- Peter Leung, «Командная строка: маленькие хитрости от Linux Commando»
- Выбираем нужные строки из файла с помощью sed
- Просмотр содержимого файлов в командной строке Linux
- Команда cat
- Команда nl
- Команда less
- Команда more
- Команда head
- Команда tail
- Заключение
- Как в Linux вывести строку?
- Как вывести сходу информацию из двух созданных файлов?
- Как вывести некоторую строку файла в Linux?
- Как вывести 5-ый строку в Linux?
- Как вывести нужные строки в Linux из файла с помощью sed?
- Команда Grep в Linux (Поиск текста в файлах)
- Grep Command in Linux (Find Text in Files)
- В этой статье мы покажем вам, как использовать grep команду, на практических примерах и подробных объяснениях наиболее распространенных grep опций GNU .
- grep Синтаксис команды
- Поиск строки в файлах
- Инвертировать (исключить) совпадение
- Использование Grep для фильтрации выходных данных команды
- Рекурсивный поиск
- Показывать только имя файла
- Поиск без учета регистра
- Поиск полных слов
- Показать номера строк
- Количество совпадений
- Скрытый режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск по шаблону нескольких строк
- Печать строк перед сопоставлением
- Печать строк после сопоставления
- Вывод
Peter Leung, «Командная строка: маленькие хитрости от Linux Commando»
Выбираем нужные строки из файла с помощью sed
Тому, кто пишет много скриптов bash, часто приходится выбирать нужные строки из текста, например готовые блоки кода. Вчера я как раз должен был извлечь первую строку из файла, назовем его somefile.txt.
Это очень просто сделать при помощи команды head:
Для более сложных задач, например, извлечь вторую и третью строки из того же файла, команда head не подходит.
Давайте попробуем команду sed ≈ редактор потока (STream Editor).
Моя первая попытка применить команду p (print) оказалась неудачной:
Обратите внимание, что редактор печатает весь файл, причем указанную первую строку печатает дважды. Почему? По умолчанию редактор перепечатывает на стандартный вывод каждую строку вводимого файла. Четко заданная команда 1p приказывает печатать первую строку. В итоге первая строка дублируется.
Чтобы этого не происходило нужно подавить дефолтный вывод при помощи опции -n, чтобы на выводе был только результат команды 1p:
Можно пойти другим путем и удалить из файла все строки, кроме первой:
где ‘1!d’ означает: если строка не является первой (!), то подлежит удалению. Обратите внимания на кавычки (одинарные). Они совершенно необходимы, так как без них конструкция 1!d вызовет последнюю запускавшуюся в шелле команду, начинающуюся с буквы d.
Для извлечения нескольких строк, скажем, со второй по четвертую, можно поступить одним из следующих способов:
Интервал обозначается через запятую включительно.
А если строки не идут друг за другом, например, с первой по вторую и еще четвертую?
Если вам известны иные способы выбирать нужные строки из файлов, сообщите, пожалуйста, в комментариях.
Блестящий пример нестандартного подхода продемонстрировал в комментариях к этой статье некий Chris:
| Если я хочу извлечь пятую строку файла, то делаю так: |
А правда, здорово! И никаких заумных команд не надо с их километровыми манами. Кстати так и нужные блоки подряд идущих строк можно извлекать.
Источник
Просмотр содержимого файлов в командной строке Linux

Рассмотрим несколько команд, которые используются для просмотра содержимого текстовых файлов в командной строке Linux.
Команда cat
Команда cat выводит содержимое файла, который передается ей в качестве аргумента.
Это самый простой и наиболее часто используемый способ для вывода содержимого текстовых файлов. Но выводить большие файлы через cat не всегда удобно.
Команда nl
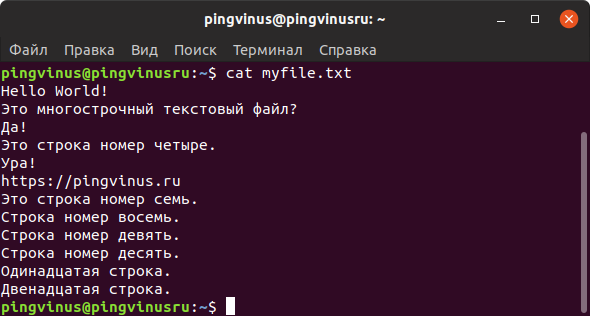
Команда nl действует аналогично команде cat , но выводит еще и номера строк в столбце слева.
