- File descriptor
- Overview
- Stdin, stdout, and stderr
- Redirecting file descriptors
- Русские Блоги
- Подробные файловые дескрипторы Linux
- Overview
- Стандартные файловые дескрипторы Linux
- Некоторые команды оболочки, связанные с файловыми дескрипторами
- Разница между каналами и перенаправлениями
- Что такое файловый дескриптор простыми словами
- Как файлы получают дескрипторы
- Для чего нужны файловые дескрипторы
- Что такое плохой файловый дескриптор
- Что можно делать с файловыми дескрипторами
- Linux: Find Out How Many File Descriptors Are Being Used
- Step # 1 Find Out PID
- Step # 2 List File Opened By a PID # 28290
- Tip: Count All Open File Handles
- List File Descriptors in Kernel Memory
- More about /proc/PID/file & procfs File System
- See also: /proc related FAQ/Tips
File descriptor

A file descriptor is a number that uniquely identifies an open file in a computer’s operating system. It describes a data resource, and how that resource may be accessed.
When a program asks to open a file — or another data resource, like a network socket — the kernel:
- Grants access.
- Creates an entry in the global file table.
- Provides the software with the location of that entry.
The descriptor is identified by a unique non-negative integer, such as 0, 12, or 567. At least one file descriptor exists for every open file on the system.
File descriptors were first used in Unix, and are used by modern operating systems including Linux, macOS, and BSD. In Microsoft Windows, file descriptors are known as file handles.
Overview
When a process makes a successful request to open a file, the kernel returns a file descriptor which points to an entry in the kernel’s global file table. The file table entry contains information such as the inode of the file, byte offset, and the access restrictions for that data stream (read-only, write-only, etc.).

Stdin, stdout, and stderr
On a Unix-like operating system, the first three file descriptors, by default, are STDIN (standard input), STDOUT (standard output), and STDERR (standard error).
| Name | File descriptor | Description | Abbreviation |
|---|---|---|---|
| Standard input | 0 | The default data stream for input, for example in a command pipeline. In the terminal, this defaults to keyboard input from the user. | stdin |
| Standard output | 1 | The default data stream for output, for example when a command prints text. In the terminal, this defaults to the user’s screen. | stdout |
| Standard error | 2 | The default data stream for output that relates to an error occurring. In the terminal, this defaults to the user’s screen. | stderr |
Redirecting file descriptors
File descriptors may be directly accessed using bash, the default shell of Linux, macOS X, and Windows Subsystem for Linux.
For example, when you use the find command, successful output goes to stdout (file descriptor 1), and error messages go to stderr (file descriptor 2). Both streams display as terminal output:
We’re getting errors because find is trying to search a few system directories that we don’t have permission to read. All the lines that say «Permission denied» were written to stderr, and the other lines were written to stdout.
You can hide stderr by redirecting file descriptor 2 to /dev/null, the special device in Linux that «goes nowhere»:
The errors sent to /dev/null, and are not displayed.
Understanding the difference between stdout and stderr is important when you want to work with a program’s output. For example, if you try to grep the output of the find command, you’ll notice the error messages are not filtered, because only the standard output is piped to grep.
However, you can redirect standard error to standard output, and then grep will process the text of both:
Notice that in the command above, the target file descriptor (1) is prefixed with an ampersand («&»). For more information about data stream redirection, see pipelines in the bash shell.
For examples of creating and using file descriptors in bash, see our exec builtin command examples.
Источник
Русские Блоги
Подробные файловые дескрипторы Linux
Заявление об авторском праве: Пожалуйста, укажите источник при перепечатке, спасибо https://blog.csdn.net/xlinsist/article/details/51147212
Overview
Важно понимать, как Linux обрабатывает ввод и вывод. Как только мы поймем принцип, мы сможем правильно и умело использовать сценарий, чтобы вывести содержимое в нужное место. Мы также можем лучше понять перенаправление ввода и перенаправление вывода.
Стандартные файловые дескрипторы Linux
| Дескриптор файла | сокращение | описание |
|---|---|---|
| 0 | STDIN | Стандартный ввод |
| 1 | STDOUT | Стандартный вывод |
| 2 | STDERR | Стандартный вывод ошибок |
Системы Linux рассматривают все устройства как файлы, а Linux использует файловые дескрипторы для идентификации каждого файлового объекта. Фактически, мы можем представить, что дисплей и клавиатура нашего компьютера рассматриваются как файлы в системе Linux, и все они имеют соответствующие файловые дескрипторы, соответствующие им.
