- tail -f и grep -m в скрипте
- Команда tail Linux
- Команда tail в Linux
- Использование tail
- Выводы
- grep and tail -f?
- 8 Answers 8
- How to ‘grep’ a continuous stream?
- 12 Answers 12
- Команда Tail в Linux
- Linux Tail Command
- В этом уроке мы покажем вам, как использовать хвостовую команду Linux, на практических примерах и подробных объяснениях наиболее распространенных опций хвоста.
- Синтаксис хвостовой команды
- Как использовать команду Tail
- Как отобразить определенное количество строк
- Как отобразить определенное количество байтов
- Как посмотреть файл на предмет изменений
- Как отобразить несколько файлов
- Как использовать хвост с другими командами
- Вывод
tail -f и grep -m в скрипте
Есть приложение, которое в свой лог-файл постоянно пишет очень много инфы о своей работе. Также у этого приложения есть конфиг, который этот приклад постоянно проверяет — если конфиг изменился, то он перечитывается приложением, и инфа о статусе этой операции (ОК\неОК) тоже заносится в этот лог-файл.
Сейчас я руками изменяю конфиг и параллельно смотрю лог, вылавливая сообщение об обработке конфига. Теперь вопрос — как мне запихнуть это в скрипт? tail -f logfile | grep -m 1 status не помогает — даже после того как греп отловил нужную строку он не завершается. Скопировать предварительно кусок файла тоже не очень хороши вариант — могу просто не угадать нужное кол-во строк — в логи валится постоянно очень много инфы. С другой стороны копирование тоже приемлемый вариант, потому что я хочу еще в логах отловить строчки с новыми параметрами в конфиге, а через tail -f | grep -m мне это сделать не удастся.
В общем что посоветуете в этой ситуации? Заранее спасибо!!


Могу предложить посмотреть в сторону inotify : грепать по файлу после записи.
Или простой цикл наподобии:

как вариант в цикле проверять каждые, например, 0,5 секунд на изменение и реагировать вслучае изменения
Источник
Команда tail Linux
Все знают о команде cat, которая используется для просмотра содержимого файлов. Но в некоторых случаях вам не нужно смотреть весь файл, иногда достаточно посмотреть только то, что находится в конце файла. Например, когда вы хотите посмотреть содержимое лог файла, то вам не нужно то, с чего он начинается, вам будет достаточно последних сообщений об ошибках.
Для этого можно использовать команду tail, она позволяет выводить заданное количество строк с конца файла, а также выводить новые строки в интерактивном режиме. В этой статье будет рассмотрена команда tail Linux.
Команда tail в Linux
Перед тем как мы будем рассматривать примеры tail linux, давайте разберем ее синтаксис и опции. А синтаксис очень прост:
$ tail опции файл
По умолчанию утилита выводит десять последних строк из файла, но ее поведение можно настроить с помощью опций:
- -c — выводить указанное количество байт с конца файла;
- -f — обновлять информацию по мере появления новых строк в файле;
- -n — выводить указанное количество строк из конца файла;
- —pid — используется с опцией -f, позволяет завершить работу утилиты, когда завершится указанный процесс;
- -q — не выводить имена файлов;
- —retry — повторять попытки открыть файл, если он недоступен;
- -v — выводить подробную информацию о файле;
В качестве значения параметра -c можно использовать число с приставкой b, kB, K, MB, M, GB, G T, P, E, Z, Y. Еще есть одно замечание по поводу имен файлов. По умолчанию утилита не отслеживает изменение имен, но вы можете указать что нужно отслеживать файл по дескриптору, подробнее в примерах.
Использование tail
Теперь, когда вы знаете основные опции, рассмотрим приемы работы с утилитой. Самый простой пример — выводим последние десять строк файла:
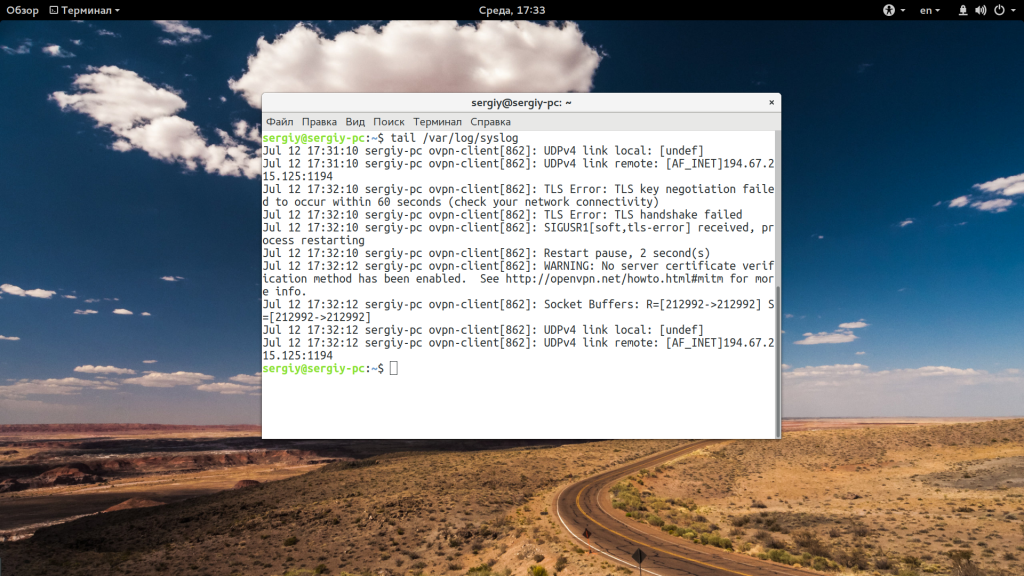
Если вам недостаточно 10 строк и нужно намного больше, то вы можете увеличить этот параметр с помощью опции -n:
tail -n 100 /var/log/syslog

