- Использование команды uniq в Linux (10 примеров)
- Утилита uniq в Linux
- 1. Удаление повторяющихся строк из вывода
- 2. Вывод информации о количестве дубликатов каждой из строк
- 3. Вывод лишь повторяющихся строк
- 4. Пропуск начальных фрагментов строк
- 5. Вывод всех строк с разделением групп повторяющихся строк
- 6. Вывод лишь не повторяющихся строк
- 7. Пропуск заданного количества символов в начале строк
- 8. Указание количества символов для сравнения
- 9. Сравнение строк без учета регистра
- 10. Использование завершающего нулевого символа вместо символа перехода на новую строку
- Заключение
- Есть ли способ «uniq» по столбцу?
- 8 ответов
- 12.4. Команды обработки текста
- Примечания
Использование команды uniq в Linux (10 примеров)
Оригинал: Linux Uniq Command Tutorial for Beginners (10 examples)
Автор: Himanshu Arora
Дата публикации: 23 мая 2017 г.
Перевод: А.Панин
Дата перевода: 24 мая 2017 г.
Если вы являетесь пользователем интерфейса командной строки Linux и ваша работа связана с редактированием текстовых файлов, вы должны знать (если уже не знаете) о существовании огромного количества утилит с интерфейсом командной строки, которые могут помочь вам в различных ситуациях. Например, одной из таких утилит является утилита uniq , выводящая или удаляющая из вывода повторяющиеся строки, находящиеся в текстовом файле.
В данной статье мы будем обсуждать методику использования утилиты uniq на основе простых для понимания примеров. Но перед тем, как приступить к рассмотрению примеров стоит упомянуть о том, что все примеры и инструкции из данной статьи были протестированы в системе Ubuntu 16.04 LTS.
Утилита uniq в Linux
Как уже говорилось ранее, утилита uniq осуществляет вывод или удаление из вывода повторяющихся строк. А это синтаксис соответствующей команды:
А это описание функций утилиты с ее страницы руководства: «Утилита осуществляет фильтрацию идентичных строк из ВХОДНОГО ФАЙЛА (или из стандартного потока ввода) и выводит информацию в ВЫХОДНОЙ ФАЙЛ (или стандартный поток вывода). При вызове без параметров идентичные строки объединяются в рамках первых найденных экземпляров строк.»
Ниже приведен ряд примеров, которые помогут вам лучше понять принцип работы рассматриваемой утилиты.
1. Удаление повторяющихся строк из вывода
Предположим, что в нашем распоряжении имеется файл со следующими строками:
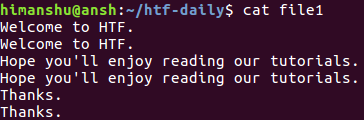
Несложно заметить, что каждая из строк повторяется. Теперь применим утилиту uniq по отношению к этому файлу и посмотрим, к чему это приведет.

Очевидно, что вывод не содержит дубликатов строк. Обратите внимание на то, что содержимое оригинального файла с именем file1 в нашем случае осталось неизменным. Вы можете перенаправить вывод утилиты в другой файл в том случае, если вам нужно сохранить вывод для дальнейшей обработки.
2. Вывод информации о количестве дубликатов каждой из строк
Если вам нужно, вы можете использовать утилиту uniq для вывода информации о количестве повторений каждой из строк файла. Это может быть сделано с помощью параметра командной строки -c . Например, команда
будет генерировать следующий вывод:

Несложно заметить, что перед каждой из строк выводится число, соответствующее количеству ее повторений.
3. Вывод лишь повторяющихся строк
Для того, чтобы утилита uniq выводила лишь повторяющиеся строки, следует использовать параметр -D командной строки. Например, предположим, что файл с именем файл file1 теперь содержит дополнительную строку в конце (обратите внимание на то, что эта строка не повторяется).