Команду nl удобно применять для просмотра программного кода или поиска строк в файлах конфигурации.
Команда less
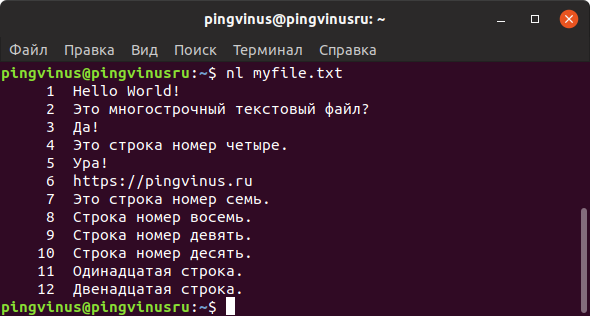
Утилита less выводит содержимое файла, но отображает его только в рамках текущего окна в режиме просмотра.
Вы можете прокручивать текст файла клавишами стрелок или перелистывать страницы клавишами w и z .
Для поиска текста внутри файла нажмите / .
Для просмотра списка доступных горячих клавиш нажмите h
Чтобы выйти из режима просмотра используется клавиша q .
Очень удобно, что после выхода окно терминала остается чистым и не содержит текст файла.
Команда more
Команда more очень похожа на команду less . Она также выводит файл в терминале в режиме просмотра, но имеет некоторые отличия от команды less.
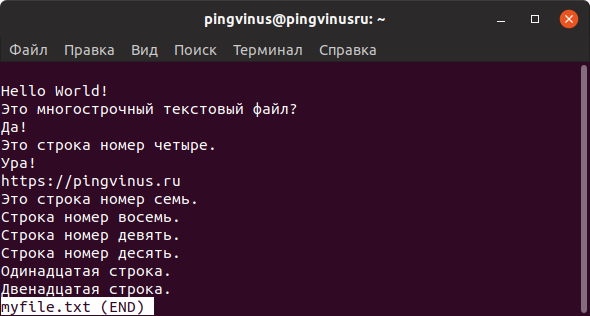
Например, less в конце файла выводит сообщение (END) (или EOF — End Of File) и ожидает нажатия клавиши q чтобы закрыть режим просмотра, а more по достижении конца файла сразу возвращает управление в терминал.
Также more после своей работы оставляет текст файла в терминале, а less работает «чисто» и не сохраняет текст в терминале.
Команда head
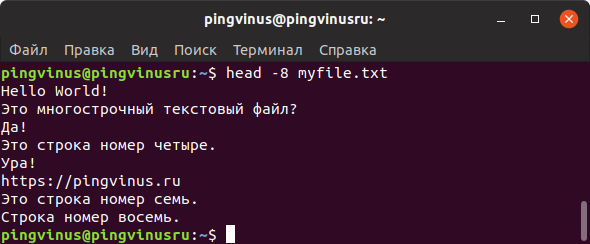
Команда head выводит на экран только первые 10 строк файла.
Используя опцию -n можно задать количество строк, которое нужно вывести. Например, чтобы вывести 15 строк используется команда:
Вместо -n можно просто использовать знак минус — , за которым сразу указывается количество строк.
Команда tail
Команда tail аналогична команде head , но выводит последние 10 строк файла.
Заключение
Команды, которые мы рассмотрели, имеют дополнительные возможности и области применения. Для получения справки по каждой команде можно воспользоваться Man-страницами.
Источник
Как в Linux вывести строку?
Начнем с команды, с которой уже не однократно встречались, команда cat. Сначала посмотрим справку по данной команде с помощью man cat. Этая команда предназначена для объединения файлов и печати на стандартный вывод информации. Под стандартным выводом предполагается вывод на консоль информации. Так же можно увидеть, что у данной команды есть ключи.
Как вывести сходу информацию из двух созданных файлов?
cat hello1.txt hello2.txt
А в справке было написано, что команда сможет объединять содержимое файлов.
cat hello1.txt hello2.txt > hello3.txt
cat hello3.txt
Мы вывели на стандартный вывод (консоль) содержание файлов и передали то, что на экране в новый файл hello3.txt. А затем просто вывели на консоль.
