- linux-notes.org
- Узнать размер Java Heap Memory Size
- Обзор памяти Java
- ТЕСТЫ или ГОТОВЫЕ примеры
- Предлагаемые для Java Memory
- Вывод
- Ограничить память процесса JVM
- Управление памятью Java
- Стек (Stack)
- Куча (Heap)
- Типы ссылок
- 1. Сильная ссылка
- 2. Слабая ссылка
- 3. Мягкая ссылка
- 4. Фантомная ссылка
- Ссылки на String
- Процесс сборки мусора
- Типы сборщиков мусора
- Советы и приемы
- Заключение
linux-notes.org
Узнать размер Java Heap Memory Size
Есть проблема с Java Heap Memory Size, ее нужно нормально указать для того чтобы все нормально работало ( например, веб- сервер tomcat, liferay, OpenMRS и так далее) и в данной статье «Узнать размер Java Heap Memory Size» расскажу как можно найти оптимальное значение для java.
Сейчас я покажу вам, как использовать-XX:+PrintFlagsFinal чтобы узнать ваш размер кучи «heap size». В Java, по умолчанию и максимальный размер кучи распределяются на основании алгоритма — эргономики (ergonomics algorithm).
Как же рассчитывается Heap sizes?
Начальный размер кучи — это соотношение 1/64 физической памяти к 1 Гб. (Initial heap size of 1/64 of physical memory up to 1Gbyte)
Максимальный размер кучи — это соотношение 1/4 физической памяти до 1 Гб. (Maximum heap size of 1/4 of physical memory up to 1Gbyte)
Тем не менее, алгоритм что выше, как раз для справки, могут варьироваться в разных VM.

Обзор памяти Java
Краткий обзор структуры памяти Java:
1. Java Heap Size
Место для хранения объектов, созданных приложением Java, это где Garbage Collection берет память для приложений Java. Для «тяжелого процесса Java», недостаточный размер кучи вызовет популярную ошибку: java.lang.OutOfMemoryError: Java heap space.
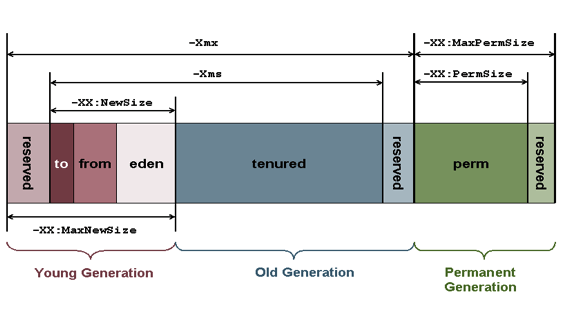
-Xms — Установить начальный размер Java куча «Java heap size»
-Xmx — Установить максимальный размер Java куча «Java heap size»
2. Размер Perm Gen (Perm Gen Size).
Место для хранения определение загруженного класса и метаданных. Если большой кодовый, базовый проект загружен, имеет недостаточный размер Perm Gen size то это вызовит ошибку: Java.Lang.OutOfMemoryError: PermGen.
-XX:PermSize — Установить начальный размер для параметра «PermGen Size».
-XX:MaxPermSize — Установить максимальный размер для параметра «PermGen Size».
3. Размер java стека «Java Stack Size»
Размер java нитей (Size of a Java thread). Если проект имеет много обработки нитей, попробуйте уменьшить этот размер стека, чтобы избежать нехватки памяти.
-Xss = Установить размер стека Java (java thread stack size).
ЗАМЕТКА
Значение по умолчанию для heap size, perm gen, или stack size отличаются от различных JVM. Лучшие практически всегда определить собственные значение для сервера.
ТЕСТЫ или ГОТОВЫЕ примеры
Приведу различные тесты на разных ОС.
Ubuntu
Среда тестирования имеет такие характеристики:
ОС : Ubuntu 13 (64 битная) (Под управлением VirtualBox)
RAM : 4Гб оперативной памяти
CPU : 1 x Процессор
JDK : 1.7
Выполним команду для отображения необходимой информации:
Для JVM выделено следующие значения по умолчанию:
Java heap size
InitialHeapSize = 64781184 байт (61.7 Мб) и MaxHeapSize = 1038090240 байт (990Мб).
