- как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Re: как заполнить свободное на разделе место нулями?
- Как заполнить жесткий диск в Linux
- 7 ответов
- REALIX.RU — IT, компьютеры и всё остальное.
- Уничтожение данных на жестком диске в Linux
- Стирание данных с использованием dd
- Стирание данных с помощью shred
как заполнить свободное на разделе место нулями?

Re: как заполнить свободное на разделе место нулями?
cat /dev/zero > file
Когда отвалится — значит всё свободное место забито нулями.
Re: как заполнить свободное на разделе место нулями?
file естественно должен быть на забиваемом разделе

Re: как заполнить свободное на разделе место нулями?
Или чуть быстрее
dd if=/dev/zero of=/path/file
Re: как заполнить свободное на разделе место нулями?
это с 512-байтным bs по умолчанию? Шутник.

Re: как заполнить свободное на разделе место нулями?
Оставайтесь на месте, отдел К выезжает
Re: как заполнить свободное на разделе место нулями?
Есть такое слово — называется кеширование.
Что мешает написать bs=4096?
Re: как заполнить свободное на разделе место нулями?
Re: как заполнить свободное на разделе место нулями?
sync еще неплохо бы.

Re: как заполнить свободное на разделе место нулями?
>Оставайтесь на месте, отдел К выезжает Тогда лучше использовать shred
Re: как заполнить свободное на разделе место нулями?
Только потом надо удалить файл.
Re: как заполнить свободное на разделе место нулями?
>как заполнить свободное на разделе место нулями?
А зачем, если не секрет.
Re: как заполнить свободное на разделе место нулями?
всем спасибо за ответы
>А зачем, если не секрет.
предпродажная подготовка=) продаю комп, а систему попросили не сносить
Источник
Как заполнить жесткий диск в Linux
Я тестирую фрагмент кода, и я хочу заполнить жесткий диск данными. Я обнаружил, что dd может делать огромные файлы в одно мгновение, но df не согласен. Вот что я пробовал:
dd if=/dev/zero of=filename bs=1 count=1 seek=$((10*1024*1024*1024))
ls -lh показывает файл 10G. Однако df -h показывает, что раздел не сжимался. Итак, что мне нужно сделать, чтобы сделать df распознать данные теперь? Я надеюсь на что-то быстрое, что я код в единичном тесте.
7 ответов
Проблема с трюком seek= заключается в том, что файловая система (обычно) умна: если часть файла никогда не была написана (и, следовательно, все нули), он не хочет выделять для этого какое-либо пространство — так, как вы видели, у вас может быть 10-гигабайтный файл, который не занимает места (это называется «разреженный файл», и может быть очень полезен в некоторых случаях, например, в некоторых реализациях базы данных).
Вы можете заставить пространство быть выделенным (например):
, который займет гораздо больше времени, но фактически заполнит диск. Я рекомендую сделать размер блока намного выше, чем один, потому что это определит, сколько системных вызовов обрабатывает процесс dd — чем меньше размер блока, тем больше системных вызовов, и, следовательно, медленнее будет работать. (Хотя за пределами 1 МБ или около того он, вероятно, не будет иметь большого значения и может даже замедлить работу . )
В качестве другого варианта для этого вы можете использовать да вместе с одной строкой и примерно в 10 раз быстрее, чем запуск dd if = /dev /urandom of = largefile. Как этот
Вы создали так называемый «разреженный файл» — файл, который, поскольку большая часть его пуста (т.е. читается как \ 0), не занимает места на диске, кроме того, что на самом деле написано (1B , после 10 ГБ пробела).
Я не верю, что вы могли бы создавать огромные файлы, занимая фактическое дисковое пространство в одно мгновение — физическое пространство означает, что файловой системе необходимо выделить блоки диска для вашего файла.
Я думаю, что вы застряли со старомодным «dd if = /dev /zero of = filename bs = 100M count = 100», который ограничен скоростью последовательной записи вашего диска.
Если вы просто проверяете случаи с заполненными файловыми системами, возможно, fallocate достаточно хорош. И быстрее! например.
Остановить использование seek и использовать очень большой bs и /или count . Поскольку вы делаете разреженный файл , и, очевидно, вам не нужно этого делать.
Если вы хотите буквально заполнить жесткий диск, сделайте следующее:
Вы можете дополнительно указать счетчик, если хотите ограничить размер, но если вы опустите счет, он будет работать только до тех пор, пока вы не выберете место на диске.
Как упоминалось выше, вы получите лучшую производительность, если вы установите размер блока 1 МБ (bs = 1M) вместо 1 B (bs = 1). Это займет некоторое время, но если вы хотите проверить ход выполнения своей команды, откройте отдельную консоль и запустите следующие команды:
Используйте PID dd в этой команде (замените PID на PID dd):
Затем перейдите на свой dd-терминал. Конечно, это ограниченное использование, когда вы просто пытаетесь заполнить диск (вы можете просто использовать df или du для проверки свободного места на диске или размера файла соответственно). Однако есть и другие моменты, когда удобно делать вывод dd о его прогрессе.
Дополнительный кредит: одно практическое использование для обнуления свободного пространства заключается в том, что после этого вы можете удалить «нулевые» файлы и dd весь раздел (или диск, если вы обнулили все разделы), на образ диска файл (скажем, disk-backup.dd), а затем сжать файл. Свободное пространство теперь сильно сжимаемо, поэтому сжатое dd-изображение будет намного меньше исходного блочного устройства, содержимое которого оно содержит.
Shenanigans: запишите большой файл нулей и отправьте его по электронной почте всем своим друзьям. Скажите им, что это действительно здорово.
Вы создаете не разреженный файл 1 ТБ со следующей командой:
Это было полезно при тестировании того, что происходит, когда квоты превышены, или файловая система заполняется.
df -h показывает, что доступное пространство становится меньше.
Источник
REALIX.RU — IT, компьютеры и всё остальное.
Автор: Lucky Рубрики: Linux
В жизни случаются ситуации, когда хочется бесследно избавиться от информации на жестком диске. Причин этого желания может быть много.
Одни из таких причин: Продажа жесткого диска или выбрасывание жесткого диска на свалку.
Продавая HDD совсем не хочется чтобы кто-то копался в старой информации, тем более что там могут быть конфеденциальные данные. Даже выбрасывая жесткий диск на помойку хочется знать, что никто не сможет восстановить информацию оттуда.
Способов бесследно стереть информацию существует много. О двух способах полного удаления информации с HDD я расскажу ниже.
Собрался я выбрасывать старый, но еще работающий жесткий диск. Хотя диск и сбоил, но позволял с собой работать. И мне захотелось уверенности, что никто из праздного любопытства не сможет восстановить пароли от различных интернет-ресурсов ранее хранившееся на этом HDD. Немного подумав решил воспользоваться бесплатными вариантами, реализованными в мире Linux систем.
На полке с CD/DVD дисками обнаружился установочный диск Ubuntu 12.04, которым я и решил воспользоваться. Устанавливать Ubuntu я не собирался, а хотел воспользоваться возможностью запуска этой операционной системы без установки с CD диска. Дабы ничего не перепутать я отключил все HDD, кроме того, с которого собирался бесследно удалить информацию и загрузился с установочного диска Ubuntu 12.04.
Подопытный HDD был подключен мастером на IDE шлейф, а DVD-ROM был подключен слэйвом. После загрузки с диска передо мной появился экран выбора.
Мне предлагалось выбрать: попробовать Ubuntu без установки или установить.
Я выбрал попробовать [Try Ubuntu], а языком интерфейса я оставил предложенный мне по умолчанию English. Английский я выбрал по простой причине: Я собирался в консоли вводить команды и у меня не было желания вспоминать как переключать язык ввода.
Ubuntu загрузилась и предо мной предстал “Рабочий стол”.
Первый вариант: команда dd
dd (dataset definition) — программа UNIX, предназначенная как для копирования, так и для конвертации файлов. Название унаследовано от оператора DD (Dataset Definition) из языка JCL
Будьте внимательны! Не ошибитесь с выбором файла устройства! Иначе потеряете данные.
- Первым делом я нажал комбинацию клавиш CTRL + ALT + F1 ( Переключился на первую виртуальную консоль ).
- Затем в консоли ввел команду sudo -i ( Становимся Суперпользователем )
- Затем команда fdisk -l ( Выводит список доступных дисков, в выводе этой команды мы уточняем название нашего hdd ). В моем случае жесткий диск в системе был назван sda.
- Затем: dd if=/dev/zero of=/dev/sda bs=4M ( Собственно сама команда, стирающая данные с жесткого диска. Хотя На самом деле эта команда не стирает данные, а заполняет HDD нулями. Сама операция занимает достаточно продолжительное время ).
Если же нас преследует паранойя, то после этой команды мы задаем команду, которая заполняет жесткий диск случайными данными (очень медленный процесс, сильно загружающий CPU ): dd if=dev/urandom of=/dev/sda bs=4M
Если же с паранойя совсем не дает покоя, то мы несколько раз, чередуя, запускаем эти команды.
CTRL + ALT + F7 — Вернуться в графический режим.
- dd if=/dev/zero of=/dev/sda — заполняем диск нулями
- dd if=/dev/urandom of=/dev/sda — заполняем диск случайными данными
- dd if=/dev/random of=/dev/sda — заполняем диск случайными данными ( немного быстрее предыдущей)
