- How to use sed to find and replace text in files in Linux / Unix shell
- Find and replace text within a file using sed command
- Syntax: sed find and replace text
- Examples that use sed to find and replace
- sed command problems
- How to use sed to match word and perform find and replace
- Recap and conclusion – Using sed to find and replace text in given files
- How to Replace a String in a File in Bash
- Replace String in a File with the `sed` Command
- Example 1: Replace File with the ‘sed’ Command
- Example 2: Replace File with the ‘sed’ Command with ‘g’ and ‘i’ Flag
- Example 3: Replace File with ‘sed’ Command and Matching Digit Pattern
- Replace String in a File with `awk` Command
- Example 4: Replace File with ‘awk’ Command
- Conclusion
- About the author
- Fahmida Yesmin
- Find and replace text within a file using commands
- 7 Answers 7
- Python
- How can I replace a string in a file(s)?
- 9 Answers 9
- 1. Replacing all occurrences of one string with another in all files in the current directory:
- 2. Replace only if the file name matches another string / has a specific extension / is of a certain type etc:
- 3. Replace only if the string is found in a certain context
- 4. Multiple replace operations: replace with different strings
- 5. Multiple replace operations: replace multiple patterns with the same string
How to use sed to find and replace text in files in Linux / Unix shell
Find and replace text within a file using sed command
The procedure to change the text in files under Linux/Unix using sed:
- Use Stream EDitor (sed) as follows:
- sed -i ‘s/old-text/new-text/g’ input.txt
- The s is the substitute command of sed for find and replace
- It tells sed to find all occurrences of ‘old-text’ and replace with ‘new-text’ in a file named input.txt
- Verify that file has been updated:
- more input.txt
Let us see syntax and usage in details.
| Tutorial details | |
|---|---|
| Difficulty level | Easy |
| Root privileges | No |
| Requirements | sed utility on Linux, macOS or Unix-like OS |
| Est. reading time | 4 minutes |
Syntax: sed find and replace text
The syntax is:
sed ‘s/word1/word2/g’ input.file
## *bsd/macos sed syntax#
sed ‘s/word1/word2/g’ input.file > output.file
sed -i ‘s/word1/word2/g’ input.file
sed -i -e ‘s/word1/word2/g’ -e ‘s/xx/yy/g’ input.file
## use + separator instead of / ##
sed -i ‘s+regex+new-text+g’ file.txt
The above replace all occurrences of characters in word1 in the pattern space with the corresponding characters from word2.
Examples that use sed to find and replace
Let us create a text file called hello.txt as follows:
$ cat hello.txt
The is a test file created by nixCrft for demo purpose.
foo is good.
Foo is nice.
I love FOO.
I am going to use s/ for substitute the found expression foo with bar as follows:
sed ‘s/foo/bar/g’ hello.txt
Sample outputs:
- No ads and tracking
- In-depth guides for developers and sysadmins at Opensourceflare✨
- Join my Patreon to support independent content creators and start reading latest guides:
- How to set up Redis sentinel cluster on Ubuntu or Debian Linux
- How To Set Up SSH Keys With YubiKey as two-factor authentication (U2F/FIDO2)
- How to set up Mariadb Galera cluster on Ubuntu or Debian Linux
- A podman tutorial for beginners – part I (run Linux containers without Docker and in daemonless mode)
- How to protect Linux against rogue USB devices using USBGuard
Join Patreon ➔
Please note that the BSD implementation of sed (FreeBSD/MacOS and co) does NOT support case-insensitive matching. You need to install gnu sed. Run the following command on Apple Mac OS:
$ brew install gnu-sed
######################################
### now use gsed command as follows ##
######################################
$ gsed -i ‘s/foo/bar/g I ‘ hello.txt
$ cat hello.txt
sed command problems
Consider the following text file:
$ cat input.txt
http:// is outdate.
Consider using https:// for all your needs.
