- Как вывести содержимое файла Linux? Открываем текстовый файл в Linux
- Просмотр текстового файла в Linux полностью
- Как просмотреть файл в Linux с прокруткой
- Просматриваем начало или конец файла в Linux
- Просматриваем содержимое файла по шаблону в Linux
- Просматриваем Linux-файл в сжатом виде
- Linux: перенаправление
- Три стандартных потока ввода/вывода
- Перенаправление стандартного потока вывода
- Перенаправление стандартного потока ввода
- Перенаправление стандартного потока ошибок
- Итоги
- Вывод в файл Bash в Linux
- Стандартные дескрипторы вывода
- Вывод в файл Bash
- 1. Перенаправление стандартного потока вывода
- 2. Перенаправление потока ошибок
- Временные перенаправления в скриптах
- Постоянные перенаправления в скриптах
- Выводы
Как вывести содержимое файла Linux? Открываем текстовый файл в Linux

Если вы работаете с операционной системой Linux, вы должны уметь быстро и правильно просматривать содержимое Linux-файлов, используя терминал. В этой статье мы изучим команды, посредством которых можно открывать текстовые файлы Linux. И поговорим о том, как следует ими пользоваться.
Просмотр текстового файла в Linux полностью
Чтобы вывести содержимое всего текстового файла, в Linux используют команду cat. Она отлично походит для вывода небольших текстовых файлов, к примеру, конфигурационных файлов. Синтаксис прост:
Представьте, что надо посмотреть содержимое файла с названием myfile.txt:
Также можно вместо имени прописать адрес (путь) к файлу:
Если нужно посмотреть несколько файлов сразу, это тоже не вызовет проблем:

Кроме того, при просмотре текстового файла в Linux мы можем отобразить номера строк. Для этого потребуется всего лишь использовать опцию -n:

Команда nl функционирует аналогично команде cat с опцией -n, выводя номера строк в столбце слева.
При необходимости вы можете сделать так, чтобы при выводе текстового файла в конце каждой строки отображался символ $:
Вывод будет следующим:
Кроме cat, для вывода содержимого текстового файла в Linux используется команда tac. Её разница заключается в том, что она выводит содержимое файла в обратном порядке.

Как просмотреть файл в Linux с прокруткой
Бывает, что текстовый файл большой, поэтому его содержимое не помещается в один экран. Использовать в таком случае cat неудобно, зато есть less. Синтаксис у неё такой же:
Команда less обеспечит постраничный просмотр, что очень удобно. При этом:
1) less позволяет просматривать текст по определённому числу строк, для чего достаточно указать — (тире или минус) и количество строк:
2) можно начать просмотр с конкретной строки в файле, указав + (плюс) и номер строки, с которой хотим начать чтение:
Открыв текст, мы можем управлять его просмотром:

Просматриваем начало или конец файла в Linux
Порой, нам не нужно выводить содержимое всего файла и мы хотим, к примеру, посмотреть лишь несколько строчек лога. Такое часто бывает, если мы подозреваем, что в начале или в конце конфигурационного файла есть ошибки. Для решения данного вопроса у нас существуют команды head и tail (как вы уже догадались, это голова и хвост).
Команда head по умолчанию показывает лишь 10 первых строчек в текстовом файле в Linux:
Вот, что мы увидим:
Кстати, тут мы тоже можем открыть сразу несколько текстовых файлов в Linux одновременно. Вот просмотр сразу двух файлов:
Если же вас не интересуют все 10 строчек, то, как и в случае с cat, можно использовать опцию –n, цифрой указывая число строк к выводу:
В итоге мы вывели только пять строк:
По правде говоря, букву n можно и не использовать, достаточно просто передать цифру:
Кстати, выводить содержимое текстового файла в Linux можно не построчно, а посимвольно. Давайте зададим число символов, которое нужно вывести (используем опцию -с):
Итак, выводим 45 символов:
Не верите, что их действительно 45? Проверить можно командой wc:
С «головой» разобрались, давайте поговорим про «хвост». Очевидно, что команда tail работает наоборот, выводя десять последних строк текстового Linux-файла:
Количество строк при выводе тоже можно менять. Однако в tail есть такая полезная опция, как -f. С её помощью содержимое текстового файла будет постоянно обновляться, в результате чего вы станете видеть изменения сразу (постоянно открывать и закрывать файл не придётся). Это весьма удобно, если вы хотите просматривать логи Linux в реальном времени:
Просматриваем содержимое файла по шаблону в Linux
На практике зачастую нам необходим не весь текстовый файл, а лишь несколько строк из него. Используя grep, мы можем вывести Linux-файл, предварительно отсеяв лишнее:
Команду можно применять и совместно с cat:
Давайте выведем из лога лишь предупреждения:
Есть и ряд полезных опций: -A, -B, -C. Допустим, нам надо выполнить вывод двух строк после вхождения enp2s0:
А теперь, то же самое, но до вхождения loop:
Можно по две строки как до, так и после loop:
Просматриваем Linux-файл в сжатом виде
Порой, в системе встречаются текстовые файлы в сжатом виде и формате gz. Это могут быть конфигурационные файлы ядра либо логи программ. Открыть такие файлы можно тоже через терминал, не прибегая к распаковке. Для этого существует множество аналогов вышеназванных утилит с той лишь разницей, что они имеют приставку z: zgerp, zegrep, zcat, zless.
