- 15 simple TOP command examples on Linux to monitor processes
- Linux TOP command
- Note your «top» command variant
- 1. Display processes
- 2. Sort by Memory/Cpu/Process ID/Running Time
- 3. Reverse the sorting order — ‘R’
- 4. Highlight the sorted column with bold text — ‘x’
- 5. Highlight sorted column background color ‘b’
- 6. Change the update delay — ‘d’
- 7. Filter or Search processes — ‘o’/’O’
- 8. Display full command path and arguments of process — ‘c’
- 9. View processes of a user — ‘u’/’U’
- 10. Toggle the display of idle processes — ‘i’
- 11. Hide/Show the information on top — ‘l’, ‘t’, ‘m’
- 12. Forest mode — ‘V’
- 13. Change the number of processes to display — ‘n’
- 14. Display all CPU cores — ‘1’
- 15. Show/Hide columns ‘f’
- 16. Batch mode
- 17. Split output in multiple panels — ‘A’
- Conclusion
- 10 thoughts on “ 15 simple TOP command examples on Linux to monitor processes ”
- Практические рекомендации: устраняйте неполадки, используя команду ‘Top’ в Linux
15 simple TOP command examples on Linux to monitor processes
Linux TOP command
One of the most basic command to monitor processes on Linux is the top command. As the name suggests, it shows the top processes based on certain criterias like cpu usage or memory usage.
The processes are listed out in a list with multiple columns for details like process name, pid, user, cpu usage, memory usage.
Apart from the list of processes, the top command also shows brief stats about average system load, cpu usage and ram usage on the top.
This post shows you some very simple examples of how to use the top command to monitor processes on your linux machine or server.
Note your «top» command variant
Be aware that the top command comes in various variants and each has a slightly different set of options and method of usage.
To check your top command version and variant use the -v option
This post focuses on the top command coming from the procps-ng project. This is the version available on most modern distros like Ubunut, Fedora, CentOS etc.
1. Display processes
To get a glimpse of the running processes, just run the top command as is without any options like this.
And immediately the output would be something like this —
The screen contains a lot of information about the system. The header areas include uptime, load average, cpu usage, memory usage data.
The process list shows all the processes with various process specific details in separate columns.
Some of the column names are pretty self explanatory.
PID — Process ID
USER — The system user account running the process.
%CPU — CPU usage by the process.
%MEM — Memory usage by the process
COMMAND — The command (executable file) of the process
2. Sort by Memory/Cpu/Process ID/Running Time
To find the process consuming the most cpu or memory, simply sort the list.
Press M key ( yes, in capital, not small ) to sort the process list by memory usage. Processes using the most memory are shown first and rest in order.
Here are other options to sort by CPU usage, Process ID and Running Time —
Press ‘P’ — to sort the process list by cpu usage.
Press ‘N’ — to sort the list by process id
Press ‘T’ — to sort by the running time.
3. Reverse the sorting order — ‘R’
By default the sorting is done in descending order. Pressing ‘R’ shall reverse the sorting order of the currently sorted column
Here is the output sorted in ascending order of cpu usage. Processes consuming the least amount of cpu are shown first.
