- Как удалить большое количество файлов в Linux
- Так как же удалить миллионы файлов из одной папки?
- Подготовка
- Тесты
- Удаление через rm -r
- Удаление через rm ./*
- Удаление через find -exec
- Удаление через find -delete
- Удаление через ls -f и xargs
- Удаление через perl readdir
- Удаление через программу на C readdir + unlink
- Как удалить каталог Linux
- Как удалить каталог Linux
- Выводы
- Как удалить все, кроме 10 новейших файлов в Linux?
Как удалить большое количество файлов в Linux
Удалять файлы можно используя утилиту find, в отличие от ls или rm с указанием маски она не формирует изначально список содержимого каталога, а перебирает файлы по одному.
Посчитать количество файлов можно так
find /home/web/example.com/www/opt/cache/ -type f ¦ wc -l
С -exec rm -f можно запустить процесс удаления файлов (он может занять длительное время)
find /home/web/example.com/www/opt/cache/ -type f -exec rm -f <> \;
Можно попробовать find с опцией delete
find /home/web/example.com/www/opt/cache/ -type f -delete
Скорее всего не даст никакого результата rm с указанием файлов по маске — система при этом до того как начать удаление попытается сформировать полный список файлов, что сделать не получится
Также существует вариант с ls -f, вывод которого перенаправляется в xargs по 100 файлов, затем удаляемых при помощи rm. Может успешно отрабатывать, однако если файлов слишком много вывести список не получится и с ls -f
cd /home/web/example.com/www/opt/cache/ ; ls -f . | xargs -n 100 rm
Самой эффективной командой обычно оказывается find с -exec rm -f, однако все зависит от количества файлов и использовать стоит все представленные варианты (приоритет процессов при удалении имеет смысл максимально понижать используя nice и ionice — алиасы для find или других команд можно добавить в .bashrc пользователя, от имени которого производится удаление).
Источник
Так как же удалить миллионы файлов из одной папки?

Феерическая расстановка точек над i в вопросе удаления файлов из переполненной директории.
Прочитал статью Необычное переполнение жесткого диска или как удалить миллионы файлов из одной папки и очень удивился. Неужели в стандартном инструментарии Linux нет простых средств для работы с переполненными директориями и необходимо прибегать к столь низкоуровневым способам, как вызов getdents() напрямую.
Для тех, кто не в курсе проблемы, краткое описание: если вы случайно создали в одной директории огромное количество файлов без иерархии — т.е. от 5 млн файлов, лежащих в одной единственной плоской директории, то быстро удалить их не получится. Кроме того, не все утилиты в linux могут это сделать в принципе — либо будут сильно нагружать процессор/HDD, либо займут очень много памяти.
Так что я выделил время, организовал тестовый полигон и попробовал различные средства, как предложенные в комментариях, так и найденные в различных статьях и свои собственные.
Подготовка
Так как создавать переполненную директорию на своём HDD рабочего компьютера, потом мучиться с её удалением ну никак не хочется, создадим виртуальную ФС в отдельном файле и примонтируем её через loop-устройство. К счастью, в Linux с этим всё просто.
Создаём пустой файл размером 200Гб
Многие советуют использовать для этого утилиту dd, например dd if=/dev/zero of=disk-image bs=1M count=1M , но это работает несравнимо медленнее, а результат, как я понимаю, одинаковый.
Форматируем файл в ext4 и монтируем его как файловую систему
К сожалению, я узнал об опции -N команды mkfs.ext4 уже после экспериментов. Она позволяет увеличить лимит на количество inode на FS, не увеличивая размер файла образа. Но, с другой стороны, стандартные настройки — ближе к реальным условиям.
Создаем множество пустых файлов (будет работать несколько часов)
Кстати, если в начале файлы создавались достаточно быстро, то последующие добавлялись всё медленнее и медленнее, появлялись рандомные паузы, росло использование памяти ядром. Так что хранение большого числа файлов в плоской директории само по себе плохая идея.
Проверяем, что все айноды на ФС исчерпаны.
Размер файла директории
Теперь попробуем удалить эту директорию со всем её содержимым различными способами.
Тесты
После каждого теста сбрасываем кеш файловой системы
sudo sh -c ‘sync && echo 1 > /proc/sys/vm/drop_caches’
для того чтобы не занять быстро всю память и сравнивать скорость удаления в одинаковых условиях.