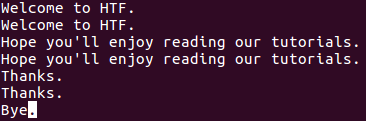
Теперь при исполнении команды
будет генерироваться следующий вывод:
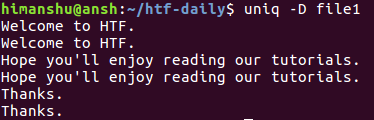
Как вы видите, параметр -D сообщает утилите uniq о необходимости вывода всех повторяющихся строк, включая их повторы. Для лучшей читаемости вы можете активировать режим вывода пустой строки после каждой из групп повторяющихся строк с помощью параметра —all-repeated .
Данный параметр требует от пользователя обязательного указания метода добавления разделителя. Строки могут добавляться к разделителю (то есть, пустой строке) с помощью метода prepend или разделяться с помощью него с помощью метода append . Например, в данном случае используется метод prepend .
![]()
Более того, если вам нужно, чтобы утилита выводила лишь по одному экземпляру каждой из повторяющихся строк, вы можете воспользоваться параметром -d . Это пример его использования:

Очевидно, что в выводе приводится лишь по одному экземпляру строки из каждой группы.
4. Пропуск начальных фрагментов строк
Иногда, в зависимости от ситуации, совпадение двух строк может быть установлено по совпадению определенных частей этих строк. Например, рассмотрим следующий файл:
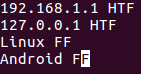
Теперь предположим, что строки должны считаться совпадающими или не совпадающими на основании совпадения или несовпадения их вторых полей (то есть HTF или FF) и вам нужно сделать так, чтобы утилита uniq использовала такой же критерий сравнения, чего несложно добиться с помощью параметра командной строки -f .
Параметр -f требует от вас обязательной передачи числа, которое соответствует количеству полей, которые нужно пропустить. Например, в нашем случае мы передаем в качестве значения параметр -f значение 1, так как мы хотим, чтобы утилита uniq пропустила лишь первое поле:

Из вывода очевидно, что утилита uniq посчитала первую и третью строку повторяющимися исключительно на основе их вторых полей.
5. Вывод всех строк с разделением групп повторяющихся строк
При необходимости вывода всех строк с разделением групп повторяющихся строк с помощью пустой строки вы можете использовать параметр —group . Как и в случае описанного выше параметра —all-repeated , параметр —groups требует от пользователя обязательного указания позиции пустой строки ( prepend , append или both ).
Это пример использования рассматриваемого параметра:
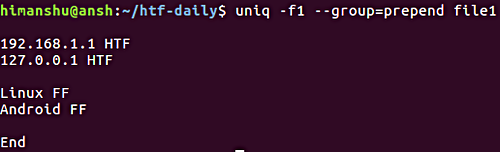
Обратите внимание на параметр -f , который обсуждался в предыдущем разделе.
6. Вывод лишь не повторяющихся строк
Вы уже наверняка поняли, что утилита uniq по умолчанию выводит лишь повторяющиеся строки. Но если вам нужно, вы можете сообщить ей о необходимости вывода лишь не повторяющихся или уникальных строк. Это делается с помощью параметра командной строки -u .
В нашем случае команда будет выглядеть следующим образом:
Это пример ее использования:

Обратите внимание на параметр -f , который обсуждался в разделе 4.
7. Пропуск заданного количества символов в начале строк
В одном из предыдущих разделов мы обсуждали методику пропуска полей строк при использовании утилиты uniq. Однако, при необходимости вы можете сообщить утилите о необходимости пропуска не начальных полей, а начальных символов строк. Для доступа к соответствующей функции может использоваться параметр командной строки -s .
Например, предположим, что наш файл содержит следующие строки:
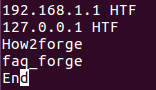
Теперь, если вы захотите, чтобы uniq пропустила первые 4 символа каждой строки перед их сравнением, вы сможете воспользоваться следующей командой:
А это приведенная выше команда в действии:
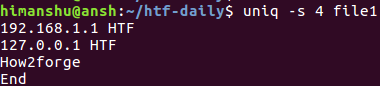
Несложно заметить, что четвертая строка (faq_forge) из оригинального файла была пропущена. Это объясняется тем, что после пропуска первых четырех символов третья и четвертая строки становятся идентичными для утилиты uniq и она выводит лишь первую из них.
