- Как удалить (удалить) символические ссылки в Linux
- How to Remove (Delete) Symbolic Links in Linux
- В этом руководстве мы покажем вам , как удалить символические ссылки в системах Linux / UNIX с использованием rm , unlink и find команды.
- Прежде чем вы начнете
- Удалить символические ссылки с rm
- Удалить символические ссылки с unlink
- Найти и удалить неработающие символические ссылки
- Вывод
- Команда tr в Linux с примерами
- Команда tr и ее синтаксис
- 1) Заменить все строчные буквы на заглавные
- 2) Удаление символов с помощью tr
- 3) Удаление ила змена символов НЕ в наборе
- 4) Замена пробелов на табуляцию
- 5) Удаление повторений символов
- 6) Заменить символы из набора на перенос строки
- 7) Генерируем список уникальных слов из файла
- 8) Кодируем символы с помошью ROT
- Вывод
- C.1. Sed
- Изучаем команды Linux: команда sed Linux
- Команда sed в Linux
- Установка
- Концепции
- Как работает sed
- Адреса sed
- Синтаксис
- Особенности адресов, предающихся утилите «sed»
- Использование специальных символов:
- Регулярные выражения
- Использование переменных в выражениях sed
- Основные команды Sed
- Замена слова в файле
- Замена слова в файле и вывод результата в другой файл
- Замена слова в нескольких файлах одновременно
- Отбросить всё, что левее определённого слова
- Отбросить всё, что правее определённого слова
- Экранирование символов в sed
- Два условия одновременно в Sed
- Удаление переходов на новую строку
- Удалить всё после определённой строки
- Удаление текста
- Замена текста
- Примеры использования sed
- В окружении UNIX: конвертируем новые строки DOS (CR/LF) в формат Unix.
Как удалить (удалить) символические ссылки в Linux
How to Remove (Delete) Symbolic Links in Linux
В этом руководстве мы покажем вам , как удалить символические ссылки в системах Linux / UNIX с использованием rm , unlink и find команды.

Символическая ссылка, также известная как символическая ссылка, представляет собой специальный тип файла, который указывает на другой файл или каталог. Это что-то вроде ярлыка в Windows. Символьная ссылка может указывать на файл или каталог в той же или другой файловой системе или разделе.
Прежде чем вы начнете
Чтобы удалить символическую ссылку, вам нужно иметь права на запись в каталог, который содержит символическую ссылку. В противном случае вы получите ошибку «Операция не разрешена».
Когда вы удаляете символическую ссылку, файл, на который она указывает, не затрагивается.
Используйте ls -l команду, чтобы проверить, является ли данный файл символической ссылкой, и найти файл или каталог, на который указывает символическая ссылка.
Первый символ «l» указывает, что файл является символической ссылкой. Символ «->» показывает файл, на который указывает символическая ссылка.
Удалить символические ссылки с rm
Команда rm удаляет указанные файлы и каталоги.
Чтобы удалить символическую ссылку, вызовите rm команду, за которой следует символическое имя ссылки в качестве аргумента:
В случае успеха команда завершается с нуля и не выводит никаких данных.
С rm его помощью вы можете удалить более одной символической ссылки одновременно. Для этого передайте имена символических ссылок в качестве аргументов через пробел:
Чтобы получить запрос перед удалением символической ссылки, используйте -i параметр:
Для подтверждения типа y и нажмите Enter .
Если символическая ссылка указывает на каталог, не добавляйте / завершающий слеш в конце. В противном случае вы получите ошибку:
Если имя аргумента заканчивается на / , rm команда предполагает, что файл является каталогом. Ошибка возникает потому, что при использовании без параметра -d или -r , rm невозможно удалить каталоги.
Чтобы быть в безопасности, никогда не -r вариант при удалении символических ссылок с rm . Например, если вы наберете:
Содержимое целевого каталога будет удалено.
Удалить символические ссылки с unlink
Чтобы удалить символическую ссылку, запустите unlink команду с именем символической ссылки в качестве аргумента:
Если команда выполняется успешно, она не отображает вывод.
Не добавляйте / косую черту в конце имени символической ссылки, потому что unlink не можете удалить каталоги.
