- Изучаем команды Linux: sed
- 1. Введение
- 2. Установка
- 3. Концепции
- 4. Регулярные выражения
- Linux sed последняя строка
- Номер строки
- Примеры
- Ещё пример
- Удаление строки по контексту
- Удаление строки или нескольких строк в файле
- Объединение строк
- Объединение двух соседних строк попарно
- Удалить последнюю строку из файла
- Команда sed Linux
- Команда sed в Linux
- 1. Как работает sed
- 2. Адреса sed
- 3. Синтаксис регулярных выражений
- 4. Команды sed
- Примеры использования sed
- Выводы
Изучаем команды Linux: sed
Оригинал: Learning Linux Commands: sed
Автор: Rares Aioanei
Дата публикации: 19 ноября 2011 года
Перевод: А. Кривошей
Дата перевода: июль 2012 г.
Николай Игнатушко проверил на GNU sed version 4.2.1 в дистрибутиве Gentoo все команды, упомянутые в этой статье. Не все скрипты хорошо отрабатывали на версии GNU sed. Но дело касалось мелочей, которые исправлены. Только скрипт по замене hill на mountains пришлось существенно переделать.
1. Введение
Добро пожаловать во вторую часть нашей серии, которая посвящена sed, версии GNU. Существует несколько версий sed, которые доступны на разных платформах, но мы сфокусируемся на GNU sed версии 4.x. Многие из вас слышали о sed, или уже использовали его, скорее всего в качестве инструмента замены. Но это только одно из предназначений sed, и мы постараемся показать вам все аспекты использования этой утилиты. Его название расшифровывается как «Stream EDitor» и слово «stream» (поток) в данном случае может означать файл, канал, или просто stdin. Мы надеемся, что у вас уже есть базовые знания о Linux, а если вы уже работали с регулярными выражениями, или по крайней мере знаете, что это такое, то все для вас будет намного проще. Объем статьи не позволяет включить в нее полное руководство по регулярным выражениям, вместо этого мы озвучим базовые концепции и дадим большое количество примеров использования sed.
2. Установка
Здесь не нужно много рассказывать. Скорее все sed у вас уже установлен, так как он используется различными системными скриптами, а также пользователями Linux, которые хотят повысить эффективность своей работы. Вы можете узнать, какая версия sed у вас установлена, с помощью команды:
В моей системе эта команда показывает, что у меня установлен GNU sed 4.2.1 плюс дает ссылку на домашнюю страницу программы и другие полезные сведения. Пакет называется «sed» независимо от дистрибутива, кроме Gentoo, где он присутствует неявно.
3. Концепции
Перед тем, как идти дальше, мы считаем важным акцентировать внимание на том, что делает «sed», так как словосочетание «потоковый редактор» мало что говорит о его назначении. sed принимает на входе текст, выполняет заданные операции над каждой строкой (если не задано другое) и выводит модифицированный текст. Указанными операциями могут быть добавление, вставка, удаление или замена. Это не так просто, как выглядит: предупреждаю, что имеется большое количество опций и их комбинаций, которые могут сделать команду sed очень трудной для понимания. Поэтому мы рекомендуем вам изучить основы регулярных выражений, чтобы понимать, как это работает. Перед тем, как приступить к руководству, мы хотели бы поблагодарить Eric Pement и других за вдохновление и за то, что он сделал для всех, кто хочет изучать и использовать sed.
4. Регулярные выражения
Так как команды (скрипты) sed для многих остаются загадкой, мы чувствуем, что наши читатели должны понимать базовые концепции, а не слепо копировать и вставлять команды, значения которых они не понимают. Когда человек хочет понять, что представляют собой регулярные выражения, ключевым словом является «соответствие», или, точнее, «шаблон соответствия». Например, в отчете для своего департамента вы написали имя Nick, обращаясь к сетевому архитектору. Но Nick ушел, а на его место пришел John, поэтому теперь вы должны заменить слово Nick на John. Если файл с отчетом называется report.txt, вы должны выполнить следующую команду:
По умолчанию sed использует stdout, вы можете использовать оператор перенаправления вывода, как показано в примере выше. Это очень простой пример, но мы проиллюстрировали несколько моментов: мы ищем все соответствия шаблону «Nick» и заменяем во всех случаях на «John». Отметим, что sed призводит поиск с учетом регистра, поэтому будьте внимательны и проверьте выходной файл, чтобы убедиться, что все замены были выполнены. Приведенный выше пример можно было записать и так:
Хорошо, скажете вы, но где же здесь регулярные выражения? Да, мы хотели сначала показать пример, а теперь начинается самая интересная часть.