PermGen Size
PermSize = 21757952 байт (20.75 Мб), MaxPermSize = 174063616 байт (166 Мб)
Thread Stack Size
ThreadStackSize = 1024 кб (1 Мб)
Выделенный размер кучи (heap memory size) довольно близок к результатам эргономики.
#ergonomics algorithm
Initial heap size = 4096M/64 = 64 Мб
Maximum heap size = 4096M/4 = 1024 Мб
Mac OS X
Среда тестирования имеет такие характеристики:
ОС : Mac OSX 10.9
RAM : 8 Гб оперативной памяти
CPU : 4 x Поцессор
JDK : 1.7
Запускаем команду чтобы проверить:
Узнать размер Java Heap Memory Size в macOS X
Для JVM выделено следующие значения по умолчанию:
Java heap size
InitialHeapSize = 20655360 байт (19.69M) и MaxHeapSize = 331350016 bytes (316 Мб).
PermGen Size
PermSize = 21757952 байт (20.75 Мб), MaxPermSize = 85983232 байт (82 Мб).
Java Stack Size
ThreadStackSize = 1024 Кб (1 Мб)
Выделенный размер кучи памяти (heap memory size) не имеют никакого значения, если сравнить со следующий результат по алгоритму эргономики.
#ergonomics algorithm
Initial heap size = 8192M/64 = 128 Мб
Maximum heap size = 8192M/4 = 2048 Мб
Windows
Grep нет в Windows, вместо этого, мы используем Findstr.
Среда тестирования имеет такие характеристики:
ОС : Windows 8
RAM : 16 Гб
CPU : 8 x процессор
JDK : 1.7
Узнать размер Java Heap Memory Size в windows
Для JVM в Windows ОС выделено следующие значения по умолчанию:
Java heap size
InitialHeapSize = 266634176 байт (256 Мб) и MaxHeapSize = 4266146816 байт (4068 Мб).
PermGen Size
PermSize = 21757952 байт (20.75 Мб), MaxPermSize = 85983232 bytes (823 Мб).
Java Stack Size
ThreadStackSize = 0 kilobytes. (weird…)
Выделенный размер кучи памяти почти такой же как и по алгоритму эргономика:
#ergonomics algorithm
Initial heap size = 16384/64 = 256 Мб
Maximum heap size = 16384/4 = 4096 Мб
Предлагаемые для Java Memory
Ниже, я привел мою рекомендацию (параметры) для малой и средней нагрузки приложений Java 🙂
Heap = -Xms512m -Xmx1024m
PermGen = -XX:PermSize=64m -XX:MaxPermSize=128m
Thread = -Xss512k
P.S: Для большинства проектов Java, 512k памяти для потока (thread) более чем достаточно.
оптимаьные значения для Java Heap Memory Size
Часто задаваемые вопросы.
какая -version?
Избегайте жалоб от компилятора Java, заменить «-version» с вашим именем приложения Java.
Что это -XX:+PrintCommandLineFlags?
Это -XX:+PrintCommandLineFlags используется для вывода значения,только для изменения VM (обозначается так: = символ).
Вывод
Наконец, значения по умолчанию для heap memory, perm gem и stack size отличается от JVM, не ожидайте что JVM будет использовать оптимальные значения для вашего приложения Java.
На этом, я завершаю «Узнать размер Java Heap Memory Size». Надеюсь, было познавательно.
Источник
Ограничить память процесса JVM
Такой вот вопрос организовался. Java при запуске всегда запускается с резервом памяти намного больше размера хипа вм. При этом этот резерв я так понимаю определяется общим размером озу машины на котором стартует вм. Пример: есть микросервис, запускается с Xmx32M, ему для работы этого всегда хватает. У меня на компе процесс вм скушает около гига памяти (16гб озу). На сервере 250мб (2гб озу), на оранжевом пи 64мб (256мб озу). Очевидно что для нормальной работы, ему явно не требуется > 64мб памяти, но по каким-то причинам, он жрет все что дают.