Найти и удалить неработающие символические ссылки
Если вы удалите или переместите исходный файл в другое место, символический файл останется висящим (поврежденным).
Команда выведет список всех неработающих ссылок в каталоге и его подкаталогах.
Если вы хотите исключить символические ссылки, содержащиеся в подкаталогах, передайте -maxdepth 1 параметр find :
После того, как вы найдете нарушенные символические ссылки, вы можете вручную удалить их с rm или unlink или использовать -delete опцию в find команде:
Вывод
Чтобы удалить символическую ссылку, используйте команду rm или, unlink за которой следует имя символической ссылки в качестве аргумента. При удалении символической ссылки, указывающей на каталог, не добавляйте косую черту к имени символической ссылки.
Команда tr в Linux с примерами

Команда tr (translate) используется в Linux в основном для преобразования и удаления символов. Она часто находит применение в скриптах обработки текста. Ее можно использовать для преобразования верхнего регистра в нижний, сжатия повторяющихся символов и удаления символов.
Команда tr требует два набора символов для преобразований, а также может использоваться с другими командами, использующими каналы (пайпы) Unix для расширенных преобразований.
В этой статье мы узнаем, как использовать команду tr в операционных системах Linux и рассмотрим некоторые примеры.
Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
\NNN -> восмеричные (OCT) символы NNN (1 до 3 цифр)
\\ -> обратный слеш (экранированный)
\n -> новая строка (new line)
\r -> перенос строки (return)
\t -> табуляция (horizontal tab)
[:alnum:] -> все буквы и цифры
[:alpha:] -> все буквы
[:blank:] -> все пробелы
[:cntrl:] -> все управляющие символы (control)
[:digit:] -> все цифры
[:lower:] -> все буквы в нижнем регистре (строчные)
[:upper:] -> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
Вот некоторые опции:
-c , -C , —complement -> удалить все символы, кроме тех, что в первом наборе
-d , —delete -> удалить символы из первого набора
-s , —squeeze-repeats -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы [:lower:] [:upper:] или «a-z» «A-Z» для замены всех символов.
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
А сейчас сделаем замену из файла input.txt
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
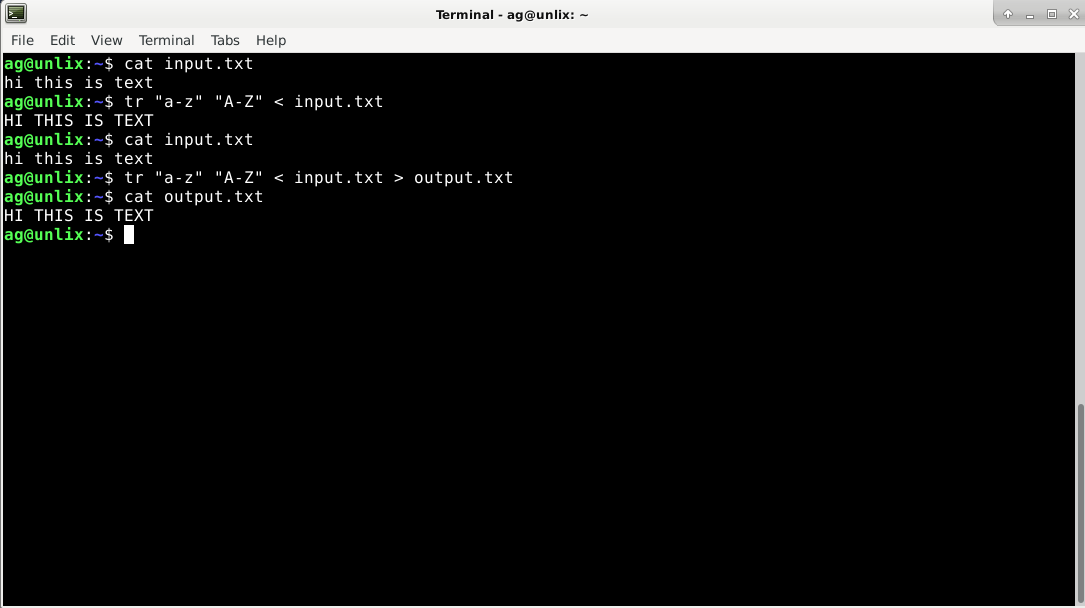
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
2) Удаление символов с помощью tr
Опция -d используется для удаления всех символов, которые указаны в наборе символов.