Find word ‘http://’ and replace with ‘https://www.cyberciti.biz’:
sed ‘s/ http:// / https://www.cyberciti.biz /g’ input.txt
You will get an error that read as follows:
Our syntax is correct but the / delimiter character is also part of word1 and word2 in above example. Sed command allows you to change the delimiter / to something else. So I am going to use +:
sed ‘s+ http:// + https://www.cyberciti.biz +g’ input.txt
Sample outputs:
How to use sed to match word and perform find and replace
In this example only find word ‘love’ and replace it with ‘sick’ if line content a specific string such as FOO:
sed -i -e ‘/FOO/s/love/sick/’ input.txt
Use cat command to verify new changes:
cat input.txt
Recap and conclusion – Using sed to find and replace text in given files
The general syntax is as follows:
## find word1 and replace with word2 using sed ##
sed -i ‘s/word1/word2/g’ input
## you can change the delimiter to keep syntax simple ##
sed -i ‘s+word1+word2+g’ input
sed -i ‘s_word1_word2_g’ input
## you can add I option to GNU sed to case insensitive search ##
sed -i ‘s/word1/word2/gI’ input
sed -i ‘s_word1_word2_gI’ input
See BSD(used on macOS too) sed or GNU sed man page by typing the following command:
man sed
🐧 Get the latest tutorials on Linux, Open Source & DevOps via
Источник
How to Replace a String in a File in Bash
Sales.txt
Date Amount Area
01/01/2020 60000 Dhaka
10/02/2020 76000 Rajshahi
21/03/2020 54000 Khulna
15/04/2020 78000 Chandpur
17/05/2020 45000 Bogra
02/06/2020 67000 Comilla
Replace String in a File with the `sed` Command
The basic syntax of the `sed` command for replacing the particular string in a file is given below.
Syntax
Every part of the above syntax is explained below.
‘-i’ option is used to modify the content of the original file with the replacement string if the search string exists in the file.
‘s’ indicates the substitute command.
‘search_string’ contains the string value that will be searched in the file for replacement.
‘replace_string’ contains the string value that will be used to replace the content of the file that matches the ‘search_string’ value.
‘filename’ contains the filename where the search and replace will be applied.
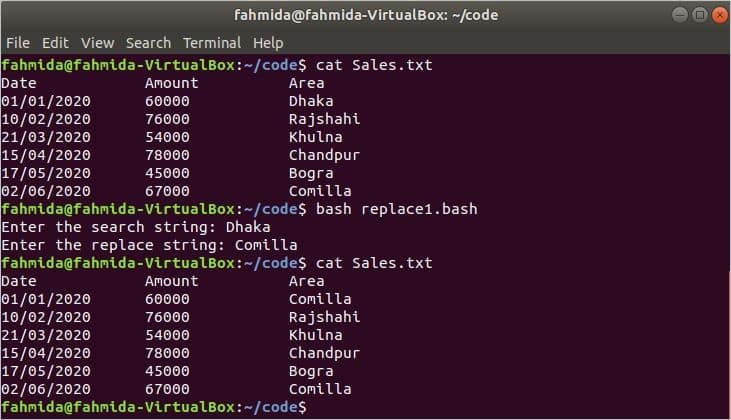
Example 1: Replace File with the ‘sed’ Command
In the following script, the search-and-replace text will be taken from the user. If the search string exists in ‘Sales.txt’, then it will be replaced by the replacement string. Here, a case-sensitive search will be performed.