8. Указание количества символов для сравнения
По аналогии с пропуском символов, вы можете сообщить утилите uniq о необходимости сравнения лишь заданного количества символов строк. Для этой цели вам придется использовать параметр командной строки -w .
Например, предположим, что файл содержит следующие строки:
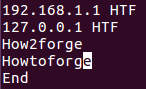
Теперь при необходимости ограничения диапазона символов строк для сравнения тремя первыми символами, может использоваться следующая команда:
Это приведенная выше команда в действии:
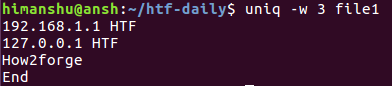
Так как первые три символа третьей и четвертой строк совпадают, эти строки считаются утилитой идентичными. По этой причине в выводе находится лишь третья строка.
9. Сравнение строк без учета регистра
По умолчанию утилита uniq осуществляет сравнение строк с учетом регистра символов. Однако, вы можете активировать режим сравнения строк без учета регистра символов с помощью параметра командной строки -i .
Например, предположим, что мы будем использовать файл с содержимым, аналогичным рассмотренному в предыдущем разделе, но теперь четвертая строка будет начинаться с символов H, O и W в верхнем регистре.
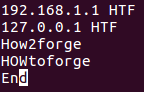
Теперь, если вы попытаетесь выполнить рассмотренную в предыдущем разделе команду, вы получите отличный вывод:
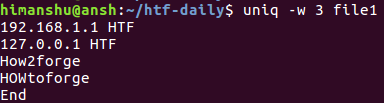
Это объясняется тем, что первые три символа третьей и четвертой строк отличны для утилиты uniq ввиду их регистра. В подобных ситуациях вы можете активировать режим сравнения строк без учета регистра с помощью параметра командной строки -i .
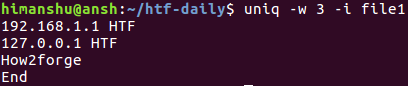
10. Использование завершающего нулевого символа вместо символа перехода на новую строку
По умолчанию утилита uniq генерирует вывод с завершающим символом перехода на новую строку. Однако, при необходимости вы можете активировать режим использования завершающего нулевого символа (полезный при вызове uniq из сценариев). Для этого следует использовать параметр командной строки -z :
Заключение
Мы рассмотрели практически все поддерживаемые утилитой uniq параметры командной строки, поэтому вам остается лишь самостоятельно испытать их в работе для того, чтобы лучше понять их принцип работы и функции. И как обычно, в случае каких-либо сомнений и вопросов следует обращаться к странице руководства утилиты .
Источник
Есть ли способ «uniq» по столбцу?
У меня есть файл .csv, например:
Мне нужно удалить повторяющиеся электронные письма (всю строку) из файла (т.е. одну из строк, содержащих overflow@example.com в приведенном выше примере). Как использовать uniq только в поле 1 (разделенном запятыми)? Согласно man , uniq не имеет параметров для столбцов.
Я пробовал что-то с sort | uniq , но это не работает.
8 ответов
- -u для уникального
- -t, поэтому запятая является разделителем
- -k1,1 для ключевого поля 1
- -F устанавливает разделитель полей.
- $1 — первое поле.
- _[val] ищет val в хэше _ (обычная переменная).
- ++ увеличивает и возвращает старое значение.
- ! возвращает логическое «нет».
- в конце есть неявная печать.
Считать несколько столбцов.
Отсортируйте и дайте уникальный список на основе столбца 1 и столбца 3:
- -t : двоеточие — разделитель
- -k 1,1 -k 3,3 на основе столбца 1 и столбца 3
Или если вы хотите использовать uniq:
Если вы хотите сохранить последний дубликат, вы можете использовать
Что было моим требованием
tac перевернет файл построчно
Вот очень изящный способ.
Сначала отформатируйте содержимое так, чтобы столбец, который будет сравниваться на предмет уникальности, имел фиксированную ширину. Один из способов сделать это — использовать awk printf со спецификатором ширины поля / столбца («% 15s»).
Теперь параметры -f и -w команды uniq можно использовать, чтобы пропустить предыдущие поля / столбцы и указать ширину сравнения (ширину столбца (столбцов)).
Вот три примера.
В первом примере .
