- 4 commands to check thread count per process (threads vs processes) in Linux
- Threads vs Processes
- Show threads per process
- 1. Using PID task
- 2. Using ps command
- 3. Using pstree command
- 4. Using top command
- Check thread count per process
- 1. Using PID status
- 2. Using ps command
- Check number of threads allowed in Linux system?
- What is the maximum processes count allowed in Linux?
- Related Posts
- What are Linux Processes, Threads, Light Weight Processes, and Process State
- Linux Processes
- Linux Threads vs Light Weight Processes
- Linux Process States
- Linux Kernel Process Management
- This chapter is from the book
- This chapter is from the book
- This chapter is from the book
- Process Descriptor and the Task Structure
- Allocating the Process Descriptor
- Storing the Process Descriptor
- Process State
- Manipulating the Current Process State
- Process Context
- The Process Family Tree
4 commands to check thread count per process (threads vs processes) in Linux
Table of Contents
In Linux, some processes are divided into pieces called threads. In one liner, threads are essentially just processes with a shared address space on Linux. In this article we will get some brief overview on threads and processes, also some examples to show threads per process, check thread count per process, check number of threads allowed, count threads and some more related topics.
Threads vs Processes
- A thread is very similar to a process, it has an identifier (TID, or thread ID), and the kernel schedules and runs threads just like processes.
- However, unlike separate processes, which usually do not share system resources such as memory and I/O connections with other processes, all threads inside a single process share their system resources and some memory.
- A process with one thread is single-threaded , and a process with more than one thread is multithreaded .
- All processes start out single-threaded . This starting thread is usually called the main thread. The main thread may then start new threads in order for the process to become multithreaded, similar to the way a process can call fork() to start a new process.
- The primary advantage of a multithreaded process is that when the process has a lot to do, threads can run simultaneously on multiple processors, potentially speeding up computation.
- Although you can also achieve simultaneous computation with multiple processes, threads start faster than processes, and it is often easier and/or more efficient for threads to intercommunicate using their shared memory than it is for processes to communicate over a channel such as a network connection or a pipe.
Show threads per process
1. Using PID task
You can count threads with the list of available sub directories inside /proc/
/task/ . The count of total available sub-directories inside this part is directly proportional to the thread count per process for the provided PID.
For example to check java thread count, I have a Java process for which you can see I have multiple sub-directories so it means this is a multi threaded process. using ls command under this path you can show threads per process for java
But then again I have another process for which as you can see I have single sub-directory hence we know this is a single thread process
2. Using ps command
You can also use » ps » command to show threads per process. With » ps » we can list LWP (Light Weight process) which depicts Thread ID of the respective process and NWLP (Number of Threads).
To show threads per process using ps command you can use below argument
3. Using pstree command
You can also use pstree to show threads per process. Here as you see java thread count and check number of threads for java process
4. Using top command
In top , by default we will not be able to see thread count per process. But when running top , it is possible to change which fields to display and add this column to print thread count per process can be added manually.
- Press f
- This will show a list of fields that top can display. The fields that are displayed in bold are the ones that top will display.
- Use the down arrow to navigate to «nTH» (Number of Threads).
- Press to select «nTH«
- Press ‘s‘ to sort on number of threads.
- Press ‘q‘ to display the data of threads count.
Next you should see a new column at the end of top command with number of thread (nTH) column to show threads per process
Check thread count per process
Next you can use the above explained commands to also check thread count per process by customising them a little bit.
1. Using PID status
To check thread count per process you can use below command. For example here java thread count is 59 threads in my Linux environment
While amsHelper process has single thread
2. Using ps command
We used ps command to show threads per process and count threads, we can also use » ps » command to get LWP and NLWP details, which when combined with » wc » we can count threads per process.
To check thread count per process for a particular PID for example to check java thread count:
Check number of threads allowed in Linux system?
Linux doesn’t have a separate threads per process limit, j ust a limit on the total number of processes on the system . This value controls the maximum number of threads that can be created using fork() . During initialization the kernel sets this value such that even if the maximum number of threads is created
To check number of threads which Linux system can allow
The minimum number of threads that can be written to threads-max is 20 .
