- Команда sed Linux
- Команда sed в Linux
- 1. Как работает sed
- 2. Адреса sed
- 3. Синтаксис регулярных выражений
- 4. Команды sed
- Примеры использования sed
- Выводы
- Bash-скрипты, часть 7: sed и обработка текстов
- Основы работы с sed
- Выполнение наборов команд при вызове sed
- Чтение команд из файла
- Флаги команды замены
- Символы-разделители
- Выбор фрагментов текста для обработки
- Удаление строк
- Вставка текста в поток
- Замена строк
- Замена символов
- Вывод номеров строк
- Чтение данных для вставки из файла
- Пример
- Итоги
Команда sed Linux
Команда sed — это потоковый редактор текста, работающий по принципу замены. Его можно использовать для поиска, вставки, замены и удаления фрагментов в файле. С помощью этой утилиты вы можете редактировать файлы не открывая их. Будет намного быстрее если вы напишите что и на что надо заменить, чем вы будете открывать редактор vi, искать нужную строку и вручную всё заменять.
В этой статье мы рассмотрим основы использования команды sed linux, её синтаксис, а также синтаксис регулярных выражений, который используется непосредственно для поиска и замены в файлах.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая
шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
число
— начиная от строки номер и до строки номер которой будет кратный числу.Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \ — любой символ в количестве i;
- \ — любой символ в количестве от i до j;
- \ — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла строки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:
sed -n ‘5,10p’ /etc/group
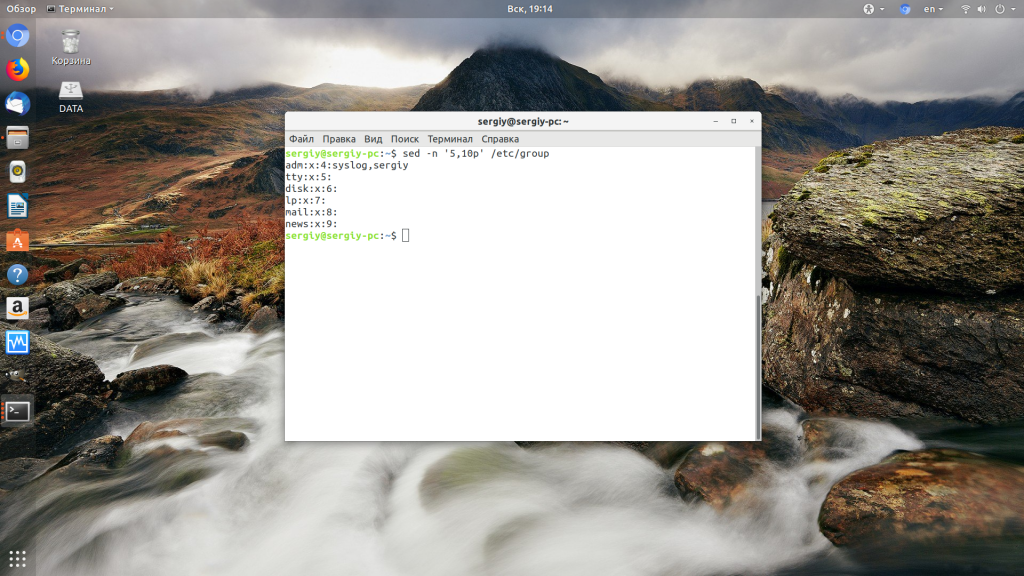
Или можно вывести весь файл, кроме строк с первой по двадцатую:
sed ‘1,20d’ /etc/group

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:
sed ‘s/root/losst/g’ /etc/group

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:
sed ‘1,10 s/0/1000/g’ /etc/group

Переходим ещё ближе к регулярным выражениям, удалим все пустые строки или строки с комментариями из конфига Apache:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:
sed ‘s/[$p*]/losst_p/g’ /etc/group

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf | sudo tee /etc/apache2/apache2.conf
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:
sudo sed -i ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.
