- Команда sort в Linux
- Синтаксис
- Опции
- Вывод результатов в файл
- Вывод результатов в обратном порядке
- Сортировка по заданным полям
- Удаление дублирующих записей
- Проверка сортировки
- Заключение
- Команда sort в Linux с примерами
- Сохранить результат в другом файле
- Сортировка по номеру столбца
- Проверьте отсортированное состояние файла
- Отсортированные данные
- Удалить повторяющиеся элементы
- Сортировка с помощью конвейера в команде
- Случайная сортировка
- Сортировка данных из нескольких файлов
- Сортировать с присоединением
- Сравнить файлы с помощью сортировки
- Заключение
- Примеры использования утилиты sort
- Принципы, по которым команда sort linux сортирует строки
- Пример сортировки и обратной сортировки
- Сортировка по колонке и по нескольким полям
- Использование sort для удаления дубликатов
- Linux sort по нескольким полям
- Программа sort без опций
- Параметры sort
- Опции -n и -k
- Опция -r
- Опция -M
- Опция -t
- Опция -c
- Опция -u
- Опция -b
- Опция -d
- Опция -i
- Опция -f
- Опция -g
- Опция -T
- Опция -S
- Опция -s
- Опция -z
- Опция -o
- Послесловие
- Команда sort и кириллица
- Резюме команды sort
- Приложение
Команда sort в Linux
sort – простая и очень полезная команда, которая меняет порядок строк в текстовом файле, то есть осуществляет их сортировку по алфавиту или в соответствии с числовыми значениями. По умолчанию правила сортировки следующие:
- строки, начинающиеся с цифр, выводятся раньше строк, начинающихся с букв;
- строки, начинающиеся с букв, выводятся в алфавитном порядке;
- строки, начинающиеся со строчных букв, выводятся раньше строк, начинающихся с таких же заглавных.
Правила сортировки можно изменять при помощи опций. Мы рассмотрим их ниже.
Синтаксис
Основной синтаксис команды следующий
Команда также может быть использована в составе конвейеров (пайпов). Например
Опции
Как видим, сейчас строки выводятся в том же порядке как и были записаны. Для его сортировки в алфавитном порядке выполните команду:
Вы получите следующий результат:
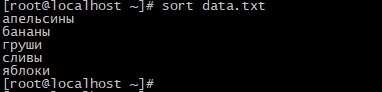
Как видим сейчас строки отсортированы в алфавитном порядке.
Вывод результатов в файл
Команда sort не изменяет исходный файл, а просто выводит его содержимое в отсортированном виде. Чтобы сохранить результаты сортировки, воспользуйтесь опцией -o или перенаправлением вывода:
Выведем файл output.txt:
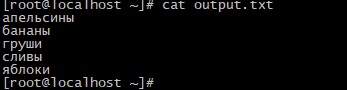
Вывод результатов в обратном порядке
Опция -r позволяет выводить результаты сортировки в обратном порядке:
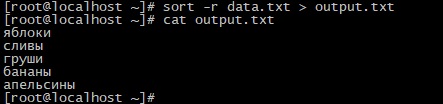
Сортировка по заданным полям
Для сортировки по определенным полям используется опция –k. Она указывается в следующем формате:
Где ПОЛЕ1 и т.д. – номер поля (столбца), по которому осуществляется сортировка. Для примера создадим новый файл prices.txt со следующим содержимым:
Для его сортировки по второму столбцу можно выполнить следующую команду:
Результат будет следующим
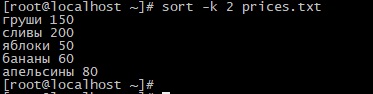
На первый взгляд кажется что команда сработала неправильно. Действительно, кажется что в самом верху должны стоять сливы, а яблоки нижней строкой, да и апельсины дороже банан. Но на самом деле команда sort воспринимает цифры не как число, а как строку, т.е сортировка происходит по первой цифре. Вот тогда все встает на свои места команда вывела последовательность не числовую сортировку «200-150-80-60-50» а строковую «1-2-5-6-8».
