- Linux sockets in windows
- Программирование сокетов в Linux
- Введение
- Основы socket API
- Понятие сокета
- Атрибуты сокета
- Адреса
- Установка соединения (сервер)
- Установка соединения (клиент)
- Обмен данными
- Закрытие сокета
- Обработка ошибок
- Отладка программ
- Эхо-клиент и эхо-сервер
- Обмен датаграммами
- Использование низкоуровневых сокетов
- Функции для работы с адресами и DNS
- Параллельное обслуживание клиентов
- Способ 1
- Способ 2
- Работа по стандартным протоколам
- Прорыв за пределы платформы
- Заключение
Linux sockets in windows
В ф-ии select есть сразу две проблемы.
Первая — это параметр nfds (первый параметр ф-ии select). Для Windows этот параметр не учитывается, для Unix это важный параметр который должен быть равен: максимальный дескриптор (из трех возможных fdset) плюс 1.
Вторая — второй, третий и четвертый параметры — fd_set.
Что представляет собой fd_set в Windows:
Это просто массив и счетчик элементов в нем. В этот массив, как и в любой другой можно положить все что угодно. Даже то, что сокетом не является. В этом случае select просто вернет ошибку.
Что собой представляет fd_set в Linux и FreeBSD:
Т.е. это всего лишь массив. Заполняется он так:
Чем грозит такое отличие ? Например, под Windows можно написать следующий код:
Дальше можно делать так:
И это будет работать.
В Linux и FreeBSD такой код сразу даст segmentation fault.
INVALID_SOCKET определен как -1, т.е. 0xFFFFFFFF
Например в FreeBSD NFDBITS отпределен как 32 ( 4*8 ). И мы пытаемся прочесть позицию 0x07FFFFFF в fds_bits[] из 32’ух возможных ((1024 + 31)/32).
Поэтому, тот же код с минимальными исправлениями для Linux и FreeBSD должен выглядеть так:
Еще в Windows FD_ISSET определен через ф-ию:
И что-то подсказывает, что эта ф-ия защищена от сбоев по памяти и прочих неприятных вещей.
Кстати, INVALID_SOCKET для Linux и FreeBSD надо определять самому.
Первая проблема — это SIGPIPE. Сигнал, который посылается Unix системой приложению, если то пытается послать данные в сокет, соединение которого уже разорвано. В Windows в таком случае будет возвращена одна из ошибок.
Есть два метода борьбы с этим сигналом.
Первый — пригодный для Linux — установка флага (четвертый параметр ф-ии send() ) в MSG_NOSIGNAL.
Второй, пригодный для Linux и FreeBSD — установка обработчика сигнала, для SIGPIPE. Сам обработчик ничего не делает, просто при выходе из него программа продолжается дальше, а по ошибке, возвращаемой send, можно судить о разрыве соединения.
Вторая проблема — невозможность узнать, были ли реально отправлены данные. Теоретически это проблема не кросс-платформенного кода. В MSDN сказано: The successful completion of a send does not indicate that the data was successfully delivered.
Но практически, я ни разу не сталкивался с таким под Windows, и сразу столкнулся делая порт под FreeBSD.
Поэтому опишу проблему и решение здесь.
Разрыв соединения о котором не знают обе(или одна) стороны. Например, ваша программа под FreeBSD послала данные, ей вернулась ошибка 13 icmp — сокет будет принимать следующие данные для отправки, еще в течении некоторого времени. Они будут буфферизированы в исходящей очереди, и в конце концов утеряны, при закрытии соединения системой.
Один из способов борьбы — это поставить сокет в select(), во второй параметр (readfds). При возврате положительного числа попробовать прочесть 1 байт. Если recv вернет 0 — значит соединение было разорвано. (если вы не хотите читать из сокета, вызовите recv с флагом MSG_PEEK).
Может возникнуть ситуация когда данный метод не сработает. Например, FIN не доставлен, select с readfd вернет 0, а отправить нам пока нечего. О том что соединение разорвано мы так и не узнаем, пока не сделаем send (а он может, в структуре приложения, не сделан никогда). Параметр SO_KEEPALIVE мало пригоден. Для Linux, по умолчанию, детектирование соединения происходит раз в час, таймаут ожидания ответа — 15 минут. Т.е. 1 час 15 минут система будет считать что соединение есть.
Единственный способ борьбы — это реализация своего протокола подтверждения доставки пакета.
3. shutdown(), close() и closesocket()
В Windows принято, что после вызова closesocket() соединение закрывается. Так же, соединения закрываются при закрытии программы.
Система знает, какому процессу соответствуют сокеты, и закрывает их при смерти приложения. В Linix и FreeBSD это не так.
Необходимо явно сказать shutdown (посылка FIN) и close (разъединение дескриптора и сокета). Если этого не сделать, то после закрытия приложения сокеты еще будут висеть в системе некоторое время, в течение которого bind на «занятые» порты будет возвращать ошибку.
Такая же ситуация возникает если вы сделаете на серверной стороне приложения shutdown и close, закроете приложение, а на клиентской стороне эти ф-ии вызваны не будут. После этого Вы не сможете запустить серверное приложение в течении некоторого времени.
Методы борьбы — не известны. Только ждать.
