- Просмотр содержимого файлов в командной строке Linux
- Команда cat
- Команда nl
- Команда less
- Команда more
- Команда head
- Команда tail
- Заключение
- ПРОСМОТР СОДЕРЖИМОГО ФАЙЛА В LINUX
- ПРОСМОТР ФАЙЛА В LINUX ПОЛНОСТЬЮ
- ПРОСМОТР ФАЙЛА В LINUX С ПРОКРУТКОЙ
- ПРОСМОТР ТОЛЬКО НАЧАЛА ИЛИ КОНЦА ФАЙЛА
- ПРОСМОТР СОДЕРЖИМОГО ФАЙЛА ПО ШАБЛОНУ
- ПРОСМОТР ФАЙЛОВ LINUX В СЖАТОМ ВИДЕ
- EOF — это не символ
- EOF — это не символ
- В конце файлов нет некоего особого символа
- Что такое EOF?
- ANSI C
- Python 3
- JavaScript (Node.js)
- Низкоуровневые системные механизмы
- Итоги
Просмотр содержимого файлов в командной строке Linux

Рассмотрим несколько команд, которые используются для просмотра содержимого текстовых файлов в командной строке Linux.
Команда cat
Команда cat выводит содержимое файла, который передается ей в качестве аргумента.
Это самый простой и наиболее часто используемый способ для вывода содержимого текстовых файлов. Но выводить большие файлы через cat не всегда удобно.
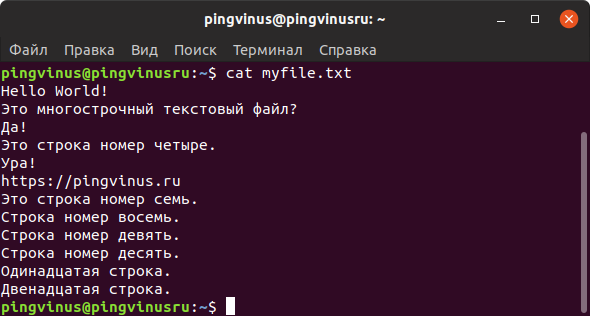
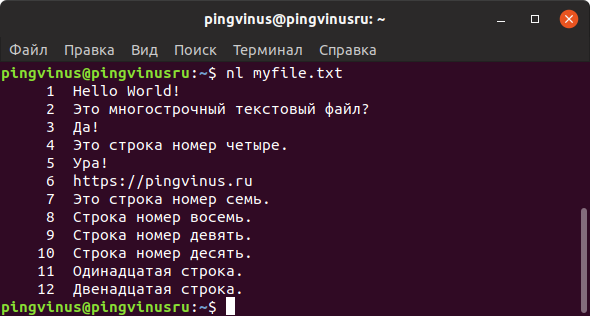
Команда nl
Команда nl действует аналогично команде cat , но выводит еще и номера строк в столбце слева.
Команду nl удобно применять для просмотра программного кода или поиска строк в файлах конфигурации.
Команда less
Утилита less выводит содержимое файла, но отображает его только в рамках текущего окна в режиме просмотра.
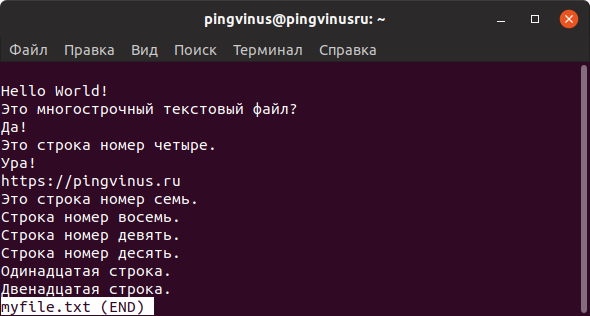
Вы можете прокручивать текст файла клавишами стрелок или перелистывать страницы клавишами w и z .
Для поиска текста внутри файла нажмите / .
Для просмотра списка доступных горячих клавиш нажмите h
Чтобы выйти из режима просмотра используется клавиша q .
Очень удобно, что после выхода окно терминала остается чистым и не содержит текст файла.
Команда more
Команда more очень похожа на команду less . Она также выводит файл в терминале в режиме просмотра, но имеет некоторые отличия от команды less.
