- Показать только имя файла
- Поиск без учета регистра
- Искать полные слова
- Показать номера строк
- Подсчет совпадений
- Бесшумный режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск нескольких строк (шаблонов)
- Строки печати перед матчем
- Печатать строки после матча
- Выводы
Поиск в Linux с помощью команды find
Утилита find представляет универсальный и функциональный способ для поиска в Linux. Данная статья является шпаргалкой с описанием и примерами ее использования.
Общий синтаксис
— путь к корневому каталогу, откуда начинать поиск. Например, find /home/user — искать в соответствующем каталоге. Для текущего каталога нужно использовать точку «.».
— набор правил, по которым выполнять поиск.
* по умолчанию, поиск рекурсивный. Для поиска в конкретном каталоге можно использовать опцию maxdepth.
Описание опций
| Опция | Описание |
|---|---|
| -name | Поиск по имени. |
| -iname | Регистронезависимый поиск по имени. |
| -type | |
| -size | Размер объекта. Задается в блоках по 512 байт или просто в байтах (с символом «c»). |
| -mtime | Время изменения файла. Указывается в днях. |
| -mmin | Время изменения в минутах. |
| -atime | Время последнего обращения к объекту в днях. |
| -amin | Время последнего обращения в минутах. |
| -ctime | Последнее изменение владельца или прав на объект в днях. |
| -cmin | Последнее изменение владельца или прав в минутах. |
| -user | Поиск по владельцу. |
| -group | По группе. |
| -perm | С определенными правами доступа. |
| -depth | Поиск должен начаться не с корня, а с самого глубоко вложенного каталога. |
| -maxdepth | Максимальная глубина поиска по каталогам. -maxdepth 0 — поиск только в текущем каталоге. По умолчанию, поиск рекурсивный. |
| -prune | Исключение перечисленных каталогов. |
| -mount | Не переходить в другие файловые системы. |
| -regex | По имени с регулярным выражением. |
| -regextype | Тип регулярного выражения. |
| -L или -follow | Показывает содержимое символьных ссылок (симлинк). |
| -empty | Искать пустые каталоги. |
| -delete | Удалить найденное. |
| -ls | Вывод как ls -dgils |
| Показать найденное. | |
| -print0 | Путь к найденным объектам. |
| -exec <> \; | Выполнить команду над найденным. |
| -ok | Выдать запрос перед выполнением -exec. |
Также доступны логические операторы:
| Оператор | Описание |
|---|---|
| -a | Логическое И. Объединяем несколько критериев поиска. |
| -o | Логическое ИЛИ. Позволяем команде find выполнить поиск на основе одного из критериев поиска. |
| -not или ! | Логическое НЕ. Инвертирует критерий поиска. |
Полный набор актуальных опций можно получить командой man find.
Примеры использования find
Поиск файла по имени
1. Простой поиск по имени:
find / -name «file.txt»
* в данном примере будет выполнен поиск файла с именем file.txt по всей файловой системе, начинающейся с корня /.
2. Поиск файла по части имени:
* данной командой будет выполнен поиск всех папок или файлов в корневой директории /, заканчивающихся на .tmp
3. Несколько условий.
а) Логическое И. Например, файлы, которые начинаются на sess_ и заканчиваются на cd:
find . -name «sess_*» -a -name «*cd»
б) Логическое ИЛИ. Например, файлы, которые начинаются на sess_ или заканчиваются на cd:
find . -name «sess_*» -o -name «*cd»
в) Более компактный вид имеют регулярные выражения, например:
find . -regex ‘.*/\(sess_.*cd\)’
* где в первом поиске применяется выражение, аналогичное примеру а), а во втором — б).
4. Найти все файлы, кроме .log:
find . ! -name «*.log»
* в данном примере мы воспользовались логическим оператором !.
Поиск по дате
1. Поиск файлов, которые менялись определенное количество дней назад:
find . -type f -mtime +60
* данная команда найдет файлы, которые менялись более 60 дней назад.
2. Поиск файлов с помощью newer. Данная опция доступна с версии 4.3.3 (посмотреть можно командой find —version).
а) дате изменения:
find . -type f -newermt «2019-11-02 00:00»
* покажет все файлы, которые менялись, начиная с 02.11.2019 00:00.
find . -type f -newermt 2019-10-31 ! -newermt 2019-11-02
* найдет все файлы, которые менялись в промежутке между 31.10.2019 и 01.11.2019 (включительно).
б) дате обращения:
find . -type f -newerat 2019-10-08
* все файлы, к которым обращались с 08.10.2019.
find . -type f -newerat 2019-10-01 ! -newerat 2019-11-01
* все файлы, к которым обращались в октябре.