В Windows есть только один механизм потоков, и он реализван в ядре. В Unix реализации потоков могут быть различны. Некоторые реализованны в пространстве ядра (posix thread для Linux и FreeBSD), другие могут быть в пространстве пользователя (у Рихтера они названы fibers).
Необходимо четко представлять чем Вы пользуетесь.
Потоки, реализованные в пространстве пользователя, имеют одну неприятную особенность — система о них не знает. Значит планировщик системы никогда не передаст управление другому потоку. Только процессу. Если же такой поток в процессе завис, то зависло и все приложение.
Простейший тест для определения в каком пространстве реализованы потоки (использован pthread, используйте другие ф-ии из выбранной вами библиотеки, аналогичные приведенным):
Если Вы видите надпись TH2. менее чем 20 раз — значит потоки реализованы в пространстве пользователя.
Методы борьбы: переходить на pthread или не допускать зависания потоков.
В Windows, mutex созданый по умолчанию ведет себя рекурсивно. Т.е. сколько раз один и тот же поток вызвал для него lock, столько же раз должен быть вызван unlock.
pthread_mitex, по умолчанию, ведет себя иначе. Для того что бы его поведение соответствовало Windows mutex (по умолчанию) необходимо создать его следующим образом:
В Windows системные исключения и исключения C++ смешаны (это точно, если вы пользуетесь MS VC). Например, сбой по памяти, попытка деления на 0, и пр. ловятся с помощью catch(. ). В Unix это не так (точно, если использовать gcc). В таких случаях приложению посылаются сигналы.
В большинстве случаев, после такого сигнала приложение можно только закрыть.
Windows код:
Методы борьбы: писать приложение так, что бы не допустить подобных ситуаций.
Программирование сокетов в Linux
Автор: Александр Шаргин
Опубликовано: 16.05.2001
Исправлено: 04.02.2006
Версия текста: 1.1
Введение
Socket API был впервые реализован в операционной системе Berkley UNIX. Сейчас этот программный интерфейс доступен практически в любой модификации Unix, в том числе в Linux. Хотя все реализации чем-то отличаются друг от друга, основной набор функций в них совпадает. Изначально сокеты использовались в программах на C/C++, но в настоящее время средства для работы с ними предоставляют многие языки (Perl, Java и др.).
Сокеты предоставляют весьма мощный и гибкий механизм межпроцессного взаимодействия (IPC). Они могут использоваться для организации взаимодействия программ на одном компьютере, по локальной сети или через Internet, что позволяет вам создавать распределённые приложения различной сложности. Кроме того, с их помощью можно организовать взаимодействие с программами, работающими под управлением других операционных систем. Например, под Windows существует интерфейс Window Sockets, спроектированный на основе socket API. Ниже мы увидим, насколько легко можно адаптировать существующую Unix-программу для работы под Windows.
Сокеты поддерживают многие стандартные сетевые протоколы (конкретный их список зависит от реализации) и предоставляют унифицированный интерфейс для работы с ними. Наиболее часто сокеты используются для работы в IP-сетях. В этом случае их можно использовать для взаимодействия приложений не только по специально разработанным, но и по стандартным протоколам — HTTP, FTP, Telnet и т. д. Например, вы можете написать собственный Web-броузер или Web-сервер, способный обслуживать одновременно множество клиентов.
Как видим, сокеты — весьма мощное и удобное средство для сетевого программирования. В этой статье я покажу, как ими пользоваться. Начав с понятия сокета и самых основных функций для работы с ним, мы постепенно перейдём к обсуждению более сложных тем. В частности, мы рассмотрим использование низкоуровневых сокетов, различные способы организации параллельного обслуживания клиентов, использование стандартных протоколов Internet и взаимодействие с программами, работающими под управлением операционной системы Microsoft Windows.
| ПРИМЕЧАНИЕ Большая часть материала, изложенного в статье, применимо ко всему семейству ОС Unix. Тем не менее, все приводимые далее факты и демонстрационные программы проверялись только под Linux, поэтому название этой ОС и вынесено в заголовок статьи. |
Основы socket API
Понятие сокета
Сокет (socket) — это конечная точка сетевых коммуникаций. Он является чем-то вроде «портала», через которое можно отправлять байты во внешний мир. Приложение просто пишет данные в сокет; их дальнейшая буферизация, отправка и транспортировка осуществляется используемым стеком протоколов и сетевой аппаратурой. Чтение данных из сокета происходит аналогичным образом.
В программе сокет идентифицируется дескриптором — это просто переменная типа int . Программа получает дескриптор от операционной системы при создании сокета, а затем передаёт его сервисам socket API для указания сокета, над которым необходимо выполнить то или иное действие.
Атрибуты сокета
С каждым сокет связываются три атрибута: домен , тип и протокол . Эти атрибуты задаются при создании сокета и остаются неизменными на протяжении всего времени его существования. Для создания сокета используется функция socket , имеющая следующий прототип.
Домен определяет пространство адресов, в котором располагается сокет, и множество протоколов, которые используются для передачи данных. Чаще других используются домены Unix и Internet, задаваемые константами AF_UNIX и AF_INET соответственно (префикс AF означает «address family» — «семейство адресов»). При задании AF_UNIX для передачи данных используется файловая система ввода/вывода Unix. В этом случае сокеты используются для межпроцессного взаимодействия на одном компьютере и не годятся для работы по сети. Константа AF_INET соответствует Internet-домену. Сокеты, размещённые в этом домене, могут использоваться для работы в любой IP-сети. Существуют и другие домены ( AF_IPX для протоколов Novell, AF_INET6 для новой модификации протокола IP — IPv6 и т. д.), но в этой статье мы не будем их рассматривать.