4. Highlight the sorted column with bold text — ‘x’
Press x, to highlight the values in the sort column with bold text. Here is a screenshot, with the memory column in bold text —
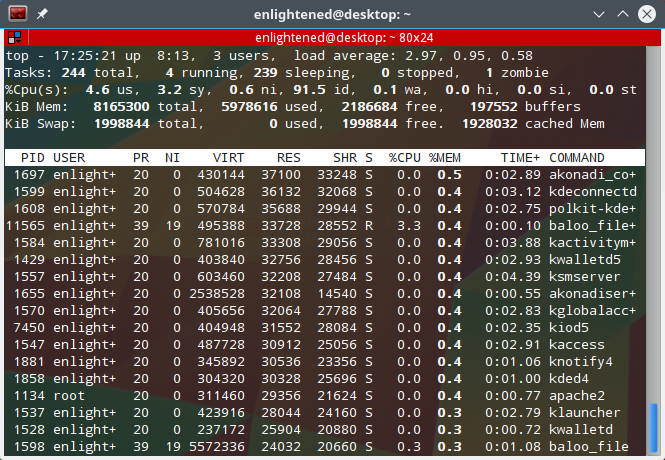
top command highlight column
5. Highlight sorted column background color ‘b’
After highlighting the sorted column with bold font, its further possible to highlight with a different background color as well. This is how it looks
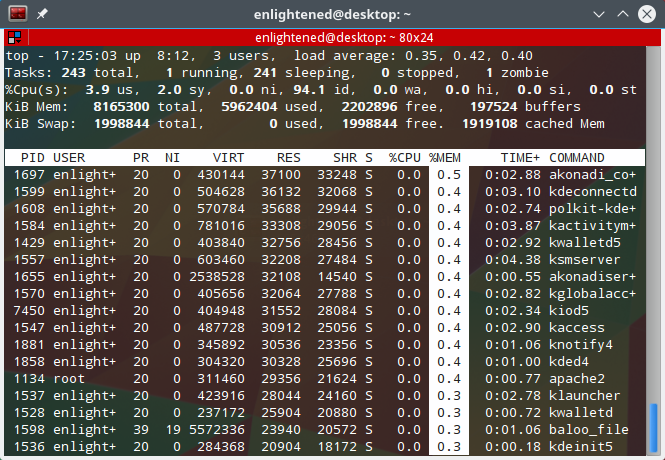
Top command highlight column background
6. Change the update delay — ‘d’
The top command updates the information on the screen every 3.0 seconds by default. This refresh interval can be changed.
Press the ‘d’ key, and top will ask you to enter the time interval between each refresh. You can enter numbers smaller than 1 second as well, like 0.5. Enter the desired interval and hit Enter.
7. Filter or Search processes — ‘o’/’O’
You can filter the process list based on various criterias like process name, memory usage, cpu usage etc. Multiple filter criterias can be applied.
Press the ‘o’ or ‘O’ to activate filter prompt. It will show a line indicating the filter format like this —
Then enter a filter like this and hit Enter.
COMMAND=apache
Now top will show only those processes whose COMMAND field contains the value apache.
Here is another filter example that shows processes consuming CPU actively —
%CPU>0.0
See active filters — Press Ctrl+o to see currently active filters
Clear filter — Press ‘=’ key to clear any active filters
8. Display full command path and arguments of process — ‘c’
Press ‘c’ to display the full command path along with the commandline arguments in the COMMAND column.
9. View processes of a user — ‘u’/’U’
To view the processes of a specific user only, press ‘u’ and then top will ask you to enter the username.
Which user (blank for all)
Enter the desired username and hit Enter.
10. Toggle the display of idle processes — ‘i’
Press ‘i’ to toggle the display of idle/sleeping processes. By default all processes are display.
11. Hide/Show the information on top — ‘l’, ‘t’, ‘m’
The ‘l’ key would hide the load average information.
The ‘m’ key will hide the memory information.
The ‘t’ key would hide the task and cpu information.
Hiding the header information area, makes more processes visible in the list.
12. Forest mode — ‘V’
Pressing ‘V’ will display the processes in a parent child hierarchy. It looks something like this —
13. Change the number of processes to display — ‘n’
Lets say you want to monitor only few processes based on a certain filter criteria. Press ‘n’ and enter the number of processes you wish to display.
It will display a line saying —
Maximum tasks = 0, change to (0 is unlimited)
14. Display all CPU cores — ‘1’
Pressing ‘1’ will display the load information about individual cpu cores. Here is how it looks —
15. Show/Hide columns ‘f’
By default top displays only few columns out of many more that it can display. If you want to add or remove a particular column or change the order of columns, then press f
The fields marked * or bold are the fields that are displayed, in the order in which they appear in this list.
Navigate the list using up/down arrow keys and press ‘d’ to toggle the display of that field. Once done, press q to go back to the process list
The following output displays only PID, USER, CPU, MEMORY and COMMAND columns.
