- 7.3. Операции сравнения
- Операторы сравнения в UNIX shell
- Сравнение чисел
- Пример использования в IF
- Сравнение строк
- Пример использования в IF
- Несколько условий (логические операторы)
- Дополнительно
- Как написать IF в одну строку
- Арифметические операции
- Ошибка «Integer expression expected»
- Основные приёмы обработки строк в bash
- Термины
- Сравнение строковых переменных
- Основные операторы сравнения
- Пример скрипта для сравнения двух строковых переменных
- Создание тестового файла
- Основы работы с grep
- Синтаксис команды
- Основные опции
- Практическое применение grep
- Поиск подстроки в строке
- Вывод нескольких строк
- Чтение строки из файла с использованием регулярных выражений
- Рекурсивный режим поиска
- Точное вхождение
- Поиск нескольких слов
- Количество строк в файле
- Вывод только имени файла
- Использование sed
- Синтаксис
- Распространенные конструкции с sed
- Замена слова
- Редактирование файла
- Удаление строк из файла
- Нумерация строк
- Удаление всех чисел из текста
- Замена символов
- Обработка указанной строки
- Работа с диапазоном строк
7.3. Операции сравнения
сравнение целых чисел
if [ «$a» -eq «$b» ]
if [ «$a» -ne «$b» ]
if [ «$a» -gt «$b» ]
больше или равно
if [ «$a» -ge «$b» ]
if [ «$a» -lt «$b» ]
меньше или равно
if [ «$a» -le «$b» ]
меньше или равно (внутри двойных круглых скобок)
больше (внутри двойных круглых скобок)
больше или равно (внутри двойных круглых скобок)
сравнение строк
if [ «$a» = «$b» ]
if [ «$a» == «$b» ]
if [ «$a» != «$b» ]
Этот оператор используется при поиске по шаблону внутри [[ . ]].
меньше, в смысле величины ASCII-кодов
if [[ «$a» if [ «$a» \ » необходимо экранировать внутри [ ].
больше, в смысле величины ASCII-кодов
if [[ «$a» > «$b» ]]
if [ «$a» \> «$b» ]
Обратите внимание! Символ «>» необходимо экранировать внутри [ ].
См. Пример 25-6 относительно применения этого оператора сравнения.
строка «пустая» , т.е. имеет нулевую длину
строка не «пустая» .
 |
| Оператор | Описание | Пример |
|---|---|---|
| -eq | [ $x -eq $y ] Равно. Для результат True необходимо, чтобы x был равен y. | [ 1 -eq 2 ] — False [ 3 -eq 3 ] — True |
| -ne | [ $x -ne $y ] Не равно. Оператор обратный -eq. | [ 1 -ne 2 ] — True [ 3 -ne 3 ] — False |
| -gt | [ $x -gt $y ] Больше. То есть проверяет больше ли x чем y. | [ 1 -gt 2 ] — False [ 3 -gt 3 ] — False [ 5 -gt 4 ] — True |
| -lt | [ $x -lt $y ] Меньше. Проверяет, что число в левой части (x) меньше числа в правой (y) | [ 1 -lt 2 ] — True [ 3 -lt 3 ] — False [ 5 -lt 4 ] — False |
| -ge | [ $x -ge $y ] Больше или равно. | [ 1 -ge 2 ] — False [ 3 -ge 3 ] — True [ 5 -ge 4 ] — True |
| -le | [ $x -le $y ] Меньше или равно. | [ 1 -le 2 ] — True [ 3 -le 3 ] — True [ 5 -le 4 ] — False |
Пример использования в IF
if [ $x -eq $y ]
then
echo ‘true’
else
echo ‘false’
fi
Сравнение строк
| Оператор | Описание | Пример |
|---|---|---|
| = | [ «$a» = «$b» ] Равно. То есть строка a равна строке b. | [ ‘linux’ = ‘windows’ ] — False [ ‘unix’ = ‘unix’ ] — True |
| != | [ «$a» != «$b» ] Не равно. Оператор обратный =. | [ ‘linux’ != ‘windows’ ] — True [ ‘unix’ != ‘unix’ ] — False |
| = |
$b ]] Содержит.
То есть в строке a есть b.
