- Linux удалить перевод строки
- Команда tr и ее синтаксис
- 1) Заменить все строчные буквы на заглавные
- 2) Удаление символов с помощью tr
- 3) Удаление ила змена символов НЕ в наборе
- 4) Замена пробелов на табуляцию
- 5) Удаление повторений символов
- 6) Заменить символы из набора на перенос строки
- 7) Генерируем список уникальных слов из файла
- 8) Кодируем символы с помошью ROT
- Вывод
- unixforum.org
- Решено: удалить в тексте переносы строк
- Решено: удалить в тексте переносы строк
- Re: Решено: удалить в тексте переносы строк
- Re: Решено: удалить в тексте переносы строк
- Re: Решено: удалить в тексте переносы строк
- Как удалить символы переноса строк, стоящие перед определёнными символами
- 1 ответ 1
- Как я могу удалить завершающий перевод строки в bash?
- удаление замыкающего пустые линии-SED
- Аннотация
- Другие решения
- переменная
- Память
- Две строки в памяти
- Прямая обработка
Linux удалить перевод строки

Команда tr (translate) используется в Linux в основном для преобразования и удаления символов. Она часто находит применение в скриптах обработки текста. Ее можно использовать для преобразования верхнего регистра в нижний, сжатия повторяющихся символов и удаления символов.
Команда tr требует два набора символов для преобразований, а также может использоваться с другими командами, использующими каналы (пайпы) Unix для расширенных преобразований.
В этой статье мы узнаем, как использовать команду tr в операционных системах Linux и рассмотрим некоторые примеры.
Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
\NNN -> восмеричные (OCT) символы NNN (1 до 3 цифр)
\\ -> обратный слеш (экранированный)
\n -> новая строка (new line)
\r -> перенос строки (return)
\t -> табуляция (horizontal tab)
[:alnum:] -> все буквы и цифры
[:alpha:] -> все буквы
[:blank:] -> все пробелы
[:cntrl:] -> все управляющие символы (control)
[:digit:] -> все цифры
[:lower:] -> все буквы в нижнем регистре (строчные)
[:upper:] -> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
Вот некоторые опции:
-c , -C , —complement -> удалить все символы, кроме тех, что в первом наборе
-d , —delete -> удалить символы из первого набора
-s , —squeeze-repeats -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы [:lower:] [:upper:] или «a-z» «A-Z» для замены всех символов.
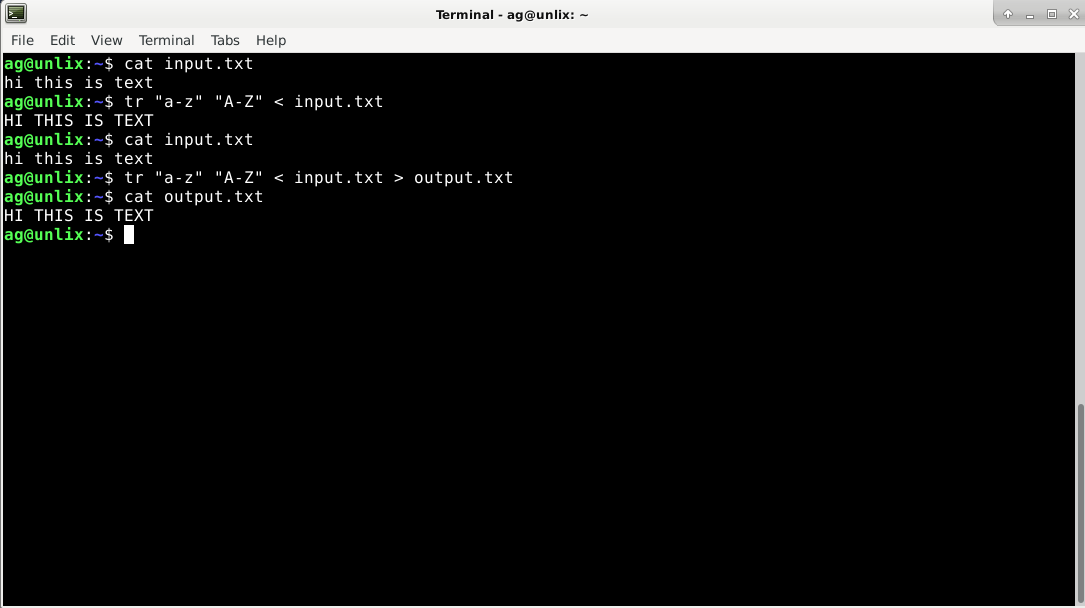
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
А сейчас сделаем замену из файла input.txt
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
2) Удаление символов с помощью tr
Опция -d используется для удаления всех символов, которые указаны в наборе символов.