Тип сокета определяет способ передачи данных по сети. Чаще других применяются:
- SOCK_STREAM . Передача потока данных с предварительной установкой соединения. Обеспечивается надёжный канал передачи данных, при котором фрагменты отправленного блока не теряются, не переупорядочиваются и не дублируются. Поскольку этот тип сокетов является самым распространённым, до конца раздела мы будем говорить только о нём. Остальным типам будут посвящены отдельные разделы.
- SOCK_DGRAM . Передача данных в виде отдельных сообщений (датаграмм). Предварительная установка соединения не требуется. Обмен данными происходит быстрее, но является ненадёжным: сообщения могут теряться в пути, дублироваться и переупорядочиваться. Допускается передача сообщения нескольким получателям (multicasting) и широковещательная передача (broadcasting).
- SOCK_RAW . Этот тип присваивается низкоуровневым (т. н. «сырым») сокетам. Их отличие от обычных сокетов состоит в том, что с их помощью программа может взять на себя формирование некоторых заголовков, добавляемых к сообщению.
Обратите внимание, что не все домены допускают задание произвольного типа сокета. Например, совместно с доменом Unix используется только тип SOCK_STREAM . С другой стороны, для Internet-домена можно задавать любой из перечисленных типов. В этом случае для реализации SOCK_STREAM используется протокол TCP, для реализации SOCK_DGRAM — протокол UDP, а тип SOCK_RAW используется для низкоуровневой работы с протоколами IP, ICMP и т. д.
Наконец, последний атрибут определяет протокол, используемый для передачи данных. Как мы только что видели, часто протокол однозначно определяется по домену и типу сокета. В этом случае в качестве третьего параметра функции socket можно передать 0, что соответствует протоколу по умолчанию. Тем не менее, иногда (например, при работе с низкоуровневыми сокетами) требуется задать протокол явно. Числовые идентификаторы протоколов зависят от выбранного домена; их можно найти в документации.
Адреса
Прежде чем передавать данные через сокет, его необходимо связать с адресом в выбранном домене (эту процедуру называют именованием сокета). Иногда связывание осуществляется неявно (внутри функций connect и accept ), но выполнять его необходимо во всех случаях. Вид адреса зависит от выбранного вами домена. В Unix-домене это текстовая строка — имя файла, через который происходит обмен данными. В Internet-домене адрес задаётся комбинацией IP-адреса и 16-битного номера порта. IP-адрес определяет хост в сети, а порт — конкретный сокет на этом хосте. Протоколы TCP и UDP используют различные пространства портов.
Для явного связывания сокета с некоторым адресом используется функция bind . Её прототип имеет вид:
В качестве первого параметра передаётся дескриптор сокета, который мы хотим привязать к заданному адресу. Второй параметр, addr , содержит указатель на структуру с адресом, а третий — длину этой структуры. Посмотрим, что она собой представляет.
Поле sa_family содержит идентификатор домена, тот же, что и первый параметр функции socket . В зависимости от значения этого поля по-разному интерпретируется содержимое массива sa_data . Разумеется, работать с этим массивом напрямую не очень удобно, поэтому вы можете использовать вместо sockaddr одну из альтернативных структур вида sockaddr_XX (XX — суффикс, обозначающий домен: «un» — Unix, «in» — Internet и т. д.). При передаче в функцию bind указатель на эту структуру приводится к указателю на sockaddr . Рассмотрим для примера структуру sockaddr_in .
Здесь поле sin_family соответствует полю sa_family в sockaddr , в sin_port записывается номер порта, а в sin_addr — IP-адрес хоста. Поле sin_addr само является структурой, которая имеет вид:
Зачем понадобилось заключать всего одно поле в структуру? Дело в том, что раньше in_addr представляла собой объединение (union), содержащее гораздо большее число полей. Сейчас, когда в ней осталось всего одно поле, она продолжает использоваться для обратной совместимости.
И ещё одно важное замечание. Существует два порядка хранения байтов в слове и двойном слове. Один из них называется порядком хоста (host byte order), другой — сетевым порядком (network byte order) хранения байтов. При указании IP-адреса и номера порта необходимо преобразовать число из порядка хоста в сетевой. Для этого используются функции htons (Host TO Network Short) и htonl (Host TO Network Long). Обратное преобразование выполняют функции ntohs и ntohl .
| ПРИМЕЧАНИЕ На некоторых машинах (к PC это не относится) порядок хоста и сетевой порядок хранения байтов совпадают. Тем не менее, функции преобразования лучше применять и там, поскольку это улучшит переносимость программы. Это никак не скажется на производительности, так как препроцессор сам уберёт все «лишние» вызовы этих функций, оставив их только там, где преобразование действительно необходимо. |
Установка соединения (сервер)
Установка соединения на стороне сервера состоит из четырёх этапов, ни один из которых не может быть опущен. Сначала сокет создаётся и привязывается к локальному адресу. Если компьютер имеет несколько сетевых интерфейсов с различными IP-адресами, вы можете принимать соединения только с одного из них, передав его адрес функции bind . Если же вы готовы соединяться с клиентами через любой интерфейс, задайте в качестве адреса константу INADDR_ANY . Что касается номера порта, вы можете задать конкретный номер или 0 (в этом случае система сама выберет произвольный неиспользуемый в данный момент номер порта).
