16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
Хотите знать, что самом деле происходит на с вашим сервером? Тогда вы должны знать эти основные команды. Как только вы их освоите, вы станете администратором-экспертом в системах Linux.
В зависимости от дистрибутива Linux, вы можете с помощью программы с графическим интерфейсом получить больше информации, чем могут дать эти команды, запускаемые из командной оболочки. В SUSE Linux, например, есть отличное графическое инструментальное средство YaST , предназначенное для конфигурирования и управления системой; также в KDE есть отличное инструментальное средство KDE System Guard .
Однако, основное правило администратора Linux состоит в том, что вы должны работать с графическим интерфейсом на сервере только в случае, когда это вам абсолютно необходимо. Это обусловлено тем, что графические программы на Linux занимают системные ресурсы, которые было бы лучше использовать в другом месте. Поэтому хотя программа с графическим интерфейсом и может отлично подходить для базовой проверки состояния сервера, если вы хотите знать, что происходит на самом деле, отключите графический интерфейс и воспользуйтесь инструментальными средствами, работающими из командной строки Linux.
Это также означает, что вы должны запускать графический интерфейс на сервере только тогда, когда это действительно необходимо; не оставляйте его работать. Чтобы достичь оптимальной производительности, сервер Linux должен работать на уровне runlevel 3 , на котором, когда компьютер загружается, полностью поддерживается работа в сети и многопользовательский режим, но графический интерфейс не запускается. Если вам действительно нужно графический рабочий стол, вы всегда можете его открыть с помощью команды startx , выполненной из командной строки.
Если ваш сервер при загрузке запускается в графическом режиме, то вам это нужно изменить. Для этого откройте терминальное окно, с помощью команды su перейдите в режим пользователя root и с помощью вашего любимого текстового редактора откройте файл /etc/inittab .
Как только вы это сделаете, найдите строку initdefault и измените ее с id:5:initdefault: на id:3:initdefault:
Если файла inittab нет, то создайте его и добавьте строку id:3 . Сохраните файл и выйдите из редактора. В следующий раз при загрузке ваш сервер будет загружаться на уровне запуска 3. Если вы после этого изменения не захотите перезагружать сервер, вы также можете с помощью команды init 3 непосредственно задать уровень запуска вашего сервера.
Как только ваш сервер станет работать на уровне запуска init 3, вы для того, чтобы увидеть, что происходит внутри вашего сервера, можете начать пользоваться следующими программами командной оболочки.
iostat
Команда iostat подробно показывает, что к чему в вашей подсистеме хранения данных. Как правило, вы должны использовать команду iostat для того, чтобы следить, что ваша подсистема хранения работают в целом хорошо и прежде, чем ваши клиенты заметят, что сервер работает медленно, выявлять те места, из-за медленного ввода/вывода которых возникают проблемы. Поверьте мне, вам следует обнаруживать эти проблемы раньше, чем это сделают ваши пользователи!
meminfo и free
Команда meminfo предоставит вам подробный список того, что происходит в памяти. Как правило, доступ к данным meminfo можно получить с помощью другой программы, например, cat или grep . Так, например, с помощью команды
вы в любой момент будете знать все, что происходит в памяти вашего сервера.
Вы можете воспользоваться командой free для быстрого «фактографического» взгляда на память. Если кратко, то с помощью команды free вы получите обзор состояния памяти, а с помощью команды meminfo вы узнаете все подробности.
mpstat
Команда mpstat сообщает о действиях каждого из доступных процессоров в многопроцессорных серверах. В настоящее время почти во всех серверах используются многоядерные процессоры. Команда mpstat также сообщает об усредненной загрузке всех процессоров сервера. Это позволяет отображать общую статистику по процессорам во всей системе или для каждого процессора отдельно. Эти значения могут предупредить вас о возможных проблемах с приложением прежде, чем они станут раздражать пользователей.
netstat
Команда netstat , точно также, как и ps , является инструментальным средством Linux, которым администраторы пользуются каждый день. Она отображает большое количество информации о состоянии сети, например, об использовании сокетов, маршрутизации, интерфейсах, протоколах, показывает сетевую статистику и многое другое. Некоторые из наиболее часто используемых параметров:
-a — Показывает информацию о всех сокетах
-r — Показывает информацию, касающуюся маршрутизации
-i — Показывает статистику, касающуюся сетевых интерфейсов
-s — Показывает статистику, касающуюся сетевых протоколов
Команда nmon , сокращение от Nigel’s Monitor, является популярным инструментальным средством с открытым исходным кодом, которое предназначено для мониторинга производительности систем Linux. Команда nmon следит за информацией о производительности нескольких подсистем, таких как использование процессоров, использование памяти, выдает информацию о работе очередей, статистику дисковых операций ввода/вывода, статистику сетевых операций, активности системы подкачки и метрические характеристики процессов. Затем вы через «графический» интерфейс команды curses можете в режиме реального времени просматривать информацию, собираемую командой nmon.