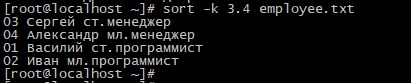
Опцию -k можно задавать в более сложном виде. Каждое поле задается в виде X.Y, где X – номер поля, а Y – начальная позиция поля, с которой начинается сортировка. Для примера создадим файл employee.txt со следующим содержимым:
Если просто указать номер поля, результат сортировки будет следующим:

Значение начальной позиции сортировки 4 заставит команду игнорировать первые 3 буквы и начнет сортировку с 4-й, т.е после «ст.» и «мл.»
Удаление дублирующих записей
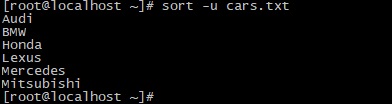
Опция -u удаляет из результатов дублирующие записи и выводит только уникальные поля. Допустим, у нас есть файл cars.txt со следующими данными:
Выведет следующий результат:
Проверка сортировки
Опция -с позволяет проверить, отсортированы ли данные в файле. Если выполнение команды с этой опцией не возвращает никакого результата, значит, строки файла уже упорядочены. Иначе будут выведены строки, нарушающие порядок сортировки. Допустим, файл cars2.txt содержит следующие данные:
Audi
Cadillac
BMW
Dodge
Для проверки выполним следующую команду:
Вот ее результат.
Мы видим, что строка «BMW» нарушает порядок сортировки:
Заключение
Команда sort – простой, но очень мощный и полезный при работе с данными инструмент. У нее есть множество разнообразных опций, помимо уже рассмотренных, которые можно узнать на соответствующей man-странице. Кроме того, ее можно использовать совместно с командами find и join для поиска по большому количеству файлов или объединения результатов.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Команда sort в Linux с примерами
Команда SORT в Linux используется для упорядочивания записей в определенном порядке в соответствии с используемой опцией. Это помогает в сортировке данных в файле построчно. Команда SORT имеет разные функции, которым она следует в результате команд. Во-первых, строки с номерами будут предшествовать буквенным строкам. Строки с строчными буквами будут отображаться раньше, чем строки с тем же символом в верхнем регистре.
Предпосылка
Вам необходимо установить Ubuntu на виртуальный ящик и настроить его. Пользователи должны быть созданы, чтобы иметь права доступа к приложениям.
Синтаксис
Пример
Это простой пример сортировки файла, имеющего данные об именах. Эти имена расположены не по порядку, и для того, чтобы упорядочить их, вам необходимо их отсортировать.
Итак, рассмотрим файл с именем file1.txt. Мы отобразим содержимое файла с помощью добавленной команды:
Теперь используйте команду для сортировки текста в файле:
Сохранить результат в другом файле
Используя команду сортировки, вы узнаете, что ее результат только отображается, но не сохраняется. Чтобы зафиксировать результат, нам нужно его сохранить. Для этого используется опция —o в команде сортировки.
Рассмотрим пример имени sample1.txt с названиями автомобилей. Мы хотим отсортировать их и сохранить полученные данные в отдельном файле. Во время выполнения создается файл с именем result.txt, и в нем сохраняется соответствующий вывод. Данные из sample1.txt передаются в результирующий файл, а затем с помощью —o соответствующие данные сортируются. Мы отобразили данные с помощью команды cat:
$ sort –o result.txt sample1.txt
Вывод показывает, что данные отсортированы и сохранены в другом файле.
Сортировка по номеру столбца
Сортировка выполняется не только по одному столбцу. Мы можем отсортировать один столбец из-за второго столбца. Приведем пример текстового файла, в котором есть имена и оценки студентов. Мы хотим расположить их в порядке возрастания. Поэтому мы будем использовать в команде ключевое слово —k. В то время как —n используется для числовой сортировки.
Поскольку есть два столбца, поэтому 2 используется с n.
Проверьте отсортированное состояние файла
Если вы не уверены, отсортирован данный файл или нет, удалите это сомнение с помощью команды, которая проясняет путаницу и отображает сообщение. Мы рассмотрим два основных примера:
Теперь рассмотрим несортированный файл с названиями овощей.
В команде будет использоваться ключевое слово —c. Это проверит, отсортированы ли данные в файле или нет. Если данные не отсортированы, то вывод будет отображать номер строки первого слова, в котором присутствует несортированность, а также слово.
Из приведенного вывода вы можете понять, что 3- е слово в файле было неуместным.