На самом деле наше взаимодействие с компьютером заключается в том, что я могу вводить некоторые инструкции, и это дает мне некоторую информацию. Тогда мы можем поставитьФайловый дескриптор 0 понимается как мой ввод при взаимодействии с компьютером, и этот ввод по умолчанию направлен на клавиатуру; Файловый дескриптор 1 понимается как вывод, когда я взаимодействую с компьютером, и этот вывод по умолчанию направляется на дисплей; Файловый дескриптор 2 понимается как выходная информация об ошибке компьютера, когда я взаимодействую с компьютером, и этот вывод по умолчанию соответствует местоположению, указанному файловым дескриптором 1;
Как я уже говорил выше, так как они по умолчанию, я могу их изменить. Следующая команда изменяет расположение стандартного вывода в файл xlinsist:
На этот раз, если я войду ls -al или ps Команда, наш терминал не будет ничего отображать. Теперь мы можем открыть новый терминал и посмотреть, есть ли в файле xlinsist содержимое, показанное в двух приведенных выше командах.Примечание: вы должны открыть новый терминал.
Таким же образом мы также можем изменить положение стандартного ввода. Во-первых, давайте посмотрим на то, что не изменилось:
То есть мы читаем xlinsist в пользовательскую переменную с клавиатуры. Это чтение требует моего ввода. Теперь я хочу изменить стандартную позицию стандартного ввода:
Как вы можете видеть из приведенной выше команды чтения, меня ни о чем не просили.
Разница между стандартным выводом ошибки и стандартным выводом заключается в том, что он выводится в случае ошибки команды. Это не так уж отличается, мы также можем изменить его вывод в любое место, которое мы хотим. Просто нам нужно изменить стандартный вывод с 1 на 2. Команда выглядит следующим образом:
- Конечно, в дополнение к 0, 1, 2 мы можем выделить наши собственные файловые дескрипторы. Посмотрите на следующий пример:
Вышеприведенная команда очень интересна: сначала я указываю дескриптор файла 6 на тестовый файл. Поскольку в отличие от дескриптора 1, все выходные данные будут естественно искать его и видеть, направлен ли он на экран или в файл. Поэтому, когда мы хотим найти дескриптор 6, нам нужно использовать & для ссылки на него. Фактически, мы можем рассматривать дескриптор файла как ссылку на файл, который может указывать на любой файл (включая отображение). Процесс наведения — это процесс изменения местоположения по умолчанию. И используйте амперсанд, чтобы найти целевой файл, на который он указывает, и записать в него данные.
Если вы действительно понимаете вышеприведенные принципы, мы можем воспроизвести любое перенаправление ввода, перенаправление вывода, и это небольшой случай. Теперь давайте возьмем более сложный пример, чтобы помочь вам организовать ваши идеи. Сценарий выглядит следующим образом:
Давайте разберемся с вышеприведенной командой шаг за шагом: во-первых, дескриптор файла 1 по умолчанию указывает на монитор. Используйте &, чтобы найти целевой файл, на который указывает дескриптор файла 1, который является монитором. Таким образом, дескриптор файла 3 также указывает на отображение. Затем мы изменили файл, на который указывает дескриптор файла 1, в тестовый файл. Затем выходные данные двух команд echo будут естественно искать дескриптор файла 1, а затем он обнаруживает, что дескриптор файла 1 указывает на тестовый файл, поэтому он записывает выходные данные в тестовый файл. Наконец, мы используем &, чтобы найти целевой файл, на который указывает дескриптор файла 3, который является дисплеем, и затем мы модифицируем файл, на который указывает дескриптор файла 1, для отображения. Следовательно, последняя команда echo естественным образом найдет дескриптор файла 1 и выведет его на дисплей.
Весь процесс таков, пока вы понимаете их принципы, вы не будете чувствовать растерянность, независимо от того, как вы будете обрабатывать перенаправления в сценариях в будущем. Ниже я представлю некоторые команды оболочки, относящиеся к файловым дескрипторам, которые могут сделать вас еще более мощным.
Некоторые команды оболочки, связанные с файловыми дескрипторами
На следующем рисунке показано значение вышеперечисленных пунктов

Теперь я модифицирую стандартный вывод ошибок:
Файл / dev / null, это очень специальный файл, все, что вы пишете, будет очищено. Вы можете записать данные, чтобы попробовать эффект.
- Мы можем перенаправить стандартный вывод ошибок в / dev / null, тем самым отбрасывая сообщения об ошибках, которые мы не хотим сохранять
- Мы можем быстро удалить данные из существующих файлов без предварительного удаления файла при его создании. Команда выглядит следующим образом:
Linux использует каталог / tmp для хранения файлов, которые не нужно хранить постоянно. Большинство систем Linux автоматически удаляют все файлы в каталоге / tmp при запуске.