Вопрос — как ограничить память процесса java?


ему явно не требуется > 64мб памяти
Вопрос не в том, сколько памяти берётся, а в том, что взятая память не используется и не высвобождается. А зачем тогда она выделяется?
Сискол ядру на выделение памяти дорогая операция, например в сях в тех местах где нужно избегать пауз не делают malloc, а jvm один раз запрашивает вагон памяти а дальше сама менеджет памятью, т.е. выделение памяти под новые объекты обходятся дешевле нативного malloc’а.
jvm один раз запрашивает вагон памяти а дальше сама менеджет памятью
Так какого рожна именно это «менеджет памятью» не происходит, память не пользуется, но при этом на её обслуживание тратится cpu.
-Xmx -Xms -Xss не имеют отношения к размеру процесса. Все значения зафиксированы на 32М. Вопрос идет о памяти именно процесса ОС, который раздут во много раз больше чем размер хипа.
На её обслуживание cpu не тратится, т.к. как я понимаю jvm не занимается очисткой пока не достигнет некоторого лимита на занимаемую память.
Смотрел всякие конференции с рассказами про работу GC, где говори что jvm создает область для долгоживущих объектов и две области для короткоживущих, в первой области jvm может заняться например дефрагментацией (упреждая проблему фрагментации хипа), а вот области для короткоживущих объектов скорее всего создают «пилу» на графиках использования памяти. Если я не ошибаюсь новые объекты создаются в первой области короткоживущих объектов до тех пор пока не не будет достигнут лимит по выделенной памяти, затем происходит stop-the-world пауза (раньше так было) во время которой объекты на которых хоть кто-то ссыпается копируются из первой области во вторую область короткоживущих объектов, а исходная область уничтожается/отчищается. Т.е. чем меньше хип тем больше stop-the-world пауз, и все повторяется. Про stop-the-wrold так раньше было, сейчас кажется хитрее и пауз таких мало.
На её обслуживание cpu не тратится
Ха-ха-ха. Прочти свой же пост. Нифига себе не тратится.
Ну . 🙂 Призываю  stevejobs ‘а
stevejobs ‘а
А вообще я хотел сказать, что пока память не кончилась, jvm ничего делать не будет, никакого копирования из одной области в другую и прочего, в этом смысл был мой фразы что cpu не используется, правда из моих слов выходит, что потом должна возникнуть долгая паза, потому надеюсь stevejobs сможет разъяснить по работе gc или хотяб ссылку дать.
если все значения зафиксированы на 32M, то меньше 96 никак быть не может: Xmx + XX:MaxPermSize + 1*Xss и это только для случая 1 треда

При этом этот резерв я так понимаю определяется общим размером озу машины на котором стартует вм.
Если упростить, то да.
Вопрос — как ограничить память процесса java?

Да, старая жаба не отпускает память, которую потрогала.
Частично эта проблема решена только в свежих сборщиках. В том числе, в G1 — только начиная с Java 12
Попробуйте скачать сборку от Azul (в оракловой нет шенанды) и вначале пожить с G1, потом переключиться на шенанду ( -XX:+UseShenandoahGC).
начиная со слов «Promptly Return Unused Committed Memory from G1» (искать ctrl+F, потому что мне лень размечать хтмл-якори)
обратите внимание на флаги, которыми настраивается G1, если используете его
Ну и может быть, начать надо не с GC, а с того что начиная с OpenJDK 8 метаданные лежат не в пермгене, а в Метаспейсе, и метаспейс — это нативная память. По умолчанию она расширяется, но можно зафиксировать. Надо глянуть на ключики -XX:MetaspaceSize и -XX:MaxMetaspaceSize.
Я не уверен, где лежит в хотспоте code cache, но если тоже в оффхипе — проверьте что не делаете ничего *странного* в настройках JIT и тому подобного. То есть, если вы врубили Грааль, выключили tiered compilation и сказали собрать джитом всю программу, то наверное вы сами выпрыгнули без парашюта

Я даже не знаю что сказать. В гугле забанили?