16. Batch mode
Top also supports batch mode output, where it would keep printing information sequentially instead of a single screen. This is useful when you need to log the top output for later analysis of some kind.
Here is a simple example that shows the Cpu usage at intervals of 1 second.
17. Split output in multiple panels — ‘A’
Each panel can be sorted on a different column. Press ‘a’ to move through the panels. Each panel can have a different set of fields displayed and different sort columns.
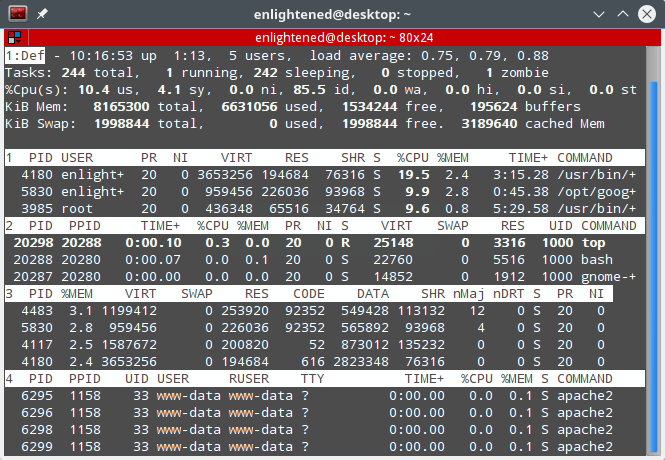
top command multiple panels
Conclusion
Top is a great commandline tool to check system resource usage and process details. Its often used on servers for monitoring and quick diagnosis.
If you are looking for something easier with a better user interface then try htop. Htop has a intuitive user interface, where you need not memorize keyboard shortcuts. Htop has onscreen instructions that guide you on how to use it.
A Tech Enthusiast, Blogger, Linux Fan and a Software Developer. Writes about Computer hardware, Linux and Open Source software and coding in Python, Php and Javascript. He can be reached at [email protected] .
10 thoughts on “ 15 simple TOP command examples on Linux to monitor processes ”
Nice article and great explanation.
if same user id is running multiple times how to delete all others except one.Please any one reply me fast.
exp
PID USER PR %cpu
QPD02201
QPD02201
QPD02201
QPD02201
A really top article!
Hi, thanks for the great article but I’m still looking for an answer for my case: It looks like that all the time. CPU load is around 45-50% all the time but if I add up the CPU usage of the services it never gets close… Why’s that?
Tasks: 251 total, 1 running, 250 sleeping, 0 stopped, 0 zombie
%Cpu0 : 50,1 us, 10,1 sy, 0,0 ni, 39,8 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st
%Cpu1 : 55,7 us, 7,2 sy, 0,0 ni, 36,8 id, 0,0 wa, 0,0 hi, 0,2 si, 0,0 st
%Cpu2 : 35,6 us, 4,4 sy, 0,0 ni, 58,8 id, 0,0 wa, 0,0 hi, 1,2 si, 0,0 st
%Cpu3 : 36,7 us, 5,8 sy, 0,0 ni, 56,9 id, 0,0 wa, 0,0 hi, 0,6 si, 0,0 st
KiB Mem : 16242248 total, 12711832 free, 2071424 used, 1458992 buff/cache
KiB Swap: 3809276 total, 3809276 free, 0 used. 13807884 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9066 root 20 0 830468 35332 25632 S 2,2 0,2 2:19.18 metricbeat
5428 www-data 20 0 72168 27716 2520 S 1,2 0,2 3:28.49 kix.Daemon.pl
590 kopano 20 0 291488 41016 24640 S 0,6 0,3 1:27.52 kopano-search
581 kopano 20 0 355280 38644 18984 S 0,4 0,2 1:27.69 kopano-presence
7 root 20 0 0 0 0 S 0,2 0,0 0:31.24 rcu_sched
580 root 20 0 250116 4332 2508 S 0,2 0,0 0:01.37 rsyslogd
821 postgres 20 0 268376 6448 4688 S 0,2 0,0 0:00.07 postgres
1569 mysql 20 0 739704 114760 17024 S 0,2 0,7 0:38.78 mysqld
1802 root 20 0 392128 12028 6828 S 0,2 0,1 0:08.35 docker-containe
1875 root 20 0 3125288 23428 9428 S 0,2 0,1 0:40.27 slapd
2043 root 20 0 818760 70340 28176 S 0,2 0,4 0:37.41 named
2686 kdm 20 0 392288 59108 33904 S 0,2 0,4 0:29.23 kdm_greet
2871 root 20 0 4822492 437276 23464 S 0,2 2,7 2:01.74 java
9560 root 20 0 588668 69552 22952 S 0,2 0,4 0:40.12 packetbeat
10650 root 20 0 38144 3588 3012 R 0,2 0,0 0:04.37 top