Доступны следующие команды:
tee команда-чтение из стандартного ввода, запись в стандартный вывод и файлы.
Разница между каналами и перенаправлениями
Канал — это выход одной программы как вход другой программы.
Перенаправление — это перенаправление вывода в файл или стандартный поток.
Источник
Что такое файловый дескриптор простыми словами
Файловый дескриптор — это неотрицательное число, которое является идентификатором потока ввода-вывода. Дескриптор может быть связан с файлом, каталогом, сокетом.
Например, когда вы открываете или создаете новый файл, операционная система формирует для себя запись для представления этого файла и хранения информации о нем. У каждого файла индивидуальный файловый дескриптор Linux. Открыли 100 файлов — где-то в ядре появились 100 записей, представленных целыми числами.
Как файлы получают дескрипторы
Обычно файловые дескрипторы выделяются последовательно. Есть пул свободных номеров. Когда вы создаете новый файл или открываете существующий, ему присваивается номер. Следующий файл получает очередной номер — например, 101, 102, 103 и так далее.
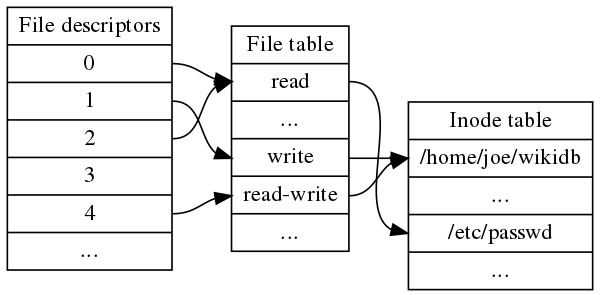
Дескриптор для каждого процесса является уникальным. Но есть три жестко закрепленных индекса — это первые три номера (0, 1, 2).
- 0 — стандартный ввод (stdin), место, из которого программа получает интерактивный ввод.
- 1 — стандартный вывод (stdout), на который направлена большая часть вывода программы.
- 2 — стандартный поток ошибок (stderror), в который направляются сообщения об ошибках.
Когда вы завершаете работу с файлом, присвоенный ему дескриптор освобождается и возвращается в пул свободных номеров. Он снова доступен для выделения под новый файл. 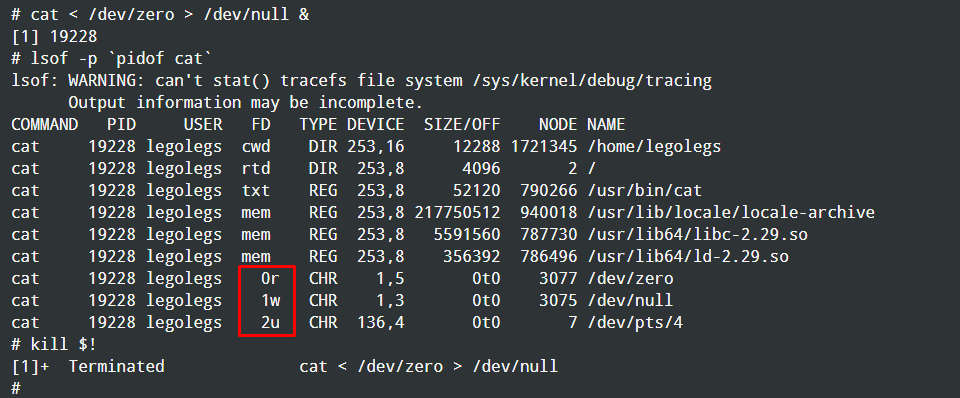
В Unix-подобных системах файловые дескрипторы могут относиться к любому типу файлов Unix: обычным файлам, каталогам, блочным и символьным устройствам, сокетам домена, именованным каналам. Дескрипторы также могут относиться к объектам, которые не существуют в файловой системе: анонимным каналам и сетевым сокетам.
Понятием «файловый дескриптор» оперируют и в языках программирования. Например, в Python функция os.open(path, flags, mode=0o777, *, dir_fd=None) открывает путь к файлу path, добавляет флаги и режим, а также возвращает дескриптор для вновь открытого файла. Начиная с версии 3.4 файловые дескрипторы в дочернем процессе Python не наследуются. В Unix они закрываются в дочерних процессах при выполнении новой программы.
Для чего нужны файловые дескрипторы
Чтобы оценить важность файловых дескрипторов, нужно разобраться, как работает файловая система.
- В традиционной реализации Unix дескрипторы индексируются в таблицу дескрипторов для каждого процесса, поддерживаемого ядром.