Следующая команда удалит все символы из этого набора ‘aei’.
Следующая команда удалит все цифры в тексте. Будем использовать набор [:digit:] , чтобы определить все цифры.
А вот пример команд, которыми можно удалить переносы на новые строки
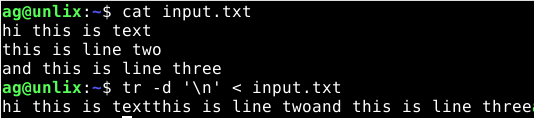
3) Удаление ила змена символов НЕ в наборе
С помощью параметра -c Вы можете сказать tr заменить все символы, которые Вы не указали в наборе. Приведем пример.
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)

4) Замена пробелов на табуляцию
Для указания пробелов используем — [:space:] , а для табуляции — \t.
5) Удаление повторений символов
Это делает параметр -s . Рассмотрим пример удаления повторов знаков.
Или заменим повторения на символ решетки
6) Заменить символы из набора на перенос строки
Сделаем так, чтобы все буквы были заменены на перенос новой строки:
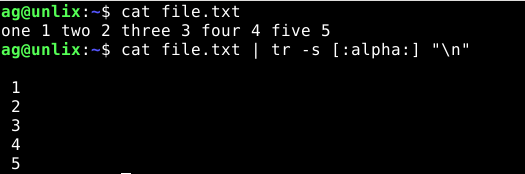
7) Генерируем список уникальных слов из файла
Это иногда очень полезная команда, когда необходимо определить количество повторений и вывести уникальные слова из файла:
8) Кодируем символы с помошью ROT
ROT (Caesar Cipher) — это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор [a-z] (это значит abcdefghijklmnopqrstuvwxyz). Второй набор [n-za-m] (который содержит pqrstuvwxyzabcdefghijklmn).
Простая команда для демонстрации вышеуказанной теории:
Полезно при шифровании электронных адресов:
Вывод
tr — это очень мощная команда линукс при использовании пайпов Unix и очень часто используется в скриптах. Дополнительную информацию об этой утилите всегда можно найти в man.
Если у Вас есть какие-либо дополнения, не стесняйтесь пишите в комментариях.
C.1. Sed
Sed — это неинтерактивный строчный редактор. Он принимает текст либо с устройства stdin , либо из текстового файла, выполняет некоторые операции над строками и затем выводит результат на устройство stdout или в файл. Как правило, в сценариях, sed используется в конвейерной обработке данных, совместно с другими командами и утилитами.
Sed определяет, по заданному адресному пространству, над какими строками следует выполнить операции. [66] Адресное пространство строк задается либо их порядковыми номерами, либо шаблоном. Например, команда 3d заставит sed удалить третью строку, а команда /windows/d означает, что все строки, содержащие «windows», должны быть удалены.
Из всего разнообразия операций, мы остановимся на трех, используемых наиболее часто. Это p — печать (на stdout ), d — удаление и s — замена.