# Assign the filename
filename = «Sales.txt»
# Take the search string
read -p «Enter the search string: » search
# Take the replace string
read -p «Enter the replace string: » replace
if [ [ $search ! = «» && $replace ! = «» ] ] ; then
sed -i «s/ $search / $replace /» $filename
fi
Output
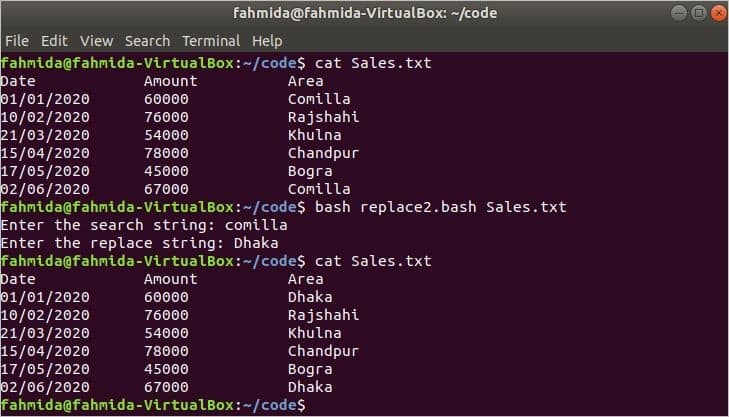
Example 2: Replace File with the ‘sed’ Command with ‘g’ and ‘i’ Flag
The following script will work like the previous example, but the search string will be searched globally for the ‘g’ flag, and the case-insensitive search will be done for the ‘i’ flag.
# Take the search string
read -p «Enter the search string: » search
# Take the replace string
read -p «Enter the replace string: » replace
if [ [ $search ! = «» && $replace ! = «» ] ] ; then
sed -i «s/ $search / $replace /gi» $1
fi
Output
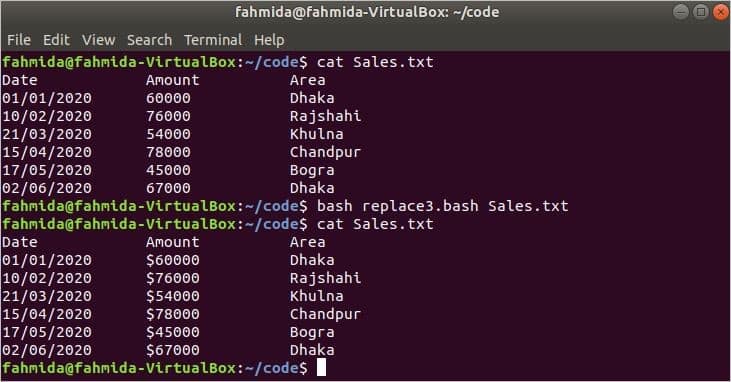
Example 3: Replace File with ‘sed’ Command and Matching Digit Pattern
The following script will search for all numerical content in a file and will replace the content by adding the ‘$’ symbol at the beginning of the numbers.
# Check the command line argument value exists or not
if [ $1 ! = «» ] ; then
# Search all string containing digits and add $
sed -i ‘s/\b5\<5\>\b/$&/g’ $1
fi
Output
Replace String in a File with `awk` Command
The ‘awk’ command is another way to replace the string in a file, but this command cannot update the original file directly like the ‘sed’ command.
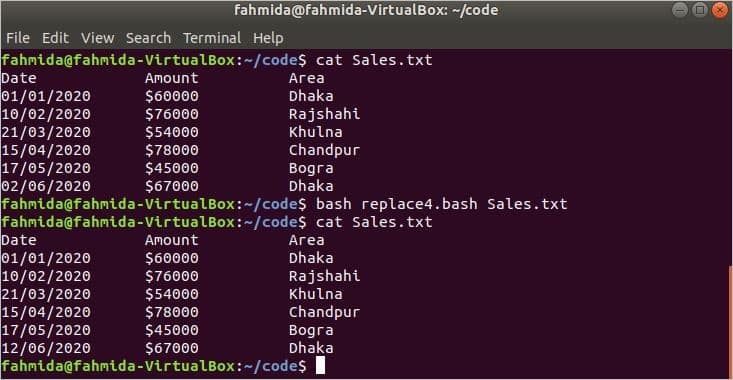
Example 4: Replace File with ‘awk’ Command
The following script will store the updated content in the temp.txt file that will be renamed by the original file.