Например, less в конце файла выводит сообщение (END) (или EOF — End Of File) и ожидает нажатия клавиши q чтобы закрыть режим просмотра, а more по достижении конца файла сразу возвращает управление в терминал.
Также more после своей работы оставляет текст файла в терминале, а less работает «чисто» и не сохраняет текст в терминале.
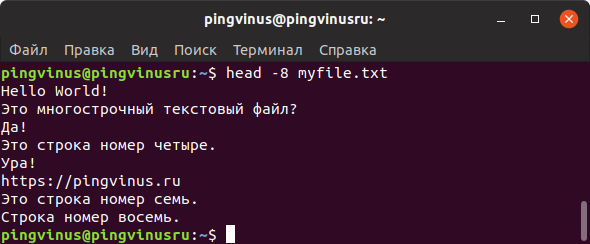
Команда head
Команда head выводит на экран только первые 10 строк файла.
Используя опцию -n можно задать количество строк, которое нужно вывести. Например, чтобы вывести 15 строк используется команда:
Вместо -n можно просто использовать знак минус — , за которым сразу указывается количество строк.
Команда tail
Команда tail аналогична команде head , но выводит последние 10 строк файла.
Заключение
Команды, которые мы рассмотрели, имеют дополнительные возможности и области применения. Для получения справки по каждой команде можно воспользоваться Man-страницами.
Источник
ПРОСМОТР СОДЕРЖИМОГО ФАЙЛА В LINUX
В Linux все настройки, все логи, и почти вся информация хранится в обычных текстовых файлах. Важно уметь правильно и эффективно посмотреть содержимое файла linux с помощью терминала. Это еще одна из статей, ориентированных на новичков. Вот вы скажете, а что их там открывать, открыл и посмотрел, и все. Да, но не совсем, терминал Linux настолько гибкий инструмент, что даже обычный просмотр файлов можно очень сильно оптимизировать. Просмотр содержимого файлов Linux — это тоже искусство. В этой инструкции мы рассмотрим все команды, с помощью которых можно открыть текстовый файл linux, поговорим о том как ими пользоваться, а также приведем несколько примеров.
ПРОСМОТР ФАЙЛА В LINUX ПОЛНОСТЬЮ
Самая простая и в то же время наиболее часто используемая утилита для просмотра содержимого файла linux — cat. Выводит все содержимое файла в стандартный вывод. В параметре нужно передать только адрес файла, или нескольких файлов. Идеально подходит для просмотра небольших файлов. Общий синтаксис команды cat такой:
cat опции адрес_файла .
Например просмотр содержимого файла linux /etc/passwd:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
adm:x:3:4:adm:/var/adm:/bin/false
lp:x:4:7:lp:/var/spool/lpd:/bin/false
sync:x:5:0:sync:/sbin:/bin/sync
Также можно посмотреть сразу несколько файлов:
Hello everybody
Hi world,
Опция -n включает нумерацию строк:
cat -n /var/log/Xorg.0.log
1 [ 85.675]
2 X.Org X Server 1.17.4
3 Release Date: 2015-10-28
4 [ 85.675] X Protocol Version 11, Revision 0
5 [ 85.675] Build Operating System: Linux 4.0.5-gentoo x86_64 Gentoo
6 [ 85.675] Current Operating System: Linux seriyyy95-pc 4.1.12-gentoo #2 SMP Tue Dec 29 14:50:59 EET 2015 x86_64
Для удобства, можно включить отображение в конце каждой строки символа $
hello everyone, how do you do?$
$
Hey, am fine.$
А также отображение табуляций, все табуляции будут заменены на символ ^I:
hello ^Ieveryone, how do you do?
Больше о ней говорить не будем, потому что большинство ее опций направлены на форматирование вывода, и вы сможете их легко изучить выполнив:
Есть еще одна очень похожая на cat утилита — tac. Принимает те же параметры и делает то же самое, только наоборот — выполняет вывод содержимого файла linux в обратном порядке — с конца:
ПРОСМОТР ФАЙЛА В LINUX С ПРОКРУТКОЙ
Если файл очень длинный и его содержимое не помещается на одном экране, cat использовать не очень удобно. для таких случаев есть less. Синтаксис тот же:
$ less опции файл
Также ее можно комбинировать с cat:
$ cat адрес_файла | less
Например, посмотрим лог Х сервера:
Теперь мы можем листать содержимое файла в Linux с помощью стрелок вверх-вниз. Для того чтобы выйти нажмите q. Также эта утилита поддерживает поиск. Для поиска по файлу нажмите слеш «/». О более правильном способе поиска мы поговорим дальше.