Таблица C-1. Основные операции sed
| Операция | Название | Описание |
|---|---|---|
| [диапазон строк]/p | Печать [указанного диапазона строк] | |
| [диапазон строк]/d | delete | Удалить [указанный диапазон строк] |
| s/pattern1/pattern2/ | substitute | Заменить первое встреченное соответствие шаблону pattern1, в строке, на pattern2 |
| [диапазон строк]/s/pattern1/pattern2/ | substitute | Заменить первое встреченное соответствие шаблону pattern1, на pattern2, в указанном диапазоне строк |
| [диапазон строк]/y/pattern1/pattern2/ | transform | заменить любые символы из шаблона pattern1 на соответствующие символы из pattern2, в указанном диапазоне строк (эквивалент команды tr) |
| g | global | Операция выполняется над всеми найдеными соответствиями внутри каждой из заданных строк |
 |
|
| Операция | Описание |
|---|---|
| 8d | Удалить 8-ю строку. |
| /^$/d | Удалить все пустые строки. |
| 1,/^$/d | Удалить все строки до первой пустой строки, включительно. |
| /Jones/p | Вывести строки, содержащие «Jones» (с ключом -n). |
| s/Windows/Linux/ | В каждой строке, заменить первое встретившееся слово «Windows» на слово «Linux». |
| s/BSOD/stability/g | В каждой строке, заменить все встретившиеся слова «BSOD» на «stability». |
| s/ *$// | Удалить все пробелы в конце каждой строки. |
| s/00*/0/g | Заменить все последовательности ведущих нулей одним символом «0». |
| /GUI/d | Удалить все строки, содержащие «GUI». |
| s/GUI//g | Удалить все найденые «GUI», оставляя остальную часть строки без изменений. |
Замена строки пустой строкой, эквивалентна удалению части строки, совпадающей с шаблоном. Остальная часть строки остается без изменений. Например, s/GUI// , изменит следующую строку
Символ обратного слэша представляет символ перевода строки, как символ замены. В этом случае, замещающее выражение продолжается на следующей строке.
Эта инструкция заменит начальные пробелы в строке на символ перевода строки. Ожидаемый результат — замена отступов в начале параграфа пустыми строками.
Указание диапазона строк, предшествующее одной, или более, инструкции может потребовать заключения инструкций в фигурные скобки, с соответствующими символами перевода строки.
В этом случае будут удалены только первые из нескольких, идущих подряд, пустых строк. Это может использоваться для установки однострочных интервалов в файле, оставляя, при этом, пустые строки между параграфами.
 |
| В случае использования символа | (pipe) в качестве разделителя спецсимволы экранировать не нужно, но при этом регулярные выражения работать не будут |
sed ‘s|root |Admin:|g’ имя_файла
Регулярные выражения
Убрать все цыфры из вывода:
Продублировать отсеченное значение:
echo`123 abc` | sed ‘s/77*/&-&/’
Регулярное выражение 4* определят 0 или больше цыфр.
Регулярное выражение 44* определят 1 или больше цыфр.
Если Вам нужно использовать первое слово из строки текста — обзначьте его экранированой цыфрой:
echo’abcd qwer zxc 123’| sed ‘s/([a-z]*).*/1/’
Для того что бы поменять местами первое и второе слово — воспользуйтесь следующей конструкцией:
Пробел в левой части выражения может быть заменен на любой другой разделитель.
echo’abcd qwer zxc 123’| sed -r’s/([a-z]+) ([a-z]+)/2 1/’
echo’abcd_qwer_zxc_123’| sed -r’s/([a-z]+)_([a-z]+)/2**_**1/’echo’abcd_qwer_zxc_123’| sed -r’s/([a-z]+)**_**([a-z]+)/2 1/’
Замена текства между двумя словами:
sed -ure’s/**word1**.+?**word2**/**word1** замена **word2**/g’-i файл
Использование переменных в выражениях sed
При написании bash скриптов мы используем переменные. Иногда возникает необходимость использовать эти переменные в выражениях sed.
Самый простой подход — использование двойных кавычек для обертки выражения:
Двойные кавычки не сработают, есть в $var1 или $var2 присутвствуют спецсимволы. Лучше всего — исключать переменные из обертки:
Основные команды Sed
Для того чтобы применить SED достаточно ввести в командную строку
echo ice | sed s/ice/fire/
Замена слова в файле
Обычно SED применяют к файлам, например к логам или конфигам.