Отсортированные данные
В этом случае, когда данные уже организованы, больше ничего делать не нужно. Рассмотрим файл result.txt.
Из результата вы можете видеть, что не отображается сообщение, указывающее на то, что данные в соответствующем файле уже отсортированы.
Удалить повторяющиеся элементы
Вот самый полезный вариант. Это помогает удалить повторяющиеся слова в файле и упорядочить элемент файла. Он также поддерживает согласованность данных в файле.
Представьте, что имя файла file2.txt содержит имена субъектов, но одна тема повторяется несколько раз. Затем команда сортировки будет использовать ключевое слово —u для удаления дублирования и родства:
Теперь вы можете видеть, что повторяющиеся элементы удаляются из вывода и что данные также сортируются.
Сортировка с помощью конвейера в команде
Если мы хотим отсортировать данные файла, предоставив список каталога относительно размеров файлов, мы включим все соответствующие данные каталога. ’Ls’ используется в команде, и -l отобразит его. Pipe поможет в упорядоченном отображении файлов.

Случайная сортировка
Иногда, выполняя какую-либо функцию, можно нарушить аранжировку. Если вы хотите расположить данные в любой последовательности и если нет критериев для сортировки, предпочтительнее случайная сортировка. Рассмотрим файл с именем sample3.txt, содержащий названия континентов.
Соответствующие выходные данные показывают, что файл отсортирован, а элементы расположены в другом порядке.
Сортировка данных из нескольких файлов
Одна из самых полезных команд сортировки — это одновременная сортировка данных из разных файлов. Это можно сделать с помощью команды find. Выходные данные команды find будут действовать как входные данные для команды после канала, который является командой сортировки. Ключевое слово Find используется для выдачи только одного файла в каждой строке, или мы можем сказать, что оно использует разрыв после каждого слова.
Например, давайте рассмотрим три файла с именами sample1.txt, sample2.txt и sample3.txt. Здесь «?» представляет собой любое число, за которым следует слово «образец». Find извлечет все три файла, и их данные будут отсортированы с помощью команды sort с инициативой pipe:
Выходные данные показывают, что данные всех файлов серии sample.txt отображаются и упорядочены в алфавитном порядке.

Сортировать с присоединением
Теперь мы представляем пример, который сильно отличается от тех, которые обсуждались ранее в этом руководстве. В дополнение к сортировке мы использовали join. Этот процесс выполняется таким образом, что оба файла сначала сортируются, а затем объединяются с помощью ключевого слова join.
Рассмотрим два файла, которые вы хотите объединить.
Теперь используйте приведенный ниже запрос, чтобы применить данную концепцию:
Из вывода видно, что данные обоих файлов объединены в отсортированном виде.
Сравнить файлы с помощью сортировки
Мы также можем принять концепцию сравнения двух файлов. Техника такая же, как и для стыковки. Сначала сортируются два файла, а затем данные в них сравниваются.
Рассмотрим те же два файла, что и в предыдущем примере. Sample2.txt и sample3.txt:
Данные сортируются и упорядочиваются поочередно. Начальная строка файла sample2.txt записывается рядом с первой строкой файла sample3.txt.
Заключение
В этой статье мы рассказали об основных функциях и параметрах команды сортировки. Команда сортировки Linux очень полезна для обслуживания данных и фильтрации всех бесполезных элементов из файлов.
Источник
Примеры использования утилиты sort
sort — UNIX‐ утилита, сортирует содержимое указанных файлов, с учётом установленной в среде переменных локализации.
Утилиту sort можно использовать для сортировки текста из одного или нескольких файлов или c помощью нее может быть выполнена сортировка вывода linux для какой-либо команды, например использования утилиты sort для обнаружения DoS-атак.
Принципы, по которым команда sort linux сортирует строки
Пример сортировки и обратной сортировки
Прямая сортировка файл, по принципам описанным выше, происходит по умолчанию. Просто вызовите команду sort и укажите нужный файл. Например, мы хотим отсортировать по алфавиту файл служб Linux (/etc/services), который хранит информацию о многочисленных службах, которые клиентские приложения могут использовать на компьютере. Внутри файла services находятся имя службы, номер порта и протокол, который он использует, и любые применимые псевдонимы.