# Check the command line argument value exists or not
if [ $1 ! = «» ] ; then
# Search all string based on date
awk ‘
fi
Output
Conclusion
This article showed you how to use bash scripts to replace particular strings in a file. The task to replace a string in a file should become easier for you after practicing the above examples.
About the author
Fahmida Yesmin
I am a trainer of web programming courses. I like to write article or tutorial on various IT topics. I have a YouTube channel where many types of tutorials based on Ubuntu, Windows, Word, Excel, WordPress, Magento, Laravel etc. are published: Tutorials4u Help.
Источник
Find and replace text within a file using commands
How can I find and replace specific words in a text file using command line?
7 Answers 7
- sed = Stream EDitor
- -i = in-place (i.e. save back to the original file)
The command string:
- s = the substitute command
- original = a regular expression describing the word to replace (or just the word itself)
- new = the text to replace it with
- g = global (i.e. replace all and not just the first occurrence)
file.txt = the file name
There’s multitude of ways to achieve it. Depending on the complexity of what one tries to achieve with string replacement, and depending on tools with which user is familiar, some methods may be preferred more than others.
In this answer I am using simple input.txt file, which you can use to test all examples provided here. The file contents:
Bash isn’t really meant for text processing, but simple substitutions can be done via parameter expansion , in particular here we can use simple structure $
This small script doesn’t do in-place replacement, meaning that you would have to save new text to new file, and get rid of the old file, or mv new.txt old.txt
Side note: if you’re curious about why while IFS= read -r ; do . done is used, it’s basically shell’s way of reading file line by line. See this for reference.
AWK, being a text processing utility, is quite appropriate for such task. It can do simple replacements and much more advanced ones based on regular expressions. It provides two functions: sub() and gsub() . The first one only replaces only the first occurrence, while the second — replaces occurrences in whole string. For instance, if we have string one potato two potato , this would be the result:
AWK can take an input file as argument, so doing same things with input.txt , would be easy:
Depending on the version of AWK you have, it may or may not have in-place editing, hence the usual practice is save and replace new text. For instance something like this:
Sed is a line editor. It also uses regular expressions, but for simple substitutions it’s sufficient to do:
What’s good about this tool is that it has in-place editing, which you can enable with -i flag.
Perl is another tool which is often used for text processing, but it’s a general purpose language, and is used in networking, system administration, desktop apps, and many other places. It borrowed a lot of concepts/features from other languages such as C,sed,awk, and others. Simple substitution can be done as so:
Like sed, perl also has the -i flag.
Python
This language is very versatile and is also used in a wide variety of applications. It has a lot of functions for working with strings, among which is replace() , so if you have variable like var=»Hello World» , you could do var.replace(«Hello»,»Good Morning»)
Simple way to read file and replace string in it would be as so:
With Python, however, you also need to output to new file , which you can also do from within the script itself. For instance, here’s a simple one:
Источник
How can I replace a string in a file(s)?
Replacing strings in files based on certain search criteria is a very common task. How can I
- replace string foo with bar in all files in the current directory?
- do the same recursively for sub directories?
- replace only if the file name matches another string?
- replace only if the string is found in a certain context?
- replace if the string is on a certain line number?
- replace multiple strings with the same replacement
- replace multiple strings with different replacements

9 Answers 9
1. Replacing all occurrences of one string with another in all files in the current directory:
These are for cases where you know that the directory contains only regular files and that you want to process all non-hidden files. If that is not the case, use the approaches in 2.
All sed solutions in this answer assume GNU sed . If using FreeBSD or macOS, replace -i with -i » . Also note that the use of the -i switch with any version of sed has certain filesystem security implications and is inadvisable in any script which you plan to distribute in any way.
Non recursive, files in this directory only:
Recursive, regular files (including hidden ones) in this and all subdirectories
If you are using zsh:
(may fail if the list is too big, see zargs to work around).