На следующем шаге создаётся очередь запросов на соединение. При этом сокет переводится в режим ожидания запросов со стороны клиентов. Всё это выполняет функция listen .
Первый параметр — дескриптор сокета, а второй задаёт размер очереди запросов. Каждый раз, когда очередной клиент пытается соединиться с сервером, его запрос ставится в очередь, так как сервер может быть занят обработкой других запросов. Если очередь заполнена, все последующие запросы будут игнорироваться. Когда сервер готов обслужить очередной запрос, он использует функцию accept .
Функция accept создаёт для общения с клиентом новый сокет и возвращает его дескриптор. Параметр sockfd задаёт слушающий сокет. После вызова он остаётся в слушающем состоянии и может принимать другие соединения. В структуру, на которую ссылается addr , записывается адрес сокета клиента, который установил соединение с сервером. В переменную, адресуемую указателем addrlen , изначально записывается размер структуры; функция accept записывает туда длину, которая реально была использована. Если вас не интересует адрес клиента, вы можете просто передать NULL в качестве второго и третьего параметров.
Обратите внимание, что полученный от accept новый сокет связан с тем же самым адресом, что и слушающий сокет. Сначала это может показаться странным. Но дело в том, что адрес TCP-сокета не обязан быть уникальным в Internet-домене. Уникальными должны быть только соединения , для идентификации которых используются два адреса сокетов, между которыми происходит обмен данными.
Установка соединения (клиент)
На стороне клиента для установления соединения используется функция connect , которая имеет следующий прототип.
Здесь sockfd — сокет, который будет использоваться для обмена данными с сервером, serv_addr содержит указатель на структуру с адресом сервера, а addrlen — длину этой структуры. Обычно сокет не требуется предварительно привязывать к локальному адресу, так как функция connect сделает это за вас, подобрав подходящий свободный порт. Вы можете принудительно назначить клиентскому сокету некоторый номер порта, используя bind перед вызовом connect . Делать это следует в случае, когда сервер соединяется с только с клиентами, использующими определённый порт (примерами таких серверов являются rlogind и rshd). В остальных случаях проще и надёжнее предоставить системе выбрать порт за вас.
Обмен данными
После того как соединение установлено, можно начинать обмен данными. Для этого используются функции send и recv . В Unix для работы с сокетами можно использовать также файловые функции read и write , но они обладают меньшими возможностями, а кроме того не будут работать на других платформах (например, под Windows), поэтому я не рекомендую ими пользоваться.
Функция send используется для отправки данных и имеет следующий прототип.
Здесь sockfd — это, как всегда, дескриптор сокета, через который мы отправляем данные, msg — указатель на буфер с данными, len — длина буфера в байтах, а flags — набор битовых флагов, управляющих работой функции (если флаги не используются, передайте функции 0). Вот некоторые из них (полный список можно найти в документации):
- MSG_OOB . Предписывает отправить данные как срочные (out of band data, OOB). Концепция срочных данных позволяет иметь два параллельных канала данных в одном соединении. Иногда это бывает удобно. Например, Telnet использует срочные данные для передачи команд типа Ctrl+C. В настоящее время использовать их не рекомендуется из-за проблем с совместимостью (существует два разных стандарта их использования, описанные в RFC793 и RFC1122). Безопаснее просто создать для срочных данных отдельное соединение.
- MSG_DONTROUTE . Запрещает маршрутизацию пакетов. Нижележащие транспортные слои могут проигнорировать этот флаг.
Функция send возвращает число байтов, которое на самом деле было отправлено (или -1 в случае ошибки). Это число может быть меньше указанного размера буфера. Если вы хотите отправить весь буфер целиком, вам придётся написать свою функцию и вызывать в ней send , пока все данные не будут отправлены. Она может выглядеть примерно так.
Использование sendall ничем не отличается от использования send , но она отправляет весь буфер с данными целиком.
Для чтения данных из сокета используется функция recv .
В целом её использование аналогично send . Она точно так же принимает дескриптор сокета, указатель на буфер и набор флагов. Флаг MSG_OOB используется для приёма срочных данных, а MSG_PEEK позволяет «подсмотреть» данные, полученные от удалённого хоста, не удаляя их из системного буфера (это означает, что при следующем обращении к recv вы получите те же самые данные). Полный список флагов можно найти в документации. По аналогии с send функция recv возвращает количество прочитанных байтов, которое может быть меньше размера буфера. Вы без труда сможете написать собственную функцию recvall , заполняющую буфер целиком. Существует ещё один особый случай, при котором recv возвращает 0. Это означает, что соединение было разорвано.
Закрытие сокета
Закончив обмен данными, закройте сокет с помощью функции close . Это приведёт к разрыву соединения.
Вы также можете запретить передачу данных в каком-то одном направлении, используя shutdown .
Параметр how может принимать одно из следующих значений:
- 0 — запретить чтение из сокета
- 1 — запретить запись в сокет
- 2 — запретить и то и другое
Хотя после вызова shutdown с параметром how , равным 2, вы больше не сможете использовать сокет для обмена данными, вам всё равно потребуется вызвать close , чтобы освободить связанные с ним системные ресурсы.