Maybe it looks better like this
%Cpu0 : 50,1 us, 10,1 sy,
%Cpu1 : 55,7 us, 7,2 sy,
%Cpu2 : 35,6 us, 4,4 sy,
%Cpu3 : 36,7 us, 5,8 sy,
Источник
Практические рекомендации: устраняйте неполадки, используя команду ‘Top’ в Linux
Вывод команды «top»
Если в коммандной строке линукс системы вы наберете команду top, то получите табличку со следующим заголовком:

Давайте разберем значение каждой из строк.
top – 17:15:19 up 32 days, 18:24, 6 users
Здесь показана команда и текущее системное время; «время бесперебойной работы», в нашем случае это 32 дня, 18 часов и 24 минуты; наконец, указывается количество зарегистрированных в системе пользователей; в данном примере, в системе зарегистрированы 6 пользователей. Они могут быть подключены по SSH, локально, быть неактивными и т.д.
load average: 0,00, 0,01, 0,05
В этой части показывается средняя нагрузка; она может сбивать с толку, особенно на виртуальной машине/в облаке.
Первая цифра показывает среднюю нагрузку «последней минуты», или «текущую» среднюю нагрузку; вторая цифра показывает «среднюю нагрузку за 5 минут», последняя цифра – «среднюю нагрузку за 15 минут».
Средняя нагрузка – мера среднего числа процессов, ожидающих своей очереди, чтобы совершить какое-либо действие в процессоре. Как и в супермаркете, приходится стоять в очереди, дожидаясь, пока кассир уделит вам все свое внимание. Причина, по которой средняя нагрузка растет, заключается в остальной статистике и счетчиках, находящихся ниже этой линии, поэтому, если ориентироваться строго на значения средней нагрузки, можно не увидеть всей картинки полностью.
Вот пример, взятый из узла distcc:
Данный сервер, кроме того, что является средой промежуточной обработки для скриптов и хостингом инструментов командной строки облака, предоставляет также распределенную службу C компилятора различным машинам, находящимся в нашей сети, поскольку она имеет 8 процессоров, 32 ГБ оперативной памяти и тонну псевдодискового пространства. При нормальной нагрузке, среднее ее значение остается относительно низким; при выполнении java-скриптов нагрузка может вырастать в два и более раза. Однако при выполнении службы компилятора при полной нагрузке (10 выполняемых процессов при загрузке процессора, равной 95% или выше), среднее значение нагрузки составляет 0,75… Как же так получается? Попытаемся разобраться
Строка Tasks
1.
• sleeping Количество ждущих процессов показывает, какие процессы выполняются, но не являются активными; обычно это фоновые задачи, системное ПО, драйвера принтера и т.д.
• stopped Количество остановленных процессов должно, как правило, равняться 0, если вы не послали процессу сигнал a SIGSTOP или kill -STOP для устранения неисправностей. Если это число отличается от 0, то, в случае с рабочими серверами это может служить поводом для беспокойства.
• zombie Зависшие процессы. Это означает, что многопоточное приложение запустило дочерний процесс, а затем было уничтожено или неожиданно завершено, оставив после себя повисший процесс, известный, как zombie-процесс. Apache может наплодить целую кучу таких процессов в случае, если происходит что-то из ряда вон выходящее. Обычно, их число тоже должно равняться 0.