Давайте откроем сжатый файл в Linux для просмотра:
Или выполним просмотр сжатого файла с прокруткой:
Вот, пожалуй, и всё. Теперь вы точно в курсе, как правильно открывать и просматривать текстовые файлы в терминале Linux.
Источник
Linux: перенаправление
Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок.

Для оболочки, интерпретатора команд Linux, эти дополнительные символы — не пустая трата места на экране. Они — мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки — это перенаправление стандартных потоков ввода/вывода.
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.
Первый — это стандартный поток ввода (standard input). В системе это — поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности — инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
Второй поток — это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
И, наконец, третий поток — это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
Перенаправление стандартного потока вывода
Предположим, вы хотите создать файл, в который будут записаны текущие дата и время. Дело упрощает то, что имеется команда, удачно названная date , которая возвращает то, что нам нужно. Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел.
При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды. Назовём его date.txt . Расширение файла после точки обычно особой роли не играет, но расширения помогают поддерживать порядок. Итак, вот наша команда:
Нельзя сказать, что сама по себе эта команда невероятно полезна, однако, основываясь на ней, мы уже можем сделать что-то более интересное. Скажем, вы хотите узнать, как меняются маршруты вашего трафика, идущего через интернет к некоей конечной точке, ежедневно записывая соответствующие данные. В решении этой задачи поможет команда traceroute , которая сообщает подробности о маршруте трафика между нашим компьютером и конечной точкой, задаваемой при вызове команды в виде URL. Данные включают в себя сведения обо всех маршрутизаторах, через которые проходит трафик.
Так как файл с датой у нас уже есть, будет вполне оправдано просто присоединить к этому файлу данные, полученные от traceroute . Для того, чтобы это сделать, надо использовать два символа > , поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так:
Теперь нам осталось лишь изменить имя файла на что-нибудь более осмысленное, используя команду mv , которой, в качестве первого аргумента, передаётся исходное имя файла, а в качестве второго — новое:
Перенаправление стандартного потока ввода
Используя знак вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.
Предположим, имеется два файла: list1.txt и list2.txt , каждый из которых содержит неотсортированный список строк. В каждом из списков имеются уникальные для него элементы, но некоторые из элементов список совпадают. Мы можем найти строки, которые имеются и в первом, и во втором списках, применив команду comm , но прежде чем её использовать, списки надо отсортировать.
Существует команда sort , которая возвращает отсортированный список в терминал, не сохраняя отсортированные данные в файл, из которого они были взяты. Можно отправить отсортированную версию каждого списка в новый файл, используя команду > , а затем воспользоваться командой comm . Однако, такой подход потребует как минимум двух команд, хотя то же самое можно сделать в одной строке, не создавая при этом ненужных файлов.
Итак, мы можем воспользоваться командой для перенаправления отсортированной версии каждого файла команде comm . Вот что у нас получилось:
Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm , которая затем выводит результат сравнения списков.
Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.
Например, что если надо провести поиск во всей системе сведений о беспроводных интерфейсах, которые доступны пользователям, у которых нет прав суперпользователя? Для того, чтобы это сделать, можно воспользоваться мощной командой find .
Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 — это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
Как быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
Обратите внимание на то, что первая угловая скобка идёт с номером — 2> , а вторая без него. Это так из-за того, что стандартный вывод имеет дескриптор 1, и команда > подразумевает перенаправление стандартного вывода, если номер дескриптора не указан.
