- Peter Leung, «Командная строка: маленькие хитрости от Linux Commando»
- Выбираем нужные строки из файла с помощью sed
- 9.2. Работа со строками
- 9.2.1. Использование awk при работе со строками
- 9.2.2. Дальнейшее обсуждение
- Основные приёмы обработки строк в bash
- Термины
- Сравнение строковых переменных
- Основные операторы сравнения
- Пример скрипта для сравнения двух строковых переменных
- Создание тестового файла
- Основы работы с grep
- Синтаксис команды
- Основные опции
- Практическое применение grep
- Поиск подстроки в строке
- Вывод нескольких строк
- Чтение строки из файла с использованием регулярных выражений
- Рекурсивный режим поиска
- Точное вхождение
- Поиск нескольких слов
- Количество строк в файле
- Вывод только имени файла
- Использование sed
- Синтаксис
- Распространенные конструкции с sed
- Замена слова
- Редактирование файла
- Удаление строк из файла
- Нумерация строк
- Удаление всех чисел из текста
- Замена символов
- Обработка указанной строки
- Работа с диапазоном строк
Peter Leung, «Командная строка: маленькие хитрости от Linux Commando»
Выбираем нужные строки из файла с помощью sed
Тому, кто пишет много скриптов bash, часто приходится выбирать нужные строки из текста, например готовые блоки кода. Вчера я как раз должен был извлечь первую строку из файла, назовем его somefile.txt.
Это очень просто сделать при помощи команды head:
Для более сложных задач, например, извлечь вторую и третью строки из того же файла, команда head не подходит.
Давайте попробуем команду sed ≈ редактор потока (STream Editor).
Моя первая попытка применить команду p (print) оказалась неудачной:
Обратите внимание, что редактор печатает весь файл, причем указанную первую строку печатает дважды. Почему? По умолчанию редактор перепечатывает на стандартный вывод каждую строку вводимого файла. Четко заданная команда 1p приказывает печатать первую строку. В итоге первая строка дублируется.
Чтобы этого не происходило нужно подавить дефолтный вывод при помощи опции -n, чтобы на выводе был только результат команды 1p:
Можно пойти другим путем и удалить из файла все строки, кроме первой:
где ‘1!d’ означает: если строка не является первой (!), то подлежит удалению. Обратите внимания на кавычки (одинарные). Они совершенно необходимы, так как без них конструкция 1!d вызовет последнюю запускавшуюся в шелле команду, начинающуюся с буквы d.
Для извлечения нескольких строк, скажем, со второй по четвертую, можно поступить одним из следующих способов:
Интервал обозначается через запятую включительно.
А если строки не идут друг за другом, например, с первой по вторую и еще четвертую?
Если вам известны иные способы выбирать нужные строки из файлов, сообщите, пожалуйста, в комментариях.
Блестящий пример нестандартного подхода продемонстрировал в комментариях к этой статье некий Chris:
| Если я хочу извлечь пятую строку файла, то делаю так: |
А правда, здорово! И никаких заумных команд не надо с их километровыми манами. Кстати так и нужные блоки подряд идущих строк можно извлекать.
Источник
9.2. Работа со строками
Bash поддерживает на удивление большое количество операций над строками. К сожалению, этот раздел Bash испытывает недостаток унификации. Одни операции являются подмножеством операций подстановки параметров, а другие — совпадают с функциональностью команды UNIX — expr. Это приводит к противоречиям в синтаксисе команд и перекрытию функциональных возможностей, не говоря уже о возникающей путанице.
Длина строки
$ <#string>expr length $string expr «$string» : ‘.*’
Пример 9-10. Вставка пустых строк между параграфами в текстовом файле
Длина подстроки в строке (подсчет совпадающих символов ведется с начала строки)
expr match «$string» ‘$substring’
expr «$string» : ‘$substring’
где $substring — регулярное выражение.
Index
expr index $string $substring
Номер позиции первого совпадения в $string c первым символом в $substring.
Эта функция довольно близка к функции strchr() в языке C.
Извлечение подстроки
Извлекает подстроку из $string, начиная с позиции $position.
Если строка $string — » * » или » @ » , то извлекается позиционный параметр (аргумент), [1] с номером $position.
Извлекает $length символов из $string, начиная с позиции $position.
Если $string — » * » или » @ » , то извлекается до $length позиционных параметров (аргументов), начиная с $position.
expr substr $string $position $length
Извлекает $length символов из $string, начиная с позиции $position.
expr match «$string» ‘\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение.
expr «$string» : ‘\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение.
expr match «$string» ‘.*\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение. Поиск начинается с конца $string.
expr «$string» : ‘.*\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение. Поиск начинается с конца $string.