Обратите внимание, что для данного оператора используются двойные квадратные скобки.
‘windows’ ]] — False
[[ ‘unix’ =
‘ni’ ]] — True
Оператор проверяет, является ли строка b с нулевым размером.
[ -z » ] — True
Оператор обратный -z.
[ -n » ] — False
Оператор проверяет, является ли строка b не пустой.
[ » ] — False
Оператор проверяет, существует ли файл $file.
[ -f » ] — False
Пример использования в IF
if [ «$a» = «$b» ]
then
echo ‘true’
elif [[ «$a» =
$b ]]
then
echo ‘true’
else
echo ‘false’
fi
Несколько условий (логические операторы)
| Оператор | Описание | Пример |
|---|---|---|
| -a | [ $x -eq $y -a $z -le $w ] Логическое И. В данном примере, проверяет, что (x равно y) И (z меньше или равно w) | [ 1 -eq 2 -a 3 -le 4 ] — False [ 5 -eq 5 -a 3 -le 4 ] — True [ 5 -eq 5 -a 6 -le 4 ] — False |
| -o | [ $x -ne $y -o $z -ge $w ] Логическое ИЛИ. В данном примере, проверяет, что (x не равно y) ИЛИ (z больше или равно w) | [ 1 -eq 2 -o 3 -le 4 ] — True [ 5 -eq 5 -o 3 -le 4 ] — True [ 5 -eq 5 -o 6 -le 4 ] — True [ 1 -eq 2 -o 6 -le 4 ] — False |
Дополнительно
Как написать IF в одну строку
if [ $x -ne 0 ]; then echo 1; fi
if [ $x -ne 0 -a $y -eq 1 ]; then echo 1; else echo 2; fi
Арифметические операции
Расчет можно выполнить одним из следующих методов:
sum=$(( $sum1 + $sum2 + $sum3 ))
sum=`expr $sum1 + $sum2 + $sum3`
* где операции могут быть следующие:
- + — сложение;
- — — вычитание;
- * — умножение;
- / — деление;
- % — остаток от деления;
- = — приравнивание.
Ошибка «Integer expression expected»
Чаще всего, возникает при попытках использовать не тот оператор, например для строки -le (который должен использоваться для числа).
Примеры неправильного использования операторов:
Источник
Основные приёмы обработки строк в bash
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство « = »: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность « == »: возвращается «TRUE», если первая строка эквивалентна второй ( дом == дом ).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению ( дерево !== огонь ).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, « дерево > огонь » , поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, « огонь », поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 « -z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения « -n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test .

- Далее необходимо открыть терминал и запустить test на выполнение командой:
- Предварительно необходимо дать файлу право на исполнение командой:
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.


Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt .
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep . Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
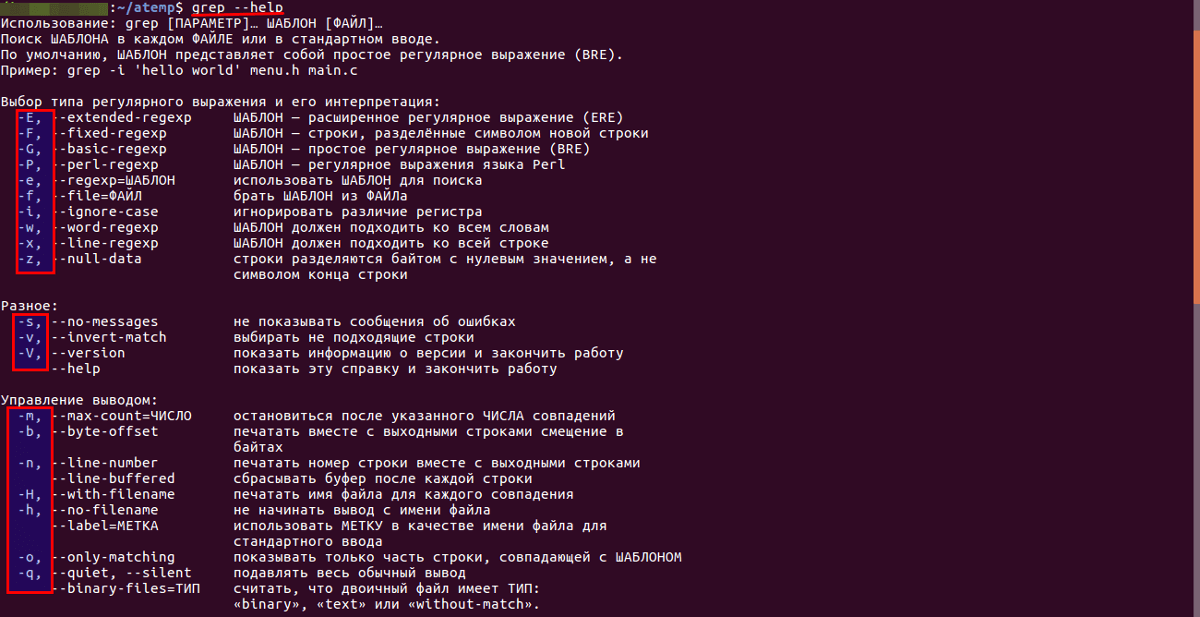
Основные опции
- Отобразить в консоли номер блока перед строкой — -b .