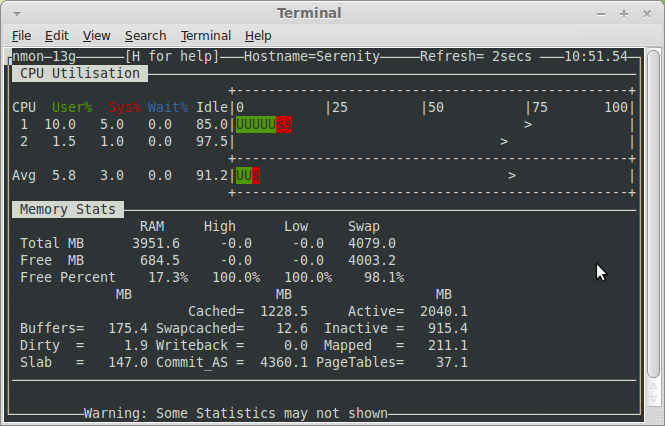
Чтобы команда nmon работала, вы должны ее запустить из командной строки. После этого вы можете с помощью нажатий на отдельные клавиши выбирать подсистемы, за работой которых вы хотите проследить. Например, чтобы получить статистику по процессору, памяти и дискам, наберите c , m и d . Вы также можете использовать команду nmon с флагом -f для того, чтобы сохранить статистику в файле CSV для последующего анализа.
Я считаю, что для повседневного мониторинга серверов команда nmon является одной из самых полезных программ в моем инструментальном наборе, предназначенном для систем Linux.
Команда pmap сообщает об объеме памяти, которые используются процессами на вашем сервере. Вы можете использовать этот инструмент для того, чтобы определить, для каких процессов на сервере выделяется память и как эти процессы ее используют.
ps и pstree
Команды ps и pstree являются двумя самыми лучшими командами администратора Linux. Они обе выдают список всех запущенных процессов. Команда ps показывает, сколько памяти и процессорного времени используют программы, работающие на сервере. Команда pstree выдает меньше информации, но указывает, какие процессы являются потомками других процессов. Имея эту информацию, вы можете обнаружить неуправляемые процессы и уничтожить их с помощью команды kill , предназначенной для «безусловного уничтожения» процессов в Linux.
Программа sar является инструментальным средством мониторинга, столь же универсальным как швейцарский армейский нож. Команда sar , на самом деле, состоит из трех программ: sar , которая отображает данные, и sa1 и sa2 , которые собирают и запоминают данные. После того, как программа sar установлена, она создает подробный отчет об использовании процессора, памяти подкачки, о статистике сетевого ввода/вывода и пересылке данных, создании процессов и работе устройств хранения данных. Основное отличие между sar и nmon в том, что первая команда лучше при долгосрочном мониторинге системы, в то время, как я считаю, nmon лучше для того, чтобы мгновенно получить информацию о состоянии моего сервера.
strace
Команду strace часто рассматривают, как отладочное средство программиста, но, на самом деле, ее можно использовать не только для отладки. Команда перехватывает и записывает системные вызовы, которые происходят в процессе. Т.е. она полезна в диагностических, учебных и отладочных целях. Например, вы можете использовать команду strace для того, чтобы выяснить, какой на самом деле при запуске программы используется конфигурационный файл.
tcpdump
Tcpdump является простой и надежной утилитой мониторинга сети. Ее базовые возможности анализа протокола позволяют получить общее представление о том, что происходит в вашей сети. Однако, чтобы по-настоящему разобраться в том, что происходит в вашей сети, вам следует воспользоваться программой Wireshark (см. ниже).
Команда top показывает, что происходит с вашими активными процессами. По умолчанию она отображает самые ресурсоемкие задачи, запущенные на сервере, и обновляет список каждые пять секунд. Вы можете отсортировать процессы по PID (идентификатор процесса), времени работы, можете сначала указывать новые процессы, затраты по времени, по суммарному затраченному времени, а также по используемой памяти и по общему времени использования процессора с момента запуска процесса. Я считаю, что это быстрый и простой способ увидеть, что некоторый процесс начинает выходить из-под контроля и из-за этого все движется к проблеме.
uptime
Используйте команду uptime для того, чтобы узнать, как долго работает сервер и сколько пользователей было зарегистрировано в системе. Эта команда также покажет вам среднюю загрузку сервера. Оптимальное значение равно 1 или меньше, что означает, что каждый процесс немедленно получает доступ к процессору и потери циклов процессора отсутствуют.
vmstat
Вы можете использовать команду vmstat , в основном, для контроля того, что происходит с виртуальной памятью. Для того, чтобы получить наилучшую производительность системы хранения данных, Linux постоянно обращается к виртуальной памяти.
Если ваши приложения занимают слишком много памяти, вы получите чрезмерное значение затрат страниц памяти (page-outs) — программы перемещаются из оперативной памяти в пространство подкачки вашей системы, которое находится на жестком диске. Ваш сервер может оказаться в таком состоянии, когда он тратит больше времени на управление памятью подкачки, а не на работу ваших приложений; это состояние называемое пробуксовкой (thrashing). Когда компьютер находится в состоянии пробуксовки, его производительность падает очень сильно. Команда vmstat , которая может отображать либо усредненные данные, либо фактические значения, может помочь вам определить программы, которые занимают много памяти, прежде, чем из-за них ваш процессор перестанет шевелиться.
Wireshark
Программа wireshark , ранее известная как ethereal (и до сих пор часто называют именно так), является «старшим братом» команды tcpdump , хотя она более сложная и с более расширенными возможностями анализа и отчетности по используемым протоколам. У wireshark есть как графический интерфейс, так и интерфейс командной оболочки. Если вам требуется серьезное администрирование сетей, вам следует использовать программу ethereal. И, если вы используете wireshark/ethereal, я настоятельно рекомендую воспользоваться книгой Practical Packet Analysis Криса Сандера (Chris Sander), рассказывающей о том, как с помощью практического анализа пакетов можно получить максимальную отдачу от этой полезной программы.
Это обзор всего лишь нескольких наиболее значимых систем мониторинга из многих, имеющихся для Linux. Тем не менее, если вы сможете освоить эти программы, они помогут вам на пути к вершинам системного администрирования Linux.
Источник
Как узнать, как долго длится процесс в Linux
Вы когда-нибудь хотели узнать, как долго процесс запускается в вашем Linux-боксе?
Ну, ты на правильном пути.
Это краткое руководство поможет вам узнать время работы активного процесса.
Вам не нужны никакие приложения для мониторинга.
В Unix-подобных операционных системах существует команда ps, которая используется для отображения информации об активных процессах.
Используя команду ps, мы можем легко узнать, как долго работает процесс.
Узнать, как долго длится процесс в Linux
Команда ps имеет разные спецификаторы формата (ключевые слова), которые могут использоваться для управления выходным форматом.
Мы будем использовать следующие два ключевых слова, чтобы найти время работы активного процесса.
- etime – прошедшее время с момента запуска процесса в виде [[DD-] hh:] mm: ss.
- etimes – прошедшее время с момента запуска процесса в секундах.
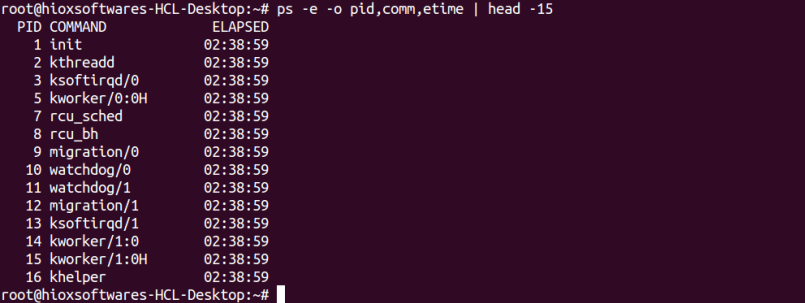
Во-первых, вам нужно узнать PID процесса. Следующая команда отображает PID процесса dhcpcd.
Как видно из вышеприведенного вывода, 8299 является PID процесса dhcpcd.
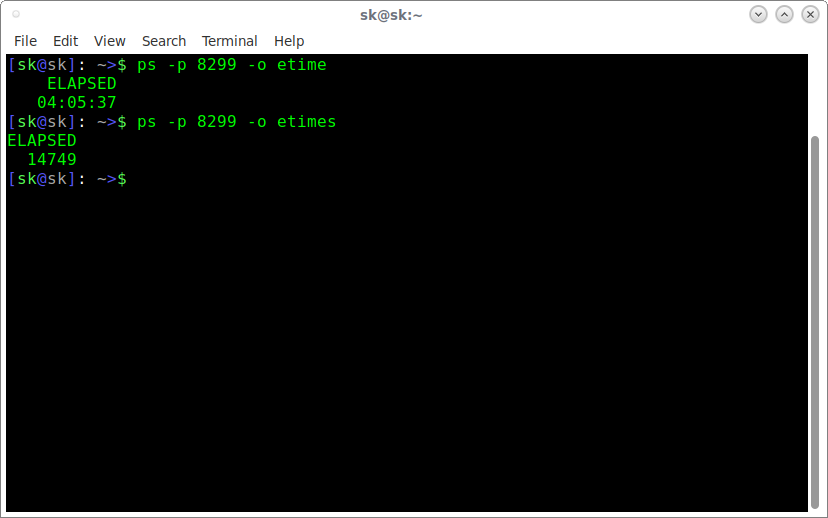
Теперь мы можем узнать, как долго этот процесс выполнялся с помощью команды:
Вы также можете просмотреть прошедшее время в секундах, используя ключевое слово etimes.
Не только один процесс, мы также можем отображать время безотказной работы всех процессов с помощью команды:
Первая команда отображает время безотказной работы всех процессов Linux в формате [[DD-] hh:] mm: ss, а на последнем отображает время безотказной работы в секундах.
Вот пример вывода второй команды.
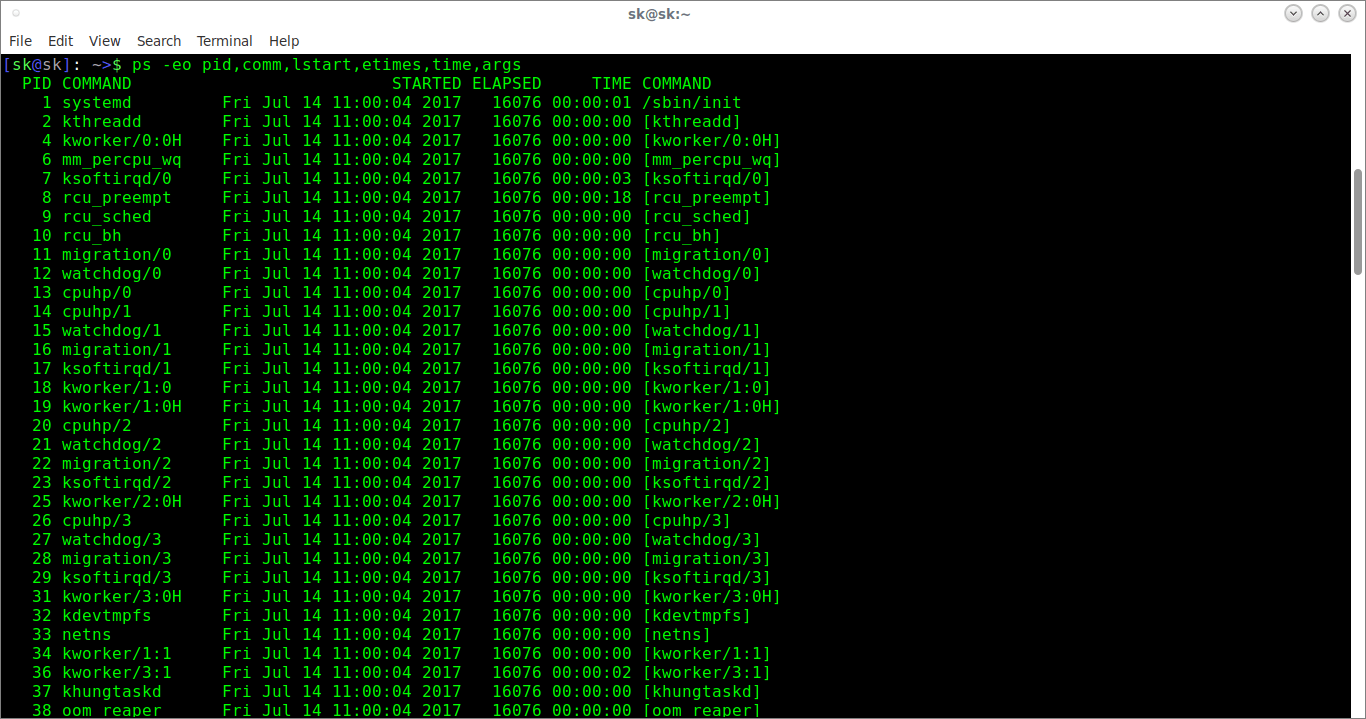
Как видно из вышесказанного, у нас есть время безотказной работы всех процессов с шестью столбцами.
Тут есть вот что:
- PID – идентификатор процесса
- COMMAND (второй столбец) – имя команды без параметров и / или аргументов.
- STARTED – абсолютное время начала процесса.
- ELAPSED – Истекшее время с момента запуска процесса в виде [[dd-] hh:] mm: ss.
- TIME – суммарное время процессора, “[dd-] hh: mm: ss” format.
- COMMAND (последний столбец) – имя команды со всеми ее опциями и аргументами.
Для получения дополнительной информации о команде ps проверьте страницы руководства.
И это все на данный момент. Теперь вы знаете, как узнать, как долго работает процесс в вашей Linux-системе. Надеюсь это поможет. Я скоро буду здесь с другим полезным руководством.
Источник
Как узнать время работы процесса в Linux
Как узнать аптайм данного процесса в Linux.
дает мне много информации, которая включает в себя время, когда процесс был запущен.
Я специально ищу switch, который возвращает время работы процесса в миллисекундах.
5 ответов
как «uptime» имеет несколько значений, вот полезная команда.
эта команда выводит список всех процессов с несколькими различными столбцами, связанными со временем. Он имеет следующие столбцы:
PID = идентификатор процесса
первый COMMAND = только имя команды без параметров и без аргументов
STARTED = абсолютное время начала процесса
ELAPSED = время, прошедшее с момента запуска процесса (времени), формат [[dd-]hh:]mm: ss TIME = накопительное время процессора,» [dd-]hh:mm:ss » формат
second COMMAND = снова команда, на этот раз со всеми предоставленными параметрами и аргументами
если у вас есть ограниченная версия ps таких как находится в busybox , вы можете получить время запуска процесса, глядя на метку /proc/
. Например, если pid, который вы хотите посмотреть, 55.
. а затем сравнить его с текущей датой.
Я думаю, что вы можете просто запустить:
пример с двумя процессами, запущенными в один и тот же час минуты секунды, но не те же миллисекунды:
такая простая вещь не правильно ответил после 5 лет?
Я не думаю, что вы можете точно сделать миллисекунд. напр. если вы видите Man procfs и видите /proc / $$ / stat, который имеет поле 22 как startime, которое находится в «Clock ticks», у вас будет что-то более точное, но тики часов не собираются с совершенно постоянной скоростью (относительно «настенного времени») и будут выключены. сон и некоторые вещи (ntpd, я думаю) компенсируют это. Например, на машине, работающей под управлением ntpd, с 8 днями uptime и никогда не спал, dmesg-T имеет ту же проблему (я думаю. ), и вы можете увидеть его здесь:
Да, слишком старые и слишком сложные вещи. Я попытался с выше предложенным методом «stat», но что, если бы у меня было»прикосновение» -ed PID proc dir вчера? Это означает, что мой летний процесс показан со вчерашней отметкой времени. Нет, не то, что мне нужно: (
в более новых, это просто:
как просто. Время присутствует в секундах. Делайте все, что вам нужно. С некоторыми старыми коробками ситуация сложнее, так как нет времени. Можно рассчитывать on:
которые выглядят «немного» странно, так как он находится в формате dd-hh:mm:ss. Не подходит для дальнейшего расчета. Я бы предпочел его в секундах, поэтому я использовал этот:
Источник