Удаление части строки
Удаление самой короткой, из найденных, подстроки $substring в строке $string. Поиск ведется с начала строки
Удаление самой длинной, из найденных, подстроки $substring в строке $string. Поиск ведется с начала строки
Удаление самой короткой, из найденных, подстроки $substring в строке $string. Поиск ведется с конца строки
Удаление самой длинной, из найденных, подстроки $substring в строке $string. Поиск ведется с конца строки
Пример 9-11. Преобразование графических файлов из одного формата в другой, с изменением имени файла
Замена подстроки
Замещает первое вхождение $substring строкой $replacement.
Замещает все вхождения $substring строкой $replacement.
Подстановка строки $replacement вместо $substring. Поиск ведется с начала строки $string.
Подстановка строки $replacement вместо $substring. Поиск ведется с конца строки $string.
9.2.1. Использование awk при работе со строками
В качестве альтернативы, Bash-скрипты могут использовать средства awk при работе со строками.
Пример 9-12. Альтернативный способ извлечения подстрок
9.2.2. Дальнейшее обсуждение
Дополнительную информацию, по работе со строками, вы найдете в разделе Section 9.3 и в секции, посвященной команде expr. Примеры сценариев:
Источник
Основные приёмы обработки строк в bash
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство « = »: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность « == »: возвращается «TRUE», если первая строка эквивалентна второй ( дом == дом ).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению ( дерево !== огонь ).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, « дерево > огонь » , поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, « огонь », поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 « -z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения « -n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test .

- Далее необходимо открыть терминал и запустить test на выполнение командой:
- Предварительно необходимо дать файлу право на исполнение командой:
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.


Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt .
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep . Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
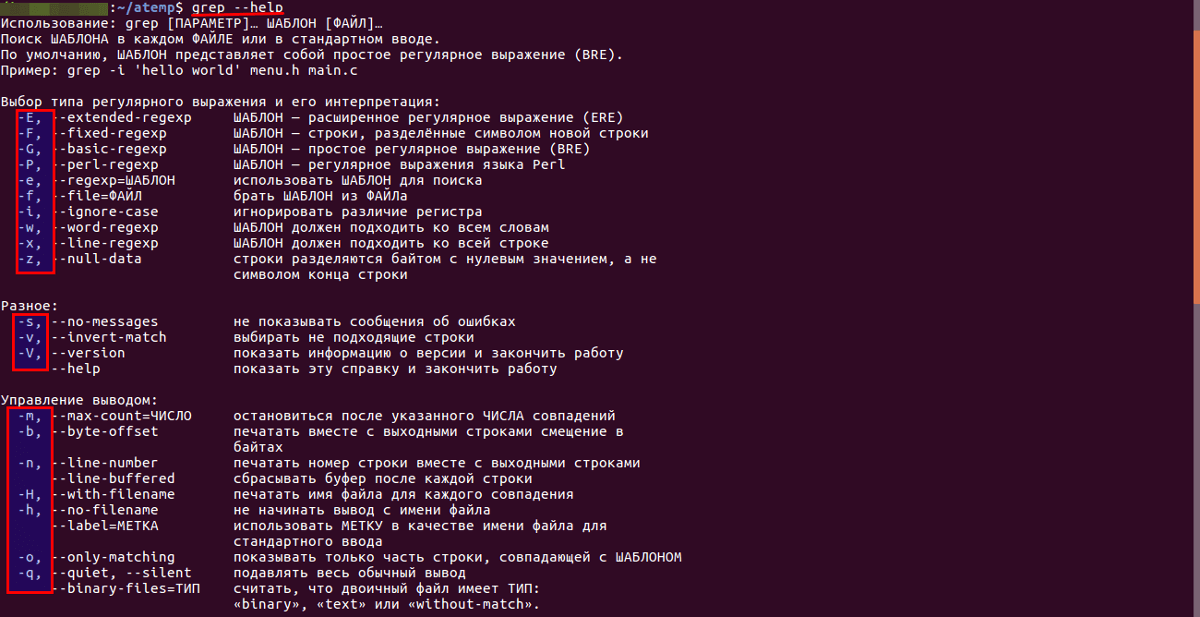
Основные опции
- Отобразить в консоли номер блока перед строкой — -b .
- Число вхождений шаблона строки — -с .
- Не выводить имя файла в результатах поиска — -h .
- Без учета регистра — -i .
- Отобразить только имена файлов с совпадением строки — -l .
- Показать номер строки — -n .
- Игнорировать сообщения об ошибках — -s .
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v .
- Слово, окруженное пробелами, — -w .
- Включить регулярные выражения при поиске — -e .
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn .
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
- Без учета регистра:
Вывод нескольких строк
- Строка с вхождением и две после нее:
- Строка с вхождением и три до нее:
- Строка, содержащая вхождение, и одну до и после нее:
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».