Строка Cpu
Я разобью эту информацию на две части, в них содержится статистика, важная для нашего использования.
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni, 99.9%id,
Первые четыре величины, приведенные здесь, присутствуют на всех серверах с linux, и они привычны для большинства людей.
• %us показывает использование отдельного процессора (пользовательскими процессами, такими, как apache, mysql и т.д.) до максимального значения, составляющего 100%. Таким образом, если в четырехъядерном процессоре 1 процесс использует 100% CPU, это даст значение %us, равное 25%. Значение 12,5% для 8-ядерного процессора означает, что занято одно ядро.
• %sy означает использование CPU системой. Обычно это значение невысоко, высокие его значения могут свидетельствовать о проблеме с конфигами ядра, проблему со стороны драйвера, или целый ряд других вещей.
• %ni означает процент CPU, используемого пользовательскими процессами, на которые повлияло использование команд nice или renice, т.е. по существу их приоритет был изменен по сравнению с приоритетом по умолчанию, назначаемому планировщиком, на более высокий или низкий. При назначении какому-либо процессу команды nice, положительное число означает более низкий приоритет (1 = 1 шаг ниже нормального), а отрицательное число означает более высокий приоритет. 0 – значение по умолчанию, что означает, что решение о приоритете принимает планировщик. Можно установить, какой планировщик используется вашей системой, но это более сложная тема для следующих статей. Кроме того, любая величина в процентах, приведенная в этот статье не накладывается на величину %us, которая показывает только пользовательские процессы с невыставленным приоритетом.
• %id – результат, получающийся при вычитании трех предыдущих значений из 100,0%, и измеряющий «простаивающую» вычислительную мощность.
0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Второй набор значений связан с виртуализацией, и именно по ним мы можем точно отследить те проблемы, которые, возможно, вносят вклад в высокое значение средней нагрузки.
• %wa – iowait, процент времени (циклов, секунд), в течение которого процессор простаивал, ожидая завершения операции ввода-вывода. Когда какой-либо процесс или программа запрашивает данные, он сначала проверяет кэш процессора (в нем имеется 2 или 3 кэша), затем проверяет память и, наконец, доходит до диска. Дойдя до диска, процессу или программе обычно приходится ждать, пока поток ввода-вывода передаст информацию в оперативную память, прежде чем иметь возможность снова на нем работать. Чем медленнее диск, тем выше будет значение IO Wait % для каждого процесса. Это происходит также с процессами записи на диск, если системный буфер заполнен и его необходимо прочистить при помощи ядра – обычно это наблюдается на серверах баз данных с высокой нагрузкой. Если значение IO Wait стабильно превышает <100 >%, это означает, что, возможно, имеется проблема хранения, с которой необходимо разобраться. Если вы наблюдаете высокую среднюю нагрузку, прежде всего, проверьте этот параметр. Если он высок, тогда узкое место в процессах, скапливающихся на диске, а не в чем-либо еще.
• %hi означает прерывания на уровне железа; на плате электроны движутся по микросхемам предсказуемым образом. Например, когда сетевая карта получает пакет, перед передачей информации, содержащейся в пакете в процессор через ядро, она запросит прерывание в канале прерывания материнской платы. Процессор сообщает ядру, что у сетевой карты для него есть информация, а ядро имеет возможность решить, как поступить. Высокое значение времени, тратящегося на обработку прерываний на уровне железа встречается на виртуальной машине довольно редко, но по мере того, как гипервизоры предоставляют в распоряжение виртуальных машин все больше «железа», эта ситуация может измениться. Чрезвычайно высокая пропускная способность сети, использование USB, вычисления на графических процессорах, — все это может привести к росту этого параметра на величину, превышающую несколько процентов.