1) Временно сделайте интересующий столбец фиксированной шириной, большей или равной максимальной ширине поля.
2) Используйте параметр -f uniq, чтобы пропустить предыдущие столбцы, и параметр -w uniq, чтобы ограничить ширину до tmp_fixed_width.
3) Удалите конечные пробелы из столбца, чтобы «восстановить» его ширину (при условии, что заранее не было конечных пробелов).
Во втором примере .
Создайте новый столбец uniq 1. Затем удалите его после применения фильтра uniq.
Третий пример такой же, как и второй, но для нескольких столбцов.
Ну, проще, чем изолировать столбец с помощью awk, если вам нужно удалить все с определенным значением для данного файла, почему бы просто не выполнить grep -v:
Например чтобы удалить все, что имеет значение «col2» во второй строке: col1, col2, col3, col4
Если этого недостаточно, потому что некоторые строки могут быть неправильно разделены из-за того, что совпадающее значение может отображаться в другом столбце, вы можете сделать что-то вроде этого:
Awk, чтобы изолировать проблемный столбец: например,
-F устанавливает поле, разделенное на «,», $ 2 означает столбец 2, за которым следует некоторый настраиваемый разделитель, а затем вся строка. Затем вы можете выполнить фильтрацию, удалив строки, начинающиеся с недопустимого значения:
А затем удалите содержимое перед разделителем:
(обратите внимание — команда sed неаккуратна, потому что она не включает экранирование значений. Также шаблон sed действительно должен быть чем-то вроде «[^ |] +» (т.е. что-либо, кроме разделителя). Но, надеюсь, это достаточно ясно.
Сначала отсортировав файл с помощью sort , вы можете применить uniq .
Источник
12.4. Команды обработки текста
Сортирует содержимое файла, часто используется как промежуточный фильтр в конвейерах. Эта команда сортирует поток текста в порядке убывания или возрастания, в зависимости от заданных опций. Ключ -m используется для сортировки и объединения входных файлов. В странице info перечислено большое количество возможных вариантов ключей. См. Пример 10-9, Пример 10-10 и Пример A-9.
Топологическая сортировка, считывает пары строк, разделенных пробельными символами, и выполняет сортировку, в зависимости от заданного шаблона.
Удаляет повторяющиеся строки из отсортированного файла. Эту команду часто можно встретить в конвейере с командой sort.
Ключ -c выводит количество повторяющихся строк.
Команда sort INPUTFILE | uniq -c | sort -nr выводит статистику встречаемости строк в файле INPUTFILE (ключ -nr, в команде sort, означает сортировку в порядке убывания). Этот шаблон может с успехом использоваться при анализе файлов системного журнала, словарей и везде, где необходимо проанализировать лексическую структуру документа.
Пример 12-8. Частота встречаемости отдельных слов
Команда expand преобразует символы табуляции в пробелы. Часто используется в конвейерной обработке текста.
Команда unexpand преобразует пробелы в символы табуляции. Т.е. она является обратной по отношению к команде expand.
Предназначена для извлечения отдельных полей из текстовых файлов. Напоминает команду print $N в awk, но более ограничена в своих возможностях. В простейших случаях может быть неплохой заменой awk в сценариях. Особую значимость, для команды cut, представляют ключи -d (разделитель полей) и -f (номер(а) поля(ей)).
Использование команды cut для получения списка смонтированных файловых систем:
Использование команды cut для получения версии ОС и ядра:
Использование команды cut для извлечения заголовков сообщений из электронных писем:
Использование команды cut при разборе текстового файла:
cut -d ‘ ‘ -f2,3 filename эквивалентно awk -F'[ ]’ ‘< print $2, $3 >‘ filename
Используется для объединения нескольких файлов в один многоколоночный файл.
Может рассматриваться как команда, родственная команде paste. Эта мощная утилита позволяет объединять два файла по общему полю, что представляет собой упрощенную версию реляционной базы данных.
Команда join оперирует только двумя файлами и объедияет только те строки, которые имеют общее поле (обычно числовое), результат объединения выводится на stdout. Объединяемые файлы должны быть отсортированы по ключевому полю.
 |
 |
|
|
 |
|
 |