Удаление через rm -r
$ rm -r /mnt/test_dir/
Под strace несколько раз подряд (. ) вызывает getdents() , затем очень много вызывает unlinkat() и так в цикле. Занял 30Мб RAM, не растет.
Удаляет содержимое успешно.
Т.е. удалять переполненные директории с помощью rm -r /путь/до/директории вполне нормально.
Удаление через rm ./*
$ rm /mnt/test_dir/*
Запускает дочерний процесс шелла, который дорос до 600Мб, прибил по ^C . Ничего не удалил.
Очевидно, что glob по звёздочке обрабатывается самим шеллом, накапливается в памяти и передается команде rm после того как считается директория целиком.
Удаление через find -exec
$ find /mnt/test_dir/ -type f -exec rm -v <> \;
Под strace вызывает только getdents() . процесс find вырос до 600Мб, прибил по ^C . Ничего не удалил.
find действует так же, как и * в шелле — сперва строит полный список в памяти.
Удаление через find -delete
$ find /mnt/test_dir/ -type f -delete
Вырос до 600Мб, прибил по ^C . Ничего не удалил.
Аналогично предыдущей команде. И это крайне удивительно! На эту команду я возлагал надежду изначально.
Удаление через ls -f и xargs
$ cd /mnt/test_dir/ ; ls -f . | xargs -n 100 rm
параметр -f говорит, что не нужно сортировать список файлов.
Создает такую иерархию процессов:
ls -f в данной ситуации ведет себя адекватнее, чем find и не накапливает список файлов в памяти без необходимости. ls без параметров (как и find ) — считывает список файлов в память целиком. Очевидно, для сортировки. Но этот способ плох тем, что постоянно вызывает rm , чем создается дополнительный оверхед.