Второй вариант: команда shred
shred переписывает несколько раз указанные файлы для того, чтобы сделать более трудоёмким процесс восстановления данных даже в случае использования специального оборудования для восстановления.
Итак, перед нами “Рабочий стол” Ubuntu.
Будьте внимательны! Не ошибитесь с выбором файла устройства! Иначе потеряете данные.
- Первым делом я нажимаем комбинацию клавиш CTRL + ALT + F1 ( Переключаемся на первую виртуальную консоль ).
- Затем в консоли вводим команду sudo -i ( Становимся Суперпользователем )
- Затем команда fdisk -l ( Выводит список доступных дисков, в выводе этой команды мы уточняем название нашего hdd ). В моем случае жесткий диск в системе был назван sda.
- Затем: shred -n0 -z -v /dev/sda ( Собственно сама команда, стирающая данные с жесткого диска ).
Подробнее о параметрах этой команды:
- n0 — число проходов ( я указал 0, это значит что число проходов с заполнением файла случайными данными будет равно нулю).
- z — Заполнить нулями ( будет еще один проход в который файл будет заполняться нулями )
- v — показывать индикатор прогресса ( удобно видеть сколько процентов сделано, а сколько осталось )
- /dev/sdb — HDD, с которого уничтожаем информацию.
CTRL + ALT + F7 — Вернуться в графический режим.
Если же нас мучает паранойя, то надо указать как минимум n1, чтобы был хотя бы один проход с заполнением файла случайными данными.
- shred -n0 -z -v /dev/sda (только один проход с заполнением файла /dev/sda нулями с отображением индикатора прогресса)
- shred -v /dev/sda ( Число проходов по умолчанию (3) с заполнением случайными данными файла /dev/sda с отображением индикатора прогресса )
- shred -n4 -z -v /dev/sda ( четыре прохода с заполнением файла /dev/sda случайными данными и один проход с заполнением файла нулями с отображением индикатора прогресса
Источник
Уничтожение данных на жестком диске в Linux
Когда мы удаляем файл из файловой системы, данные физически не удаляются: операционная система просто отмечает область, ранее занятую файлом, как свободную и делает ее доступной для хранения новой информации. Единственный способ убедиться, что данные действительно удалены с устройства, – перезаписать их другими данными. Если диск с конфиденциальной информацией меняет владельца и вы боитесь, что она может попасть не в те руки необходимо предпринять определенные действия.
Многие криминалистические инструменты с открытым исходным кодом находятся в свободном доступе в Интернете, и их можно использовать для извлечения потерянных или удаленных данных с жесткого диска. Многие из них настолько просты в использовании, что обычные пользователи настольных компьютеров также могут загрузить их и достать данные.
Рассмотрим некоторые инструменты, которые мы можем использовать, чтобы полностью стереть данные на устройстве.
Стирание данных с использованием dd
Утилита dd – мощная программа, включенная по умолчанию во все основные дистрибутивы Linux. С ее помощью мы можем заполнить содержимое диска нулями или случайными данными. В обоих случаях мы можем использовать данные, сгенерированные специальными файлами: /dev/zero и dev/urandom (или /dev/random) соответственно. Первый возвращает нули каждый раз, когда над ним выполняется операция чтения; второй возвращает случайные байты, используя генератор случайных чисел ядра Linux.
Чтобы заполнить диск нулями, мы можем запустить:
Чтобы использовать случайные данные, вместо этого:
Стирание данных с помощью shred
Основное назначение данной утилиты состоит в том, чтобы перезаписать файлы и при необходимости удалить их. Утилита основана на предположении , что файловая система перезаписывает данные на месте. Однако приложение может не позволить нам достичь ожидаемого результата. Например, в журналируемой файловой системе, таких как ext4 (пожалуй наиболее часто используемая файловая система Linux), если она смонтирована с опцией data=journal.
При монтировании файловой системы ext4 с опциями data=ordered или data=writeback (первая используется по умолчанию) данные записываются в основную файловую систему после фиксации метаданных в журнале. В обоих случаях shred работает нормально, что дает ожидаемые результаты. При использовании опции data=journal помимо метаданных в журнал файловой системы записываются также и сами данные и лишь затем данные записываются в основную файловую систему. Легко понять, почему это может вызвать проблемы.
Рассмотрим несколько примеров использования приложения. Предположим, мы хотим безопасно содержимое файла с именем «test».
Все, что нам нужно сделать, это запустить следующую команду (здесь мы используем опцию -v, чтобы сделать программу более подробной):