- Таблица файловых дескрипторов индексирует общесистемную таблицу файлов, открытых всеми процессами.
- В таблице файлов записывается режим, в котором открыт файл или другой ресурс — например, для чтения, записи, чтения и записи.
- Режим индексируется в таблицу индексных дескрипторов, описывающих фактические базовые файлы. В каждом индексном дескрипторе хранятся атрибуты и расположение дисковых блоков переданного объекта.
Когда нужно выполнить ввод или вывод, процесс через системный вызов передает ядру дескриптор нужного файла. Ядро обращается к файлу от имени процесса. При этом у самого процесса нет доступа к файлу или таблице индексных дескрипторов.
Что такое плохой файловый дескриптор
Это ошибка, которая может возникнуть в многопоточных приложениях, — Bad file descriptor. Чтобы исправить ее, нужно найти код, который закрывает один и тот же дескриптор файла. Может произойти и другая ситуация — например, один поток уже закрыл файл, а другой поток пытается получить к нему доступ.
В однопоточных приложениях такая проблема обычно не возникает.
Что можно делать с файловыми дескрипторами
Файловые дескрипторы можно использовать для исправления ошибок. Например, если на диске нет свободного места, но вы не видите файлы, которые занимают пространство, то можно посмотреть открытые дескрипторы. Это поможет понять, какое приложение заняло весь доступный объем.
Важно понимать, что если мы один раз открыли файл, и он получил файловый дескриптор, то мы можем взаимодействовать с ним дальше. Не имеет значения, что с этим файлом происходит. Его могут переименовать, удалить, могут изменить его владельца, отобрать права на запись и чтение. Если вы уже начали работать с файлом и знаете его дескриптор, то можете продолжать с ним работать.
Источник
Linux: Find Out How Many File Descriptors Are Being Used
W hile administrating a box, you may wanted to find out what a processes is doing and find out how many file descriptors (fd) are being used. You will surprised to find out that process does open all sort of files:
=> Actual log file
=> Library files /lib /lib64
=> Executables and other programs etc
In this quick post, I will explain how to to count how many file descriptors are currently in use on your Linux server system.
Step # 1 Find Out PID
To find out PID for mysqld process, enter:
# ps aux | grep mysqld
OR
# pidof mysqld
Output:
Step # 2 List File Opened By a PID # 28290
Use the lsof command or /proc/$PID/ file system to display open fds (file descriptors), run:
# lsof -p 28290
# lsof -a -p 28290
OR
# cd /proc/28290/fd
# ls -l | less
You can count open file, enter:
# ls -l | wc -l
Tip: Count All Open File Handles
To count the number of open file handles of any sort, type the following command:
# lsof | wc -l
Sample outputs:
List File Descriptors in Kernel Memory
Type the following command:
# sysctl fs.file-nr
Sample outputs:
- No ads and tracking
- In-depth guides for developers and sysadmins at Opensourceflare✨
- Join my Patreon to support independent content creators and start reading latest guides:
- How to set up Redis sentinel cluster on Ubuntu or Debian Linux
- How To Set Up SSH Keys With YubiKey as two-factor authentication (U2F/FIDO2)
- How to set up Mariadb Galera cluster on Ubuntu or Debian Linux
- A podman tutorial for beginners – part I (run Linux containers without Docker and in daemonless mode)
- How to protect Linux against rogue USB devices using USBGuard
Join Patreon ➔
- 1020 The number of allocated file handles.
- 0 The number of unused-but-allocated file handles.
- 70000 The system-wide maximum number of file handles.
You can use the following to find out or set the system-wide maximum number of file handles:
# sysctl fs.file-max
Sample outputs:
More about /proc/PID/file & procfs File System
/proc (or procfs) is a pseudo-file system that it is dynamically generated after each reboot. It is used to access kernel information. procfs is also used by Solaris, BSD, AIX and other UNIX like operating systems. Now, you know how many file descriptors are being used by a process. You will find more interesting stuff in /proc/$PID/file directory:
- /proc/PID/cmdline : process arguments
- /proc/PID/cwd : process current working directory (symlink)
- /proc/PID/exe : path to actual process executable file (symlink)
- /proc/PID/environ : environment used by process
- /proc/PID/root : the root path as seen by the process. For most processes this will be a link to / unless the process is running in a chroot jail.
- /proc/PID/status : basic information about a process including its run state and memory usage.
- /proc/PID/task : hard links to any tasks that have been started by this (the parent) process.
See also: /proc related FAQ/Tips
/proc is an essentials file system for sys-admin work. Just browser through our previous article to get more information about /proc file system:
Источник