Обработка ошибок
До сих пор я ни слова не сказал об ошибках, которые могут происходить (и часто происходят) в процессе работы с сокетами. Так вот: если что-то пошло не так, все рассмотренные нами функции возвращают -1, записывая в глобальную переменную errno код ошибки. Соответственно, вы можете проанализировать значение этой переменной и предпринять действия по восстановлению нормальной работы программы, не прерывая её выполнения. А можете просто выдать диагностическое сообщение (для этого удобно использовать функцию perror ), а затем завершить программу с помощью exit . Именно так я буду поступать в демонстрационных примерах.
Отладка программ
Начинающие программисты часто спрашивают, как можно отлаживать сетевую программу, если под рукой нет сети. Оказывается, можно обойтись и без неё. Достаточно запустить клиента и сервера на одной машине, а затем использовать для соединения адрес интерфейса внутренней петли (loopback interface). В программе ему соответствует константа INADDR_LOOPBACK (не забудьте применять к ней функцию htonl !). Пакеты, направляемые по этому адресу, в сеть не попадают. Вместо этого они передаются стеку протоколов TCP/IP как только что принятые. Таким образом моделируется наличие виртуальной сети, в которой вы можете отлаживать ваши сетевые приложения.
Для простоты я буду использовать в демонстрационных примерах интерфейс внутренней петли.
Эхо-клиент и эхо-сервер
Теперь, когда мы изучили основные функции для работы с сокетами, самое время посмотреть, как они используются на практике. Для этого я написал две небольшие демонстрационные программы. Эхо-клиент посылает сообщение «Hello there!» и выводит на экран ответ сервера. Его код приведён в листинге 1. Эхо-сервер читает всё, что передаёт ему клиент, а затем просто отправляет полученные данные обратно. Его код содержится в листинге 2.
Листинг 1. Эхо-клиент.
Листинг 2. Эхо-сервер.
Обмен датаграммами
Как уже говорилось, датаграммы используются в программах довольно редко. В большинстве случаев надёжность передачи критична для приложения, и вместо изобретения собственного надёжного протокола поверх UDP программисты предпочитают использовать TCP. Тем не менее, иногда датаграммы оказываются полезны. Например, их удобно использовать при транслировании звука или видео по сети в реальном времени, особенно при широковещательном транслировании.
Поскольку для обмена датаграммами не нужно устанавливать соединение, использовать их гораздо проще. Создав сокет с помощью socket и bind , вы можете тут же использовать его для отправки или получения данных. Для этого вам понадобятся функции sendto и recvfrom .
Функция sendto очень похожа на send . Два дополнительных параметра to и tolen используются для указания адреса получателя. Для задания адреса используется структура sockaddr , как и в случае с функцией connect . Функция recvfrom работает аналогично recv . Получив очередное сообщение, она записывает его адрес в структуру, на которую ссылается from , а записанное количество байт — в переменную, адресуемую указателем fromlen . Как мы знаем, аналогичным образом работает функция accept .
Некоторую путаницу вносят присоединённые датаграммные сокеты (connected datagram sockets). Дело в том, что для сокета с типом SOCK_DGRAM тоже можно вызвать функцию connect , а затем использовать send и recv для обмена данными. Нужно понимать, что никакого соединения при этом не устанавливается. Операционная система просто запоминает адрес, который вы передали функции connect , а затем использует его при отправке данных. Обратите внимание, что присоединённый сокет может получать данные только от сокета, с которым он соединён.
Для иллюстрации процесса обмена датаграммами я написал две небольшие программы — sender (листинг 3) и receiver (листинг 4). Первая отправляет сообщения «Hello there!» и «Bye bye!», а вторая получает их и печатает на экране. Программа sender демонстрирует применение как обычного, так и присоединённого сокета, а receiver использует обычный.
Листинг 3. Программа sender.
Листинг 4. Программа receiver.
Использование низкоуровневых сокетов
Низкоуровневые сокеты открывают перед вами новые горизонты. Они предоставляют программисту полный контроль над содержимым пакетов, которые отправляются в путешествие по сети. С другой стороны, они сложнее в использовании и обладают плохой переносимостью. Вот почему использовать их следует только в случае необходимости. Например, без них не обойтись при разработке системных утилит типа ping и traceroute.
Первым делом выясним, чем низкоуровневые сокеты отличаются от обычных. Работая с обычными сокетами, вы передаёте системе «чистые» данные, а она сама заботится о добавлении к ним необходимых заголовков (а иногда ещё и концевиков). Например, когда вы посылаете сообщение через UDP-сокет, к нему добавляется сначала UDP-заголовок, потом IP-заголовок, а в самом конце — заголовок аппаратного протокола, который используется в вашей локальной сети (например, Ethernet). В результате получается кадр, показанный на рисунке 1.

Рисунок 1
Низкоуровневые сокеты позволяют вам включать в буфер с данными заголовки некоторых протоколов. Например, вы можете включить в ваше сообщение TCP- или UDP-заголовок, предоставив системе сформировать для вас IP-заголовок, а можете вообще сформировать все заголовки самостоятельно. Разумеется, при этом вам придётся изучить работу соответствующих протоколов и строго соблюсти формат их заголовков, иначе программа работать не будет.