Выводы
Из этой статьи вы узнали что представляет из себя команда sed Linux. Как видите, это очень гибкий инструмент, который позволяет делать с текстом очень многое. Он сложный в освоении, но с помощью него очень удобно решать многие задачи редактирования конфигурационных файлов или фильтрации вывода.
Источник
Bash-скрипты, часть 7: sed и обработка текстов
В прошлый раз мы говорили о функциях в bash-скриптах, в частности, о том, как вызывать их из командной строки. Наша сегодняшняя тема — весьма полезный инструмент для обработки строковых данных — утилита Linux, которая называется sed. Её часто используют для работы с текстами, имеющими вид лог-файлов, конфигурационных и других файлов.

Если вы, в bash-скриптах, каким-то образом обрабатываете данные, вам не помешает знакомство с инструментами sed и gawk. Тут мы сосредоточимся на sed и на работе с текстами, так как это — очень важный шаг в нашем путешествии по бескрайним просторам разработки bash-скриптов.
Сейчас мы разберём основы работы с sed, а так же рассмотрим более трёх десятков примеров использования этого инструмента.
Основы работы с sed
Утилиту sed называют потоковым текстовым редактором. В интерактивных текстовых редакторах, наподобие nano, с текстами работают, используя клавиатуру, редактируя файлы, добавляя, удаляя или изменяя тексты. Sed позволяет редактировать потоки данных, основываясь на заданных разработчиком наборах правил. Вот как выглядит схема вызова этой команды:
По умолчанию sed применяет указанные при вызове правила, выраженные в виде набора команд, к STDIN . Это позволяет передавать данные непосредственно sed.
Вот что получится при выполнении этой команды.
Простой пример вызова sed
В данном случае sed заменяет слово «test» в строке, переданной для обработки, словами «another test». Для оформления правила обработки текста, заключённого в кавычки, используются прямые слэши. В нашем случае применена команда вида s/pattern1/pattern2/ . Буква «s» — это сокращение слова «substitute», то есть — перед нами команда замены. Sed, выполняя эту команду, просмотрит переданный текст и заменит найденные в нём фрагменты (о том — какие именно, поговорим ниже), соответствующие pattern1 , на pattern2 .
Выше приведён примитивный пример использования sed, нужный для того, чтобы ввести вас в курс дела. На самом деле, sed можно применять в гораздо более сложных сценариях обработки текстов, например — для работы с файлами.
Ниже показан файл, в котором содержится фрагмент текста, и результаты его обработки такой командой:
Текстовый файл и результаты его обработки
Здесь применён тот же подход, который мы использовали выше, но теперь sed обрабатывает текст, хранящийся в файле. При этом, если файл достаточно велик, можно заметить, что sed обрабатывает данные порциями и выводит то, что обработано, на экран, не дожидаясь обработки всего файла.
Sed не меняет данные в обрабатываемом файле. Редактор читает файл, обрабатывает прочитанное, и отправляет то, что получилось, в STDOUT . Для того, чтобы убедиться в том, что исходный файл не изменился, достаточно, после того, как он был передан sed, открыть его. При необходимости вывод sed можно перенаправить в файл, возможно — перезаписать старый файл. Если вы знакомы с одним из предыдущих материалов этой серии, где речь идёт о перенаправлении потоков ввода и вывода, вы вполне сможете это сделать.
Выполнение наборов команд при вызове sed
Для выполнения нескольких действий с данными, используйте ключ -e при вызове sed. Например, вот как организовать замену двух фрагментов текста:
Использование ключа -e при вызове sed
К каждой строке текста из файла применяются обе команды. Их нужно разделить точкой с запятой, при этом между окончанием команды и точкой с запятой не должно быть пробела.
Для ввода нескольких шаблонов обработки текста при вызове sed, можно, после ввода первой одиночной кавычки, нажать Enter, после чего вводить каждое правило с новой строки, не забыв о закрывающей кавычке:
Вот что получится после того, как команда, представленная в таком виде, будет выполнена.