Предположим, что у нас есть файл input.txt следующего содержания
Here is a StringHere is an IntegerHere is a Float
Мы хотим заменить слово Here на There
sed ‘s/Here/There/’ input.txt
Результат будет выведен в консоль:
There is a String
There is an Integer
There is a Float
Если нужно не вывести в консоль а изменить содержание файла — используем опцию -i
sed -i ‘s/Here/There/’ input.txt
В этом случае перепишется исходный файл input.txt
Рассмотрим пример посложнее. Файл input.txt теперь выглядит так:
Here is an Apple. Here is a Pen. Here is an ApplePenInteger is HereHere is a FloatHere is a Pen. Here is a Pineapple. Here is a PineapplePen
sed ‘s/Here/There/’ input.txt
Как Вы сейчас увидите, замена произойдёт только по одному разу в строке
There is an Apple. Here is a Pen. Here is an ApplePen
Integer is There
There is a Float
There is a Pen. Here is a Pineapple. Here is a PineapplePen
Чтобы заменить все слова нужна опция g
sed ‘s/Here/There/g’ input.txt
There is an Apple. There is a Pen. There is an ApplePen
Integer is There
There is a Float
There is a Pen. There is a Pineapple. There is a PineapplePen
Замена слова в файле и вывод результата в другой файл
Та же замена, но с выводом в новый текстовый файл, который мы назовём output:
sed ‘s/Here/There/’ input.txt > output.txt
Замена слова в нескольких файлах одновременно
Если нужно обработать сразу несколько файлов: например файл 1.txt с содержанием
First File: Here
И файл 2.txt с содержанием
Second File: Here
Это можно сделать используя *.txt
sed ‘s/Here/There/’ *.txt > output.txt
На выходе файл output.txt будет выглядеть так
First File: ThereSecond File: There
Отбросить всё, что левее определённого слова
Предположим, что у нас есть файл input.txt следующего содержания
Here is a String it has a NameHere is an Integer it has a NameHere is a Float it has a Name
Мы хотим отбросить всё, что находится левее слова it, включая слово it, и записать в файл.
sed ‘s/^.*it//’ input.txt > output.txt
^ означает, что мы стартуем с начала строки Результат:
has a Name
has a Name
has a Name
Для доступности объясню синтаксис сравнив две команды. Посмотрите внимательно, когда мы заменяем слово Here на There.
There находится между двумя слэшами. Раскрашу их для наглядности в зелёный и красный.
sed ‘s/Here /There /‘
А когда мы хотим удалить что-то, мы сначала описываем, что мы хотим удалить. Например, всё от начала строки до слова it.
Теперь в правой части условия, где раньше была величина на замену, мы ничего не пишем, т.е. заменяем на пустое место. Надеюсь, логика понятна.
sed ‘s/^.*it / /‘ > output.txt
Отбросить всё, что правее определённого слова
Предположим, что у нас есть файл input.txt следующего содержания
Here is a String / it has a NameHere is an Integer / it has a NameHere is a Float / it has a Name
Мы хотим отбросить всё, что находится правее слова is, включая слово is, и записать в файл.
sed ‘s/is.*//’ > output.txt
Экранирование символов в sed
Специальные символы экранируются с помощью
Предположим, что у нас есть файл input.txt следующего содержания
Here is a String / it has a NameHere is an Integer / it has a NameHere is a Float it / has a Name
Мы хотим отбросить всё, что находится левее /a, включая /a, и записать в файл.
sed ‘s/^.*/a//’ > output.txt
В результате получим ошибку
-e expression #1, char 15: unknown option to `s’
Чтобы команда заработала нужно добавить перед /
sed ‘s/^.* /a//’ > output.txt
Here is a StringHere is an IntegerHere is a Float
Два условия одновременно в Sed
Предположим, что у нас есть файл input.txt следующего содержания
Here is a String /b it has a NameHere is an Integer /b it has a NameHere is a Float /b it has a Name
Мы хотим отбросить всё, что находится левее /b, включая /b, и всё, что правее has.
Таким образом, в каждой строчке должно остаться только слово it.
Нужно учесть необходимость экранирования специального символа / а также мы хотим направить вывод в файл.
sed ‘s/^.*/b// s/has.*//’ input.txt > output.txt
Удаление переходов на новую строку
Удалить всё после определённой строки
Допустим Вы хотите удалить все строки после третьей
sed 3q input.txt > output.txt
Удаление текста
Можно легко удалить текст, который мы выводили в предыдущем примере, заменив команду “p” на команду “d”. Команда «-n» нам больше не нужна, потому что при использовании команды удаления утилита выводит все, что не удалено. Это позволяет нам видеть, что происходит. Изменим последнюю команду из предыдущего раздела так, чтобы она удаляла все нечетные строки, начиная с первой. В результате мы должны получить все строки, которые не были выведены в прошлый раз.