Когда вы хотите отслеживать появление новых строк в файле, добавьте опцию -f:
tail -f /var/log/syslog

Вы можете открыть несколько файлов одновременно, просто перечислив их в параметрах:
tail /var/log/syslog /var/log/Xorg.0.log

С помощью опции -s вы можете задать частоту обновления файла. По умолчанию данные обновляются раз в секунду, но вы можете настроить, например, обновление раз в пять секунд:
tail -f -s 5 /var/log/syslog

При открытии нескольких файлов будет выводиться имя файла перед участком кода. Если вы хотите убрать этот заголовок, добавьте опцию -q:
tail -q var/log/syslog /var/log/Xorg.0.log

Если вас интересует не число строк, а именно число байт, то вы можете их указать с помощью опции -c:
tail -c 500 /var/log/syslog

Для удобства, вы можете выбирать не все строки, а отфильтровать интересующие вас:
tail -f /var/log/syslog | grep err
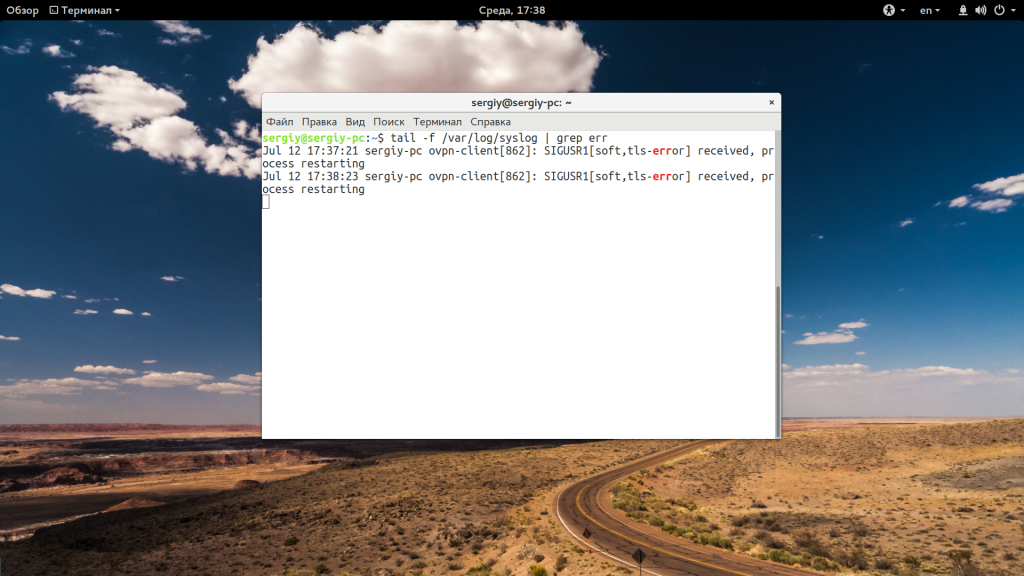
Особенно, это полезно при анализе логов веб сервера или поиске ошибок в реальном времени. Если файл не открывается, вы можете использовать опцию retry чтобы повторять попытки:
tail -f —retry /var/log/syslog | grep err
Как я говорил в начале статьи, по умолчанию опция -f или —follow отслеживает файл по его имени, но вы можете включить режим отслеживания по дескриптору файла, тогда даже если имя измениться, вы будете получать всю информацию:
tail —follow=descriptor /var/log/syslog | grep err