The maximum value that can be written to threads-max is given by the constant FUTEX_TID_MASK (0x3fffffff) .
If a value outside of this range is written to threads-max an error EINVAL occurs.
The default value depends on memory size. You can use threads-max to check number of threads allowed in Linux. You can increase thread count per process limit like this:
There is also a limit on the number of processes (an hence threads) that a single user may create, see ulimit for details regarding these limits:
Here, the system is able to create 35,000 threads/processes in total and a single user can create 10000 number of processes.
The logic is very simple here every CPU can execute 1 process at a time, if there are 8 cores that means 8 to 10 processes at a time can be executed easily without any stress but if number of running or runnable threads per CPU increases drastically then there will be performance issue.
What is the maximum processes count allowed in Linux?
Verify the value for kernel.pid_max
Here I can execute 35,000 processes simultaneously in my system that can run in separate memory spaces.
To change the value of kernel.pid_max to 65534:
Lastly I hope the steps from the article to show threads per process, check thread count per process, check number of threads allowed on Linux was helpful. So, let me know your suggestions and feedback using the comment section.
Related Posts
Didn’t find what you were looking for? Perform a quick search across GoLinuxCloud
If my articles on GoLinuxCloud has helped you, kindly consider buying me a coffee as a token of appreciation.

For any other feedbacks or questions you can either use the comments section or contact me form.
Thank You for your support!!
Источник
What are Linux Processes, Threads, Light Weight Processes, and Process State
Linux has evolved a lot since its inception. It has become the most widely used operating system when in comes to servers and mission critical work. Though its not easy to understand Linux as a whole but there are aspects which are fundamental to Linux and worth understanding.
In this article, we will discuss about Linux processes, threads and light weight processes and understand the difference between them. Towards the end, we will also discuss various states for Linux processes.
Linux Processes
In a very basic form, Linux process can be visualized as running instance of a program. For example, just open a text editor on your Linux box and a text editor process will be born.
Here is an example when I opened gedit on my machine :
First command (gedit &) opens gedit window while second ps command (ps -aef | grep gedit) checks if there is an associated process. In the result you can see that there is a process associated with gedit.
Processes are fundamental to Linux as each and every work done by the OS is done in terms of and by the processes. Just think of anything and you will see that it is a process. This is because any work that is intended to be done requires system resources ( that are provided by kernel) and it is a process that is viewed by kernel as an entity to which it can provide system resources.
Processes have priority based on which kernel context switches them. A process can be pre-empted if a process with higher priority is ready to be executed.
For example, if a process is waiting for a system resource like some text from text file kept on disk then kernel can schedule a higher priority process and get back to the waiting process when data is available. This keeps the ball rolling for an operating system as a whole and gives user a feeling that tasks are being run in parallel.
Processes can talk to other processes using Inter process communication methods and can share data using techniques like shared memory.
In Linux, fork() is used to create new processes. These new processes are called as child processes and each child process initially shares all the segments like text, stack, heap etc until child tries to make any change to stack or heap. In case of any change, a separate copy of stack and heap segments are prepared for child so that changes remain child specific. The text segment is read-only so both parent and child share the same text segment. C fork function article explains more about fork().
Linux Threads vs Light Weight Processes
Threads in Linux are nothing but a flow of execution of the process. A process containing multiple execution flows is known as multi-threaded process.
For a non multi-threaded process there is only execution flow that is the main execution flow and hence it is also known as single threaded process. For Linux kernel , there is no concept of thread. Each thread is viewed by kernel as a separate process but these processes are somewhat different from other normal processes. I will explain the difference in following paragraphs.
Threads are often mixed with the term Light Weight Processes or LWPs. The reason dates back to those times when Linux supported threads at user level only. This means that even a multi-threaded application was viewed by kernel as a single process only. This posed big challenges for the library that managed these user level threads because it had to take care of cases that a thread execution did not hinder if any other thread issued a blocking call.
