- Sed для удаления пробелов
- 2 ответа
- Какое «пространство»?
- правильный инструмент для задания
- При настаивании sed
- как удалить все пробелы в тексте?
- Как обрезать начальные и конечные пробелы в каждой строке некоторого вывода?
- пример
- Классы персонажей
- пример
- Linux удалить все пробелы
- Команда tr и ее синтаксис
- 1) Заменить все строчные буквы на заглавные
- 2) Удаление символов с помощью tr
- 3) Удаление ила змена символов НЕ в наборе
- 4) Замена пробелов на табуляцию
- 5) Удаление повторений символов
- 6) Заменить символы из набора на перенос строки
- 7) Генерируем список уникальных слов из файла
- 8) Кодируем символы с помошью ROT
- Вывод
- 12.4. Команды обработки текста
- Примечания
Sed для удаления пробелов
Кто-либо знает, как использовать Sed для удаления всех пробелов в текстовом файле? Я приют, пытаясь использовать «d», удаляет команду, чтобы сделать так, но, может казаться, не понимает это
2 ответа
Можно использовать это для удаления всех пробелов в file :
Какое «пространство»?
Для «удаления всех пробелов» может означать одну из разных вещей:
- удаляют все случаи пробела, кодируют 0x20 .
- удаляют все горизонтальное пространство, включая горизонтальный символ табуляции, » \t «
- удаляют весь пробел, включая новую строку, » \n » и другие
правильный инструмент для задания
, Если sed это не требование по некоторой скрытой причине, лучше используйте правильный инструмент для задания.
команда tr имеет основное использование в переводе (отсюда имя «TR») список символов к списку других символов. Как угловой случай, это может перевести в пустой список символов; опция -d ( —delete ) удалит символы, которые появляются в списке.
список символов может использовать классы символов в [. ] синтаксис.
- tr -d ‘ ‘ no-spaces.txt
- tr -d ‘[:blank:]’ no-spaces.txt
- tr -d ‘[:space:]’ no-spaces.txt
При настаивании sed
С sed, [. ] синтаксис для классов символов должен быть объединен с синтаксисом для наборов символов в regexps, [. ] , приведении к несколько запутывающему [[. ]] :
Источник
как удалить все пробелы в тексте?
Через командную строку стандартными средствами. Подскажите, пожалуйста.

Не могли бы Вы мне разъяснить суть каждой составляющей этой команды?
Нет, вы, кажется, не поняли. Уже есть файл с текстом, как в нем выпилить все пробелы?

Вообще все пробелы и только пробелы:
Все пробелы и символы табуляции так:
Только символы табуляции так :
Замена нескольких пробелов одним:
В данном случае от 2 до 5 стоящих подряд пробелов заменяются одним.
Какой-то вырвиглазый синтаксис у этого sed)
Это регулярные выражения, при чём простые.
- s/// — замена
- после «s/ и перед \ < указан символ, в данном случае пробел, ' ' - можно и так
- \ <2,5\>— число повторений блоков символов, указанные перед интервалом
- \ — экранирование, что бы < и >не рассматривались как конструкции интерпретатоа (bash)
- g — все включения в файла
- -i — работать с файлом

Ну или простой способ проникнуться:
\ — экранирование, что бы < и >не рассматривались как конструкции интерпретатоа (bash)
в пределах «» они и не рассматриваются. просто posix re требуют их экранировать
в extended posix re их не нужно экранировать, для этого у сед есть ключик -r
не надо трясти своим невежеством в очередной раз
Я читал про это. Мне не нужен патч Бармина-все пока не так плохо
Источник
Как обрезать начальные и конечные пробелы в каждой строке некоторого вывода?
Я хотел бы удалить все начальные и конечные пробелы и вкладки из каждой строки в выводе.
Есть ли простой инструмент, как trim я мог бы передать свой вывод?
Обрезает начальные и конечные пробелы или символы табуляции 1, а также сжимает последовательности табуляций и пробелов в один пробел.
Это работает, потому что когда вы назначаете что-то одному из полей , awk перестраивает всю запись (как напечатано print ), объединяя все поля ( $1 , . $NF ) с OFS (пробел по умолчанию).
1 (и, возможно, другие пустые символы в зависимости от локали и awk реализации)
Команду можно сжать примерно так, если вы используете GNU sed :
пример
Вот приведенная выше команда в действии.
Вы можете использовать, hexdump чтобы подтвердить, что sed команда удаляет нужные символы правильно.
Классы персонажей
Вы также можете использовать имена классов символов вместо буквального перечисления наборов, таких как [ \t] :
пример
Большинство инструментов GNU, использующих регулярные выражения (регулярные выражения), поддерживают эти классы.
Использование их вместо литеральных наборов всегда кажется пустой тратой пространства, но если вы обеспокоены тем, что ваш код переносим, или вам приходится иметь дело с альтернативными наборами символов (например, международными), то вы, вероятно, захотите использовать имена классов вместо.
Источник
Linux удалить все пробелы