При работе с низкоуровневыми сокетами вам придётся указывать в третьем параметре функции socket тот протокол, к заголовкам которого вы хотите получить доступ. Константы для основных протоколов Internet объявлены в файле netinet/in.h . Они имеют вид IPPROTO_XXX , где XXX-название протокола: IPPROTO_TCP , IPPROTO_UDP , IPPROTO_RAW (в последнем случае вы получите возможность поработать с «сырым» IP и формировать IP-заголовки вручную).
| Все числовые данные в заголовках должны записываться в сетевом формате. Поэтому не забывайте использовать функции htons и htonl . |
Чтобы проиллюстрировать всё это примером, я переписал программу sender из предыдущего раздела с использованием низкоуровневых UDP-сокетов. При этом мне пришлось вручную формировать UDP-заголовок отправляемого сообщения. Я выбрал для примера UDP, потому что у этого протокола заголовок выглядит совсем просто (рисунок 2).
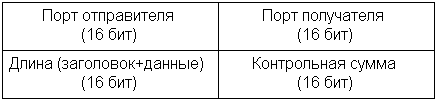
Рисунок 2
Код примера приведён в листинге 5. Хочу обратить ваше внимание на несколько моментов. Во-первых, я не стал задавать номер порта в структуре sockaddr_in . Поскольку этот номер содержится в UDP-заголовке, от поля sin_port уже ничего не зависит. Во-вторых, я записал в качестве контрольной суммы ноль, чтобы не утомлять вас её вычислением. Протокол UDP является ненадёжным по своей природе, поэтому он допускает подобную вольность. Но другие протоколы (например, IP) могут и не допускать. Наконец, обратите внимание, что все данные UDP-заголовка форматируются с использованием htons .
Листинг 5. Программа sender с использованием низкоуровневых сокетов.
Функции для работы с адресами и DNS
В этом разделе мы обсудим несколько функций, без которых можно написать учебный пример, но без которых вряд ли обойдётся реальная программа. Поскольку для идентификации хостов в Internet широко используются доменные имена, мы должны изучить механизм преобразования их в IP-адреса. Кроме того мы изучим несколько удобных вспомогательных функций.
IP-адреса принято записывать в виде четырёх чисел, разделённых точками. Для преобразования адреса, записанного в таком формате, в число и наоборот используется семейство функций inet_addr , inet_aton и inet_ntoa .
Функция inet_addr часто используется в программах. Она принимает строку и возвращает адрес (уже с сетевым порядком следования байтов). Проблема с этой функцией состоит в том, что значение -1, возвращаемое ею в случае ошибки, является в то же время корректным адресом 255.255.255.255 (широковещательный адрес). Вот почему сейчас рекомендуется использовать более новую функцию inet_aton (Ascii TO Network). Для обратного преобразования используется функция inet_ntoa (Network TO Ascii). Обе эти функции работают с адресами в сетевом формате. Обратите внимание, что в случае ошибки они возвращают 0, а не -1.
Для преобразования доменного имени в IP-адрес используется функция gethostbyname .
Эта функция получает имя хоста и возвращает указатель на структуру с его описанием. Рассмотрим эту структуру более подробно.
- h_name . Имя хоста.
- h_aliases . Массив строк, содержащих псевдонимы хоста. Завершается значением NULL.
- h_addrtype . Тип адреса. Для Internet-домена — AF_INET .
- h_length . Длина адреса в байтах.
- h_addr_list . Массив, содержащий адреса всех сетевых интерфейсов хоста. Завершается нулём. Обратите внимание, что байты каждого адреса хранятся с сетевым порядке, поэтому htonl вызывать не нужно.
Как видим, gethostbyname возвращает достаточно полную информацию. Если нас интересует адрес хоста, мы можем выбрать его из массива h_addr_list . Часто берут самый первый адрес (как мы видели выше, для ссылки на него определён специальный макрос h_addr ). Для определения имени хоста по адресу используется функция gethostbyaddr . Вместо строки она получает адрес (в виде sockaddr ) и возвращает указатель на ту же самую структуру hostent . Используя эти две функции, нужно помнить, что они сообщают об ошибке не так, как остальные: вместо указателя возвращается NULL , а расширенный код ошибки записывается в глобальную переменную h_errno (а не errno ). Соответственно, для вывода диагностического сообщения следует использовать herror вместо perror .
| Следует иметь в виду, что функции gethostbyname и gethostbyaddr возвращают указатель на статическую область памяти. Это означает, что каждое новое обращение к одной из этих функций приведёт к перезаписи данных, полученных при преыдущем обращении. |
В заключение рассмотрим ещё одно семейство полезных функций — gethostname , getsockname и getpeername .
Функция gethostname используется для получения имени локального хоста. Далее его можно преобразовать в адрес при помощи gethostbyname . Это даёт нам способ в любой момент программно получить адрес машины, на которой выполняется наша программа, что может быть полезным во многих случаях.
Функция getpeername позволяет в любой момент узнать адрес сокета на «другом конце» соединения. Она получает дескриптор сокета, соединённого с удалённым хостом, и записывает адрес этого хоста в структуру, на которую указывает addr . Фактическое количество записанных байт помещается по адресу addrlen (не забудьте записать туда размер структуры addr до вызова getpeername ). Полученный адрес при необходимости можно преобразовать в строку, используя inet_ntoa или gethostbyaddr . Функция getsockname по назначению обратна getpeername и позволяет определить адрес сокета на «нашем конце» соединения.