Later on the implementation changed and processes were attached to each thread so that kernel can take care of them. But, as discussed earlier, Linux kernel does not see them as threads, each thread is viewed as a process inside kernel. These processes are known as light weight processes.
The main difference between a light weight process (LWP) and a normal process is that LWPs share same address space and other resources like open files etc. As some resources are shared so these processes are considered to be light weight as compared to other normal processes and hence the name light weight processes.
So, effectively we can say that threads and light weight processes are same. It’s just that thread is a term that is used at user level while light weight process is a term used at kernel level.
From implementation point of view, threads are created using functions exposed by POSIX compliant pthread library in Linux. Internally, the clone() function is used to create a normal as well as alight weight process. This means that to create a normal process fork() is used that further calls clone() with appropriate arguments while to create a thread or LWP, a function from pthread library calls clone() with relevant flags. So, the main difference is generated by using different flags that can be passed to clone() function.
Read more about fork() and clone() on their respective man pages.
Linux Process States
Life cycle of a normal Linux process seems pretty much like real life. Processes are born, share resources with parents for sometime, get their own copy of resources when they are ready to make changes, go through various states depending upon their priority and then finally die. In this section will will discuss various states of Linux processes :
- RUNNING – This state specifies that the process is either in execution or waiting to get executed.
- INTERRUPTIBLE – This state specifies that the process is waiting to get interrupted as it is in sleep mode and waiting for some action to happen that can wake this process up. The action can be a hardware interrupt, signal etc.
- UN-INTERRUPTIBLE – It is just like the INTERRUPTIBLE state, the only difference being that a process in this state cannot be waken up by delivering a signal.
- STOPPED – This state specifies that the process has been stopped. This may happen if a signal like SIGSTOP, SIGTTIN etc is delivered to the process.
- TRACED – This state specifies that the process is being debugged. Whenever the process is stopped by debugger (to help user debug the code) the process enters this state.
- ZOMBIE – This state specifies that the process is terminated but still hanging around in kernel process table because the parent of this process has still not fetched the termination status of this process. Parent uses wait() family of functions to fetch the termination status.
- DEAD – This state specifies that the process is terminated and entry is removed from process table. This state is achieved when the parent successfully fetches the termination status as explained in ZOMBIE state.
Источник
Linux Kernel Process Management
This chapter is from the book
This chapter is from the book
This chapter is from the book
The process is one of the fundamental abstractions in Unix operating systems 1 . A process is a program (object code stored on some media) in execution. Processes are, however, more than just the executing program code (often called the text section in Unix). They also include a set of resources such as open files and pending signals, internal kernel data, processor state, an address space, one or more threads of execution, and a data section containing global variables. Processes, in effect, are the living result of running program code.
Threads of execution, often shortened to threads, are the objects of activity within the process. Each thread includes a unique program counter, process stack, and set of processor registers. The kernel schedules individual threads, not processes. In traditional Unix systems, each process consists of one thread. In modern systems, however, multithreaded programs—those that consist of more than one thread—are common. As you will see later, Linux has a unique implementation of threads: It does not differentiate between threads and processes. To Linux, a thread is just a special kind of process.
On modern operating systems, processes provide two virtualizations: a virtualized processor and virtual memory. The virtual processor gives the process the illusion that it alone monopolizes the system, despite possibly sharing the processor among dozens of other processes. Chapter 4, «Process Scheduling,» discusses this virtualization. Virtual memory lets the process allocate and manage memory as if it alone owned all the memory in the system. Virtual memory is covered in Chapter 11, «Memory Management.» Interestingly, note that threads share the virtual memory abstraction while each receives its own virtualized processor.
A program itself is not a process; a process is an active program and related resources. Indeed, two or more processes can exist that are executing the same program. In fact, two or more processes can exist that share various resources, such as open files or an address space.
A process begins its life when, not surprisingly, it is created. In Linux, this occurs by means of the fork() system call, which creates a new process by duplicating an existing one. The process that calls fork() is the parent, whereas the new process is the child. The parent resumes execution and the child starts execution at the same place, where the call returns. The fork() system call returns from the kernel twice: once in the parent process and again in the newborn child.