• %si – прерывание на уровне софта; в ядре linux версии 2.4 реализована возможность запроса прерывания программным обеспечением (приложениями), а не элементом аппаратного обеспечения или устройством (драйвером), запрашивающим прерывание в канале прерывания материнской платы; запрос обслуживается ядром посредством его обработчика прерываний. Это означает, что приложение может запросить приоритетный статус, ядро может подтвердить получение команда, а программное обеспечение будет терпеливо ждать, пока прерывание не будет обслужено. Если мы применим утилиту tcpdump к гигабитному каналу с высоким трафиком, то значение может измениться примерно на 10%, — по мере заполнения выделенной памяти tcpdump, утилита посылает зарос на прерывание, чтобы переместить данные со стека на диск, экран, или куда угодно еще.
• %st — самый важный параметр из всех в списке, по моему мнению, это IOSteal%. В виртуализированной среде множество логических серверов могут работать под одним фактическим гипервизором. Каждой виртуальной машине(VM) мы присваиваем 4-8 «виртуальных» CPU; хотя сами гипервизоры могут не иметь (кол-во VM * кол-во виртуальных CPU на одну VM). Причина этого заключается в том, что мы не перегружаем CPU использованием наших виртуальных машин, так что если мы дадим одной-двум VM возможность изредка использовать 8 процессоров, это не будет негативно влиять на весь пул в целом. Однако если виртуальными процессорами VM используется количество CPU, превышающее количество физических (или логических, в случае с гиперпотоковыми процессорами Xeon), тогда значение iosteal будет расти.
iosteal% — мера загруженности гипервизора; наличие в каком-либо пуле виртуальных машин, демонстрирующих стабильно высокое значение параметра iosteal% (более 15%) может свидетельствовать о необходимости переноса некоторых из VM в другую часть пула.
iowait% является показателем производительности диска. В системе хранения данных, поддерживаемой NetApp, у нас может не получиться решить проблему производительности без перемещения тома на менее используемый, или другой диск NetApp. В случае с локальным диском (SSD или SAS) это может означать, что в гипервизоре имеется слишком много VM, интенсивно использующих ресурсы диска, и может потребоваться перенести некоторые из этих VM в другую часть пула.
Подведем итоги:
• Средняя нагрузка, на самом деле, ни о чем не говорит.
• Параметр %userland (%us) важен для средней нагрузки, поскольку он говорит о том, что производятся вычисления. Например, mysql, займет всего один поток, поэтому при полной нагрузке будет использовать (1/кол-во виртуальных CPU, присвоенных VM). postgresql является многопоточным, и может использовать больше процессоров, если они будут выделены, – помните об этом, создавая виртуальные машины в гипервизоре, чтобы предотвратить:
• %st – iosteal% — показатель загруженности гипервизора. Создание стека из 4-х postgresql и 6 серверов tomcat под одним гипервизором может быть разумным с точки зрения бизнеса, но вам придется все время конкурировать за процессорное время.
• %wa – iowait% — показатель количества времени, которое уходит на отсылку ваших процессов на невероятно медленные диски, неважно какое решение для хранения данных вы используете. Диски, даже SSD, сравнительно медленные. Добавление ОЗУ для увеличения буфера ядра может немного смягчить проблему. ОЗУ дешевле диска, если учесть, насколько молниеносно она работает по сравнению с ним.
Дополнительные команды
iostat
Если вы столкнулись с высокими значениями параметров iowait или iosteal, можно с точностью отследить, какой диск является этому причиной, при помощи команды iostat. Запускается она таким образом:

Более подробно, см. руководство по iostat. Разбивка, выводимая каждую секунду, с каких и на какие диски идет чтение/ запись, а также все значения iosteal или iowait, связанные с доступом к этим дискам.
htop
Команда по использованию CPU и процессов на системе Linux. Он не показывает виртуальную статистику, но отображает дерево процессов, а также разбивку каждого процессора в системе, его использование; кроме того, он показывает статистику свопинга и памяти, позволяющую отследить неприятные утечки памяти, раскрашивая все это симпатичными цветами. По моему мнению, этот пакет должен быть обязательным для всех VM.
Источник