Другой способ работы с sed
Чтение команд из файла
Если имеется множество команд sed, с помощью которых надо обработать текст, обычно удобнее всего предварительно записать их в файл. Для того, чтобы указать sed файл, содержащий команды, используют ключ -f :
Вот содержимое файла mycommands :
Вызовем sed, передав редактору файл с командами и файл для обработки:
Результат при вызове такой команды аналогичен тому, который получался в предыдущих примерах.
Использование файла с командами при вызове sed
Флаги команды замены
Внимательно посмотрите на следующий пример.
Вот что содержится в файле, и что будет получено после его обработки sed.
Исходный файл и результаты его обработки
Команда замены нормально обрабатывает файл, состоящий из нескольких строк, но заменяются только первые вхождения искомого фрагмента текста в каждой строке. Для того, чтобы заменить все вхождения шаблона, нужно использовать соответствующий флаг.
Схема записи команды замены при использовании флагов выглядит так:
Выполнение этой команды можно модифицировать несколькими способами.
- При передаче номера учитывается порядковый номер вхождения шаблона в строку, заменено будет именно это вхождение.
- Флаг g указывает на то, что нужно обработать все вхождения шаблона, имеющиеся в строке.
- Флаг p указывает на то, что нужно вывести содержимое исходной строки.
- Флаг вида w file указывает команде на то, что нужно записать результаты обработки текста в файл.
Рассмотрим использование первого варианта команды замены, с указанием позиции заменяемого вхождения искомого фрагмента:
Вызов команды замены с указанием позиции заменяемого фрагмента
Тут мы указали, в качестве флага замены, число 2. Это привело к тому, что было заменено лишь второе вхождение искомого шаблона в каждой строке. Теперь опробуем флаг глобальной замены — g :
Как видно из результатов вывода, такая команда заменила все вхождения шаблона в тексте.
Флаг команды замены p позволяет выводить строки, в которых найдены совпадения, при этом ключ -n , указанный при вызове sed, подавляет обычный вывод:
Как результат, при запуске sed в такой конфигурации на экран выводятся лишь строки (в нашем случае — одна строка), в которых найден заданный фрагмент текста.
Использование флага команды замены p
Воспользуемся флагом w , который позволяет сохранить результаты обработки текста в файл:
Сохранение результатов обработки текста в файл
Хорошо видно, что в ходе работы команды данные выводятся в STDOUT, при этом обработанные строки записываются в файл, имя которого указано после w .
Символы-разделители
Представьте, что нужно заменить /bin/bash на /bin/csh в файле /etc/passwd . Задача не такая уж и сложная:
Однако, выглядит всё это не очень-то хорошо. Всё дело в том, что так как прямые слэши используются в роли символов-разделителей, такие же символы в передаваемых sed строках приходится экранировать. В результате страдает читаемость команды.
К счастью, sed позволяет нам самостоятельно задавать символы-разделители для использования их в команде замены. Разделителем считается первый символ, который будет встречен после s :
В данном случае в качестве разделителя использован восклицательный знак, в результате код легче читать и он выглядит куда опрятнее, чем прежде.
Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
- Задать ограничение на номера обрабатываемых строк.
- Указать фильтр, соответствующие которому строки нужно обработать.
Рассмотрим первый подход. Тут допустимо два варианта. Первый, рассмотренный ниже, предусматривает указание номера одной строки, которую нужно обработать:
Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:
Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:
Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
По аналогии с тем, что было рассмотрено выше, шаблон передаётся перед именем команды s .
Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Удаление строк
Утилита sed годится не только для замены одних последовательностей символов в строках на другие. С её помощью, а именно, используя команду d , можно удалять строки из текстового потока.
Вызов команды выглядит так:
Мы хотим, чтобы из текста была удалена третья строка. Обратите внимание на то, что речь не идёт о файле. Файл останется неизменным, удаление отразится лишь на выводе, который сформирует sed.
Удаление третьей строки
Если при вызове команды d не указать номер удаляемой строки, удалены будут все строки потока.