Для обратной сортировки используйте ключ r, команда будет выглядеть так:
Сортировка по колонке и по нескольким полям
В этом примере мне нужно вывести все лог файлы и отсортировать их по колонке с названием месяца. Колонка указывается опцией -k, номер колонки для вывода команды ls седьмой. Итого получим такую команду для запуска:
Для сортировки по числовому значению используется опция -n:
Мы можем сортировать данные по нескольким полям, например, отсортируем вывод ls по второму первично и вторично девятому полях:
Использование sort для удаления дубликатов
Команда sort Linux позволяет не только сортировать строки, но и удалять дубликаты, для этого есть опция -u.
Источник
Linux sort по нескольким полям
Команда sort сортирует содержимое файла в алфавитном или нумерологическом порядке. Если задать несколько файлов, то команда sort соединит их и, рассортировав, выдаст единым выводом. По умолчанию, объектом сортировки будут строки, однако опции позволяют выбирать объект сортировки: колонки, столбцы и прочие элементы форматирования файла. Разделителем между ними служат пробелы, однако соответствующие опции позволяют задать иные разделители.
Команда sort весьма древняя, она может служить образцом программирования утилит в ранних 70-х годах прошлого века. У команды множество опций, и их разнообразные сочетания, а также способы задания разделителей, хорошо развивают память и воображение.
Программа sort без опций
Я составил список своих должников и записал их в файл debts.txt:
Если мне придет в голову рассортировать должников по алфавиту, то я дам команду:
А могу и в обратном алфавиту порядке:
Параметры sort
Опции -n и -k
Приходится рассматривать эти две опции вместе, так как они позволяют сразу ввести читателя в курс дела, а не рассматривать множество простых примеров.
Опция -n используется всегда, когда нужно сортировать числа, разумеется в порядке возрастания (или убывания, добавив опцию -r).
Опция -k позволяет задавать объект сортировки: все эти столбцы, колонки, и тому подобные элементы форматирования файла.
Итак, я хочу выявить самых злостных должников по мере убывания долга:
Опция -n сообщает команде, что сортировать придется числа, опция -r , что в обратном порядке, а опция -k задает объект — вторую колонку текста.
У нас есть еще одна колонка с числами месяцев, можно для тренировки рассортировать список по числам разных месяцев, хотя никакого практического смысла это не имеет:
Видите, в пятой колонке числа идут по возрастающей. Древность программы сказывается еще и в том, что можно вводить опции по-разному. Например можно набрать:
с тем же результатом. И даже:
Должен предупредить, что существует два стиля задания объекта сортировки. (Имейте в виду, по-английски эти объекты называются fields, что обычно переводится как поля. Если видите в манах слова: fields или поля, знайте — речь идет о колонках, столбцах, или иных элементах форматирования текста). Но вернемся к стилям задания этих самых «полей».
Новый стиль использует опцию -k и цифры, указывающие порядковый номер нужной колонки с начала строки (начиная с 1).Возьмем файл pay.txt:
И дадим команду:
Сортировка произошла по первому символу второй колонки, что не дало нам никакой пользы. Изменим команду:
Указав пятый символ (считая точки) во второй колонке (-k2.5), мы получили алфавитный список сотрудников.
Теперь рассмотрим файл ivanov.txt:
Рассортируем его строго по второй колонке, не принимая во внимание колонку с инициалами:
Для этого мы применили опцию -k 2,2. Первая двойка означает начало объекта сортировки (колонки текста), а вторая двойка через запятую — конец объекта сортировки. То есть команде запрещено использовать для сортировки символы после последней буквы второй колонки.
Мы видим, что Ивановы идут в том же порядке, что и в исходном файле. А если мы хотим рассортировать Ивановых в алфавитном порядке их инициалов?
Мы приказали использовать для сортировки вторую и третью колонки текста (-k 2,3). Теперь Ивановы отсортированы и по инициалам. Но важнее знать, кто из Ивановых больше должен:
Теперь инициалы не сортируются, так как первичная сортировка проводится строго по второй колонке (-k 2,2), а вторичная сортировка (-k 4n) по 4 колонке, в нумерологическом порядке, и только среди Ивановых (то есть тех, кто не различался по результатам первичной сортировки). Теперь становится понятно, зачем нужна такая сортировка — строго по заданному объекту.
