- Команда cut в Linux
- Синтаксис
- Опции и их описания с примерами
- Еще несколько полезных примеров
- Заключение
- Команда sed Linux
- Команда sed в Linux
- 1. Как работает sed
- 2. Адреса sed
- 3. Синтаксис регулярных выражений
- 4. Команды sed
- Примеры использования sed
- Выводы
- Команда Cut в Linux с примерами
- Linux Cut Command with Examples
- В этом руководстве мы покажем вам, как использовать cut команду, на практических примерах и подробных объяснениях наиболее распространенных опций.
- Как использовать cut команду
- Как вырезать по полю
- Как резать на основе разделителя
- Как дополнить выбор
- Как указать выходной разделитель
- Как вырезать из байтов и символов
- Примеры
- Получить список всех пользователей
- Посмотреть 10 наиболее часто используемых команд
- Вывод
Команда cut в Linux
Команда cut вырезает участки каждой строки файла и выводит результаты в стандартный поток вывода. Она может вырезать часть строки по расположению байта, символу и полю. В сущности она разрезает строку на участки и извлекает из них текст. С этой командой обязательно нужно указывать опции, иначе она выдаст ошибку. Если указать несколько файлов, то при выводе данных имена файлов перед ними не выводятся. Команда работает как с файлами так и с выводом из другой команды.
Синтаксис
Допустим, у нас есть файл state.txt, содержащий названия 5 государств:
Если опций не указывать, то команда выдаст ошибку:
Опции и их описания с примерами
1. -b (byte, байт): используется для извлечения заданных байтов, номера которых указываются после опции через запятую. Можно указать диапазоны через дефис. Если не указать ничего, команда выдаст ошибку. Символы табуляции и пробелы рассматриваются как символы размером в один байт.
Для выбора байтов от заданной позиции до конца строки используется следующая форма:
Аналогичным образом можно указать байты от начала строки до заданной позиции:
2. -c (column, столбец): используется для вырезания по символам. Это также может быть список символов, указанных через запятую, или диапазон, заданный через дефис. Символы табуляции и пробела интерпретируются как один символ. Номера символов указывать обязательно, иначе команда выдаст ошибку.
где k – начальный символ, а n – конечный, если они разделены дефисом, либо просто позиции символов, указанные через запятую.
Следующая команда вырезает второй, пятый и седьмой символы строк:
А эта команда – выводит первые семь символов каждой строки файла:
Интервалы от заданной позиции до конца строки и от начала строки до заданной позиции задаются аналогично предыдущей опции:
3. -f (field, поле): опция -с полезна для строк фиксированной длины, однако в большинстве файлов они не встречаются. Вам потребуется вырезать данные по полям, а не по столбцам, чтобы получить нужную информацию. Для этого используется опция -f. Номера полей должны разделяться запятыми. Данная опция не позволяет указывать диапазоны. По умолчанию в качестве разделителя полей используется символ табуляции, но при помощи опции -d можно задать другой разделитель.
Важно: по умолчанию пробел не является разделителем.
В файле state.txt поля разделены пробелами, и если не использовать опцию -d, строки будут выводиться целиком:
При помощи опции -d можно задать в качестве разделителя пробел:
Было выведено каждое слово до пробела.
4. –complement: используется с другими опциями, например, -f или -c, и инвертирует опции вывода:
5. –output-delimiter: По умолчанию разделитель выводимых данных такой же, как указанный в опции -d. Чтобы его изменить, воспользуйтесь опцией –output-delimiter. Следующая команда задает в качестве разделителя вывода символ «%» и выводит 1 и 2 поля с опцией -f:
6. –version: Выводит информацию о версии команды:
7. –help: Выводит справочную информацию.
Еще несколько полезных примеров
| Команда | Описание |
| free | grep Mem | sed ‘s/\s\+/,/g’ | cut -d , -f2 | Показывает объем памяти текущей системы |
| cat /proc/cpuinfo | grep «name» | cut -d : -f2 | uniq | Возвращает тип CPU |
| wget -q -O X http://ipchicken.com/ grep ‘^ \<8\>1’ X | sed ‘s/\s\+/,/g’ | cut -d , -f2 | Возвращает мой внешний IP-адрес |
| cut -d : -f 1 /etc/passwd | Извлекает список пользователей текущей системы |
| Получает MAC-адрес моих сетевых интерфейсов | |
| who | cut -d \s -f1 | Вывод список пользователей, авторизованных в текущей системе |
| grep -w /etc/services | cut -f 1 | uniq | Показывает, какая служба использует порт . |
Заключение
Команда cut очень простая, но широко используется для работы с текстовыми данными, часто в сочетании с другими командами, такими как cat или sort. Мы разобрали практически все ее опции. Однако, в разных системах версии команды и ее опции могут немного отличаться, для уточнения обратитесь к соответствующим man-страницам.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Команда sed Linux
Команда sed — это потоковый редактор текста, работающий по принципу замены. Его можно использовать для поиска, вставки, замены и удаления фрагментов в файле. С помощью этой утилиты вы можете редактировать файлы не открывая их. Будет намного быстрее если вы напишите что и на что надо заменить, чем вы будете открывать редактор vi, искать нужную строку и вручную всё заменять.
В этой статье мы рассмотрим основы использования команды sed linux, её синтаксис, а также синтаксис регулярных выражений, который используется непосредственно для поиска и замены в файлах.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая
шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
число
— начиная от строки номер и до строки номер которой будет кратный числу.Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \ — любой символ в количестве i;
- \ — любой символ в количестве от i до j;
- \ — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла строки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:
sed -n ‘5,10p’ /etc/group
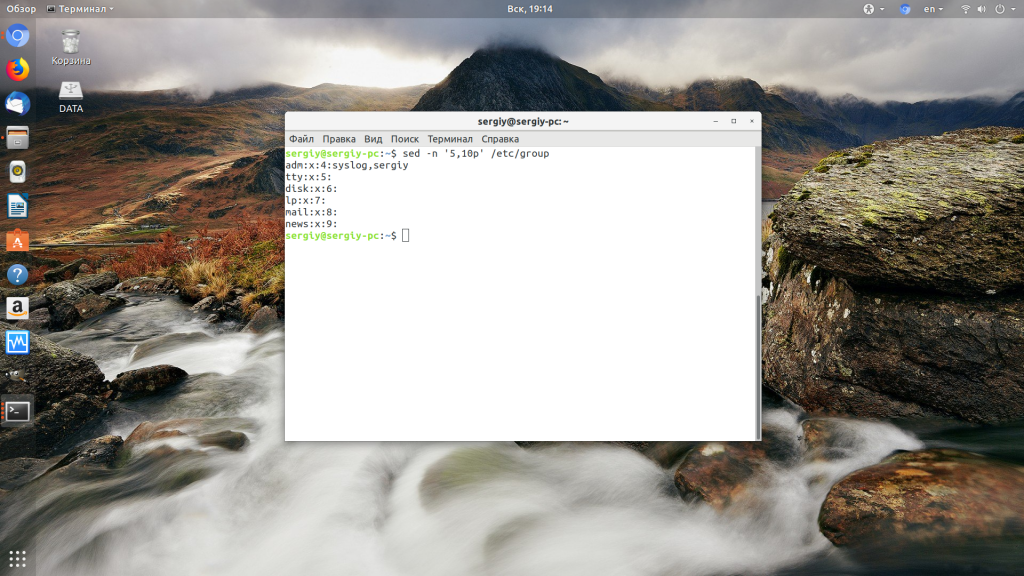
Или можно вывести весь файл, кроме строк с первой по двадцатую:
sed ‘1,20d’ /etc/group