Вот как применить команду d к диапазону строк:
Удаление диапазона строк
А вот как удалить строки, начиная с заданной — и до конца файла:
Удаление строк до конца файла
Строки можно удалять и по шаблону:
Удаление строк по шаблону
При вызове d можно указывать пару шаблонов — будут удалены строки, в которых встретится шаблон, и те строки, которые находятся между ними:
Удаление диапазона строк с использованием шаблонов
Вставка текста в поток
С помощью sed можно вставлять данные в текстовый поток, используя команды i и a :
- Команда i добавляет новую строку перед заданной.
- Команда a добавляет новую строку после заданной.
Рассмотрим пример использования команды i :
Теперь взглянем на команду a :
Как видно, эти команды добавляют текст до или после данных из потока. Что если надо добавить строку где-нибудь посередине?
Тут нам поможет указание номера опорной строки в потоке, или шаблона. Учтите, что адресация строк в виде диапазона тут не подойдёт. Вызовем команду i , указав номер строки, перед которой надо вставить новую строку:
Команда i с указанием номера опорной строки
Проделаем то же самое с командой a :
Команда a с указанием номера опорной строки
Обратите внимание на разницу в работе команд i и a . Первая вставляет новую строку до указанной, вторая — после.
Замена строк
Команда c позволяет изменить содержимое целой строки текста в потоке данных. При её вызове нужно указать номер строки, вместо которой в поток надо добавить новые данные:
Замена строки целиком
Если воспользоваться при вызове команды шаблоном в виде обычного текста или регулярного выражения, заменены будут все соответствующие шаблону строки:
Замена строк по шаблону
Замена символов
Команда y работает с отдельными символами, заменяя их в соответствии с переданными ей при вызове данными:
Используя эту команду, нужно учесть, что она применяется ко всему текстовому потоку, ограничить её конкретными вхождениями символов нельзя.
Вывод номеров строк
Если вызвать sed, использовав команду = , утилита выведет номера строк в потоке данных:
Вывод номеров строк
Потоковый редактор вывел номера строк перед их содержимым.
Если передать этой команде шаблон и воспользоваться ключом sed -n , выведены будут только номера строк, соответствующих шаблону:
Вывод номеров строк, соответствующих шаблону
Чтение данных для вставки из файла
Выше мы рассматривали приёмы вставки данных в поток, указывая то, что надо вставить, прямо при вызове sed. В качестве источника данных можно воспользоваться и файлом. Для этого служит команда r , которая позволяет вставлять в поток данные из указанного файла. При её вызове можно указать номер строки, после которой надо вставить содержимое файла, или шаблон.
Вставка в поток содержимого файла
Тут содержимое файла newfile было вставлено после третьей строки файла myfile .
Вот что произойдёт, если применить при вызове команды r шаблон:
Использование шаблона при вызове команды r
Содержимое файла будет вставлено после каждой строки, соответствующей шаблону.
Пример
Представим себе такую задачу. Есть файл, в котором имеется некая последовательность символов, сама по себе бессмысленная, которую надо заменить на данные, взятые из другого файла. А именно, пусть это будет файл newfile , в котором роль указателя места заполнения играет последовательность символов DATA . Данные, которые нужно подставить вместо DATA , хранятся в файле data .
Решить эту задачу можно, воспользовавшись командами r и d потокового редактора sed:
Замена указателя места заполнения на реальные данные
Как видите, вместо заполнителя DATA sed добавил в выходной поток две строки из файла data .
Итоги
Сегодня мы рассмотрели основы работы с потоковым редактором sed. На самом деле, sed — это огромнейшая тема. Его изучение вполне можно сравнить с изучением нового языка программирования, однако, поняв основы, вы сможете освоить sed на любом необходимом вам уровне. В результате ваши возможности по обработке с его помощью текстов будет ограничивать лишь воображение.
На сегодня это всё. В следующий раз поговорим о языке обработки данных awk.
Уважаемые читатели! А вы пользуетесь sed в повседневной работе? Если да — поделитесь пожалуйста опытом.
Источник