Из этого вытекает ещё один способ — можно вывод ls -f перенаправить в файл и затем удалить содержимое директории по этому списку.
Удаление через perl readdir
$ perl -e ‘chdir «/mnt/test_dir/» or die; opendir D, «.»; while ($n = readdir D) < unlink $n >‘ (взял здесь)
Под strace один раз вызывает getdents() , потом много раз unlink() и так в цикле. Занял 380Кб памяти, не растет.
Удаляет успешно.
Получается, что использование readdir вполне возможно?
Удаление через программу на C readdir + unlink
$ gcc -o cleandir cleandir.c
$ ./cleandir
Под strace один раз вызывает getdents() , потом много раз unlink() и так в цикле. Занял 128Кб памяти, не растет.
Удаляет успешно.
Опять — же, убеждаемся, что использовать readdir — вполне нормально, если не накапливать результаты в памяти, а удалять файлы сразу.
Источник
Как удалить каталог Linux
В операционной системе Linux можно выполнить большинство действий через терминал. Удаление каталога Linux — это достаточно простое действие, которое можно выполнить просто открыв файловый менеджер.
Однако в терминале это делается немного быстрее и вы получаете полный контроль над ситуацией. Например, можете выбрать только пустые папки или удалить несколько папок с одним названием. В этой статье мы рассмотрим как удалить каталог Linux через терминал.
Как удалить каталог Linux
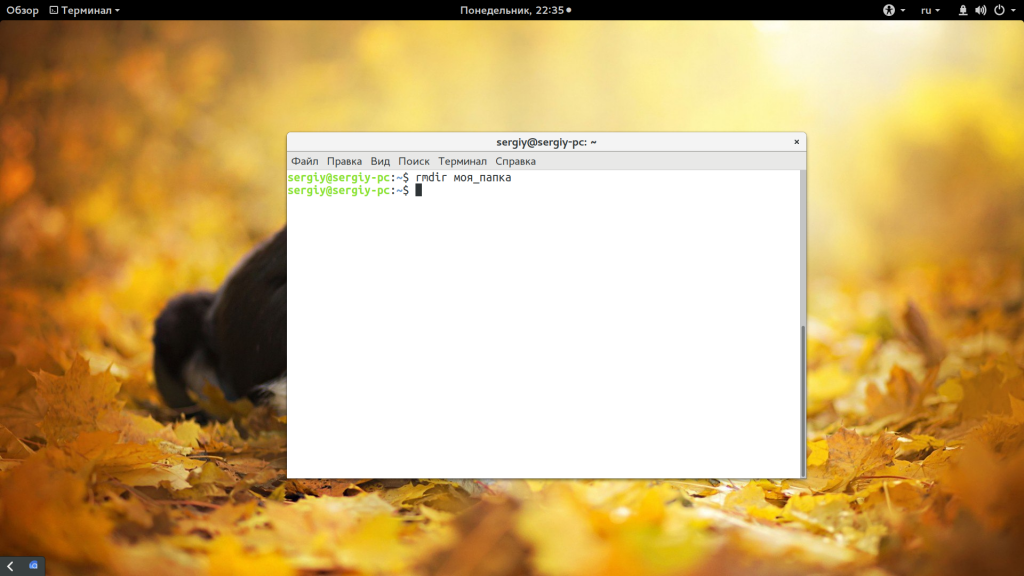
Существует несколько команд, которые вы можете использовать для удаления каталога Linux. Рассмотрим их все более подробно. Самый очевидный вариант — это утилита rmdir. Но с помощью нее можно удалять только пустые папки:
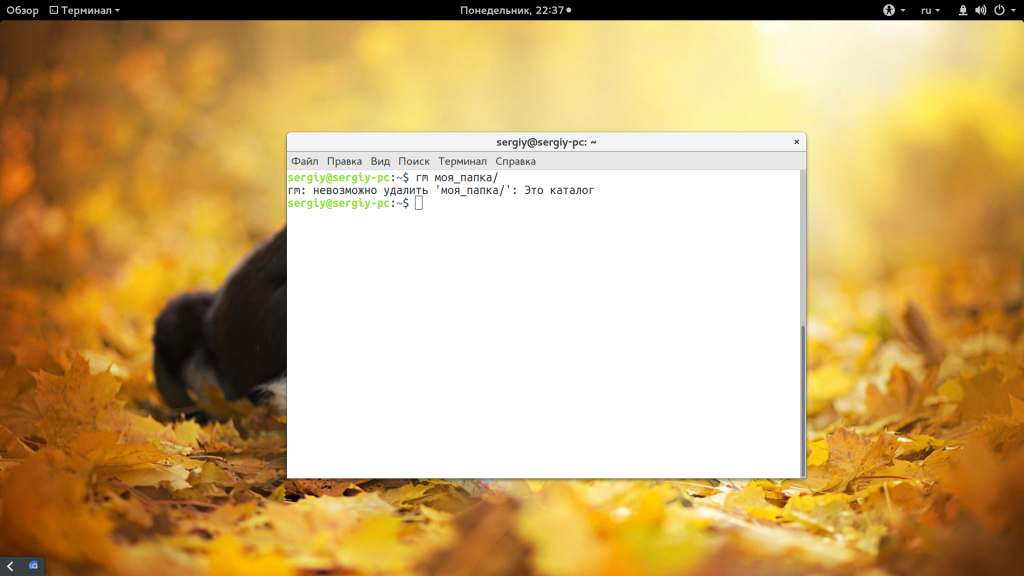
Другая команда, которую можно применить — это rm. Она предназначена для удаления файлов Linux, но может использоваться и для папок если ей передать опцию рекурсивного удаления -r:
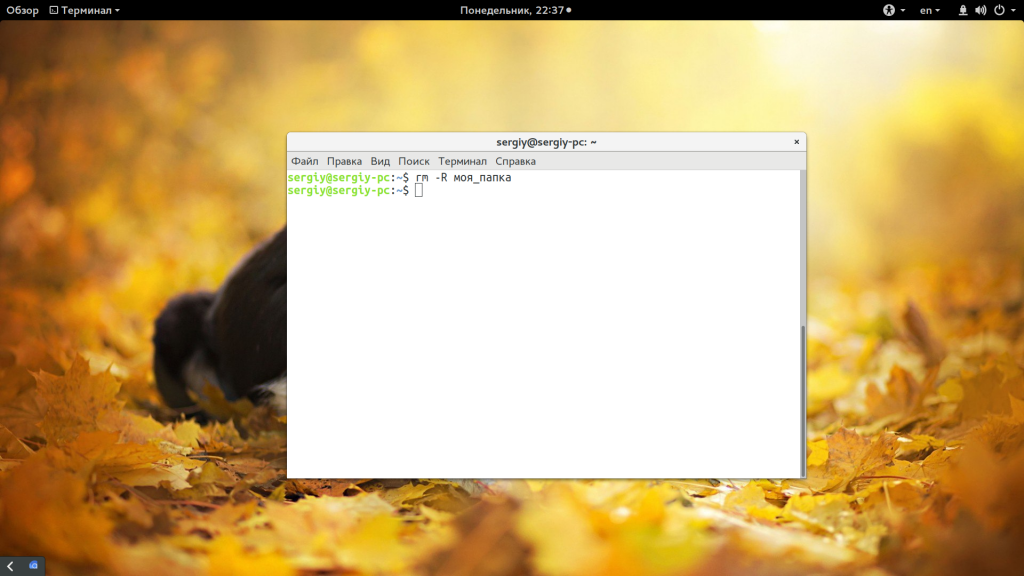
Такая команда уже позволяет удалить непустой каталог Linux. Но, можно по-другому, например, если вы хотите вывести информацию о файлах, которые удаляются:
rm -Rfv моя_папка
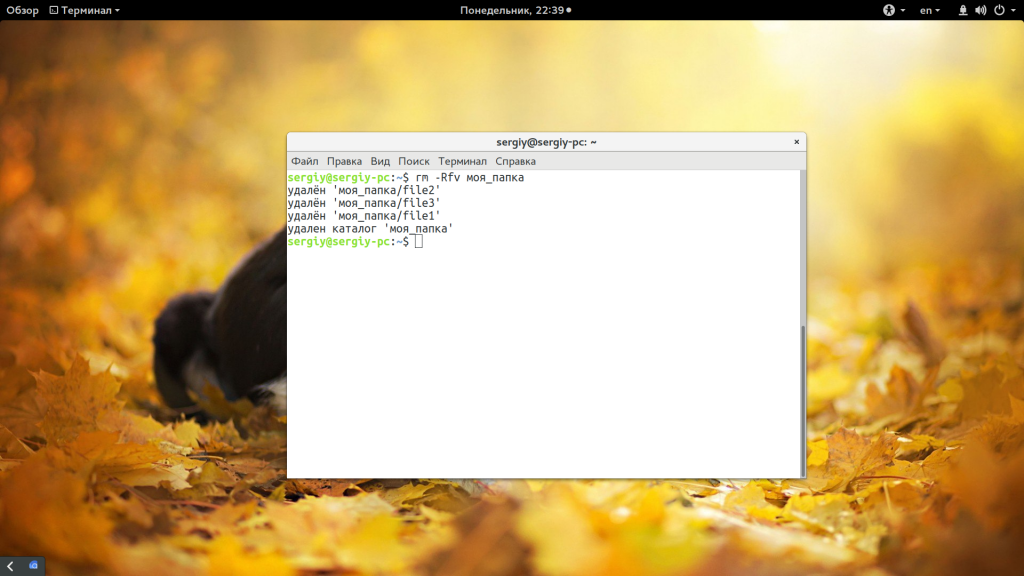
Команда -R включает рекурсивное удаление всех подпапок и файлов в них, -f — разрешает не удалять файлы без запроса, а -v показывает имена удаляемых файлов. В этих примерах я предполагаю что папка которую нужно удалить находится в текущей рабочей папке, например, домашней. Но это необязательно, вы можете указать полный путь к ней начиная от корня файловой системы:
rm -Rfv /var/www/public_html
Читайте подробнее про пути в файловой системе в статье путь к файлу Linux. Теперь вы знаете как удалить непустой каталог в консоли linux, далее усложним задачу, будем удалять папки, которые содержат определенные слова в своем имени:
find . -type d -name «моя_папка» -exec rm -rf <> \;
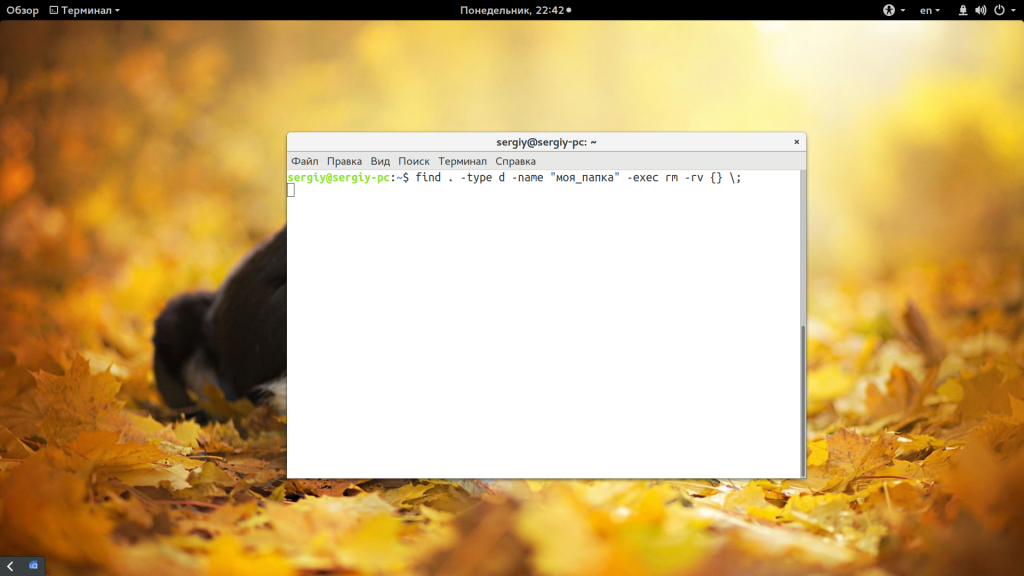
Подробнее про команду find смотрите в отдельной статье. Если кратко, то -type d указывает, что мы ищем только папки, а параметром -name задаем имя нужных папок. Затем с помощью параметра -exec мы выполняем команду удаления. Таким же образом можно удалить только пустые папки, например, в домашней папке:
/ -empty -type d -delete
Как видите, в find необязательно выполнять отдельную команду, утилита тоже умеет удалять. Вместо домашней папки, можно указать любой нужный вам путь:
find /var/www/public_html/ -empty -type d -delete
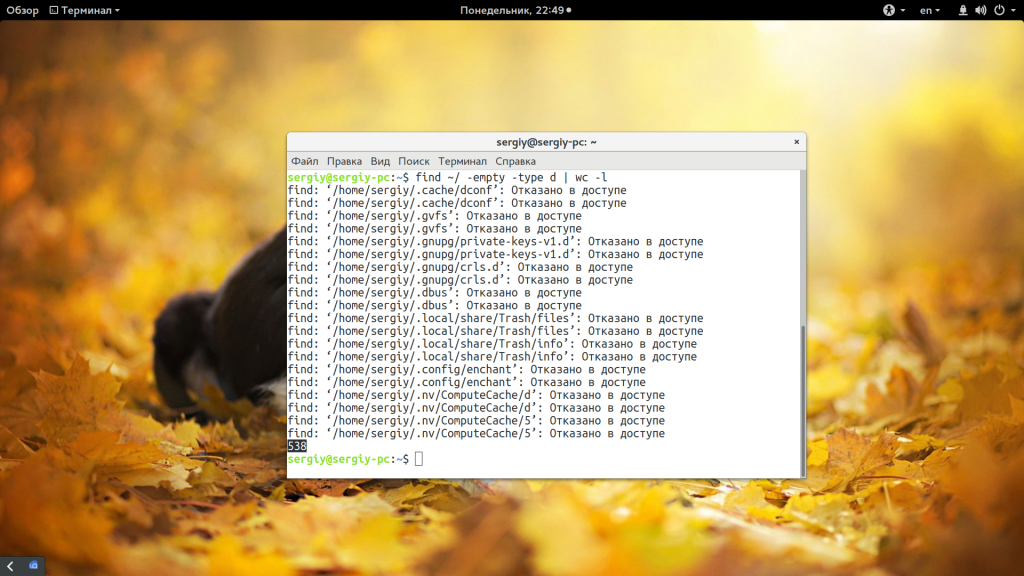
Перед удалением вы можете подсчитать количество пустых папок:
find /var/www/public_html/ -empty -type d | wc -l
Другой способ удалить папку linux с помощью find — использовать в дополнение утилиту xargs. Она позволяет подставить аргументы в нужное место. Например:
/ -type f -empty -print0 | xargs -0 -I <> /bin/rm «<>«
Опция -print0 выводит полный путь к найденному файлу в стандартный вывод, а затем мы передаем его команде xargs. Опция -0 указывает, что нужно считать символом завершения строки \0, а -I — что нужно использовать команду из стандартного ввода.
Если вы хотите полностью удалить папку Linux, так, чтобы ее невозможно было восстановить, то можно использовать утилиту wipe. Она не поставляется по умолчанию, но вы можете ее достаточно просто установить:
sudo apt install wipe
Теперь для удаления каталога Linux используйте такую команду:
Опция -r указывает, что нужно удалять рекурсивно все под папки, -f — включает автоматическое удаление, без запроса пользователя, а -i показывает прогресс удаления. Так вы можете удалить все файлы в папке linux без возможности их восстановления поскольку все место на диске где они были будет несколько раз затерто.