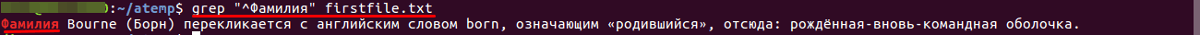 В регулярных выражения для обозначения начала строки используется специальный символ «^».
В регулярных выражения для обозначения начала строки используется специальный символ «^». Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкцию
grep «а.$» firstfile.txt . В этом случае будут выведены все строки, заканчивающиеся на литеру «а».

Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ « w »:
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.

- Число вхождений:
- Номера строк с совпадениями:
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
Использование sed
Потоковый текстовый редактор « sed » встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
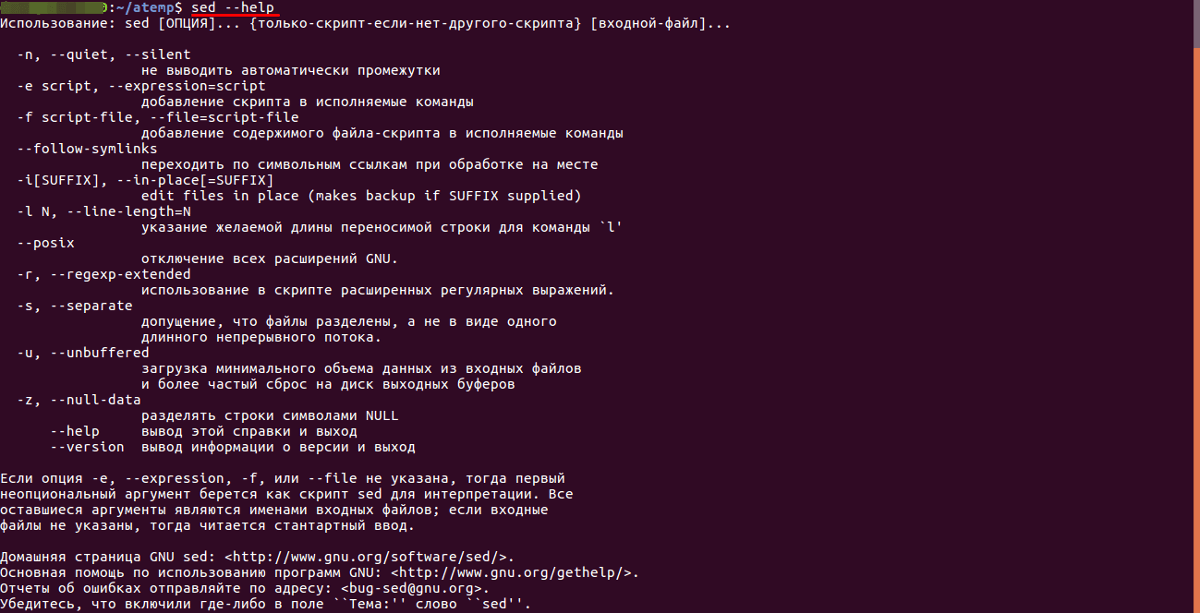
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
Распространенные конструкции с sed
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
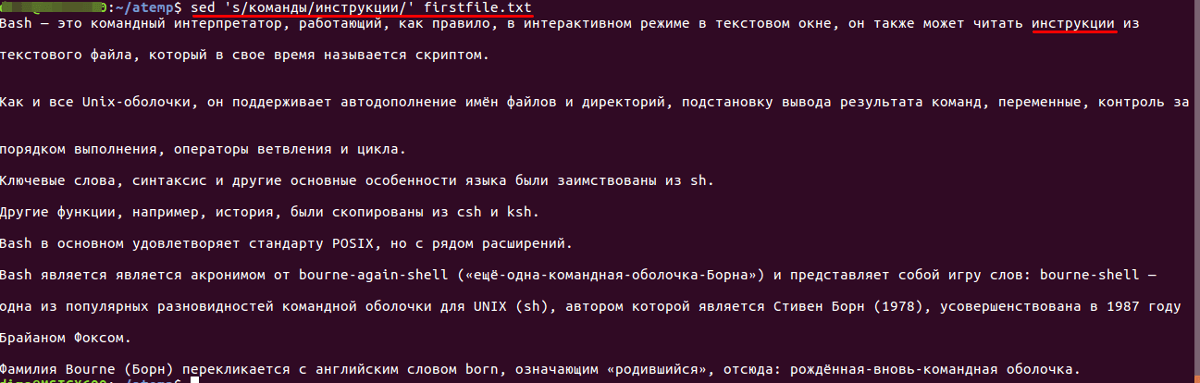
Произвести замену только в строках, которые заканчиваются на«Bash»:
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i :
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
- Удалить строку из файла, содержащую слово«окне»:
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
Удаление всех чисел из текста
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду « y »:
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:
sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
Начни экономить на хостинге сейчас — 14 дней бесплатно!
Источник