- Число вхождений шаблона строки — -с .
- Не выводить имя файла в результатах поиска — -h .
- Без учета регистра — -i .
- Отобразить только имена файлов с совпадением строки — -l .
- Показать номер строки — -n .
- Игнорировать сообщения об ошибках — -s .
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v .
- Слово, окруженное пробелами, — -w .
- Включить регулярные выражения при поиске — -e .
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn .
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
- Без учета регистра:
Вывод нескольких строк
- Строка с вхождением и две после нее:
- Строка с вхождением и три до нее:
- Строка, содержащая вхождение, и одну до и после нее:
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».
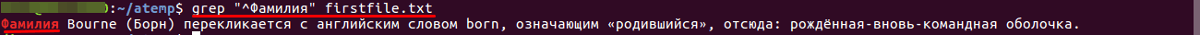 В регулярных выражения для обозначения начала строки используется специальный символ «^».
В регулярных выражения для обозначения начала строки используется специальный символ «^». Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкцию
grep «а.$» firstfile.txt . В этом случае будут выведены все строки, заканчивающиеся на литеру «а».

Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ « w »:
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.

- Число вхождений:
- Номера строк с совпадениями:
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
Использование sed
Потоковый текстовый редактор « sed » встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
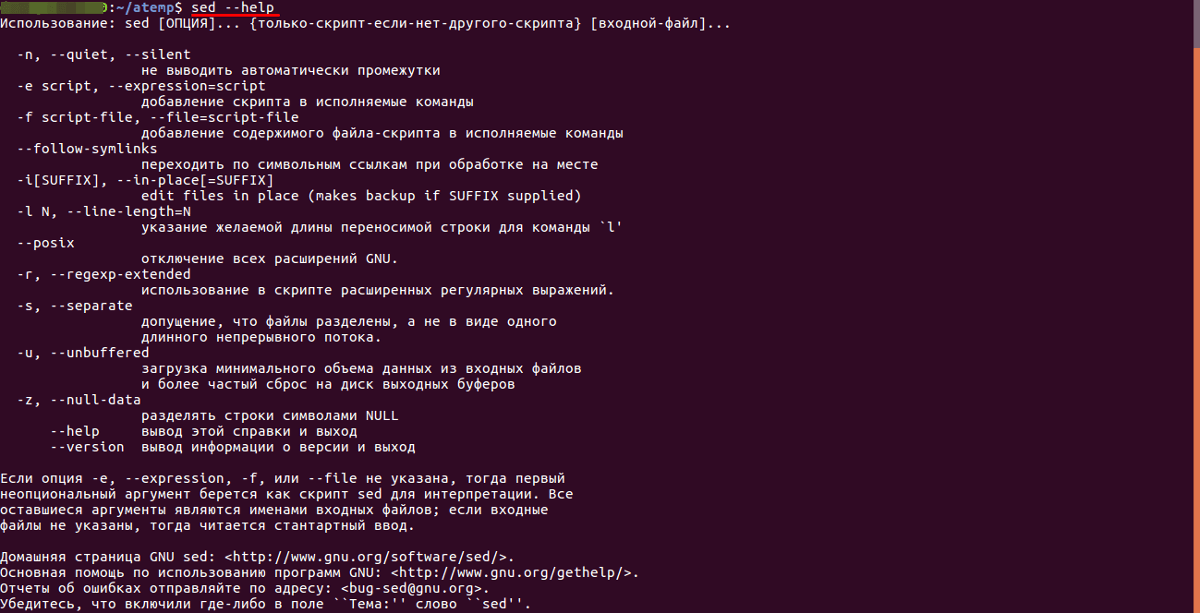
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
Распространенные конструкции с sed
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
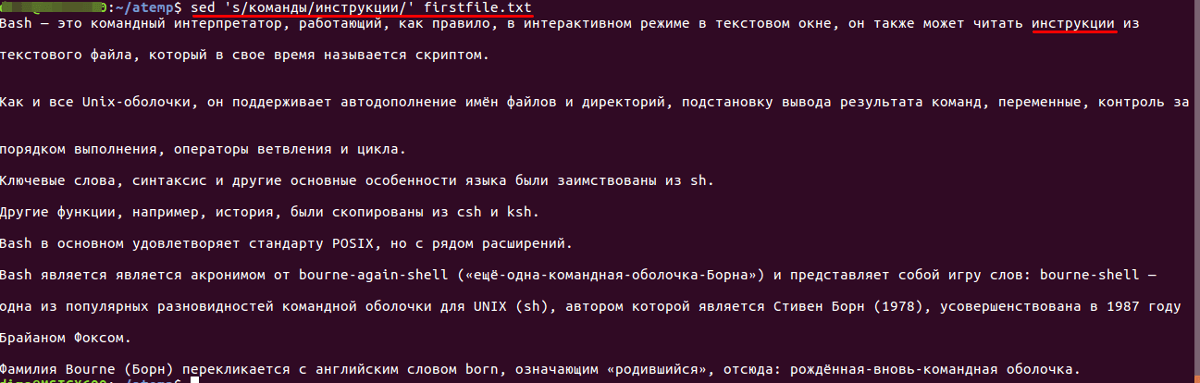
Произвести замену только в строках, которые заканчиваются на«Bash»:
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i :
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
- Удалить строку из файла, содержащую слово«окне»:
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
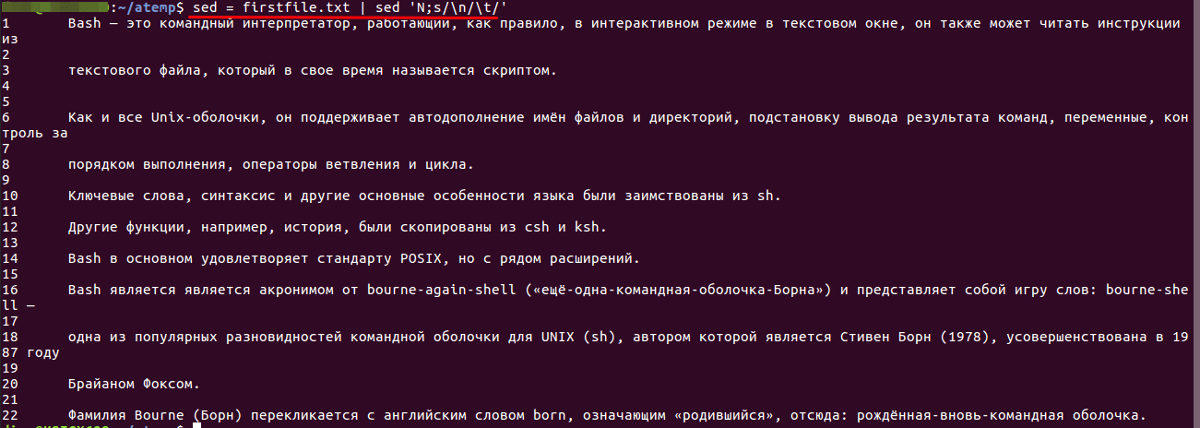
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
Удаление всех чисел из текста
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду « y »:
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:
sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
Начни экономить на хостинге сейчас — 14 дней бесплатно!
Источник