Often, immediately after a fork it is desirable to execute a new, different, program. The exec*() family of function calls is used to create a new address space and load a new program into it. In modern Linux kernels, fork() is actually implemented via the clone() system call, which is discussed in a following section.
Finally, a program exits via the exit() system call. This function terminates the process and frees all its resources. A parent process can inquire about the status of a terminated child via the wait4() 2 system call, which enables a process to wait for the termination of a specific process. When a process exits, it is placed into a special zombie state that is used to represent terminated processes until the parent calls wait() or waitpid().
Another name for a process is a task. The Linux kernel internally refers to processes as tasks. In this book, I will use the terms interchangeably, although when I say task I am generally referring to a process from the kernel’s point of view.
Process Descriptor and the Task Structure
The kernel stores the list of processes in a circular doubly linked list called the task list 3 . Each element in the task list is a process descriptor of the type struct task_struct, which is defined in . The process descriptor contains all the information about a specific process.
The task_struct is a relatively large data structure, at around 1.7 kilobytes on a 32-bit machine. This size, however, is quite small considering that the structure contains all the information that the kernel has and needs about a process. The process descriptor contains the data that describes the executing program—open files, the process's address space, pending signals, the process's state, and much more (see Figure 3.1).
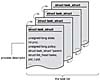
Figure 3.1 The process descriptor and task list.
Allocating the Process Descriptor
The task_struct structure is allocated via the slab allocator to provide object reuse and cache coloring (see Chapter 11, "Memory Management"). Prior to the 2.6 kernel series, struct task_struct was stored at the end of the kernel stack of each process. This allowed architectures with few registers, such as x86, to calculate the location of the process descriptor via the stack pointer without using an extra register to store the location. With the process descriptor now dynamically created via the slab allocator, a new structure, struct thread_info, was created that again lives at the bottom of the stack (for stacks that grow down) and at the top of the stack (for stacks that grow up) 4 . See Figure 3.2.
The new structure also makes it rather easy to calculate offsets of its values for use in assembly code.
The thread_info structure is defined on x86 in as
Each task's thread_info structure is allocated at the end of its stack. The task element of the structure is a pointer to the task's actual task_struct.

Figure 3.2 The process descriptor and kernel stack.
Storing the Process Descriptor
The system identifies processes by a unique process identification value or PID. The PID is a numerical value that is represented by the opaque type 5 pid_t, which is typically an int. Because of backward compatibility with earlier Unix and Linux versions, however, the default maximum value is only 32,768 (that of a short int), although the value can optionally be increased to the full range afforded the type. The kernel stores this value as pid inside each process descriptor.
This maximum value is important because it is essentially the maximum number of processes that may exist concurrently on the system. Although 32,768 might be sufficient for a desktop system, large servers may require many more processes. The lower the value, the sooner the values will wrap around, destroying the useful notion that higher values indicate later run processes than lower values. If the system is willing to break compatibility with old applications, the administrator may increase the maximum value via /proc/sys/kernel/pid_max.
Inside the kernel, tasks are typically referenced directly by a pointer to their task_struct structure. In fact, most kernel code that deals with processes works directly with struct task_struct. Consequently, it is very useful to be able to quickly look up the process descriptor of the currently executing task, which is done via the current macro. This macro must be separately implemented by each architecture. Some architectures save a pointer to the task_struct structure of the currently running process in a register, allowing for efficient access. Other architectures, such as x86 (which has few registers to waste), make use of the fact that struct thread_info is stored on the kernel stack to calculate the location of thread_info and subsequently the task_struct.
On x86, current is calculated by masking out the 13 least significant bits of the stack pointer to obtain the thread_info structure. This is done by the current_thread_info() function. The assembly is shown here:
This assumes that the stack size is 8KB. When 4KB stacks are enabled, 4096 is used in lieu of 8192.
Finally, current dereferences the task member of thread_info to return the task_struct:
Contrast this approach with that taken by PowerPC (IBM's modern RISC-based microprocessor), which stores the current task_struct in a register. Thus, current on PPC merely returns the value stored in the register r2. PPC can take this approach because, unlike x86, it has plenty of registers. Because accessing the process descriptor is a common and important job, the PPC kernel developers deem using a register worthy for the task.