Если вы не уверены, написали ли вы «nick» или «Nick», и хотите предусмотреть оба случая, необходимо использовать команду sed ‘s/Nick|nick/John/g’. Вертикальная черта имеет значение, которое вы должны знать, если изучали C, то есть ваше выражение будет соответствовать «nick» или «Nick». Как вы увидите ниже, канал может использоваться и другими способами, но смысл остается тот же самый. Другие операторы, широко использующиеся в регулярных выражениях — это «?», который соответствует повторению предшествующего символа ноль или один раз (то есть flavou?r будет соответствовать flavor и flavour), «*» — ноль или более раз, «+» — один или более раз. «^» соответствует началу строки, а «$» — наоборот. Если вы — пользователь vi или vim, многие вещи покажутся вам знакомыми. В конце концов, эти утилиты, вместе с awk и С уходят корнями в ранние дни UNIX. Мы не будем больше говорить на эту тему, так как проще понять значение этих символов на примерах, но вы должны знать, что существуют различные реализации регулярных выражений: POSIX, POSIX Extended, Perl, а также различные реализации нечетких регулярных выражений, гарантирующие вам головную боль.
Источник
Linux sed последняя строка
Содержимое sec.csv выглядит примерно так:
фактически, это время в минутах и секундах или просто в секундах. Привести его к виду hh:mm:ss можно командой:
после чего данные выглядят так:
Отрицание указывается знаком » ! » в конце конструкции » /:/! «
Номер строки
Примеры
| UNIX | SED |
|---|---|
| cat | sed ‘:’ |
| cat -s | sed ‘1s / ^ $ / / p; / . / , / ^ $ / !d’ |
| tac | sed ‘1!G;h;$!d’ |
| grep | sed ‘/ patt / !d’ |
| grep -v | sed ‘/ patt / d’ |
| head | sed ’10q’ |
| head -1 | sed ‘q’ |
| tail | sed -e ‘:a’ -e ‘$q;N;11,$D;ba’ |
| tail -1 | sed ‘$!d’ |
| tail -f | sed -u ‘/ . / !d’ |
| cut -c 10 | sed ‘s / \(.\)\<10\>.* / \1 / ‘ |
| cut -d: -f4 | sed ‘s / \(\([ ^ :]*\):\)\<4\>.* / \2 / ‘ |
| tr A-Z a-z | sed ‘y / ABCDEFGHIJKLMNOPQRSTUVWXYZ / abcdefghijklmnopqrstuvwxyz / ‘ |
| tr a-z A-Z | sed ‘y / abcdefghijklmnopqrstuvwxyz / ABCDEFGHIJKLMNOPQRSTUVWXYZ / ‘ |
| tr -s ‘ ‘ | sed ‘s / \+ / / g’ |
| tr -d ‘\012’ | sed ‘H;$!d;g;s / \n / / g’ |
| wc -l | sed -n ‘$=’ |
| uniq | sed ‘N; / ^ \(.*\)\n\1$ / !P;D’ |
| rev | sed ‘/ \n / !G;s / \(.\)\(.*\n\) / &\2\1 / ; / / D;s / . / / ‘ |
| basename | sed ‘s,.* / ,,’ |
| dirname | sed ‘s,[ ^ / ]*$,,’ |
| xargs | sed -e ‘:a’ -e ‘$!N;s / \n / / ;ta’ |
| paste -sd: | sed -e ‘:a’ -e ‘$!N;s / \n / : / ;ta’ |
| cat -n | sed ‘=’ | sed ‘$!N;s / \n / / ‘ |
| grep -n | sed -n ‘/ patt / <=;p;>‘ | sed ‘$!N;s / \n / : / ‘ |
| cp orig new | sed ‘w new’ orig |
| hostname -s | hostname | sed ‘s / \..* / / ‘ |
Ещё пример
Эта строка проходит в цикле по всем файлам в текущем каталоге, имена которых оканчиваются на .txt, и:
Для чего это? Вот для чего. Я разбил длинный dokuwiki-файл с командами линукс на мелкие файлы. Они получились вида:
Данная последовательность команд превратила их все в вид:
Удаление строки по контексту
Для удаления строки, содержащей определённый контекст, можно использовать следующую конструкцию:
Эта команда в файле notes.ini удаляет все строки, начинающиеся с AUTO_SAVE .
Удаление строки или нескольких строк в файле
Для удаления строки или нескольких строк в файле я использую следующую конструкцию:
Эта команда в файле удаляет вторую строку.
Эта команда в файле удалит десять строк начиная с пятой (включая пятую).
Объединение строк
Этот пример показывает, как можно объединить строки, разделённые возвратом каретки:
Объединение двух соседних строк попарно
Объединить попарно две строки, разделённые возвратом каретки:
Источник
Удалить последнюю строку из файла
Я использую, sed чтобы быстро удалить строки с определенной позиции, как
Но что делать, если я хочу удалить последнюю строку файла, и я не знаю количество строк (я знаю, что могу получить это, используя wc и несколько других приемов).
В настоящее время используется обходной путь head и в tail сочетании с wc этим. Какие-нибудь быстрые повороты здесь?