Надеюсь, что новый стиль написания опции -k стал понятен. Новый стиль применяется на всех современных версиях команды sort, включая GNU Coreutils, которыми укомплектованы все новые дистрибутивы Линукс.
Вкратце коснусь старого стиля написания опции -k. Вот пример задания третьего столбца для нумерологической сортировки:
- Новый стиль: sort -k 3,3n имя_файла
- Старый стиль: sort +2 -3n имя_файла
Старый стиль работает на новых версиях программы, но рассматривать его в подробностях я не стану, чтобы не запутаться самому и не запутать читателя. Нам хватит путаницы и с новым стилем.
Опция -r
Мы уже познакомились с ней. Она заставляет команду sort сортировать в обратном порядке. (От ‘z’ к ‘a’ и от 1000000 к 0).
Опция -M
Я не могу не остановится на одной удивительной способности команды sort — она может сортировать даже месяцы. Вернемся к файлу debts.txt:
Названия месяцев у нас в 4 колонке, поэтому пишем:
Вуаля! Мне это почему-то кажется чудом. Можно задать ту же команду и по-другому:
Опция М преобразует первые три непробельные символа указанного столбца в заглавные буквы (Скажем, SEP означает SEPtember), а затем сравнивает их и располагает в порядке годового круга.
До сих пор мы рассматривали файлы, в которых разделителем колонок или столбцов был пробел, что и установлено по умолчанию. Чтобы задать другой разделитель, необходимо использовать опцию -t.
Опция -t
Позволяет указать иной разделитель объектов сортировки вместо пробела. Вернемся к файлу pay.txt:
В первый раз, чтобы рассортировать должников по фамилиям, мы указывали пятую букву в третьем столбце (считая разделителем столбцов пробелы). Есть другой способ решить эту задачу:
Теперь мы задали разделителем точку и указали четвертую колонку.
Давайте рассортируем по алфавиту шеллы, доступные в системе, указав разделителем слэш (-t ‘/’):
В директории /etc масса файлов, в которых встречаются различные разделители. Часто это двоеточие:
Эта команда рассортирует файл /etc/passwd в порядке возрастания идентификационных номеров пользователей. Проделайте этот пример самостоятельно, у него длинный вывод, боюсь мой редактор будет не в восторге.
Надеюсь, с разделителями все ясно, правила их задания очень напоминают команду cut.
Опция -c
Эта опция проверяет порядок сортировки, сама ничего не сортируя. Создадим файл 123.txt:
Вывод «неправильный порядок: 1» сообщает нам номер строки с первой ошибкой.
Опция -u
Скрывает одинаковые объекты. Если в процессе сортировки выявилось несколько одинаковых объектов, то будет выведен только первый из них, остальные проигнорированы:
Остался только один Иванов из трех.
Если бы мы задали команду чуть по-другому:
то все Ивановы остались бы на своих местах. Ответьте: почему? (Ответ в приложении [1]).
Опция -b
Игнорирует пробелы в начале строк, и сортирует так, словно пробелов нет. Возьмем файл run.txt
Применим команду sort без опций:
Фактически произошла сортировка по количеству пробелов, так как пробел предшествует буквам в порядке сортировки. Введем команду:
Теперь строки отсортированы в алфавитном порядке, невзирая на пробелы.
Немного усложним файл run.txt
И попробуем выстроить животных по алфавиту:
Ничего не выходит — сортируется количество пробелов. Но стоит добавить опцию -b
как все становится на свои места.
Опция -d
Признает только буквы, цифры и пробелы и сортирует как в словаре.
Опция -i
Весьма похожа на предыдущую опцию -d, но не такая «строгая». Она признает только печатные символы, игнорируя все специальные.
Опция -f
При обычной сортировке, заглавные буквы идут прежде строчных:
А с опцией -f все равны:
Опция -g
Позволяет сортировать числа, записанные в общей математической форме. Возьмем файл notation.txt:
и попробуем рассортировать его обычной опцией -n:
и потерпим неудачу. Тогда применим опцию -g:
Теперь числа выстроились по ранжиру. Нужно сказать, что применять опцию -g следует в крайних случаях, когда нельзя обойтись опцией -n. Дело в том, что опция -g медленнее, и на больших файлах это становится заметным. Кроме того, в Интернете появляются сообщения, что в некоторых версиях GNU Coreutils sort замечены сбои в работе опции -g на больших файлах (Больше 25Мб).