в) дате создания:
find . -type f -newerct 2019-09-07
* все файлы, созданные с 07 сентября 2019 года.
find . -type f -newerct 2019-09-07 ! -newerct «2019-09-09 07:50:00»
* файлы, созданные с 07.09.2019 00:00:00 по 09.09.2019 07:50
По типу
Искать в текущей директории и всех ее подпапках только файлы:
* f — искать только файлы.
Поиск по правам доступа
1. Ищем все справами на чтение и запись:
find / -perm 0666
2. Находим файлы, доступ к которым имеет только владелец:
find / -perm 0600
Поиск файла по содержимому
find / -type f -exec grep -i -H «content» <> \;
* в данном примере выполнен рекурсивный поиск всех файлов в директории / и выведен список тех, в которых содержится строка content.
С сортировкой по дате модификации
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r
* команда найдет все файлы в каталоге /data, добавит к имени дату модификации и отсортирует данные по имени. В итоге получаем, что файлы будут идти в порядке их изменения.
Лимит на количество выводимых результатов
Самый распространенный пример — вывести один файл, который последний раз был модифицирован. Берем пример с сортировкой и добавляем следующее:
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r | head -n 1
Поиск с действием (exec)
1. Найти только файлы, которые начинаются на sess_ и удалить их:
find . -name «sess_*» -type f -print -exec rm <> \;
* -print использовать не обязательно, но он покажет все, что будет удаляться, поэтому данную опцию удобно использовать, когда команда выполняется вручную.
2. Переименовать найденные файлы:
find . -name «sess_*» -type f -exec mv <> new_name \;
find . -name «sess_*» -type f | xargs -I ‘<>‘ mv <> new_name
3. Вывести на экран количество найденных файлов и папок, которые заканчиваются на .tmp:
find . -name «*.tmp» | wc -l
4. Изменить права:
find /home/user/* -type d -exec chmod 2700 <> \;
* в данном примере мы ищем все каталоги (type d) в директории /home/user и ставим для них права 2700.
5. Передать найденные файлы конвееру (pipe):
find /etc -name ‘*.conf’ -follow -type f -exec cat <> \; | grep ‘test’
* в данном примере мы использовали find для поиска строки test в файлах, которые находятся в каталоге /etc, и название которых заканчивается на .conf. Для этого мы передали список найденных файлов команде grep, которая уже и выполнила поиск по содержимому данных файлов.
6. Произвести замену в файлах с помощью команды sed:
find /opt/project -type f -exec sed -i -e «s/test/production/g» <> \;
* находим все файлы в каталоге /opt/project и меняем их содержимое с test на production.
Чистка по расписанию
Команду find удобно использовать для автоматического удаления устаревших файлов.
Открываем на редактирование задания cron:
0 0 * * * /bin/find /tmp -mtime +14 -exec rm <> \;
* в данном примере мы удаляем все файлы и папки из каталога /tmp, которые старше 14 дней. Задание запускается каждый день в 00:00.
* полный путь к исполняемому файлу find смотрим командой which find — в разных UNIX системах он может располагаться в разных местах.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Рекурсивно найти слово в файлах и папках Linux
Великая сила grep
2 минуты чтения