Параллельное обслуживание клиентов
Следующий важный вопрос, который нам предстоит обсудить, — это параллельное обслуживание клиентов. Эта проблема становится актуальной, когда сервер должен обслуживать большое количество запросов. Конечно, на машине с одним процессором настоящей параллельности достичь не удастся. Но даже на одной машине можно добиться существенного выигрыша в производительности. Допустим, сервер отправил какие-то данные клиенту и ждёт подтверждения. Пока оно путешествует по сети, сервер вполне мог бы заняться другими клиентами. Для реализации такого алгоритма обслуживания существует множество способов, но чаще всего применяются два из них.
Способ 1
Этот способ подразумевает создание дочернего процесса для обслуживания каждого нового клиента. При этом родительский процесс занимается только прослушиванием порта и приёмом соединений. Чтобы добиться такого поведения, сразу после accept сервер вызывает функцию fork для создания дочернего процесса (я предполагаю, что вам знакома функция fork ; если нет, обратитесь к документации). Далее анализируется значение, которое вернула эта функция. В родительском процессе оно содержит идентификатор дочернего, а в дочернем процессе равно нулю. Используя этот признак, мы переходим к очередному вызову accept в родительском процессе, а дочерний процесс обслуживает клиента и завершается ( _exit ).
С использованием этой методики наш эхо-сервер перепишется, как показано в листинге 6.
Листинг 6. Эхо-сервер (версия 2, fork)
Очевидное преимущество такого подхода состоит в том, что он позволяет писать весьма компактные, понятные программы, в которых код установки соединения отделён от кода обслуживания клиента. К сожалению, у него есть и недостатки. Во-первых, если клиентов очень много, создание нового процесса для обслуживания каждого из них может оказаться слишком дорогостоящей операцией. Во-вторых, такой способ неявно подразумевает, что все клиенты обслуживаются независимо друг от друга. Однако это может быть не так. Если, к примеру, вы пишете чат-сервер, то ваша основная задача — поддерживать взаимодействие всех клиентов, присоединившихся к нему. В этих условиях границы между процессами станут для вас серьёзной помехой. В подобном случае вам следует серьёзно рассмотреть другой способ обслуживания клиентов.
Способ 2
Второй способ основан на использовании неблокирующих сокетов (nonblocking sockets) и функции select . Сначала разберёмся, что такое неблокирующие сокеты. Сокеты, которые мы до сих пор использовали, являлись блокирующими (blocking). Это название означает, что на время выполнения операции с таким сокетом ваша программа блокируется. Например, если вы вызвали recv , а данных на вашем конце соединения нет, то в ожидании их прихода ваша программа «засыпает». Аналогичная ситуация наблюдается, когда вы вызываете accept , а очередь запросов на соединение пуста. Это поведение можно изменить, используя функцию fcntl .
Эта несложная операция превращает сокет в неблокирующий. Вызов любой функции с таким сокетом будет возвращать управление немедленно. Причём если затребованная операция не была выполнена до конца, функция вернёт -1 и запишет в errno значение EWOULDBLOCK . Чтобы дождаться завершения операции, мы можем опрашивать все наши сокеты в цикле, пока какая-то функция не вернёт значение, отличное от EWOULDBLOCK . Как только это произойдёт, мы можем запустить на выполнение следующую операцию с этим сокетом и вернуться к нашему опрашивающему циклу. Такая тактика (называемая в англоязычной литературе polling) работоспособна, но очень неэффективна, поскольку процессорное время тратится впустую на многократные (и безрезультатные) опросы.
Чтобы исправить ситуацию, используют функцию select . Эта функция позволяет отслеживать состояние нескольких файловых дескрипторов (а в Unix к ним относятся и сокеты) одновременно.
Функция select работает с тремя множествами дескрипторов, каждое из которых имеет тип fd_set . В множество readfds записываются дескрипторы сокетов, из которых нам требуется читать данные (слушающие сокеты добавляются в это же множество). Множество writefds должно содержать дескрипторы сокетов, в которые мы собираемся писать, а exceptfds — дескрипторы сокетов, которые нужно контролировать на возникновение ошибки. Если какое-то множество вас не интересуют, вы можете передать вместо указателя на него NULL . Что касается других параметров, в n нужно записать максимальное значение дескриптора по всем множествам плюс единица, а в timeout — величину таймаута. Структура timeval имеет следующий формат.
Поле «микросекунды» смотрится впечатляюще. Но на практике вам не добиться такой точности измерения времени при использовании select . Реальная точность окажется в районе 100 миллисекунд.
Теперь займёмся множествами дескрипторов. Для работы с ними предусмотрены функции FD_XXX , показанные выше; их использование полностью скрывает от нас детали внутреннего устройства fd_set . Рассмотрим их назначение.
- FD_ZERO(fd_set *set) — очищает множество set
- FD_SET(int fd, fd_set *set) — добавляет дескриптор fd в множество set
- FD_CLR(int fd, fd_set *set) — удаляет дескриптор fd из множества set
- FD_ISSET(int fd, fd_set *set) — проверяет, содержится ли дескриптор fd в множестве set
Если хотя бы один сокет готов к выполнению заданной операции, select возвращает ненулевое значение, а все дескрипторы, которые привели к «срабатыванию» функции, записываются в соответствующие множества. Это позволяет нам проанализировать содержащиеся в множествах дескрипторы и выполнить над ними необходимые действия. Если сработал таймаут, select возвращает ноль, а в случае ошибки -1. Расширенный код записывается в errno .