Следующая команда удалит все символы из этого набора ‘aei’.
Следующая команда удалит все цифры в тексте. Будем использовать набор [:digit:] , чтобы определить все цифры.
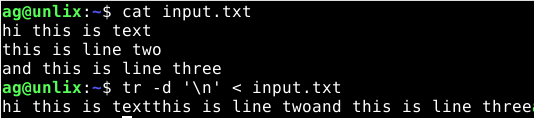
А вот пример команд, которыми можно удалить переносы на новые строки
3) Удаление ила змена символов НЕ в наборе
С помощью параметра -c Вы можете сказать tr заменить все символы, которые Вы не указали в наборе. Приведем пример.
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)

4) Замена пробелов на табуляцию
Для указания пробелов используем — [:space:] , а для табуляции — \t.
5) Удаление повторений символов
Это делает параметр -s . Рассмотрим пример удаления повторов знаков.
Или заменим повторения на символ решетки
6) Заменить символы из набора на перенос строки
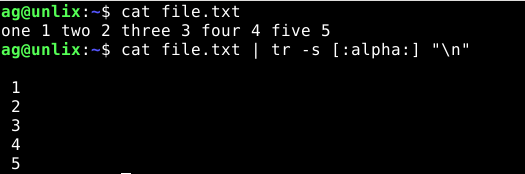
Сделаем так, чтобы все буквы были заменены на перенос новой строки:
7) Генерируем список уникальных слов из файла
Это иногда очень полезная команда, когда необходимо определить количество повторений и вывести уникальные слова из файла:
8) Кодируем символы с помошью ROT
ROT (Caesar Cipher) — это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор [a-z] (это значит abcdefghijklmnopqrstuvwxyz). Второй набор [n-za-m] (который содержит pqrstuvwxyzabcdefghijklmn).
Простая команда для демонстрации вышеуказанной теории:
Полезно при шифровании электронных адресов:
Вывод
tr — это очень мощная команда линукс при использовании пайпов Unix и очень часто используется в скриптах. Дополнительную информацию об этой утилите всегда можно найти в man.
Если у Вас есть какие-либо дополнения, не стесняйтесь пишите в комментариях.
Источник
unixforum.org
Форум для пользователей UNIX-подобных систем
- Темы без ответов
- Активные темы
- Поиск
- Статус форума
Решено: удалить в тексте переносы строк
Модератор: Bizdelnick
Решено: удалить в тексте переносы строк
Сообщение xa3ap » 24.05.2009 15:31
имеется plain text, каким то мудаком разбитый переносами по 80 символов. как удалить эти переносы. но оставить пробелы перед абзацами?

Re: Решено: удалить в тексте переносы строк
Сообщение Nikky » 24.05.2009 15:35
Re: Решено: удалить в тексте переносы строк
Сообщение allez » 24.05.2009 15:57
cat plain.txt | tr «\n» » » > new.txt
tr «\n» » » new.txt
P. S. И не следует называть чудаками на букву «м» незнакомых (и, скорее всего, ничем вам не обязанных) людей только потому, что вам не понравилось форматирование текстового файла. 😉
Re: Решено: удалить в тексте переносы строк
Сообщение xa3ap » 24.05.2009 16:57
cat plain.txt | tr «\n» » » > new.txt
tr «\n» » » new.txt
P. S. И не следует называть чудаками на букву «м» незнакомых (и, скорее всего, ничем вам не обязанных) людей только потому, что вам не понравилось форматирование текстового файла. 
