- How To Run All Scripts In A Directory In Linux
- Run all scripts in a directory in Linux
- bash script read all the files in directory
- 3 Answers 3
- Not the answer you’re looking for? Browse other questions tagged linux bash or ask your own question.
- Linked
- Related
- Hot Network Questions
- Subscribe to RSS
- Get a list of all files in folder and sub-folder in a file
- 7 Answers 7
- tar: add all files and directories in current directory INCLUDING .svn and so on
- 16 Answers 16
- Execute command on all files in a directory
- 10 Answers 10
How To Run All Scripts In A Directory In Linux
The other day I have been testing some basic shell scripts that I created for fun. Since I am new to shell scripting, I ran and test the scripts one by one. It was OK if there are only a few scripts. As the number of scripts grew, I find it bit time consuming to test all of them. After a bit of web search, I find out a couple methods to run all scripts in a directory in Linux, one after another.
Run all scripts in a directory in Linux
I have a couple scripts in my Documents directory.
All of them are simple one-liner shell scripts that displays the given string(s) using «echo» command in the standard output.
Before I knew we can run all scripts in a folder, I would usually make the script executable like:
Then I run it using command:
Again, I make the second script executable and run it and so on.
Well, there is a better way to do this. We can run all scripts in a directory or path using «run-parts» command. The run-parts command is used to run scripts or programs in a directory or path.
One disadvantage with run-parts command is it won’t execute all scripts. It will work only if your scripts have the correct names. The names must consist entirely of ASCII upper-case and lower-case letters, ASCII digits, ASCII underscores, and ASCII minus-hyphens.
To resolve this naming problem, we can use the regex option. For example, the following command will find and run all script files in the
/Documents directory that starts with letter ‘s’ and end with ‘sh’ extension:

Run all scripts in a directory in Linux with run-parts command
Troubleshooting:
If you encountered with an error something like below;
Refer the following guide to fix it.
Similarly, to run all script files that ends with .sh in Documents directory, run:
To print the names of all files in the Documents directory that start with letter ‘s’ and end with ‘sh’ extension, run:
This command will only print the name the script files, but won’t execute them.
To list all files end with .sh in Documents directory, run:
The run-parts command is primarily used by cron jobs and is not reliable for manual usage.
Another way to avoid dealing with renaming your scripts to fit run-parts’s naming structure, you can use find or for loop commands.
To find and run all script files that start with letter «s» in
/Documents folder, run:
If you want to run all scripts in the given directory and all its sub-directories, remove the maxdepth option in the above command:
To run all scripts that ends with extension «.sh», run:
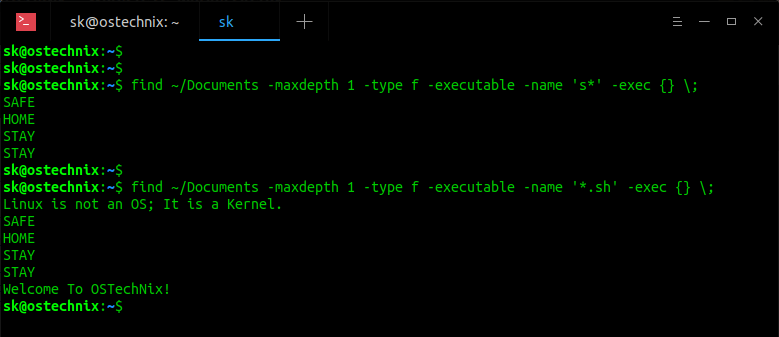
Find and run all scripts in a directory in Linux using find command
This method has also a minor disadvantage. This command can only run the scripts that can be interpreted by your current shell. If you want to run all type of scripts, for example awk, perl, python, shell scripts, use for loop method like below.
The above command will run the scripts that starts with letter «s» in
/Documents folder. If you want to run all files that ends with «.sh» extension, do:
Источник
bash script read all the files in directory
How do I loop through a directory? I know there is for f in /var/files;do echo $f;done; The problem with that is it will spit out all the files inside the directory all at once. I want to go one by one and be able to do something with the $f variable. I think the while loop would be best suited for that but I cannot figure out how to actually write the while loop.
Any help would be appreciated.
3 Answers 3
A simple loop should be working:

To write it with a while loop you can do:
The primary disadvantage of this is that cmd is run in a subshell, which causes some difficulty if you are trying to set variables. The main advantages are that the shell does not need to load all of the filenames into memory, and there is no globbing. When you have a lot of files in the directory, those advantages are important (that’s why I use -f on ls; in a large directory ls itself can take several tens of seconds to run and -f speeds that up appreciably. In such cases ‘for file in /var/*’ will likely fail with a glob error.)
You can go without the loop:
Not the answer you’re looking for? Browse other questions tagged linux bash or ask your own question.
Linked
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
site design / logo © 2021 Stack Exchange Inc; user contributions licensed under cc by-sa. rev 2021.10.8.40416
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
Get a list of all files in folder and sub-folder in a file
How do I get a list of all files in a folder, including all the files within all the subfolders and put the output in a file?

7 Answers 7
You can do this on command line, using the -R switch (recursive) and then piping the output to a file thus:
this will make a file called filename1 in the current directory, containing a full directory listing of the current directory and all of the sub-directories under it.
You can list directories other than the current one by specifying the full path eg:
will list everything in and under /var and put the results in a file in the current directory called filename2. This works on directories owned by another user including root as long as you have read access for the directories.
You can also list directories you don’t have access to such as /root with the use of the sudo command. eg:
Would list everything in /root, putting the results in a file called filename3 in the current directory. Since most Ubuntu systems have nothing in this directory filename3 will not contain anything, but it would work if it did.
Just use the find command with the directory name. For example to see the files and all files within folders in your home directory, use
Check the find manual manpage for the find command 
Also check find GNU info page by using info find command in a terminal.
An alternative to recursive ls is the command line tool tree that comes with quite a lot of options to customize the format of the output diplayed. See the manpage for tree for all options.
will give you the same as tree using other characters for the lines.
to display hidden files too
to not display lines
- Go to the folder you want to get a content list from.
- Select the files you want in your list ( Ctrl + A if you want the entire folder).
- Copy the content with Ctrl + C .
- Open gedit and paste the content using Ctrl + V . It will be pasted as a list and you can then save the file.
This method will not include subfolder, content though.
You could also use the GUI counterpart to Takkat’s tree suggestion which is Baobab. It is used to view folders and subfolders, often for the purpose of analysing disk usage. You may have it installed already if you are using a GNOME desktop (it is often called disk usage analyser).
You can select a folder and also view all its subfolders, while also getting the sizes of the folders and their contents as the screenshot below shows. You just click the small down arrow to view a subfolder within a folder. It is very useful for gaining a quick insight into what you’ve got in your folders and can produce viewable lists, but at the present moment it cannot export them to file. It has been requested as a feature, however, at Launchpad. You can even use it to view the root filesystem if you use gksudo baobab .
(You can also get a list of files with their sizes by using ls -shR
Источник
tar: add all files and directories in current directory INCLUDING .svn and so on
I try to tar.gz a directory and use
The resulting tar includes .svn directories in subdirs but NOT in the current directory (as * gets expanded to only ‘visible’ files before it is passed to tar
tar -czf workspace.tar.gz . instead but then I am getting an error because ‘.’ has changed while reading:
Is there a trick so that * matches all files (including dot-prefixed) in a directory?
(using bash on Linux SLES-11 (2.6.27.19)
16 Answers 16
Don’t create the tar file in the directory you are packing up:
does the trick, except it will extract the files all over the current directory when you unpack. Better to do:
or, if you don’t know the name of the directory you were in:
(This assumes that you didn’t follow symlinks to get to where you are and that the shell doesn’t try to second guess you by jumping backwards through a symlink — bash is not trustworthy in this respect. If you have to worry about that, use cd -P .. to do a physical change directory. Stupid that it is not the default behaviour in my view — confusing, at least, for those for whom cd .. never had any alternative meaning.)
One comment in the discussion says:
I [. ] need to exclude the top directory and I [. ] need to place the tar in the base directory.
The first part of the comment does not make much sense — if the tar file contains the current directory, it won’t be created when you extract file from that archive because, by definition, the current directory already exists (except in very weird circumstances).
The second part of the comment can be dealt with in one of two ways:
Источник
Execute command on all files in a directory
Could somebody please provide the code to do the following: Assume there is a directory of files, all of which need to be run through a program. The program outputs the results to standard out. I need a script that will go into a directory, execute the command on each file, and concat the output into one big output file.
For instance, to run the command on 1 file:


10 Answers 10
The following bash code will pass $file to command where $file will represent every file in /dir

- -maxdepth 1 argument prevents find from recursively descending into any subdirectories. (If you want such nested directories to get processed, you can omit this.)
- -type -f specifies that only plain files will be processed.
- -exec cmd option <> tells it to run cmd with the specified option for each file found, with the filename substituted for <>
- \; denotes the end of the command.
- Finally, the output from all the individual cmd executions is redirected to results.out
However, if you care about the order in which the files are processed, you might be better off writing a loop. I think find processes the files in inode order (though I could be wrong about that), which may not be what you want.
I’m doing this on my raspberry pi from the command line by running:

The accepted/high-voted answers are great, but they are lacking a few nitty-gritty details. This post covers the cases on how to better handle when the shell path-name expansion (glob) fails, when filenames contain embedded newlines/dash symbols and moving the command output re-direction out of the for-loop when writing the results to a file.
When running the shell glob expansion using * there is a possibility for the expansion to fail if there are no files present in the directory and an un-expanded glob string will be passed to the command to be run, which could have undesirable results. The bash shell provides an extended shell option for this using nullglob . So the loop basically becomes as follows inside the directory containing your files
This lets you safely exit the for loop when the expression ./* doesn’t return any files (if the directory is empty)
or in a POSIX compliant way ( nullglob is bash specific)
This lets you go inside the loop when the expression fails for once and the condition [ -f «$file» ] check if the un-expanded string ./* is a valid filename in that directory, which wouldn’t be. So on this condition failure, using continue we resume back to the for loop which won’t run subsequently.
Also note the usage of — just before passing the file name argument. This is needed because as noted previously, the shell filenames can contain dashes anywhere in the filename. Some of the shell commands interpret that and treat them as a command option when the name are not quoted properly and executes the command thinking if the flag is provided.
The — signals the end of command line options in that case which means, the command shouldn’t parse any strings beyond this point as command flags but only as filenames.
Double-quoting the filenames properly solves the cases when the names contain glob characters or white-spaces. But *nix filenames can also contain newlines in them. So we de-limit filenames with the only character that cannot be part of a valid filename — the null byte ( \0 ). Since bash internally uses C style strings in which the null bytes are used to indicate the end of string, it is the right candidate for this.
So using the printf option of shell to delimit files with this NULL byte using the -d option of read command, we can do below
The nullglob and the printf are wrapped around (..) which means they are basically run in a sub-shell (child shell), because to avoid the nullglob option to reflect on the parent shell, once the command exits. The -d » option of read command is not POSIX compliant, so needs a bash shell for this to be done. Using find command this can be done as
For find implementations that don’t support -print0 (other than the GNU and the FreeBSD implementations), this can be emulated using printf
Another important fix is to move the re-direction out of the for-loop to reduce a high number of file I/O. When used inside the loop, the shell has to execute system-calls twice for each iteration of the for-loop, once for opening and once for closing the file descriptor associated with the file. This will become a bottle-neck on your performance for running large iterations. Recommended suggestion would be to move it outside the loop.
Extending the above code with this fixes, you could do
which will basically put the contents of your command for each iteration of your file input to stdout and when the loop ends, open the target file once for writing the contents of the stdout and saving it. The equivalent find version of the same would be
Источник