ПРОСМОТР ТОЛЬКО НАЧАЛА ИЛИ КОНЦА ФАЙЛА
Очень часто нам не нужен файл целиком. Например, достаточно посмотреть несколько последних строчек лога, чтобы понять суть ошибки, или нужно увидеть только начало конфигурационного файла. Для таких случаев тоже есть команды. Это head и tail (голова и хвост).
По умолчанию head открывает текстовый файл в Linux и показывает только десять первых строчек переданного в параметре файла:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
adm:x:3:4:adm:/var/adm:/bin/false
lp:x:4:7:lp:/var/spool/lpd:/bin/false
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
news:x:9:13:news:/var/spool/news:/bin/false
uucp:x:10:14:uucp:/var/spool/uucp:/bin/false
Можно открыть сразу два текстовых файла в Linux одновременно:
head /etc/passwd /etc/shadow
Так можно открыть текстовый файл linux или несколько и вывести по десять первых строчек каждого из них.
Если вам не нужны все 10 строчек, опцией -n и цифрой можно указать количество строк которые нужно вывести. Например, 5:
head -n5 /var/log/emerge.log
1394924012: Started emerge on: Mar 15, 2014 22:53:31
1394924012: *** emerge —sync
1394924012: === sync
1394924012: >>> Synchronization of repository ‘gentoo’ located in ‘/usr/portage’.
1394924027: >>> Starting rsync with rsync://212.113.35.39/gentoo-portage
Тот же результат можно получить опустив букву n и просто передав цифру в качестве ключа:
head -5 /var/log/emerge.log
Также можно задать количество байт, которые нужно вывести с помощью опции -с и числа. Например: 45:
head -c45 /var/log/emerge.log
1394924012: Started emerge on: Mar 15, 2014 2
Тоже хотите подсчитать действительно ли там 45 символов? Используйте команду wc:
head -c45 /var/log/emerge.log | wc -c
Команда tail наоборот, выводит 10 последних строк из файла:
[ 141.977] (—) NVIDIA(GPU-0):
[ 141.977] (—) NVIDIA(GPU-0): DFP-1: disconnected
[ 141.977] (—) NVIDIA(GPU-0): DFP-1: Internal TMDS
[ 141.977] (—) NVIDIA(GPU-0): DFP-1: 165.0 MHz maximum pixel clock
[ 141.977] (—) NVIDIA(GPU-0):
Утилита tail тоже поддерживает изменение количества строк, с помощью опции -n. Но она обладает еще одной интересной и очень полезной опцией -f. Она позволяет постоянно обновлять содержимое файла и, таким образом, видеть все изменения сразу, а не постоянно закрывать и открывать файл. Очень удобно для просмотра логов linux в реальном времени:
tail -f /var/log/Xorg.0.log
ПРОСМОТР СОДЕРЖИМОГО ФАЙЛА ПО ШАБЛОНУ
В большинстве случаев нам нужен не полностью весь файл, а только несколько строк, с интересующей нас информацией. Можно выполнить просмотр файла linux предварительно отсеяв все лишнее с помощью grep. Сначала синтаксис:
$ grep опции шаблон файл
Или в комбинации с cat:
$ cat файл | grep опции шаблон
Например выведем из лога только предупреждения:
$ cat /var/log/Xorg.0.log | grep WW
(WW) warning, (EE) error, (NI) not implemented, (??) unknown.
[ 85.839] (WW) Hotplugging is on, devices using drivers ‘kbd’, ‘mouse’ or ‘vmmouse’ will be disabled.
[ 85.839] (WW) Disabling Keyboard0
[ 85.839] (WW) Disabling Mouse0
[ 87.395] (WW) evdev: A4TECH USB Device: ignoring absolute axes.
Но это еще не все, многие не знают, но у этой утилиты еще несколько полезных опций.