в sed $ последняя строка, поэтому удалить последнюю строку:
$ за последнюю строку:
cat file.txt | head -n -1 > new_file.txt
Остерегайтесь, кажется, в зависимости от последней строки file.txt (если она заканчивается EOF , или \n и затем EOF ), количество строк в new_file.txt может быть таким же (как file.txt ) после этой команды (это происходит, когда нет \n ) — в любом случае, содержимое последней строки удаляется.
Также обратите внимание, что вы должны использовать второй (промежуточный) файл. Если вы переадресовали и перенаправили на тот же файл, вы удалите его.
head —lines=-1 , Сначала я наткнулся на эту возможность в man-странице для головы в SLES11SP2-системе (coreutils-8.12-6.23.1)
tail и head являются частью coreutils -rpm (по крайней мере для систем на основе rpm).
Согласно журналу изменений coreutils, этот синтаксис поддерживается начиная с версии coreutils 5.0.1.
Плохая новость: в соответствии с man-страницей RH5 эта опция не описана
Хорошие новости: он работает с RH5 (так в вашем случае: он работает — по крайней мере, с текущей версией RH5).
rpm -q coreutils показывает мне (на CentOS 5.8): coreutils-5.97-34.el5_8.1
Я не уверен, что RH5.5. уже имеет версию coreutils, которая ее поддерживает. Но у 5.5 все равно есть EoLed.
Источник
Команда sed Linux
Команда sed — это потоковый редактор текста, работающий по принципу замены. Его можно использовать для поиска, вставки, замены и удаления фрагментов в файле. С помощью этой утилиты вы можете редактировать файлы не открывая их. Будет намного быстрее если вы напишите что и на что надо заменить, чем вы будете открывать редактор vi, искать нужную строку и вручную всё заменять.
В этой статье мы рассмотрим основы использования команды sed linux, её синтаксис, а также синтаксис регулярных выражений, который используется непосредственно для поиска и замены в файлах.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая
шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
число
— начиная от строки номер и до строки номер которой будет кратный числу.Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \ — любой символ в количестве i;
- \ — любой символ в количестве от i до j;
- \ — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла строки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:
sed -n ‘5,10p’ /etc/group
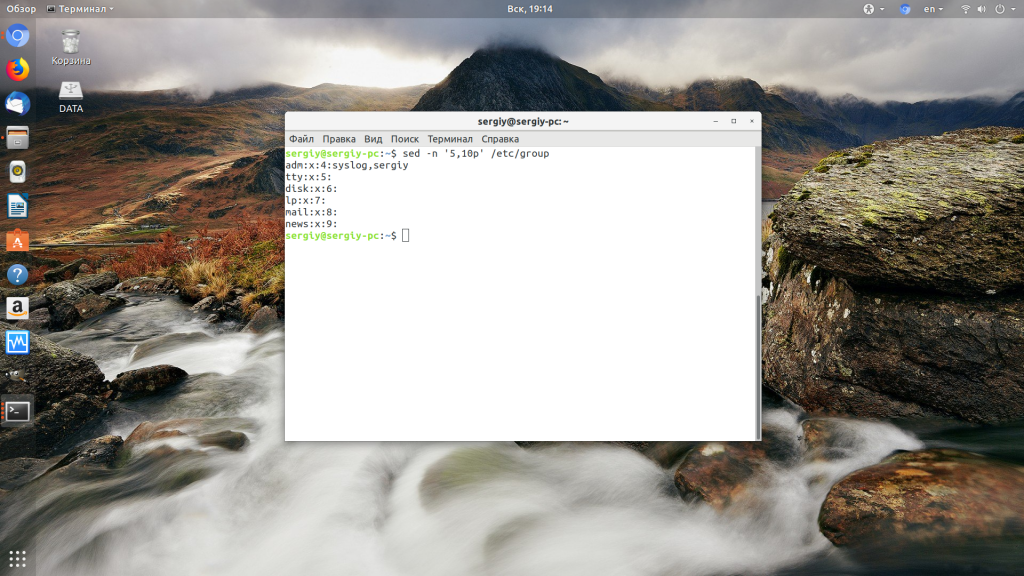
Или можно вывести весь файл, кроме строк с первой по двадцатую:
sed ‘1,20d’ /etc/group

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:
sed ‘s/root/losst/g’ /etc/group

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:
sed ‘1,10 s/0/1000/g’ /etc/group

Переходим ещё ближе к регулярным выражениям, удалим все пустые строки или строки с комментариями из конфига Apache:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:
sed ‘s/[$p*]/losst_p/g’ /etc/group

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf | sudo tee /etc/apache2/apache2.conf
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:
sudo sed -i ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.
Выводы
Из этой статьи вы узнали что представляет из себя команда sed Linux. Как видите, это очень гибкий инструмент, который позволяет делать с текстом очень многое. Он сложный в освоении, но с помощью него очень удобно решать многие задачи редактирования конфигурационных файлов или фильтрации вывода.
Источник