Команда tr (translate) используется в Linux в основном для преобразования и удаления символов. Она часто находит применение в скриптах обработки текста. Ее можно использовать для преобразования верхнего регистра в нижний, сжатия повторяющихся символов и удаления символов.
Команда tr требует два набора символов для преобразований, а также может использоваться с другими командами, использующими каналы (пайпы) Unix для расширенных преобразований.
В этой статье мы узнаем, как использовать команду tr в операционных системах Linux и рассмотрим некоторые примеры.
Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
\NNN -> восмеричные (OCT) символы NNN (1 до 3 цифр)
\\ -> обратный слеш (экранированный)
\n -> новая строка (new line)
\r -> перенос строки (return)
\t -> табуляция (horizontal tab)
[:alnum:] -> все буквы и цифры
[:alpha:] -> все буквы
[:blank:] -> все пробелы
[:cntrl:] -> все управляющие символы (control)
[:digit:] -> все цифры
[:lower:] -> все буквы в нижнем регистре (строчные)
[:upper:] -> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
Вот некоторые опции:
-c , -C , —complement -> удалить все символы, кроме тех, что в первом наборе
-d , —delete -> удалить символы из первого набора
-s , —squeeze-repeats -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы [:lower:] [:upper:] или «a-z» «A-Z» для замены всех символов.
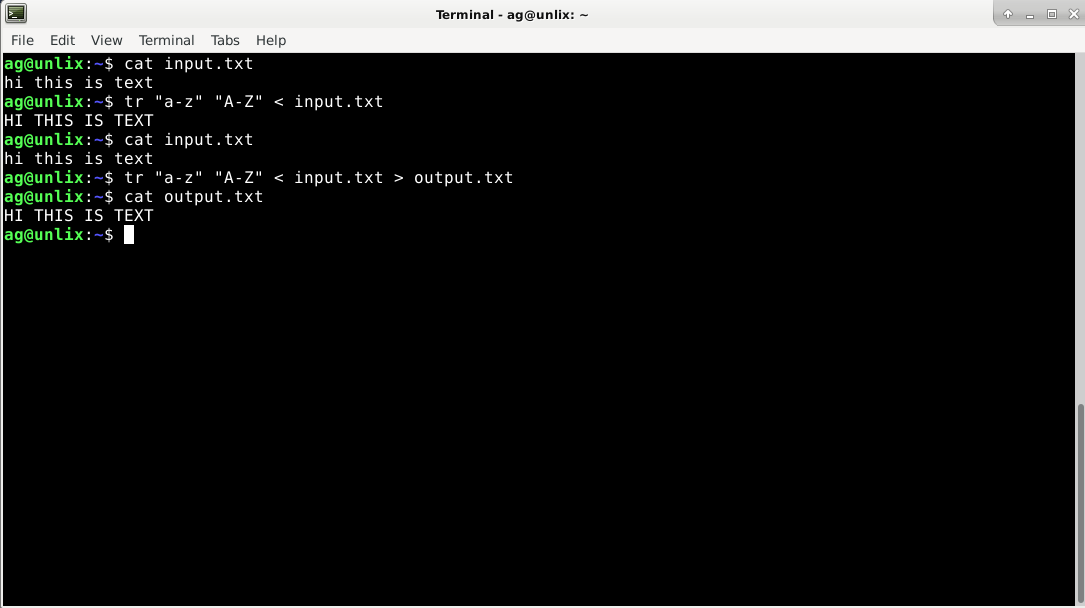
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
А сейчас сделаем замену из файла input.txt
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
2) Удаление символов с помощью tr
Опция -d используется для удаления всех символов, которые указаны в наборе символов.
Следующая команда удалит все символы из этого набора ‘aei’.
Следующая команда удалит все цифры в тексте. Будем использовать набор [:digit:] , чтобы определить все цифры.
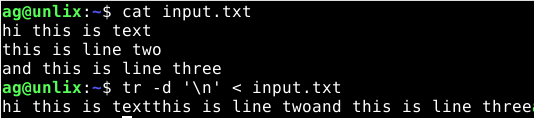
А вот пример команд, которыми можно удалить переносы на новые строки
3) Удаление ила змена символов НЕ в наборе
С помощью параметра -c Вы можете сказать tr заменить все символы, которые Вы не указали в наборе. Приведем пример.
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)