Программы, использующие неблокирующие сокеты вместе с select , получаются весьма запутанными. Если в случае с fork мы строим логику программы, как будто клиент всего один, здесь программа вынуждена отслеживать дескрипторы всех клиентов и работать с ними параллельно. Чтобы проиллюстрировать эту методику, я в очередной раз переписал эхо-сервер с использованием select . Новая версия приведена в листинге 7. Обратите внимание, что эта программа, в отличие от всех остальных, написана на C++ (а не на C). Я воспользовался классом set из библиотеки STL языка C++, чтобы облегчить работу с набором дескрипторов и сделать её более понятной.
Листинг 7. Эхо-сервер (версия 3, неблокирующие сокеты и select).
Работа по стандартным протоколам
Как я уже говорил, сокеты могут использоваться при написании приложений, работающих по протоколам прикладного уровня Internet (HTTP, FTP, SMTP и т. д.). При этом взаимодействие клиента и сервера происходит по той же самой схеме, что и взаимодействие эхо-клиента и эхо-сервера в нашем примере. Разница в том, что данные, которыми обмениваются клиент и сервер, интерпретируются в соответствии с предписаниями соответствующего протокола.
Например, веб-сервер может работать по следующему алгоритму.
- Создаём слушающий сокет и привязываем его к 80-му порту (стандартный порт для HTTP-сервера).
- Принимаем очередной запрос на соединение.
- Читаем HTTP-запрос от клиента (он имеет стандартный формат и описан в RFC2616).
- Обрабатываем запрос и отправляем клиенту ответ, который также имеет стандартный формат.
- Разрываем соединение.
Веб-броузер, который является клиентом по отношению к веб-серверу, может использовать похожий алгоритм.
- Соединяемся с сервером по заданному адресу.
- Отправляем ему HTTP-запрос.
- Получаем и обрабатываем ответ сервера (например, форматируем и выводим на экран полученную HTML-страницу).
- Разрываем соединение.
Как видим, в работе по стандартным протоколам нет ничего сложного или принципиально нового.
Прорыв за пределы платформы
В мире Internet взаимодействие программ, работающих на разных платформах, встречается сплошь и рядом. Так, практически ежесекундно очередной Internet Explorer подсоединяется к веб-серверу Apache, а очередной Netscape Navigator совершенно спокойно подключается к IIS. Вот почему весьма полезно писать программы так, чтобы их можно было без труда переносить на другие платформы. В этом разделе мы посмотрим, как переносить Linux-программы, использующие сокеты, на платформу Windows.
Список основных отличий socket API и Winsock API выглядит примерно так.
- В Windows набор заголовочных файлов существенно уменьшен. Собственно говоря, вам нужно включить всего один файл winsock.h (или winsock2.h, если вы хотите использовать расширенные возможности Winsock 2).
- В Windows библиотеку Winsock необходимо явно проинициализировать до обращения к любым другим функциям из неё. Это делается с помощью функции WSAStartup . Кроме того, существует функция WSACleanup , которую следует вызывать по завершении работы с сокетами.
- Как мы знаем, в Linux дескрипторы сокетов имеют тип int . В Windows сокеты не являются файловыми дескрипторами, поэтому для них введён свой тип SOCKET . Хотя этот тип и объявлен как u_int , полагаться на это в программе не следует.
- В Windows для работы с сокетами не используются функции файлового ввода/вывода ( read и write ). Вместо close используется closesocket .
- В Windows глобальная переменная errno не используется. Вместо этого код последней ошибки сохраняется системой для каждого потока отдельно. Чтобы его получить, используется функция WSAGetLastError .
- В Windows введены дополнительные константы, которые следует применять вместо конкретных чисел. Так, значения, возвращаемые функциями Winsock, следует сравнивать с константами INVALID_SOCKET или SOCKET_ERROR , а не с -1.
Если переписать наш эхо-клиент с учётом приведённых особенностей Winsock API, а затем скомпилировать его под Windows (например, с помощью Visual C++), он вполне сможет взаимодействовать с эхо-сервером, работающим под Linux. Таким образом, сокеты позволяют решить проблему кроссплатформенного взаимодействия двух приложений.
К сожалению, различия socket API и Winsock не ограничиваются приведённым списком. При портировании более сложных, «продвинутых» программ начинают возникать более принципиальные проблемы. Например, под Windows существуют ограничения в поддержке низкоуровневых сокетов (они впервые появились в спецификации Winsock 2, а возможность напрямую манипулировать IP-заголовками доступна только под Windows 2000). Кроме того, проблемы могут возникнуть с функциями, не имеющими прямого отношения к socket API. Так, в Windows нет прямого аналога функции fork , и для организации параллельного обслуживания клиентов придётся прибегнуть к другим средствам.
Заключение
В этой статье мы рассмотрели целый ряд важных аспектов программирования сокетов. Тем самым мы заложили прочную основу для дальнейших исследований в этой области. Разумеется, большое количество деталей осталось за рамками нашей беседы. Но теперь вы сможете самостоятельно почерпнуть недостающую информацию из man-страниц Linux и из собственного практического опыта. Желаю удачи.