2d’ BSD All rights reserved. Redistribution and use in source and binary forms, with or without are met: notice, this list of conditions and the following disclaimer. notice, this list of conditions and the following disclaimer in the 3. Neither the name of the University nor the names of its contributors without specific prior written permission. . . . . . .
При этом исходный файл не меняется. Результаты редактирования просто выводятся на экран. Если результат нужно сохранить, можно перенаправить стандартный вывод в файл:
2d’ BSD > everyother.txt
Открыв этот файл командой cat, мы увидим тот же результат, который был на экране после выполнения предыдущей команды. По умолчанию sed не редактирует исходный файл в целях безопасности. Это можно изменить при помощи опции «-i», которая означает редактирование на месте. Исходный файл будет изменен. Давайте попробуем отредактировать только что созданный нами файл «everyother.txt». Снова удалим все нечетные строки:
При помощи cat можно убедиться, что файл был отредактирован.
Опция “-i” может быть опасной, но утилита предоставляет возможность создания резервной копии перед редактированием. Для этого сразу после опции “-i” укажите расширение резервной копии “.bak”:
Будет создан файл резервной копии с расширением “bak”, а затем выполнено редактирование исходного файла.
Замена текста
Чаще всего sed используется для замены текста. Редактор позволяет осуществлять поиск текста по шаблону при помощи регулярных выражений. А затем заменять найденный текст. В простейшем варианте можно заменить одно слово на другое, используя следующий синтаксис:
Параметр «s» – это команда замены. Три слэша (/) нужны для разделения различных текстовых полей. Если вам удобно, вы можете использовать для этого другие символы. Например, если нам нужно изменить имя веб-сайта, удобнее использовать другой разделитель, так как URL содержат слэши. Воспользуемся командой echo для передачи примера:
echo «http://www.example.com/index.html» | sed ‘s_com/index_org/home_’ http://www.example.org/home.html
Здесь секция «com/index» заменяется на «org/home». В качестве разделителя используется нижнее подчеркивание «_». Не забудьте про последний разделитель, иначе sed выдаст ошибку.
echo «http://www.example.com/index.html» | sed ‘s_com/index_org/home’ sed: -e expression #1, char 22: unterminated `s’ command
Создадим файл для отработки замен:
echo «this is the song that never ends yes, it goes on and on, my friend some people started singing it not knowing what it was and they’ll continue singing it forever just because…» > annoying.txt
Теперь заменим «on» на «forward»
sed ‘s/on/forward/’ annoying.txt this is the sforwardg that never ends yes, it goes forward and on, my friend some people started singing it not knowing what it was and they’ll cforwardtinue singing it forever just because…
Стоит обратить внимание на ряд моментов. Во-первых, мы заменяем шаблоны, а не слова. “on” в слове “song” было заменено на “forward”. Во-вторых, второе “on” в строке 2 заменено не было. Это произошло потому, что по умолчанию команда “s” обрабатывает первое совпадение в строке. А затем переходит к следующей строке. Для замены каждого “on”, а не только первого в строке, можно указать команде замены флаг “g” после шаблонов:
sed ‘s/on/forward/g’ annoying.txt this is the sforwardg that never ends yes, it goes forward and forward, my friend some people started singing it not knowing what it was and they’ll cforwardtinue singing it forever just because…
Теперь были заменены все “on”. Чтобы заменить только вторые “on” в каждой строке, вместо “g” нужно указать “2”:
sed ‘s/on/forward/2’ annoying.txt this is the song that never ends yes, it goes on and forward, my friend some people started singing it not knowing what it was and they’ll continue singing it forever just because…
Если нам нужно вывести только те строки, где выполнялась замена, для отмены автоматического вывода можно снова воспользоваться опцией «-n». Затем мы можем передать флаг “p” для вывода строк, в которых производились замены.
sed -n ‘s/on/forward/2p’ annoying.text yes, it goes on and forward, my friend
Пример показывает, что флаги в конце команды можно комбинировать. Чтобы игнорировать регистр, нужно указать флаг “i”.