4) Замена пробелов на табуляцию
Для указания пробелов используем — [:space:] , а для табуляции — \t.
5) Удаление повторений символов
Это делает параметр -s . Рассмотрим пример удаления повторов знаков.
Или заменим повторения на символ решетки
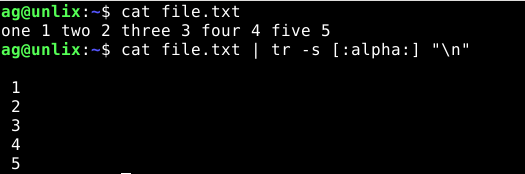
6) Заменить символы из набора на перенос строки
Сделаем так, чтобы все буквы были заменены на перенос новой строки:
7) Генерируем список уникальных слов из файла
Это иногда очень полезная команда, когда необходимо определить количество повторений и вывести уникальные слова из файла:
8) Кодируем символы с помошью ROT
ROT (Caesar Cipher) — это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор [a-z] (это значит abcdefghijklmnopqrstuvwxyz). Второй набор [n-za-m] (который содержит pqrstuvwxyzabcdefghijklmn).
Простая команда для демонстрации вышеуказанной теории:
Полезно при шифровании электронных адресов:
Вывод
tr — это очень мощная команда линукс при использовании пайпов Unix и очень часто используется в скриптах. Дополнительную информацию об этой утилите всегда можно найти в man.
Если у Вас есть какие-либо дополнения, не стесняйтесь пишите в комментариях.
Источник
12.4. Команды обработки текста
Сортирует содержимое файла, часто используется как промежуточный фильтр в конвейерах. Эта команда сортирует поток текста в порядке убывания или возрастания, в зависимости от заданных опций. Ключ -m используется для сортировки и объединения входных файлов. В странице info перечислено большое количество возможных вариантов ключей. См. Пример 10-9, Пример 10-10 и Пример A-9.
Топологическая сортировка, считывает пары строк, разделенных пробельными символами, и выполняет сортировку, в зависимости от заданного шаблона.
Удаляет повторяющиеся строки из отсортированного файла. Эту команду часто можно встретить в конвейере с командой sort.
Ключ -c выводит количество повторяющихся строк.
Команда sort INPUTFILE | uniq -c | sort -nr выводит статистику встречаемости строк в файле INPUTFILE (ключ -nr, в команде sort, означает сортировку в порядке убывания). Этот шаблон может с успехом использоваться при анализе файлов системного журнала, словарей и везде, где необходимо проанализировать лексическую структуру документа.
Пример 12-8. Частота встречаемости отдельных слов
Команда expand преобразует символы табуляции в пробелы. Часто используется в конвейерной обработке текста.
Команда unexpand преобразует пробелы в символы табуляции. Т.е. она является обратной по отношению к команде expand.
Предназначена для извлечения отдельных полей из текстовых файлов. Напоминает команду print $N в awk, но более ограничена в своих возможностях. В простейших случаях может быть неплохой заменой awk в сценариях. Особую значимость, для команды cut, представляют ключи -d (разделитель полей) и -f (номер(а) поля(ей)).
Использование команды cut для получения списка смонтированных файловых систем:
Использование команды cut для получения версии ОС и ядра:
Использование команды cut для извлечения заголовков сообщений из электронных писем:
Использование команды cut при разборе текстового файла:
cut -d ‘ ‘ -f2,3 filename эквивалентно awk -F'[ ]’ ‘< print $2, $3 >‘ filename
Используется для объединения нескольких файлов в один многоколоночный файл.
Может рассматриваться как команда, родственная команде paste. Эта мощная утилита позволяет объединять два файла по общему полю, что представляет собой упрощенную версию реляционной базы данных.
Команда join оперирует только двумя файлами и объедияет только те строки, которые имеют общее поле (обычно числовое), результат объединения выводится на stdout. Объединяемые файлы должны быть отсортированы по ключевому полю.
 |
 |
|
|
 |
|
 |