Выводы
В этой статье была рассмотрена команда tail linux. С помощью нее очень удобно анализировать логи различных служб, а также искать в них ошибки. Надеюсь, эта информация была полезной для вас.
Источник
grep and tail -f?
Is it possible to do a tail -f (or similar) on a file, and grep it at the same time? I wouldn’t mind other commands just looking for that kind of behavior.

8 Answers 8
Using GNU tail and GNU grep , I am able to grep a tail -f using the straight-forward syntax:

Add —line-buffered to grep , and that may reduce the delay for you. Very useful in some cases.
It will work fine; more generally, grep will wait when a program isn’t outputting, and keep reading as the output comes in, so if you do:
Nothing will happen for 5 seconds, then grep will output the matched «test», and then five seconds later it will exit when the piped process does
You can just pipe the output of grep into tail -f . There are also programs that combine tail -f functionality with filtering and coloring, in particular multitail (examples).
I see all these people saying to use tail -f , but I do not like the limitations of that! My favorite method of searching a file while also watching for new lines (e.g., I commonly work with log files to which are appended the redirected output of processes executed periodically via cron jobs) is:
This assumes GNU tail and grep. Supporting details from the tail manpage (GNU coreutils, mine is v8.22) [https://www.gnu.org/software/coreutils/manual/coreutils.html] :
So, the tail portion of my command equates to tail —follow —retry —lines=+0 , where the final argument directs it to start at the beginning, skipping zero lines.
Источник
How to ‘grep’ a continuous stream?
Is that possible to use grep on a continuous stream?
What I mean is sort of a tail -f command, but with grep on the output in order to keep only the lines that interest me.
I’ve tried tail -f | grep pattern but it seems that grep can only be executed once tail finishes, that is to say never.
12 Answers 12
Turn on grep ‘s line buffering mode when using BSD grep (FreeBSD, Mac OS X etc.)
It looks like a while ago —line-buffered didn’t matter for GNU grep (used on pretty much any Linux) as it flushed by default (YMMV for other Unix-likes such as SmartOS, AIX or QNX). However, as of November 2020, —line-buffered is needed (at least with GNU grep 3.5 in openSUSE, but it seems generally needed based on comments below).
I use the tail -f | grep
It will wait till grep flushes, not till it finishes (I’m using Ubuntu).
I think that your problem is that grep uses some output buffering. Try
it will set output buffering mode of grep to unbuffered.
If you want to find matches in the entire file (not just the tail), and you want it to sit and wait for any new matches, this works nicely:
The -c +0 flag says that the output should start 0 bytes ( -c ) from the beginning ( + ) of the file.
In most cases, you can tail -f /var/log/some.log |grep foo and it will work just fine.
If you need to use multiple greps on a running log file and you find that you get no output, you may need to stick the —line-buffered switch into your middle grep(s), like so:
you may consider this answer as enhancement .. usually I am using
-F is better in case of file rotate (-f will not work properly if file rotated)
-A and -B is useful to get lines just before and after the pattern occurrence .. these blocks will appeared between dashed line separators
But For me I prefer doing the following
this is very useful if you want to search inside streamed logs. I mean go back and forward and look deeply
Источник
Команда Tail в Linux
Linux Tail Command
В этом уроке мы покажем вам, как использовать хвостовую команду Linux, на практических примерах и подробных объяснениях наиболее распространенных опций хвоста.