Выводы
В этой статье мы рассмотрели как удалить каталог linux, а также как удалить все файлы в папке linux без возможности их будущего восстановления. Как видите, это очень просто, достаточно набрать несколько команд в терминале. Если у вас остались вопросы, спрашивайте в комментариях!
Источник
Как удалить все, кроме 10 новейших файлов в Linux?
Я пытаюсь держать каталог, полный файлов журнала, управляемым. Ночью я хочу удалить все, кроме 10 самых последних. Как я могу сделать это в одной команде?
Для портативного и надежного решения, попробуйте это:
tail -n -10 Синтаксис в одном из других ответов , кажется , не работать везде (то есть, не на моих системах RHEL5).
И использование $() или « в командной строке rm рискует
- разделение имен файлов пробелами и
- превышение максимального ограничения символов командной строки.
xargs устраняет обе эти проблемы, потому что он автоматически выяснит, сколько аргументов он может передать в пределах ограничения на количество символов, и при этом -d ‘\n’ он будет разбиваться только на границе строки ввода. Технически это все еще может вызвать проблемы для имен файлов с новой строкой в них, но это гораздо реже, чем имена файлов с пробелами, и единственный способ обойти новые строки будет намного сложнее, вероятно, с использованием по крайней мере awk, если не perl.
Если у вас нет xargs (возможно, старых систем AIX?), Вы можете сделать это циклом:
Это будет немного медленнее, потому что он порождает отдельное rm для каждого файла, но все равно будет избегать предостережений 1 и 2 выше (но все еще страдает от новых строк в именах файлов).
Код, который вы хотите включить в свой скрипт
Опция -1 (числовая) печатает каждый файл в одной строке, чтобы быть в безопасности. -f Вариант rm говорит , что игнорировать файлы несуществующие для того, когда ls возвращает ничего.
Если каждый файл создается ежедневно и вы хотите сохранить файлы, созданные в течение последних 10 дней, вы можете сделать следующее:
Или, если каждый файл создан произвольно:
Такой инструмент, как logrotate, сделает это за вас. Это делает управление журналами намного проще. Вы также можете включить дополнительные процедуры очистки, такие как предложенный гало.
Теперь он работает с желаемым путем:
В Bash вы можете попробовать:
Это пропускает 10 новейших файлов, удаляет остальные. logrotate может быть лучше, я просто хочу исправить неправильные ответы, связанные с оболочкой.
Не уверен, что это кому-нибудь поможет, но чтобы избежать потенциальных проблем со странными символами, которые я использовал ls для сортировки, а затем использовать файлы inode для удаления.
Для текущего каталога это сохраняет последние 10 файлов в зависимости от времени модификации.
ls -1tri | awk ‘
Мне нужно было элегантное решение для busybox (роутера), все решения xargs или array были для меня бесполезны — такой команды там не было. find и mtime не правильный ответ, так как речь идет о 10 пунктах и не обязательно 10 днях. Ответ Эспо был самым коротким и чистым и, вероятно, самым неожиданным.
Ошибка с пробелами и когда файлы не должны быть удалены, просто решаются стандартным способом:
Немного больше образовательной версии: мы можем сделать все это, если будем использовать awk по-другому. Обычно я использую этот метод для передачи (возврата) переменных из awk в sh. Поскольку мы все время читаем, что не может быть сделано, я позволю себе не согласиться: вот метод.
Пример для файлов .tar без проблем с пробелами в имени файла. Чтобы проверить, замените «rm» на «ls».
ls -td *.tar перечисляет все файлы .tar, отсортированные по времени. Чтобы применить ко всем файлам в текущей папке, удалите часть «d * .tar»
awk ‘NR>7. пропускает первые 7 строк
print «rm \»» $0 «\»» конструирует строку: rm «имя файла»
eval выполняет это
Поскольку мы используем rm , я бы не использовал вышеуказанную команду в сценарии! Более разумное использование:
В случае использования ls -t команда не нанесет никакого вреда таким глупым примерам, как: touch ‘foo » bar’ и touch ‘hello * world’ . Не то чтобы мы когда-либо создавали файлы с такими именами в реальной жизни!
Примечание. Если бы мы хотели передать переменную sh таким образом, мы бы просто изменили вывод:
установить переменную VarName в значение $1 . Несколько переменных могут быть созданы за один раз. Это VarName становится нормальной переменной sh и впоследствии может быть использовано в скрипте или оболочке. Итак, чтобы создать переменные с помощью awk и вернуть их обратно в оболочку:
Источник