Я рад тебя читать (хоть ты и странный). Кеш Джава машины лежит в среде самой Джава машины. Я вообще не понял, что ты хочешь донести.
Я не уверен, где лежит в хотспоте code cache
А зачем ты тогда ходишь на всякие «посиделки» и рассказываешь что ты мега джавист? Если ты мега круто всё по Джаве — тогда и пиши.
Источник
Управление памятью Java
Это глубокое погружение в управление памятью Java позволит расширить ваши знания о том, как работает куча, ссылочные типы и сборка мусора.
Вероятно, вы могли подумать, что если вы программируете на Java, то вам незачем знать о том, как работает память. В Java есть автоматическое управление памятью, красивый и тихий сборщик мусора, который работает в фоновом режиме для очистки неиспользуемых объектов и освобождения некоторой памяти.
Поэтому вам, как программисту на Java, не нужно беспокоиться о таких проблемах, как уничтожение объектов, поскольку они больше не используются. Однако, даже если в Java этот процесс выполняется автоматически, он ничего не гарантирует. Не зная, как устроен сборщик мусора и память Java, вы можете создать объекты, которые не подходят для сбора мусора, даже если вы их больше не используете.
Поэтому важно знать, как на самом деле работает память в Java, поскольку это дает вам преимущество в написании высокопроизводительных и оптимизированных приложений, которые никогда не будут аварийно завершены с ошибкой OutOfMemoryError . С другой стороны, когда вы окажетесь в плохой ситуации, вы сможете быстро найти утечку памяти.
Для начала давайте посмотрим, как обычно организована память в Java:
 Структура памяти
Структура памяти
Обычно память делится на две большие части: стек и куча. Имейте в виду, что размер типов памяти на этом рисунке не пропорционален реальному размеру памяти. Куча — это огромный объем памяти по сравнению со стеком.
Стек (Stack)
Стековая память отвечает за хранение ссылок на объекты кучи и за хранение типов значений (также известных в Java как примитивные типы), которые содержат само значение, а не ссылку на объект из кучи.
Кроме того, переменные в стеке имеют определенную видимость, также называемую областью видимости. Используются только объекты из активной области. Например, предполагая, что у нас нет никаких глобальных переменных (полей) области видимости, а только локальные переменные, если компилятор выполняет тело метода, он может получить доступ только к объектам из стека, которые находятся внутри тела метода. Он не может получить доступ к другим локальным переменным, так как они не выходят в область видимости. Когда метод завершается и возвращается, верхняя часть стека выталкивается, и активная область видимости изменяется.
Возможно, вы заметили, что на картинке выше отображено несколько стеков памяти. Это связано с тем, что стековая память в Java выделяется для каждого потока. Следовательно, каждый раз, когда поток создается и запускается, он имеет свою собственную стековую память и не может получить доступ к стековой памяти другого потока.
Куча (Heap)
Эта часть памяти хранит в памяти фактические объекты, на которые ссылаются переменные из стека. Например, давайте проанализируем, что происходит в следующей строке кода:
Ключевое слово new несет ответственность за обеспечение того, достаточно ли свободного места на куче, создавая объект типа StringBuilder в памяти и обращаясь к нему через «Builder» ссылки, которая попадает в стек.
Для каждого запущенного процесса JVM существует только одна область памяти в куче. Следовательно, это общая часть памяти независимо от того, сколько потоков выполняется. На самом деле структура кучи немного отличается от того, что показано на картинке выше. Сама куча разделена на несколько частей, что облегчает процесс сборки мусора.
Максимальные размеры стека и кучи не определены заранее — это зависит от работающей JVM машины. Позже в этой статье мы рассмотрим некоторые конфигурации JVM, которые позволят нам явно указать их размер для запускаемого приложения.
Типы ссылок
Если вы внимательно посмотрите на изображение структуры памяти, вы, вероятно, заметите, что стрелки, представляющие ссылки на объекты из кучи, на самом деле относятся к разным типам. Это потому, что в языке программирования Java используются разные типы ссылок: сильные, слабые, мягкие и фантомные ссылки. Разница между типами ссылок заключается в том, что объекты в куче, на которые они ссылаются, имеют право на сборку мусора по различным критериям. Рассмотрим подробнее каждую из них.
1. Сильная ссылка
Это самые популярные ссылочные типы, к которым мы все привыкли. В приведенном выше примере со StringBuilder мы фактически храним сильную ссылку на объект из кучи. Объект в куче не удаляется сборщиком мусора, пока на него указывает сильная ссылка или если он явно доступен через цепочку сильных ссылок.
2. Слабая ссылка
Попросту говоря, слабая ссылка на объект из кучи, скорее всего, не сохранится после следующего процесса сборки мусора. Слабая ссылка создается следующим образом:
Хорошим вариантом использования слабых ссылок являются сценарии кеширования. Представьте, что вы извлекаете некоторые данные и хотите, чтобы они также были сохранены в памяти — те же данные могут быть запрошены снова. С другой стороны, вы не уверены, когда и будут ли эти данные запрашиваться снова. Таким образом, вы можете сохранить слабую ссылку на него, и в случае запуска сборщика мусора, возможно, он уничтожит ваш объект в куче. Следовательно, через некоторое время, если вы захотите получить объект, на который вы ссылаетесь, вы можете внезапно получить null значение. Хорошей реализацией сценариев кеширования является коллекция WeakHashMap . Если мы откроем WeakHashMap класс в Java API, мы увидим, что его записи фактически расширяют WeakReference класс и используют его поле ref в качестве ключа отображения ( Map) :
После сбора мусора ключа из WeakHashMap вся запись удаляется из карты.
3. Мягкая ссылка
Эти типы ссылок используются для более чувствительных к памяти сценариев, поскольку они будут собираться сборщиком мусора только тогда, когда вашему приложению не хватает памяти. Следовательно, пока нет критической необходимости в освобождении некоторого места, сборщик мусора не будет касаться легко доступных объектов. Java гарантирует, что все объекты, на которые имеются мягкие ссылки, будут очищены до того, как будет выдано исключение OutOfMemoryError . В документации Javadocs говорится, что «все мягкие ссылки на мягко достижимые объекты гарантированно очищены до того, как виртуальная машина выдаст OutOfMemoryError».
Подобно слабым ссылкам, мягкая ссылка создается следующим образом:
4. Фантомная ссылка
Используется для планирования посмертных действий по очистке, поскольку мы точно знаем, что объекты больше не живы. Используется только с очередью ссылок, поскольку .get() метод таких ссылок всегда будет возвращаться null . Эти типы ссылок считаются предпочтительными для финализаторов.
Ссылки на String
Ссылки на тип String в Java обрабатываются немного по- другому. Строки неизменяемы, что означает, что каждый раз, когда вы делаете что-то со строкой, в куче фактически создается другой объект. Для строк Java управляет пулом строк в памяти. Это означает, что Java сохраняет и повторно использует строки, когда это возможно. В основном это верно для строковых литералов. Например:
При запуске этот код распечатывает следующее:
Strings are equal
Следовательно, оказывается, что две ссылки типа String на одинаковые строковые литералы фактически указывают на одни и те же объекты в куче. Однако это не действует для вычисляемых строк. Предположим, что у нас есть следующее изменение в строке // 1 приведенного выше кода.
Strings are different
В этом случае мы фактически видим, что у нас есть два разных объекта в куче. Если учесть, что вычисляемая строка будет использоваться довольно часто, мы можем заставить JVM добавить ее в пул строк, добавив .intern() метод в конец вычисляемой строки:
При добавлении вышеуказанного изменения создается следующий результат:
Процесс сборки мусора
Как обсуждалось ранее, в зависимости от типа ссылки, которую переменная из стека содержит на объект из кучи, в определенный момент времени этот объект становится подходящим для сборщика мусора.
 Объекты, подходящие для сборки мусора
Объекты, подходящие для сборки мусора
Например, все объекты, отмеченные красным цветом, могут быть собраны сборщиком мусора. Вы можете заметить, что в куче есть объект, который имеет строгие ссылки на другие объекты, которые также находятся в куче (например, это может быть список, который имеет ссылки на его элементы, или объект, имеющий два поля типа, на которые есть ссылки). Однако, поскольку ссылка из стека потеряна, к ней больше нельзя получить доступ, так что это тоже мусор.
Чтобы углубиться в детали, давайте сначала упомянем несколько вещей:
Этот процесс запускается автоматически Java, и Java решает, запускать или нет этот процесс.
На самом деле это дорогостоящий процесс. При запуске сборщика мусора все потоки в вашем приложении приостанавливаются (в зависимости от типа GC, который будет обсуждаться позже).
На самом деле это более сложный процесс, чем просто сбор мусора и освобождение памяти.
Несмотря на то, что Java решает, когда запускать сборщик мусора, вы можете явно вызвать System.gc() и ожидать, что сборщик мусора будет запускаться при выполнении этой строки кода, верно?
Это ошибочное предположение.
Вы только как бы просите Java запустить сборщик мусора, но, опять же, Java решать, делать это или нет. В любом случае явно вызывать System.gc() не рекомендуется.
Поскольку это довольно сложный процесс и может повлиять на вашу производительность, он реализован разумно. Для этого используется так называемый процесс «Mark and Sweep». Java анализирует переменные из стека и «отмечает» все объекты, которые необходимо поддерживать в рабочем состоянии. Затем все неиспользуемые объекты очищаются.
Так что на самом деле Java не собирает мусор. Фактически, чем больше мусора и чем меньше объектов помечены как живые, тем быстрее идет процесс. Чтобы сделать это еще более оптимизированным, память кучи на самом деле состоит из нескольких частей. Мы можем визуализировать использование памяти и другие полезные вещи с помощью JVisualVM, инструмента, поставляемого с Java JDK. Единственное, что вам нужно сделать, это установить плагин с именем Visual GC, который позволяет увидеть, как на самом деле структурирована память. Давайте немного увеличим масштаб и разберем общую картину:
 Поколения памяти кучи
Поколения памяти кучи
Когда объект создается, он размещается в пространстве Eden (1). Поскольку пространство Eden не такое уж большое, оно заполняется довольно быстро. Сборщик мусора работает в пространстве Eden и помечает объекты как живые.
Если объект выживает в процессе сборки мусора, он перемещается в так называемое пространство выжившего S0(2). Во второй раз, когда сборщик мусора запускается в пространстве Eden, он перемещает все уцелевшие объекты в пространство S1(3). Кроме того, все, что в настоящее время находится на S0(2), перемещается в пространство S1(3).
Если объект выживает в течение X раундов сборки мусора (X зависит от реализации JVM, в моем случае это 8), скорее всего, он выживет вечно и перемещается в пространство Old(4).
Принимая все сказанное выше, если вы посмотрите на график сборщика мусора (6), каждый раз, когда он запускается, вы можете увидеть, что объекты переключаются на пространство выживших и что пространство Эдема увеличивалось. И так далее. Старое поколение также может быть обработано сборщиком мусора, но, поскольку это большая часть памяти по сравнению с пространством Eden, это происходит не так часто. Метапространство (5) используется для хранения метаданных о ваших загруженных классах в JVM.
Представленное изображение на самом деле является приложением Java 8. До Java 8 структура памяти была немного другой. Метапространство на самом деле называется PermGen область. Например, в Java 6 это пространство также хранит память для пула строк. Поэтому, если в вашем приложении Java 6 слишком много строк, оно может аварийно завершить работу.
Типы сборщиков мусора
Фактически, JVM имеет три типа сборщиков мусора, и программист может выбрать, какой из них следует использовать. По умолчанию Java выбирает используемый тип сборщика мусора в зависимости от базового оборудования.
1. Serial GC (Последовательный сборщик мусора) — однониточный коллектор. В основном относится к небольшим приложениям с небольшим использованием данных. Можно включить, указав параметр командной строки: -XX:+UseSerialGC.
2. Parallel GC (Параллельный сборщик мусора) — даже по названию, разница между последовательным и параллельным будет заключаться в том, что параллельный сборщик мусора использует несколько потоков для выполнения процесса сбора мусора. Этот тип GC также известен как сборщик производительности. Его можно включить, явно указав параметр: -XX:+UseParallelGC.
3. Mostly concurrent GC (В основном параллельный сборщик мусора). Если вы помните, ранее в этой статье упоминалось, что процесс сбора мусора на самом деле довольно дорогостоящий, и когда он выполняется, все потоки приостанавливаются. Однако у нас есть в основном параллельный тип GC, который утверждает, что он работает одновременно с приложением. Однако есть причина, по которой он «в основном» параллелен. Он не работает на 100% одновременно с приложением. Есть период времени, на который цепочки приостанавливаются. Тем не менее, пауза делается как можно короче для достижения наилучшей производительности сборщика мусора. На самом деле существует 2 типа в основном параллельных сборщиков мусора:
3.1 Garbage First — высокая производительность с разумным временем паузы приложения. Включено с опцией: -XX:+UseG1GC.
3.2 Concurrent Mark Sweep (Параллельное сканирование отметок) — время паузы приложения сведено к минимуму. Он может быть использован с помощью опции: -XX:+UseConcMarkSweepGC . Начиная с JDK 9, этот тип GC объявлен устаревшим.
Примечание переводчика. Информация про сборщики мусора для различных версий Java приведена в переводе:
Советы и приемы
Чтобы минимизировать объем памяти, максимально ограничьте область видимости переменных. Помните, что каждый раз, когда выскакивает верхняя область видимости из стека, ссылки из этой области теряются, и это может сделать объекты пригодными для сбора мусора.
Явно устанавливайте в null устаревшие ссылки. Это сделает объекты, на которые ссылаются, подходящими для сбора мусора.
Избегайте финализаторов (finalizer). Они замедляют процесс и ничего не гарантируют. Фантомные ссылки предпочтительны для работы по очистке памяти.
Не используйте сильные ссылки там, где можно применить слабые или мягкие ссылки. Наиболее распространенные ошибки памяти — это сценарии кэширования, когда данные хранятся в памяти, даже если они могут не понадобиться.
JVisualVM также имеет функцию создания дампа кучи в определенный момент, чтобы вы могли анализировать для каждого класса, сколько памяти он занимает.
Настройте JVM в соответствии с требованиями вашего приложения. Явно укажите размер кучи для JVM при запуске приложения. Процесс выделения памяти также является дорогостоящим, поэтому выделите разумный начальный и максимальный объем памяти для кучи. Если вы знаете его, то не имеет смысла начинать с небольшого начального размера кучи с самого начала, JVM расширит это пространство памяти. Указание параметров памяти выполняется с помощью следующих параметров:
Начальный размер кучи -Xms512m — установите начальный размер кучи на 512 мегабайт.
Максимальный размер кучи -Xmx1024m — установите максимальный размер кучи 1024 мегабайта.
Размер стека потоков -Xss1m — установите размер стека потоков равным 1 мегабайту.
Размер поколения -Xmn256m — установите размер поколения 256 мегабайт.
Если приложение Java выдает ошибку OutOfMemoryError и вам нужна дополнительная информация для обнаружения утечки, запустите процесс с –XX:HeapDumpOnOutOfMemory параметром, который создаст файл дампа кучи, когда эта ошибка произойдет в следующий раз.
Используйте опцию -verbose:gc , чтобы получить вывод процесса сборки мусора. Каждый раз, когда происходит сборка мусора, будет генерироваться вывод.
Заключение
Знание того, как организована память, дает вам преимущество в написании хорошего и оптимизированного кода с точки зрения ресурсов памяти. Преимущество заключается в том, что вы можете настроить свою работающую JVM, предоставив различные конфигурации, наиболее подходящие для запуска вашего приложения. Выявление и устранение утечек памяти — это очень просто, если использовать правильные инструменты.
Источник