Вот что мы можем видеть после выполнения команды:
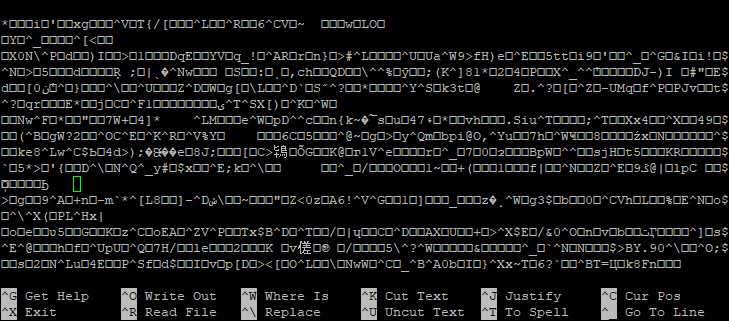
По умолчанию приложение переписывает указанный файл случайными данными в три прохода. Количество проходов можно изменить с помощью опции -n. Чтобы переопределить файл 6 раз, мы запустим:

В некоторых случаях мы можем скрыть тот факт, что операция удаления была выполнена для файла или устройства. В этих ситуациях мы можем использовать опцию программы -z (сокращение от –zero), чтобы заставить программу выполнить дополнительный проход нулями:

Из подробного вывода команды мы действительно можем заметить, как выполняется последний проход, записав нули ( 000000).
Помимо работы с файлами shred позволяет производить такие же операции с разделами. Например, нам необходимо навсегда затереть информацию на диске sda:
Источник