Process State
The state field of the process descriptor describes the current condition of the process (see Figure 3.3). Each process on the system is in exactly one of five different states. This value is represented by one of five flags:
TASK_RUNNING—The process is runnable; it is either currently running or on a runqueue waiting to run (runqueues are discussed in Chapter 4, "Scheduling"). This is the only possible state for a process executing in user-space; it can also apply to a process in kernel-space that is actively running.
TASK_INTERRUPTIBLE—The process is sleeping (that is, it is blocked), waiting for some condition to exist. When this condition exists, the kernel sets the process's state to TASK_RUNNING. The process also awakes prematurely and becomes runnable if it receives a signal.
TASK_UNINTERRUPTIBLE—This state is identical to TASK_INTERRUPTIBLE except that it does not wake up and become runnable if it receives a signal. This is used in situations where the process must wait without interruption or when the event is expected to occur quite quickly. Because the task does not respond to signals in this state, TASK_UNINTERRUPTIBLE is less often used than TASK_INTERRUPTIBLE 6 .
TASK_ZOMBIE—The task has terminated, but its parent has not yet issued a wait4() system call. The task's process descriptor must remain in case the parent wants to access it. If the parent calls wait4(), the process descriptor is deallocated.
TASK_STOPPED—Process execution has stopped; the task is not running nor is it eligible to run. This occurs if the task receives the SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal or if it receives any signal while it is being debugged.
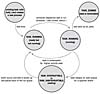
Figure 3.3 Flow chart of process states.
Manipulating the Current Process State
Kernel code often needs to change a process's state. The preferred mechanism is using
This function sets the given task to the given state. If applicable, it also provides a memory barrier to force ordering on other processors (this is only needed on SMP systems). Otherwise, it is equivalent to
The method set_current_state(state) is synonymous to set_task_state(current, state).
Process Context
One of the most important parts of a process is the executing program code. This code is read in from an executable file and executed within the program's address space. Normal program execution occurs in user-space. When a program executes a system call (see Chapter 5, "System Calls") or triggers an exception, it enters kernel-space. At this point, the kernel is said to be "executing on behalf of the process" and is in process context. When in process context, the current macro is valid 7 . Upon exiting the kernel, the process resumes execution in user-space, unless a higher-priority process has become runnable in the interim, in which case the scheduler is invoked to select the higher priority process.
System calls and exception handlers are well-defined interfaces into the kernel. A process can begin executing in kernel-space only through one of these interfaces—all access to the kernel is through these interfaces.
The Process Family Tree
A distinct hierarchy exists between processes in Unix systems, and Linux is no exception. All processes are descendents of the init process, whose PID is one. The kernel starts init in the last step of the boot process. The init process, in turn, reads the system initscripts and executes more programs, eventually completing the boot process.
Every process on the system has exactly one parent. Likewise, every process has zero or more children. Processes that are all direct children of the same parent are called siblings. The relationship between processes is stored in the process descriptor. Each task_struct has a pointer to the parent's task_struct, named parent, and a list of children, named children. Consequently, given the current process, it is possible to obtain the process descriptor of its parent with the following code:
Similarly, it is possible to iterate over a process's children with
The init task's process descriptor is statically allocated as init_task. A good example of the relationship between all processes is the fact that this code will always succeed:
In fact, you can follow the process hierarchy from any one process in the system to any other. Oftentimes, however, it is desirable simply to iterate over all processes in the system. This is easy because the task list is a circular doubly linked list. To obtain the next task in the list, given any valid task, use:
Obtaining the previous works the same way:
These two routines are provided by the macros next_task(task) and prev_task(task), respectively. Finally, the macro for_each_process(task) is provided, which iterates over the entire task list. On each iteration, task points to the next task in the list:
Note: It can be expensive to iterate over every task in a system with many processes; code should have good reason (and no alternative) before doing so.
Источник