sed ‘s/SINGING/saying/i’ annoying.txt this is the song that never ends yes, it goes on and on, my friend some people started saying it not knowing what it was and they’ll continue saying it forever just because…
Если нужно заменить текст во всех файлах директории то можно воспользоваться командой
grep ‘текс’ -P -R -I -l * | xargs sed -i ‘s/текст_который_нужно_искать/текст/g’
Примеры использования sed
| Синтаксис команды | Описание |
| sed ‘s/Nick/John/g’ report.txt | Заменяет каждое вхождение Nick на John в файле report.txt |
| sed ‘s/Nick|nick/John/g’ report.txt | Заменяет каждое вхождение Nick или nick на John. |
| sed ‘s/^/ /’ file.txt > file_new.txt | Добавляет 8 пробелов слева от текста для улучшения качества печати. |
| sed -n ‘/Of course/,/attention you pay/p’ myfile | Выводит все абзацы, начинающиеся с «Of course» и заканчивающиеся на «attention you pay». |
| sed -n 12,18p file.txt | Выводит только строки 12-18 файла file.txt |
| sed 12,18d file.txt | Выводит весь файл file.txt за исключением строк с 12 по 18 |
| sed G file.txt | Вставляет пустую строку после каждой строки в file.txt |
| sed -f script.sed file.txt | Записывает все команды в script.sed и выполняет их. |
| sed ‘5!s/ham/cheese/’ file.txt | Заменяет ham на cheese в file.txt за исключением 5-й строки |
| sed ‘$d’ file.txt | Удаляет последнюю строку |
| sed -n ‘/7<3>/p’ file.txt | Печатает только строки с тремя последовательными цифрами |
| sed ‘/boom/s/aaa/bb/’ file.txt | Если найден «boom», заменить aaa на bb |
| sed ’17,/disk/d’ file.txt | Удаляет все строки, начиная с 17-й, до «disk». Если строк с «disk» несколько, удаляет до первой из них. |
| echo ONE TWO | sed «s/one/unos/I» | Заменяет one на unos независимо от регистра, поэтому будет напечатано «unos TWO» |
| sed ‘G;G’ file.txt | Вставляет две пустые строки после каждой строки в file.txt |
| sed ‘s/.$//’ file.txt | Способ замены dos2unix :). В общем случае удаляет последний символ в каждой строке. |
| sed ‘s/^[ t]*//’ file.txt | Удаляет все пробелы/табы перед каждой строкой в file.txt |
| sed ‘s/[ t]*$//’ file.txt | Удаляет все пробелы/табы в конце каждой строки в file.txt |
| sed ‘s/^[ t]*//;s/[ t]*$//’ file.txt | Удаляет все пробелы/табы в начале и в конце каждой строки в file.txt |
| sed ‘s/foo/bar/’ file.txt | Заменяет foo на bar только в первом вхождении в строке. |
| sed ‘s/foo/bar/4’ file.txt | Заменяет foo на bar только в четвертом вхождении в строке. |
| sed ‘s/foo/bar/g’ file.txt | Заменяет foo на bar для всех вхождений в строке. |
| sed ‘/baz/s/foo/bar/g’ file.txt | Заменить foo на bar только если строка содержит baz. |
| sed ‘/./,/^$/!d’ file.txt | Сжать все последовательные пустые строки до одной. Пустой строки сверху не остается. |
| sed ‘/^$/N;/n$/D’ file.txt | Сжать все последовательные пустые строки до одной, но оставить верхнюю пустую строку. |
| sed ‘/./,$!d’ file.txt | Удалить все начальные пустые строки |
| sed -e :a -e ‘/^n*$/<$d;N;>;/n$/ba’ file.txt | Удалить все замыкающие пустые строки |
| sed -e :a -e ‘/\$/N; s/\n/ /; ta’ file.txt | Если строка заканчивается обратным сплешем, соединить ее со следующей (полезно для скриптов оболочки) |
| sed -n ‘/regex/,+5p’ file.txt | Выводит 5 строк после строки содержащей regex |
| sed ‘1 |
3d’ file.txt
5p’ file.txt
В окружении UNIX: конвертируем новые строки DOS (CR/LF) в формат Unix.
Предполагаем, что все строки оканчиваются на CR/LF