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &> :
Итоги
Тут мы разобрали лишь основы механизма перенаправления потоков в интерпретаторе командной строки Linux, однако даже то немногое, что вы сегодня узнали, даёт вам практически неограниченные возможности. И, кстати, как и всё остальное, что касается работы в терминале, освоение перенаправления потоков требует практики. Поэтому рекомендуем вам приступить к собственным экспериментам с > и .
Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале?
Источник
Вывод в файл Bash в Linux
Часто возникает необходимость, чтобы скрипт командного интерпретатора Bash выводил результат своей работы. По умолчанию он отображает стандартный поток данных — окно терминала. Это удобно для обработки результатов небольшого объёма или, чтобы сразу увидеть необходимые данные.
В интерпретаторе можно делать вывод в файл Bash. Применяется это для отложенного анализа или сохранения массивного результата работы сценария. Чтобы сделать это, используется перенаправление потока вывода с помощью дескрипторов.
Стандартные дескрипторы вывода
В системе GNU/Linux каждый объект является файлом. Это правило работает также для процессов ввода/вывода. Каждый файловый объект в системе обозначается дескриптором файла — неотрицательным числом, однозначно определяющим открытые в сеансе файлы. Один процесс может открыть до девяти дескрипторов.
В командном интерпретаторе Bash первые три дескриптора зарезервированы для специального назначения:
| Дескриптор | Сокращение | Название |
|---|---|---|
| 0 | STDIN | Стандартный ввод |
| 1 | STDOUT | Стандартный вывод |
| 2 | STDERR | Стандартный вывод ошибок |
Их предназначение — обработка ввода/вывода в сценариях. По умолчанию стандартным потоком ввода является клавиатура, а вывода — терминал. Рассмотрим подробно последний.
Вывод в файл Bash
1. Перенаправление стандартного потока вывода
Для того, чтобы перенаправить поток вывода с терминала в файл, используется знак «больше» (>).
#!/bin/bash
echo «Строка 1»
echo «Промежуточная строка» > file
echo «Строка 2» > file
Как результат, «Строка 1» выводится в терминале, а в файл file записывается только «Строка 2»:

Связано это с тем, что > перезаписывает файл новыми данными. Для того, чтобы дописать информацию в конец файла, используется два знака «больше» (>>).
#!/bin/bash
echo «Строка 1»
echo «Промежуточная строка» > file
echo «Строка 2» >> file

Здесь «Промежуточная строка» перезаписала предыдущее содержание file, а «Строка 2» дописалась в его конец.
Если во время использования перенаправления вывода интерпретатор обнаружит ошибку, то он не запишет сообщение о ней в файл.
#!/bin/bash
ls badfile > file2
echo «Строка 2» >> file2
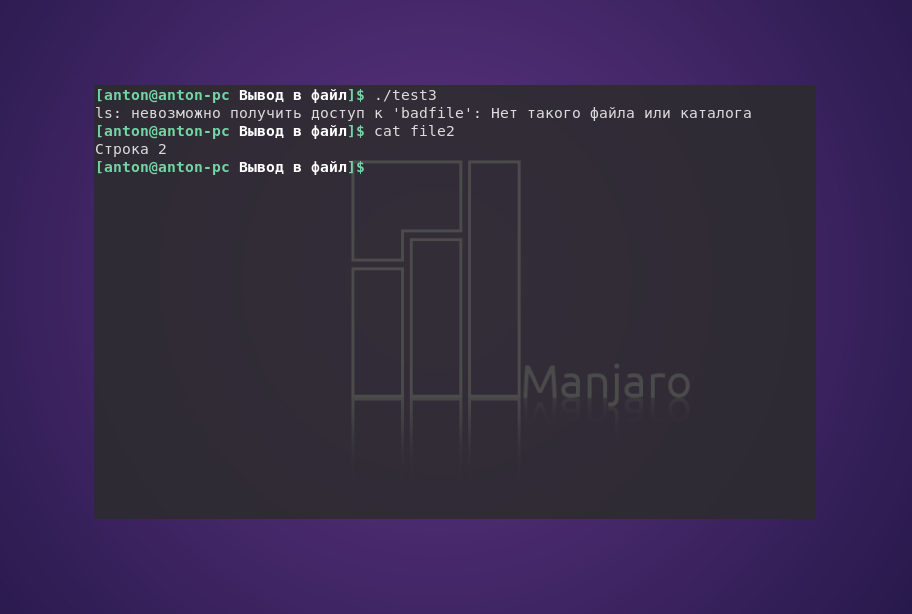
В данном случае ошибка была в том, что команда ls не смогла найти файл badfile, о чём Bash и сообщил. Но вывелось сообщение в терминал, а не записалось в файл. Всё потому, что использование перенаправления потоков указывает интерпретатору отделять мух от котлет ошибки от основной информации.
Это особенно полезно при выполнении сценариев в фоновом режиме, где приходится предусматривать вывод сообщений в журнал. Но так как ошибки в него писаться не будут, нужно отдельно перенаправлять поток ошибок для того, чтобы выполнить их вывод в файл Linux.
2. Перенаправление потока ошибок
В командном интерпретаторе для обработки сообщений об ошибках предназначен дескриптор STDERR, который работает с ошибками, сформированными как от работы интерпретатора, так и самим скриптом.
По умолчанию STDERR указывает в то же место, что и STDOUT, хотя для них и предназначены разные дескрипторы. Но, как было показано в примере, использование перенаправления заставляет Bash разделить эти потоки.
Чтобы выполнить перенаправление вывода в файл Linux для ошибок, следует перед знаком«больше» указать дескриптор 2.
#!/bin/bash
ls badfile 2> errors
echo «Строка 1» > file3
echo «Строка 2» >> file3
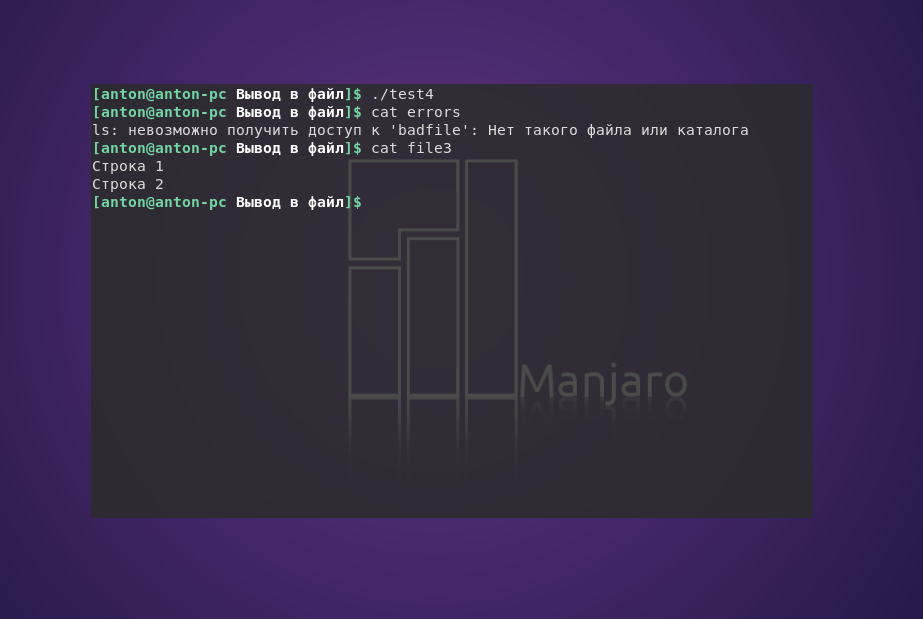
В результате работы скрипта создан файл errors, в который записана ошибка выполнения команды ls, а в file3 записаны предназначенные строки. Таким образом, выполнение сценария не сопровождается выводом информации в терминал.
Пример того, как одна команда возвращает и положительный результат, и ошибку:
ls -lh test badtest 2> errors
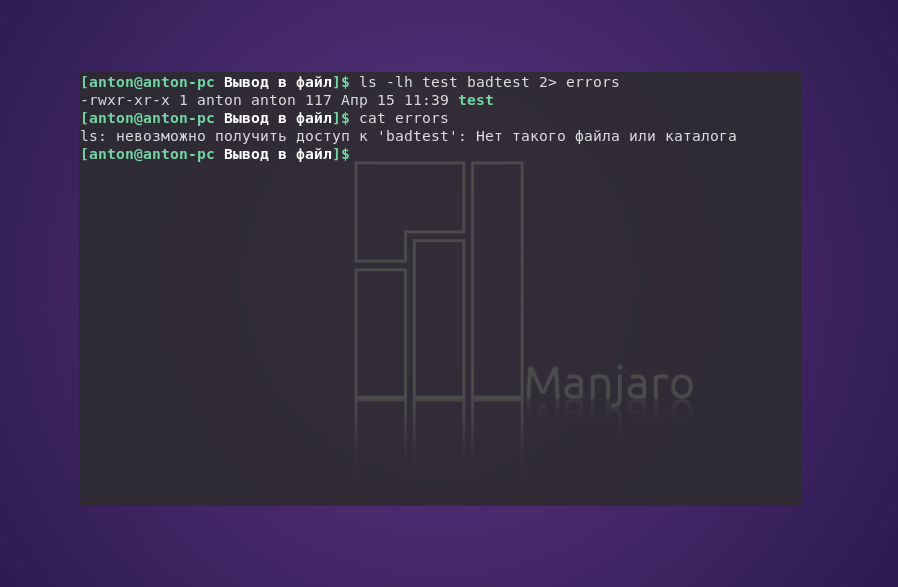
Команда ls попыталась показать наличие файлов test и badtest. Первый присутствовал в текущем каталоге, а второй — нет. Но сообщение об ошибке было записано в отдельный файл.
Если возникает необходимость выполнить вывод команды в файл Linux, включая её стандартный поток вывода и ошибки, стоит использовать два символа перенаправления, перед которыми стоит указывать необходимый дескриптор.
ls -lh test test2 badtest 2> errors 1> output
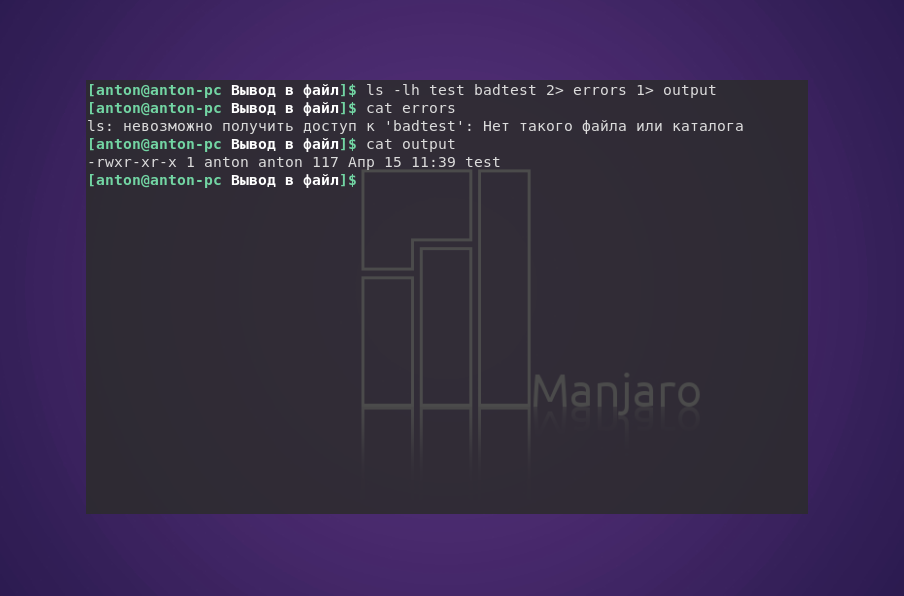
Результат успешного выполнения записан в файл output, а сообщение об ошибке — в errors.
По желанию можно выводить и ошибки, и обычные данные в один файл, используя &>.
ls -lh test badtest &> output
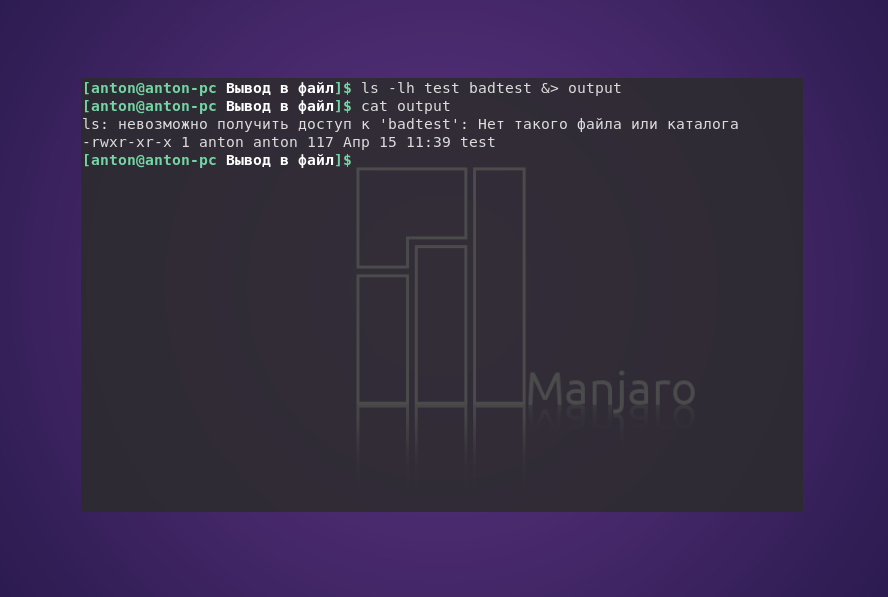
Обратите внимание, что Bash присваивает сообщениям об ошибке более высокий приоритет по сравнению с данными, поэтому в случае общего перенаправления ошибки всегда будут располагаться в начале.
Временные перенаправления в скриптах
Если есть необходимость в преднамеренном формировании ошибок в сценарии, можно каждую отдельную строку вывода перенаправлять в STDERR. Для этого достаточно воспользоваться символом перенаправления вывода, после которого нужно использовать & и номер дескриптора, чтобы перенаправить вывод в STDERR.
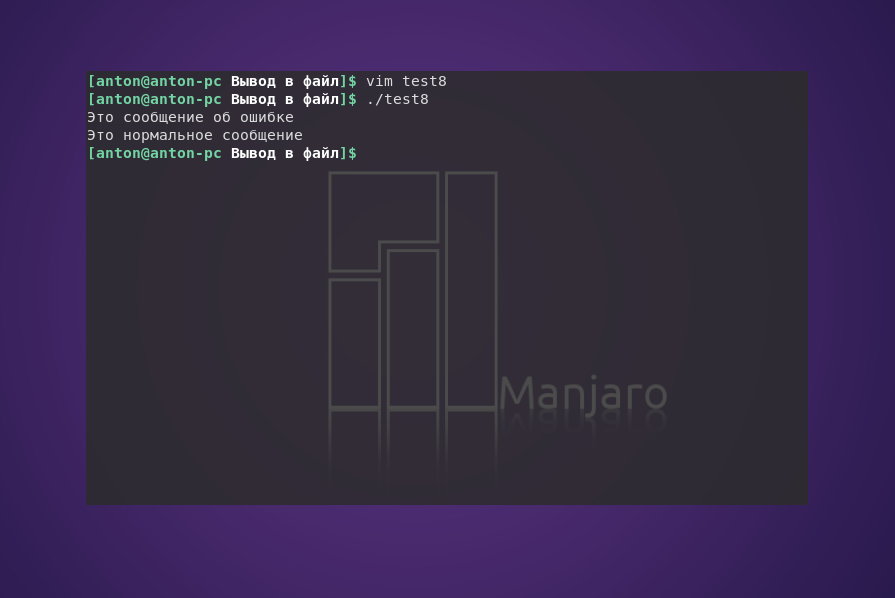
#!/bin/bash
echo «Это сообщение об ошибке» >&2
echo «Это нормальное сообщение»
При выполнении программы обычно нельзя будет обнаружить отличия:
Вспомним, что GNU/Linux по умолчанию направляет вывод STDERR в STDOUT. Но если при выполнении скрипта будет перенаправлен поток ошибок, то Bash, как и полагается, разделит вывод.

Этот метод хорошо подходит для создания собственных сообщений об ошибках в сценариях.
Постоянные перенаправления в скриптах
Если в сценарии необходимо перенаправить вывод в файл Linux для большого объёма данных, то указание способа вывода в каждой инструкции echo будет неудобным и трудоёмким занятием. Вместо этого можно указать, что в ходе выполнения данного скрипта должно осуществляться перенаправление конкретного дескриптора с помощью команды exec:
#!/bin/bash
exec 1> testout
echo «Это тест перенаправления всего вывода»
echo «из скрипта в другой файл»
echo «без использования временного перенаправления»
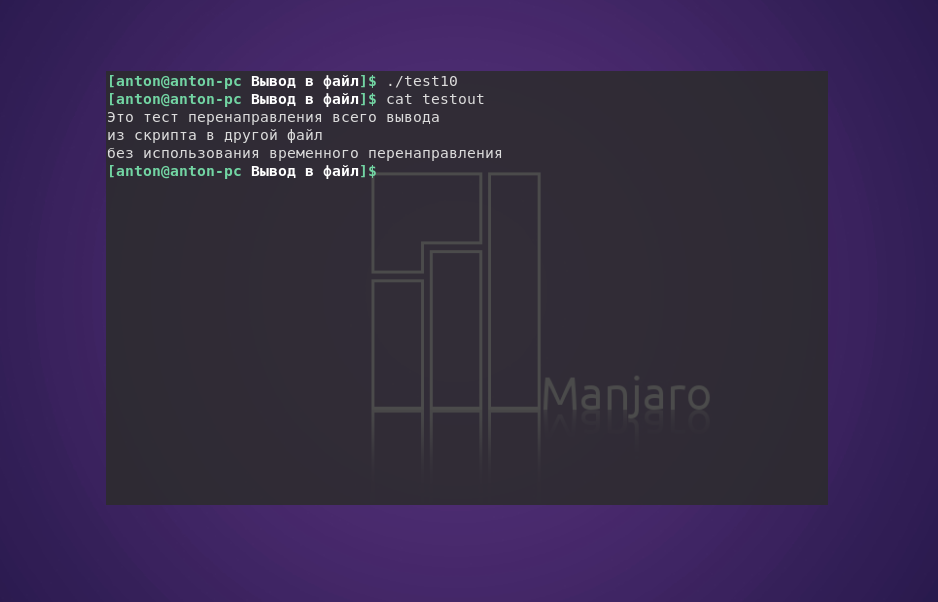
Вызов команды exec запускает новый командный интерпретатор и перенаправляет стандартный вывод в файл testout.
Также существует возможность перенаправлять вывод (в том числе и ошибок) в произвольном участке сценария:
#!/bin/bash
exec 2> testerror
echo «Это начально скрипта»
echo «И это первые две строки»
exec 1> testout
echo «Вывод сценария перенаправлен»
echo «из с терминала в другой файл»
echo «но эта строка записана в файл ошибок» >&2
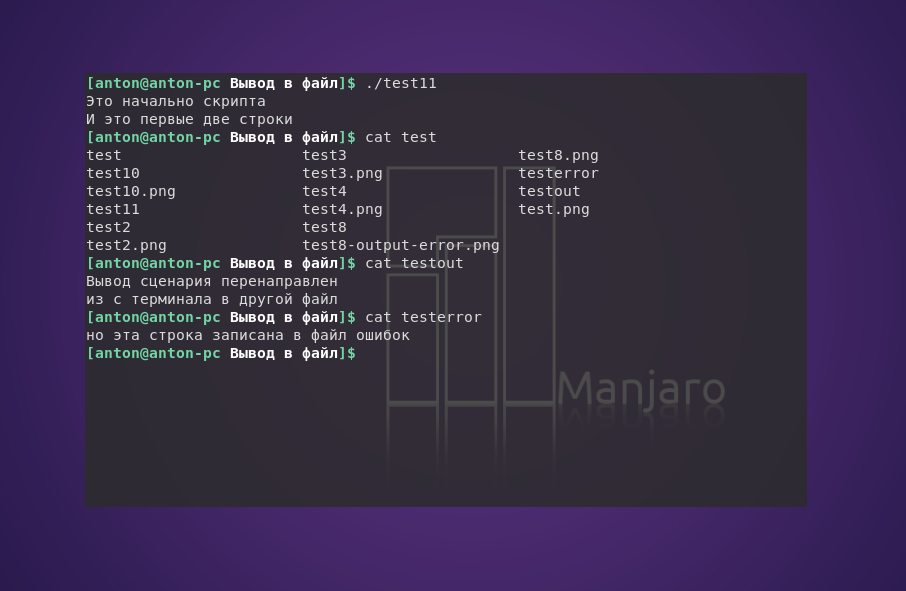
Такой метод часто применяется при необходимости перенаправить лишь часть вывода скрипта в другое место, например в журнал ошибок.
Выводы
Перенаправление в скриптах Bash, чтобы выполнить вывод в файл Bash, является хорошим средством ведения различных журналов, особенно в фоновом режиме.
Использование временного и постоянного перенаправлений в сценариях позволяет создавать собственные сообщения об ошибках для записи в отличное от STDOUT место.
Источник