Дистрибутив Linux, несмотря на версию и вид, имеет множество графических оболочек, которые позволяют искать файлы. Большинство из их них позволяют искать сами файлы, но, к сожалению, они редко позволяют искать по содержимому. А особенно рекурсивно. В статье покажем два способа того, как можно рекурсивно найти файлы, которые содержат ту или иную фразу. Поиск будет осуществлен по папкам и директориям внутри этих папок.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Найти фразу в файлах рекурсивно через консоль
Все просто. Открываем серверную консоль, подключившись по SSH. А далее, вводим команду:
Например, команда может выглядеть вот так:
Команда найдет и выведет все файлы, которые содержат фразу merionet в директории /home/user/merion и во всех директориях, внутри этой папки. Мы используем следующие ключи:
- -i — игнорировать регистра текста (большие или маленькие буквы);
- -R — рекурсивно искать файлы в сабдиректориях;
- -I — показывать названия файлов, вместо их содержимого;
Так же, вам могут быть полезны следующие ключи:
- -n — показать номер строки, в которой находится фраза;
- -w — показать место, где слово попадается;

Поиск слова через Midnight Commander
Так же, в консоли сервера, дайте команду:
Эта команда запустит Midnight Commander. Кстати, если он у вас не установлен, его можно просто установить через yum:
Открыв mc, во вкладке Command выберите Find File и заполните поисковую форму как показано ниже:
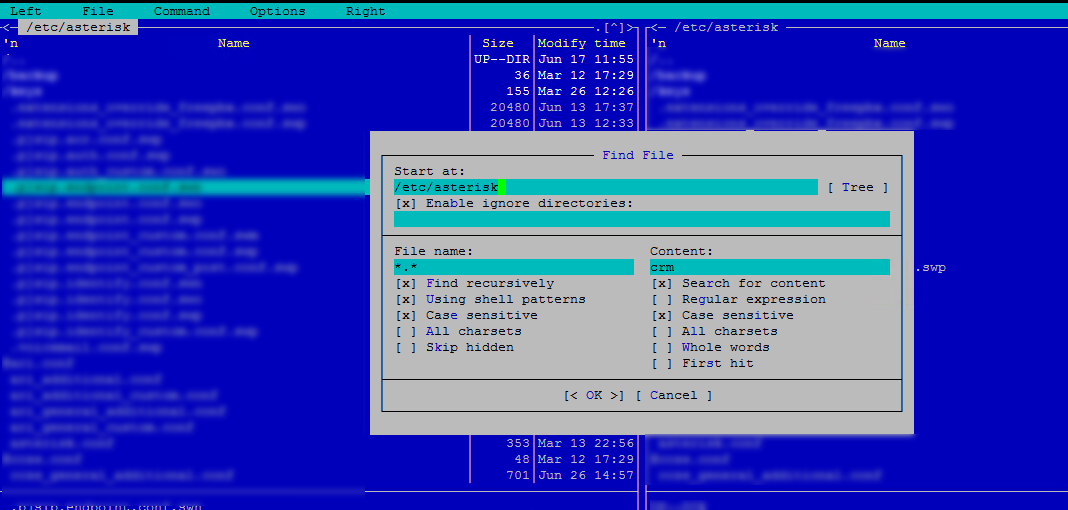
- Start at: — директория, где нужно осуществлять поиск;
- File name: — маска поиска. Например, искать только в файлах расширения txt будет — *.txt;
- Content — сама фраза;
Нажимаем OK и получаем результат:
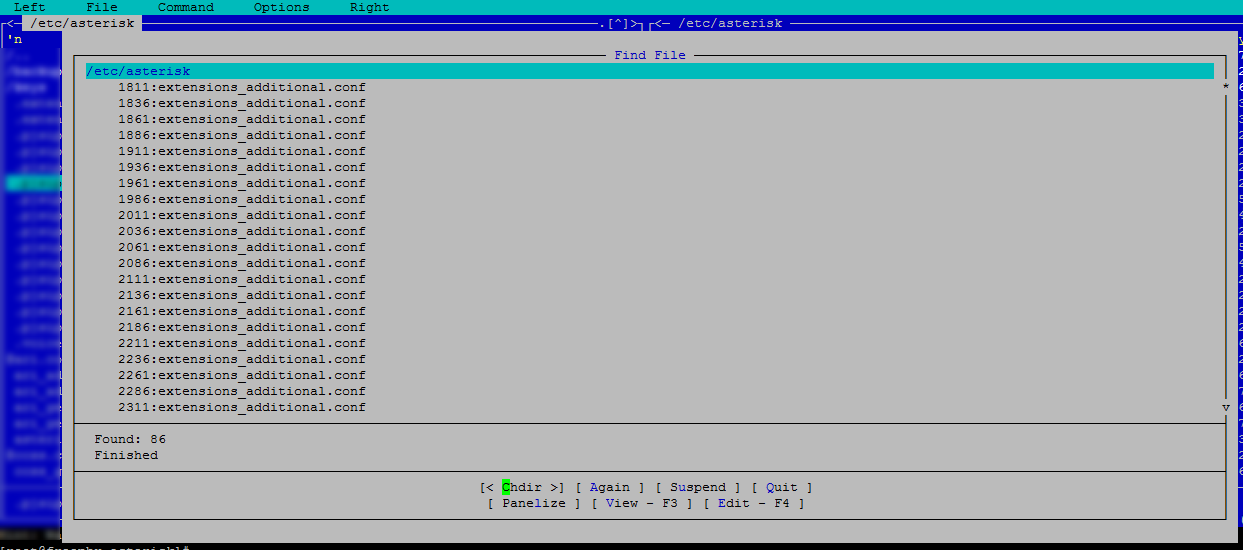
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
Команда Grep в Linux (поиск текста в файлах)
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
- OPTIONS — Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.
- PATTERN — Шаблон поиска.
- FILE — Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или —invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или —recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или —dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или —files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
Результат будет выглядеть примерно так:
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или —ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или —word-regexp ).
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
Показать номера строк
Параметр -n (или —line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или —count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
Бесшумный режим
-q (или —quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте символ $ (доллар), чтобы найти выражение в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте расширение . (точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используйте [^ ] для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и т. Д., Но не будет соответствовать строкам, содержащим cola ,
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
Строки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или —before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или —after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник