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:
sed ‘s/root/losst/g’ /etc/group

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:
sed ‘1,10 s/0/1000/g’ /etc/group

Переходим ещё ближе к регулярным выражениям, удалим все пустые строки или строки с комментариями из конфига Apache:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:
sed ‘s/[$p*]/losst_p/g’ /etc/group

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf | sudo tee /etc/apache2/apache2.conf
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:
sudo sed -i ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.
Выводы
Из этой статьи вы узнали что представляет из себя команда sed Linux. Как видите, это очень гибкий инструмент, который позволяет делать с текстом очень многое. Он сложный в освоении, но с помощью него очень удобно решать многие задачи редактирования конфигурационных файлов или фильтрации вывода.
Источник
Команда Cut в Linux с примерами
Linux Cut Command with Examples
В этом руководстве мы покажем вам, как использовать cut команду, на практических примерах и подробных объяснениях наиболее распространенных опций.

В системах Linux и Unix доступно множество утилит, позволяющих обрабатывать и фильтровать текстовые файлы. cut утилита командной строки, которая позволяет вырезать части строк из указанных файлов или данных по конвейеру и выводить результат в стандартный вывод. Его можно использовать для вырезания частей строки по разделителю, позиции байта и символу.
Как использовать cut команду
Синтаксис cut команды следующий:
Параметры, указывающие cut , использовать ли разделитель, позицию байта или символ при вырезании выделенных частей, выглядят следующим образом:
- -f ( —fields=LIST ) — Выберите, указав поле, набор полей или диапазон полей. Это наиболее часто используемый вариант.
- -b ( —bytes=LIST ) — Выберите, указав байт, набор байтов или диапазон байтов.
- -c ( —characters=LIST ) — Выберите, указав символ, набор символов или диапазон символов.
Вы можете использовать один и только один из вариантов, перечисленных выше.
- -d ( —delimiter ) — Укажите разделитель, который будет использоваться вместо разделителя «TAB» по умолчанию.
- —complement — дополнить выбор. При использовании этого параметра cut отображаются все байты, символы или поля, кроме выбранного.
- -s ( —only-delimited ) — по умолчанию cut печатает строки, которые не содержат символов-разделителей. Когда эта опция используется, cut не печатать строки, не содержащие разделителей.
- —output-delimiter — По умолчанию cut используется входной разделитель в качестве выходного разделителя. Эта опция позволяет вам указать другую строку выходного разделителя.
Команда cut может принимать ноль или более входных имен FILE. Если не FILE указано, или когда FILE есть — , cut будет читать со стандартного ввода.
LIST Аргумент , переданный -f , -b и -c варианты могут быть целым числом, несколько целых чисел , разделенных запятыми, диапазон целых чисел или нескольких диапазонов целочисленных разделенных запятыми. Каждый диапазон может быть одним из следующих:
- N N-е поле, байт или символ, начиная с 1.
- N- от N-го поля, байта или символа до конца строки.
- N-M от N-го до M-го поля, байта или символа.
- -M от первого до M-го поля, байта или символа.
Как вырезать по полю
Чтобы указать поля, которые должны быть вырезаны, вызовите команду с -f опцией. Если не указан, по умолчанию используется разделитель «TAB».
В приведенных ниже примерах мы будем использовать следующий файл. Поля разделены вкладками.
Например, для отображения 1-го и 3-го полей вы должны использовать:
Или, если вы хотите отобразить с 1-го по 4-е поле:
Как резать на основе разделителя
Чтобы вырезать на основе разделителя, вызовите команду с -d параметром, а затем разделитель, который вы хотите использовать.
Например, чтобы отобразить 1-е и 3-е поля, используя «:» в качестве разделителя, введите:
Вы можете использовать любой отдельный символ в качестве разделителя. В следующем примере мы используем символ пробела в качестве разделителя и печатаем 2-е поле:
Как дополнить выбор
Для дополнения списка полей выбора используйте —complement опцию. Это напечатает только те поля, которые не выбраны с -f опцией.
Следующая команда напечатает все поля кроме 1-го и 3-го:
Как указать выходной разделитель
Чтобы указать выходной разделитель, используйте —output-delimiter опцию. Например, чтобы установить для _ вас выходной разделитель , используйте:
Как вырезать из байтов и символов
Прежде чем идти дальше, давайте сделаем различие между байтами и символами.
Один байт составляет 8 битов и может представлять 256 различных значений. Когда был установлен стандарт ASCII, в нем были учтены все буквы, цифры и символы, необходимые для работы с английским языком. Таблица символов ASCII имеет 128 символов, и каждый символ представлен одним байтом. Когда компьютеры стали доступны во всем мире, технологические компании начали вводить новые кодировки символов для разных языков. Для языков, содержащих более 256 символов, простое сопоставление 1 к 1 было невозможно. Это приводит к различным проблемам, таким как совместное использование документов или просмотр веб-сайтов, и был необходим новый стандарт Unicode, который может работать с большинством мировых систем письма. UTF-8 был создан для решения этих проблем. В UTF-8 не все символы представлены 1 байтом. Символы могут быть представлены от 1 байта до 4 байтов.
Опция -b ( —bytes ) указывает команде вырезать секции из каждой строки, заданной заданными позициями байтов.
В следующих примерах мы используем ü символ, который занимает 2 байта.
Выберите 5-й байт:
Выберите 5-й, 9-й и 13-й байты:
Выберите диапазон от 1-го до 5-го байта:
На момент написания этой статьи версия пакета cut в GNU coreutils не имела возможности обрезать по символам. При использовании -c параметра cut ведет себя так же, как при использовании -b параметра.
Примеры
Команда cut обычно используется в сочетании с другими командами через трубопровод. Вот несколько примеров:
Получить список всех пользователей
Выходные данные getent passwd команды передаются в cut , который печатает 1-е поле, используя в : качестве разделителя.
Посмотреть 10 наиболее часто используемых команд
В следующем примере cut используется для удаления первых 8 байтов из каждой строки history вывода команды.
Вывод
cut Команда используется для отображения выбранных полей из каждой строки заданных файлов или стандартного ввода.
Хотя это очень полезно, cut имеет некоторые ограничения. Он не поддерживает указание более одного символа в качестве разделителя и не поддерживает несколько разделителей.
Источник