С помощью опции -A можно вывести несколько строк после вхождения:
$ ifconfig | grep -A2 enp2s0
enp2s0: flags=4163 mtu 1500
inet 192.168.1.2 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::beae:c5ff:febe:8bb7 prefixlen 64 scopeid 0x20
С помощью -B — до вхождения:
ifconfig | grep -B2 loop
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
А -С позволяет вывести нужное количество строк до и после вхождения шаблона:
ifconfig | grep -C2 loop
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 9810 bytes 579497 (565.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
Также с помощью grep можно подсчитать количество найденных строк:
ifconfig | grep –c inet6
Шаблоном может быть строка и простые спецсимволы замены. Если вы хотите использовать регулярное выражение укажите опцию -e или используйте egrep. Многие спрашивают, а какая разница между этими утилитами — уже никакой, в большинстве дистрибутивов egrep это ссылка на grep -e. А теперь пример:
ifconfig | egrep ‘UP|DOWN’
enp2s0: flags=4163 mtu 1500
ham0: flags=4163 mtu 1404
lo: flags=73 mtu 65536
sit0: flags=193 mtu 1480
ПРОСМОТР ФАЙЛОВ LINUX В СЖАТОМ ВИДЕ
Иногда можно встретить в системе текстовые файлы в сжатом виде, формате gz. Это, например, конфигурационный файл ядра, или логи некоторых программ. Для того чтобы открыть файл в linux через терминал не распаковывая его есть целый ряд аналогов вышеописанных утилит с приставкой z. Это zcat, zless, zgerp, zegrep.
Например, открываем сжатый файл для просмотра:
Или более практичный пример, распаковываем и копируем конфигурационный ядра в текущую директорию:
zcat /porc/cofig.gz .config
Так же можно использовать less, для просмотра сжатых файлов с прокруткой:
А для фильтрации сжатых файлов по шаблону есть zgrep и zegrep. Например, ищем в сжатом логе ошибки:
Источник
EOF — это не символ
Недавно я читал книгу «Компьютерные системы: архитектура и программирование. Взгляд программиста». Там, в главе про систему ввода-вывода Unix, авторы упомянули о том, что в конце файла нет особого символа EOF .

Если вы читали о системе ввода-вывода Unix/Linux, или экспериментировали с ней, если писали программы на C, которые читают данные из файлов, то это заявление вам, вероятно, покажется совершенно очевидным. Но давайте поближе присмотримся к следующим двум утверждениям, относящимся к тому, что я нашёл в книге:
- EOF — это не символ.
- В конце файлов нет некоего особого символа.
Что же такое EOF ?
EOF — это не символ
Почему кто-то говорит или думает, что EOF — это символ? Полагаю, это может быть так из-за того, что в некоторых программах, написанных на C, можно найти код, в котором используется явная проверка на EOF с использованием функций getchar() и getc() .
Это может выглядеть так:
Если заглянуть в справку по getchar() или getc() , можно узнать, что обе функции считывают следующий символ из потока ввода. Вероятно — именно это является причиной возникновения заблуждения о природе EOF . Но это — лишь мои предположения. Вернёмся к мысли о том, что EOF — это не символ.
А что такое, вообще, символ? Символ — это самый маленький компонент текста. «A», «a», «B», «b» — всё это — разные символы. У символа есть числовой код, который в стандарте Unicode называют кодовой точкой. Например — латинская буква «A» имеет, в десятичном представлении, код 65. Это можно быстро проверить, воспользовавшись командной строкой интерпретатора Python:
Или можно взглянуть на таблицу ASCII в Unix/Linux:
Выясним, какой код соответствует EOF , написав небольшую программу на C. В ANSI C константа EOF определена в stdio.h , она является частью стандартной библиотеки. Обычно в эту константу записано -1 . Можете сохранить следующий код в файле printeof.c , скомпилировать его и запустить:
Скомпилируем и запустим программу:
У меня эта программа, проверенная на Mac OS и на Ubuntu, сообщает о том, что EOF равняется -1 . Есть ли какой-нибудь символ с таким кодом? Тут, опять же, можно проверить коды символов в таблице ASCII, можно взглянуть на таблицу Unicode и узнать о том, в каком диапазоне могут находиться коды символов. Мы же поступим иначе: запустим интерпретатор Python и воспользуемся стандартной функцией chr() для того, чтобы она дала бы нам символ, соответствующий коду -1 :
Как и ожидалось, символа с кодом -1 не существует. Значит, в итоге, EOF , и правда, символом не является. Переходим теперь ко второму рассматриваемому утверждению.