мне надо ещё учитывать новые абзаци (они выглядят как «\n » — новая строка и пробелы в начале строки). по идее должно работать:
cat plain.txt | tr «\n » «***» > new.txt
cat new.txt | tr «\n» » » > tmp.txt
cat tmp.txt | tr «***» «\n» > new.txt
но вместо нормального результата выходит ч.з.ч. кажется, дело в том, что текст ‘выровнен’ — сплошь и рядом встречаются два и больше пробелов вместе.
обьясните, пожалуйста, в чем тут дело? таки напишите скрипт Работающий.
Источник
Как удалить символы переноса строк, стоящие перед определёнными символами
Есть строки вида:
Нужно удалить символа переноса строк с предыдущей строки, если текущая строка начинается не с [a-zA-Z]
Т.е. на выходе должно получится:
Вижу такой вариант:
- получаю номера строк, которые начинаются не с [a-zA-Z]
- сортирую в обратном порядке, чтобы после удаления переноса строки не сбился порядок строк
- вычитаю из нее 1, чтобы получить номер предыдущей строки
- с помощью sed удаляю символ \n в определенной строке
Но у меня символ удаляется только для одной строки:
Подскажите, из-за чего это?
1 ответ 1
можно обойтись одним лишь, например, интерпретатором sed:
конечено, это сработает только в реализации интерпретатора от проекта gnu.
- :a — это метка с именем a
- N — добавить символ новой строки в конец pattern space, затем дописать туда же следующую строку из входного потока
- /\n[^a-zA-Z]/s/\n/ / — общий синтаксис: /шаблон/команда . команда будет выполена для строк, соответствующих шаблону
- \n[^a-zA-Z] — составной шаблон: символ перевода строки, затем символ, соответствующий шаблону [^a-zA-Z] , т.е., «не буква латинского алфавита»
- s/\n/ / — команда s , заменяющая символ перевода строки на пробел
- ta — условный переход (если последняя выполненная команад s осуществила замену) на метку a
предыдущий предложенный мной вариант:
включал ещё две команды, которые, по размышлении, я решил убрать как излишние:
- P — в данном случае выведет pattern space
- D — в данном случае очистит pattern space и запустит нормальный новый цикл (обработку следующей строки из входного потока).
а в чём же у вас ошибка? вот здесь:
при обработке очередной строки сначала будет прочитана следующая (благодаря N ), и только затем будет обработано условие номер-строки команда (пробел тут только для наглядности, обычно его не используют в этом месте, хотя и с пробелом получается вполне корректная конструкция).
к чему приведёт такая логика для вашего случая и в том цикле, когда в $nr будет 4 ? программа для интерпретатора будет выглядеть так: N;4s/\n//g
- начнётся с обработки строки номер 1. сразу же будет (благодаря N ) считана и следующая за ней, условие не выполняется (строка имеет номер 1, это не совпадает с указанной цифрой 4 ).
- дальше будет обработана строка 3. сразу же будет прочитана и следующая за ней. но условие опять не выполнится: строка имеет номер 3, и это опять не совпадает с указанной цифрой 4
- дальше будет обработана строка 5. будет считана и следующая за ней, но, понятно, никаких замен произведено не будет.
- файл кончился. замен не было.
как исправить именно ваш (довольно длинный и медленный) вариант? например, можно команду N переместить внутрь блока с командой s . да и модификатор g можно убрать — он тут излишен:
строки теперь будут читаться последовательно, без «пропусков». дополнительная строка будет считана только один раз — когда будет обрабатываться строка с номером, который будет подставлен из переменной оболочки $
Источник
Как я могу удалить завершающий перевод строки в bash?