Как вывести некоторую строку файла в Linux?
При трейсе ошибки установки одного скрипта, возникла необходимость прочитать 98 строку файла. Делается это, ожидаемо, через команду вывода cat
# cat filename | head -n98 | tail -n1
где head -n предлагает сделать нужную строку, а tail -n задает сколько строк показать перед нужной. В данном варианте показана будет только одна строка.
То есть если нам необходимо вывести какой-никакой то сегмент строк, скажем, строки с 10 по 20, то выражение будет иметь вид
# cat filename | head -n20 | tail -n11
Как вывести 5-ый строку в Linux?
Если я хочу извлечь пятую строку файла, то делаю так:
$ head -n 5 имя_файла | tail -n 1
Ну или bash script
#!/bin/bash
for i in $(find /etc/ -type f);
do cat $i | head -n5 | tail -n1 >>
Данный скрипт на bash хватит всё файлы из папки etc, с них берёт пятую строку и выводит в файл, который создаёт в домашнем каталоге, а затем сортирует.
Как вывести нужные строки в Linux из файла с помощью sed?
Тому, кто пишет много скриптов bash, довольно частенько приходится выбирать нужные строки из текста, например готовые блоки кода. Вчера я как раз обязан был извлечь первую строку из файла, назовем его somefile.txt.
$ cat somefile.txt
Line 1
Line 2
Line 3
Line 4
Это весьма просто сделать при помощи команды head:
$ head -1 somefile.txt
Line 1
Для более сложных задачек, например, извлечь вторую и третью строки из того же файла, команда head не подходит. Подавайте попробуем команду sed ? редактор потока (STream Editor). Моя первая попытка применить команду p (print) очутилась неудачной:
$ sed 1p somefile.txt
Line 1
Line 1
Line 2
Line 3
Line 4
Обратите внимание, что редактор отпечатывает весь файл, причем указанную первую строку печатает дважды. Почему? По умолчанию редактор перепечатывает на типовой вывод каждую строку вводимого файла. Четко заданная команда 1p приказывает печатать первоначальную строку. В итоге первая строка дублируется. Чтобы этого не происходило нужно подавить дефолтный вывод при поддержки опции -n, чтобы на выводе был только результат команды 1p:
$ sed -n 1p somefile.txt
Line 1
Можно пойти иным путем и удалить из файла все строки, кроме первой:
$ sed ‘1!d’ somefile.txt
Line 1
где ‘1!d’ значит: если строка не является первой (!), то подлежит удалению. Обратите внимания на кавычки (одинарные). Они асбсолютно необходимы, так как без них конструкция 1!d вызовет последнюю запускавшуюся в шелле команду, начинающуюся с буквы d. Для извлечения многих строк, скажем, со второй по четвертую, можно поступить одним из следующих способов:
$ sed -n 2,4p somefile.txt
$ sed ‘2,4!d’ somefile.txt
Перерыв обозначается через запятую включительно. А если строки не идут друг за другом, например, с первоначальной по вторую и еще четвертую?
Источник
Команда Grep в Linux (Поиск текста в файлах)
Grep Command in Linux (Find Text in Files)
В этой статье мы покажем вам, как использовать grep команду, на практических примерах и подробных объяснениях наиболее распространенных grep опций GNU .

Команда grep означает «глобальная печать регулярных выражений», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep считывает из стандартного ввода, которое обычно является выводом другой команды.
grep Синтаксис команды
Синтаксис grep команды следующий:
- OPTIONS — Ноль или более вариантов. Grep включает в себя ряд параметров, которые контролируют его поведение.
- PATTERN — Шаблон поиска.
- FILE — Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ на чтение к файлу.
Поиск строки в файлах
Основное использование grep команды — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из /etc/passwd файла, вы должны выполнить следующую команду:
Вывод должен выглядеть примерно так:
Если строка содержит пробелы, вам необходимо заключить ее в одинарные или двойные кавычки:
Инвертировать (исключить) совпадение
Чтобы отобразить линии, которые не соответствуют шаблону, используйте параметр -v (или —invert-match ).