В конце файлов нет некоего особого символа
Может, EOF — это особенный символ, который можно обнаружить в конце файла? Полагаю, сейчас вы уже знаете ответ. Но давайте тщательно проверим наше предположение.
Возьмём простой текстовый файл, helloworld.txt, и выведем его содержимое в шестнадцатеричном представлении. Для этого можно воспользоваться командой xxd :
Как видите, последний символ файла имеет код 0a . Из таблицы ASCII можно узнать о том, что этот код соответствует символу nl , то есть — символу новой строки. Это можно выяснить и воспользовавшись Python:
Так. EOF — это не символ, а в конце файлов нет некоего особого символа. Что же такое EOF ?
Что такое EOF?
EOF (end-of-file) — это состояние, которое может быть обнаружено приложением в ситуации, когда операция чтения файла доходит до его конца.
Взглянем на то, как можно обнаруживать состояние EOF в разных языках программирования при чтении текстового файла с использованием высокоуровневых средств ввода-вывода, предоставляемых этими языками. Для этого напишем очень простую версию cat , которая будет называться mcat . Она побайтно (посимвольно) читает ASCII-текст и в явном виде выполняет проверку на EOF . Программу напишем на следующих языках:
- ANSI C
- Python 3
- Go
- JavaScript (Node.js)
Вот репозиторий с кодом примеров. Приступим к их разбору.
ANSI C
Начнём с почтенного C. Представленная здесь программа является модифицированной версией cat из книги «Язык программирования C».
Вот некоторые пояснения, касающиеся вышеприведённого кода:
- Программа открывает файл, переданный ей в виде аргумента командной строки.
- В цикле while осуществляется копирование данных из файла в стандартный поток вывода. Данные копируются побайтово, происходит это до тех пор, пока не будет достигнут конец файла.
- Когда программа доходит до EOF , она закрывает файл и завершает работу.
Python 3
В Python нет механизма явной проверки на EOF , похожего на тот, который имеется в ANSI C. Но если посимвольно читать файл, то можно выявить состояние EOF в том случае, если в переменной, хранящей очередной прочитанный символ, будет пусто:
Запустим программу и взглянём на возвращаемые ей результаты:
Вот более короткая версия этого же примера, написанная на Python 3.8+. Здесь используется оператор := (его называют «оператор walrus» или «моржовый оператор»):
Запустим этот код:
В Go можно явным образом проверить ошибку, возвращённую Read(), на предмет того, не указывает ли она на то, что мы добрались до конца файла:
JavaScript (Node.js)
В среде Node.js нет механизма для явной проверки на EOF . Но, когда при достижении конца файла делается попытка ещё что-то прочитать, вызывается событие потока end.
Низкоуровневые системные механизмы
Как высокоуровневые механизмы ввода-вывода, использованные в вышеприведённых примерах, определяют достижение конца файла? В Linux эти механизмы прямо или косвенно используют системный вызов read(), предоставляемый ядром. Функция (или макрос) getc() из C, например, использует системный вызов read() и возвращает EOF в том случае, если read() указывает на возникновение состояния достижения конца файла. В этом случае read() возвращает 0 . Если изобразить всё это в виде схемы, то получится следующее:
Получается, что функция getc() основана на read() .
Напишем версию cat , названную syscat , используя только системные вызовы Unix. Сделаем мы это не только из интереса, но и из-за того, что это вполне может принести нам какую-то пользу.
Вот эта программа, написанная на C:
В этом коде используется тот факт, что функция read() , указывая на достижение конца файла, возвращает 0 .
Вот та же программа, написанная на Python 3:
Вот — то же самое, написанное на Python 3.8+:
Запустим и этот код:
Итоги
- EOF — это не символ.
- В конце файлов нет некоего особого символа.
- EOF — это состояние, о котором сообщает ядро, и которое может быть обнаружено приложением в том случае, когда операция чтения данных доходит до конца файла.
- В ANSI C EOF — это, опять же, не символ. Это — константа, определённая в stdio.h , в которую обычно записано значение -1.
- «Символ» EOF нельзя найти в таблице ASCII или в Unicode.
Уважаемые читатели! А вы знаете о каких-нибудь более или менее широко распространённых заблуждениях из мира компьютеров?
Источник