Опция -T
Позволяет указать директорию для временных файлов, иную, чем положено по умолчанию (/tmp или $TMPDIR).
При сортировке больших файлов программа создает временные файлы, и можно указать, где их разместить. Примера по очевидным причинам дать не могу, просто помните про эту опцию, если случится сортировать многомегабайтные файлы.
Опция -S
Также пригодится для сортировки больших файлов. Она создаст в основной памяти буфер указанного размера.
Кстати, коли речь зашла о работе с большими файлами, то полезно бывает переместить эти процессы на задний план, чтобы можно было работать, не дожидаясь завершения процесса:
Опция -s
Эта опция отменяет пересортировку. Что это такое? — Допустим, мы сортировали некий файл по определенным, нужным нам объектам сортировки (полям, столбцам, колонкам, символам внутри колонок и так далее), применяли вторичную сортировку (как в примере sort -k 2,2 -k 4n ivanov.txt), но все объекты, выбранные нами, оказались одинаковыми (равными). В этом случае, по умолчанию, команда sort проводит пересортировку, считая объектом сортировки всю строку в целом (как в случае сортировки без опций). Если мы хотим сохранить первоначальный порядок строк файла, и не проводить финальную пересортировку, то мы применяем опцию -s.
Опция -z
Эта опция рассматривает исходный файл как набор строк, разделенных не знаком переноса строки, а нулевым байтом. Для чего это может понадобиться, я не знаю. Единственное, что мне удалось найти, это туманные указания, что эта опция может оказаться полезной в составе программных каналов (pipes) с такими командами как ‘perl -0’, ‘find -print0’, и ‘xargs -0’ для сортировки произвольных файловых имен. Я пока не разбирался с перечисленными программами и не могу ничего сказать по этому поводу. Я также пробовал подставлять опцию -z в многочисленные примеры из этой статьи, но никакой сортировки после добавления этой опции не происходило.
Опция -o
Видимо пережиток прошлого, когда не было перенаправления вывода. С помощью этой опции можно задать файл, куда будет помещен вывод команды вместо стандартного вывода на экран дисплея.
Послесловие
Оставшиеся опции варьируют в различных мануалах и руководствах, они достаточно понятны интуитивно, и не требуют специального рассмотрения. Если какой-то из опций нет в вашем мане, не беда, скорее всего опция поддерживается вашей версией программы. Попробуйте, чем вы рискуете? Но попадаются опции, не поддерживаемые GNU Coreutils sort, как например опции -R и —random-source=file, позволяющие «рассортировать» строки и прочие объекты в случайном порядке.
Другое дело сочетания различных опций друг с другом. Если вы соорудили заковыристое заклинание из множества разных опций, а оно не работает, попробуйте убрать ту или другую опцию, может быть поможет. А лучше идти от простого к сложному, постепенно усложняя команду, пока не достигнете нужного результата. Хорошо помогает набрать вашу команду в поисковой строке Гугла, вдруг повезет. Кстати, только этим способом я смог разобраться с некоторыми опциями, о которых пишу в этой статье.
Команда sort и кириллица
Команда sort работает с нашими буквами неадекватно.
Резюме команды sort
Чрезвычайно полезная и «мощная» команда. С ее помощью не проблема выявить в огромной директории файлы, которые вы вчера потеряли (по дате модификации), или собрать «в кучу» все линки, чтобы их проверить, и так далее. А в качестве фильтра в программных каналах (pipes), эта команда просто незаменима и позволяет творить чудеса.
Приложение
[1] Ответ на задачу про Ивановых.
В первом случае мы задали сортировку строго по второй колонке (-uk 2,2), поэтому программа видела всех Ивановых одинаковыми, и включила опцию -u.
Во втором случае мы задали сортировку, не указав конец объекта сортировки (-uk2), и программа сортировала Ивановых по следующим колонкам (могла бы до конца строки). В этом случае одинаковых объектов выявлено не было, и опция -u не включилась.
Источник