Например, чтобы напечатать строки, которые не содержат строку, которую nologin вы используете:
Использование Grep для фильтрации выходных данных команды
Выходные данные команды могут быть отфильтрованы с grep помощью сквозного трубопровода, и только те строки, которые соответствуют заданному шаблону, будут напечатаны на терминале.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользователь, www-data вы можете использовать следующую ps команду:
Вы также можете объединить несколько каналов в команду. Как вы можете видеть в выводе выше, есть также строка, содержащая grep процесс. Если вы не хотите, чтобы эта строка отображалась, передайте вывод другому grep экземпляру, как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона, grep используйте -r опцию (или —recursive ). Когда эта опция используется, grep будет выполняться поиск по всем файлам в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы перейти по всем символическим ссылкам , вместо этого -r используйте -R опцию (или —dereference-recursive ).
Вот пример, показывающий, как искать строку baks.dev во всех файлах в /etc каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете -R опцию, grep перейдите по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается -r из-за того, что файлы в sites-enabled каталоге Nginx являются символическими ссылками на файлы конфигурации внутри sites-available каталога.
Показывать только имя файла
Чтобы подавить grep вывод по умолчанию и печатать только имена файлов, содержащих сопоставленный шаблон, используйте параметр -l (или —files-with-matches ).
Команда ниже просматривает все файлы, заканчивающиеся .conf в текущем рабочем каталоге, и печатает только имена файлов, содержащих строку baks.dev :
Вывод будет выглядеть примерно так:
-l Вариант обычно используется в сочетании с рекурсивной опции -R :
Поиск без учета регистра
По умолчанию учитывается grep регистр. Это означает, что прописные и строчные символы рассматриваются как разные.
Чтобы игнорировать регистр при поиске, grep используйте -i опцию (или —ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не будет отображать никаких выходных данных, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра, используя -i опцию, он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «Зебра», «ZEbrA» или любой другой комбинации прописных и строчных букв для этой строки.
Поиск полных слов
При поиске строки grep будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр -w (или —word-regexp ).
Если вы выполните ту же команду, что и выше, включая -w опцию, grep команда вернет только те строки, которые gnu включены в качестве отдельного слова.
Показать номера строк
Опция -n (или —line-number ) указывает grep показывать номер строки, содержащей строку, которая соответствует шаблону. Когда эта опция используется, grep печатает совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из /etc/services файла, содержащего строку с bash префиксом с соответствующим номером строки, вы можете использовать следующую команду:
Вывод ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Количество совпадений
Чтобы напечатать количество совпадающих строк в стандартный вывод, используйте параметр -c (или —count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, которые имеют /usr/bin/zsh оболочку.
Скрытый режим
-q (Или —quiet ) говорит , grep чтобы работать в скрытом режиме , чтобы не показывать ничего на стандартный вывод. Если совпадение найдено, команда завершается со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве команды тестирования в if инструкции :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте ^ символ (каретка), чтобы соответствовать выражению в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте $ символ (доллар), чтобы соответствовать выражению в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте . символ (точка), чтобы соответствовать любому отдельному символу. Например, для сопоставления всего, что начинается с kan двух символов и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому отдельному символу, заключенному в скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используется [^ ] для соответствия любому отдельному символу, не заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и так далее, но не будет совпадать со строками, содержащими cola ,
Чтобы избежать специального значения следующего символа, используйте \ символ (обратный слеш).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Ниже приведены некоторые примеры:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
-o Опция используется для печати только строку соответствия.
Поиск по шаблону нескольких строк
Два или более шаблонов поиска могут быть объединены с помощью оператора ИЛИ | .
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и их версии с обратной косой чертой должны использоваться.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в журнале Nginx файл ошибки:
Если вы используете опцию расширенного регулярного выражения -E , оператор | не должен быть экранирован, как показано ниже:
Печать строк перед сопоставлением
Чтобы напечатать определенное количество строк перед сопоставлением строк, используйте параметр -B (или —before-context ).
Например, чтобы отобразить пять строк начального контекста перед сопоставлением строк, вы должны использовать следующую команду:
Печать строк после сопоставления
Чтобы напечатать определенное количество строк после сопоставления строк, используйте параметр -A (или —after-context ).
Например, чтобы отобразить пять строк конечного контекста после сопоставления строк, вы должны использовать следующую команду:
Вывод
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
На странице руководства пользователя Grep можно узнать больше о Grep .
Источник