Я ищу что-то похожее на Perl chomp . Я ищу команду, которая просто печатает ввод, минус последний символ, если это новая строка:
(Подстановка команд в Bash и Zsh удаляет все завершающие новые строки, но я ищу что-то, что максимально удаляет одну завершающую новую строку.)
Это должно работать:
Скрипт всегда печатает предыдущую строку вместо текущей, а последняя строка обрабатывается по-разному.
Что это делает более подробно:
- NR>1
Распечатать предыдущую строку (кроме первого раза). - END
Также обратите внимание, что это приведет к удалению не более одной пустой строки в конце (без поддержки удаления «one\ntwo\n\n\n» ).
Вы можете использовать perl без chomp :
Но почему бы не использовать chomp себя:
Если вам нужен точный эквивалент chomp , первым методом, который мне приходит в голову, является решение awk, которое уже выложил LatinSuD . Я добавлю некоторые другие методы, которые не реализуют, chomp но реализуют некоторые общие задачи, которые chomp часто используются для.
Когда вы помещаете некоторый текст в переменную, все символы новой строки в конце удаляются. Таким образом, все эти команды выдают одинаковый однострочный вывод:
Если вы хотите добавить какой-либо текст в последнюю строку файла или вывода команды, это sed может быть удобно. С GNU sed и большинством других современных реализаций это работает, даже если ввод не заканчивается новой строкой¹; однако, это не добавит новую строку, если ее еще не было.
¹ Однако это не работает со всеми реализациями sed: sed — это инструмент обработки текста, а файл, который не пуст и не заканчивается символом перевода строки, не является текстовым файлом.
Другой perl подход. Он считывает весь ввод в память, поэтому он не может быть хорошей идеей для больших объемов данных (используйте cuonglm или awk подход для этого):
Я поймал это где-то в репозитории github, но не могу найти где
удаление замыкающего пустые линии-SED
Аннотация
Печатайте строки без новой строки, добавляйте новую строку, только если есть еще одна строка для печати.
Другие решения
Если мы работали с файлом, мы можем просто обрезать один символ из него (если он заканчивается на новой строке):
Это быстрое решение, так как нужно прочитать только один символ из файла, а затем удалить его напрямую ( truncate ), не читая весь файл.
Однако при работе с данными из stdin (потока) все данные должны быть прочитаны. И это «потребляется», как только это прочитано. Нет возврата (как с усечением). Чтобы найти конец потока, нам нужно прочитать его до конца. В этот момент нет возможности вернуться назад к входному потоку, данные уже «использованы». Это означает, что данные должны храниться в некотором виде буфера до тех пор, пока мы не совпадем с концом потока, а затем что-то сделаем с данными в буфере.
Наиболее очевидным из решений является преобразование потока в файл и обработка этого файла. Но вопрос требует какого-то фильтра потока. Не об использовании дополнительных файлов.
переменная
Наивным решением было бы захватить весь ввод в переменную:
Память
Можно загрузить весь файл в память с помощью sed. В sed невозможно избежать завершающего перевода строки на последней строке. GNU sed может не печатать завершающий символ новой строки, но только если в исходном файле его уже нет. Так что нет, простой sed не может помочь.
За исключением GNU awk с -z опцией:
С помощью awk (любой awk) хлебать весь поток, и printf это без завершающего перевода строки.
Загрузка всего файла в память может быть не очень хорошей идеей, поскольку она может занимать много памяти.
Две строки в памяти
В awk мы можем обработать две строки в цикле, сохранив предыдущую строку в переменной и напечатав текущую:
Прямая обработка
Но мы могли бы сделать лучше.
Если мы печатаем текущую строку без новой строки и печатаем новую только тогда, когда существует следующая строка, мы обрабатываем по одной строке за раз, и последняя строка не будет иметь завершающий символ новой строки:
Источник