Команда tail отображает последнюю часть (по умолчанию 10 строк) одного или нескольких файлов или переданных данных. Он также может быть использован для мониторинга изменений файла в режиме реального времени.
Одним из наиболее распространенных применений команды tail является просмотр и анализ журналов и других файлов, которые со временем меняются, обычно в сочетании с другими инструментами, такими как grep .
Синтаксис хвостовой команды
Прежде чем перейти к использованию команды tail, давайте начнем с рассмотрения основного синтаксиса.
Выражения команды tail принимают следующую форму:
- OPTION — хвостовые варианты . Мы рассмотрим наиболее распространенные варианты в следующих разделах.
- FILE — Ноль или более имен входных файлов. Если FILE не указан или если FILE установлен — , tail будет читать стандартный ввод.
Как использовать команду Tail
В простейшем виде, когда используется без какой-либо опции, команда tail отображает последние 10 строк.
Как отобразить определенное количество строк
Используйте опцию -n ( —lines ), чтобы указать количество отображаемых строк:
Вы также можете опустить букву n и использовать только дефис ( — ) и число (без пробелов между ними).
Для отображения последних 50 строк имени файла filename.txt вы должны использовать:
В следующем примере будет показан тот же результат, что и в приведенных выше командах:
Как отобразить определенное количество байтов
Для отображения определенного количества байтов используйте опцию -c ( —bytes ).
Например, для отображения последних 500 байтов данных из названного файла filename.txt вы должны использовать:
Вы также можете использовать суффикс множителя после числа, чтобы указать количество отображаемых байтов. b умножает его на 512, kB умножает на 1000, K умножает на 1024, MB умножает на 1000000, M умножает на 1048576 и т. д.
Следующая команда отобразит последние два килобайта (2048) файла filename.txt :
Как посмотреть файл на предмет изменений
Чтобы отслеживать файл на наличие изменений, используйте параметр -f ( —follow ):
Эта опция особенно полезна для мониторинга файлов журнала. Например, чтобы отобразить последние 10 строк /var/log/nginx/error.log файла и отслеживать файл на наличие обновлений, вы будете использовать:
Чтобы прервать команду tail во время просмотра файла, нажмите Ctrl+C .
Чтобы продолжить мониторинг файла при его воссоздании, используйте -F опцию.
Эта опция полезна в ситуациях, когда команда tail следит за вращающимся файлом журнала. При использовании с -F опцией команда tail снова откроет файл, как только он снова станет доступным.
Как отобразить несколько файлов
Если несколько файлов предоставлены в качестве входных данных для команды tail, она будет отображать последние десять строк из каждого файла.
Вы можете использовать те же параметры, что и при отображении одного файла.
Этот пример показывает последние 20 строк файлов filename1.txt и filename2.txt :
Как использовать хвост с другими командами
Команда tail может использоваться в сочетании с другими командами, перенаправляя стандартный вывод из / в другие утилиты, используя каналы.
Например, чтобы отслеживать файл журнала доступа apache и отображать только те строки, которые содержат IP-адрес, который 192.168.42.12 вы используете:
Следующая ps команда отобразит десятку запущенных процессов, отсортированных по загрузке процессора:
Вывод
К настоящему времени вы должны хорошо понимать, как использовать хвостовую команду Linux. Он дополняет команду head, которая печатает первые строки файла на терминал.
Источник