Bash can’t check directly for regular files, a loop is needed (braces avoid setting the options globally):
The files are selected when they are actual files (-f) and they are writable (-w).
2. Replace only if the file name matches another string / has a specific extension / is of a certain type etc:
Non-recursive, files in this directory only:
Recursive, regular files in this and all subdirectories
If you are using bash (braces avoid setting the options globally):
If you are using zsh:
The — serves to tell sed that no more flags will be given in the command line. This is useful to protect against file names starting with — .
If a file is of a certain type, for example, executable (see man find for more options):
3. Replace only if the string is found in a certain context
Replace foo with bar only if there is a baz later on the same line:
In sed , using \( \) saves whatever is in the parentheses and you can then access it with \1 . There are many variations of this theme, to learn more about such regular expressions, see here.
Replace foo with bar only if foo is found on the 3d column (field) of the input file (assuming whitespace-separated fields):
(needs gawk 4.1.0 or newer).
For a different field just use $N where N is the number of the field of interest. For a different field separator ( : in this example) use:
Another solution using perl :
NOTE: both the awk and perl solutions will affect spacing in the file (remove the leading and trailing blanks, and convert sequences of blanks to one space character in those lines that match). For a different field, use $F[N-1] where N is the field number you want and for a different field separator use (the $»=»:» sets the output field separator to : ):
Replace foo with bar only on the 4th line:
4. Multiple replace operations: replace with different strings
You can combine sed commands:
Be aware that order matters ( sed ‘s/foo/bar/g; s/bar/baz/g’ will substitute foo with baz ).
or Perl commands
If you have a large number of patterns, it is easier to save your patterns and their replacements in a sed script file:
Or, if you have too many pattern pairs for the above to be feasible, you can read pattern pairs from a file (two space separated patterns, $pattern and $replacement, per line):
That will be quite slow for long lists of patterns and large data files so you might want to read the patterns and create a sed script from them instead. The following assumes a space > delimiter separates a list of MATCH space >REPLACE pairs occurring one-per-line in the file patterns.txt :
The above format is largely arbitrary and, for example, doesn’t allow for a space > in either of MATCH or REPLACE. The method is very general though: basically, if you can create an output stream which looks like a sed script, then you can source that stream as a sed script by specifying sed ‘s script file as — stdin.
You can combine and concatenate multiple scripts in similar fashion:
A POSIX sed will concatenate all scripts into one in the order they appear on the command-line. None of these need end in a \n ewline.
grep can work the same way:
When working with fixed-strings as patterns, it is good practice to escape regular expression metacharacters. You can do this rather easily:
5. Multiple replace operations: replace multiple patterns with the same string
Replace any of foo , bar or baz with foobar
A good replacement Linux tool is rpl, that was originally written for the Debian project, so it is available with apt-get install rpl in any Debian derived distro, and may be for others, but otherwise you can download the tar.gz file from SourceForge.
Simplest example of use:
Note that if the string contains spaces it should be enclosed in quotation marks. By default rpl takes care of capital letters but not of complete words, but you can change these defaults with options -i (ignore case) and -w (whole words). You can also specify multiple files:
Or even specify the extensions ( -x ) to search or even search recursively ( -R ) in the directory:
You can also search/replace in interactive mode with -p (prompt) option:
The output shows the numbers of files/string replaced and the type of search (case in/sensitive, whole/partial words), but it can be silent with the -q (quiet mode) option, or even more verbose, listing line numbers that contain matches of each file and directory with -v (verbose mode) option.
Other options that are worth remembering are -e (honor escapes) that allow regular expressions , so you can search also tabs ( \t ), new lines ( \n ),etc. You can use -f to force permissions (of course, only when the user has write permissions) and -d to preserve the modification times`).
Finally, if you are unsure what exactly will happen, use the -s (simulate mode).
Источник



