- Секреты Терминала. Часть 7: Регулярные выражения и фильтрация
- Regex for Mac OS X Tutorial
- Table of Contents
- Input Validation
- Matching Text
- How to build and test a regular expression using Regex for Mac OS X
- Positive Lookahead
- Negative Lookahead
- Positive Lookbehind
- Negative Lookbehind
- Backreferences
- Additional Tip
- Conclusion
- Регулярные выражения. Всё проще, чем кажется
- Содержание
- Что такое регулярка и с чем ее едят?
- Где писать регулярки?
- Самые простые регулярки
- Квантификаторы
- Специальные символы квантификаторов
- Специальные символы
- Lookahead и lookbehind (опережающая и ретроспективная проверки)
- Регулярные выражения в разных языках программирования
- Заключение
Секреты Терминала. Часть 7: Регулярные выражения и фильтрация
 Пришло время в очередной раз вернуться к циклу статей о командной строке Mac OS X. Сегодня мы расскажем об основах языка регулярных выражений и о том, как эти знания могут пригодиться при использовании команды find (равно как и ряда остальных команд). Кроме того, мы расскажем о команде grep, которая позволяет проводить «умную» фильтрацию результатов любой другой команды.
Пришло время в очередной раз вернуться к циклу статей о командной строке Mac OS X. Сегодня мы расскажем об основах языка регулярных выражений и о том, как эти знания могут пригодиться при использовании команды find (равно как и ряда остальных команд). Кроме того, мы расскажем о команде grep, которая позволяет проводить «умную» фильтрацию результатов любой другой команды.
Если верить Википедии, то регулярные выражения (regular expressions, сокр. RegExp, RegEx) — это формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов. Говоря человеческим языком — это использование всяческого рода масок для имён объектов или их содержимого.
Основа регулярных выражений — символы подстановки. Полагаем, они вам давно знакомы:
? заменяет один символ. Например, под маску ?Tunes подойдёт программа iTunes, но не подойдёт программа ooTunes.
* заменяет любое число символов. Например, a*t найдёт и трёхбуквенные, и тридцатибуквенные имена, начинающиеся с a и кончающиеся на t.
\ экранирует один следующий символ. Если помните, этой уловкой мы пользовались, чтобы напечатать в Терминале команды с пробелом. Если перед пробелом поставить обратный слэш, то пробел будет считаться именно пробелом, но не концом команды.
А теперь приступим к тому, что вам незнакомо.
^ означает начало строки. Например ^a означает выражение, начинающееся с a.
$ означает конец строки. b$ будет означать символ b в конце строки выражения.
\b означает границу слова. Обратите внимание: буква b тут входит в состав оператора. Если вам надо найти букву b на границе слов, то придётся вводить b\b.
\B означает «не конец слова». \Bw\B означает букву w, находящуюся в середине слова.
[] означает символьный класс. Всё, что между квадратными скобками — это допустимое содержимое класса. Например, вам нужно отфильтровать файлы File1, File2 и File3 от файлов File4, File5. Тогда в качестве маски можно ввести File[123].
Внутри символьного класса допустимо использование символа исключения — ^. Если написать File[^45], то результат фильтрации будет тем же, что и в предыдущем примере: из результатов будут исключены все файлы, у которых после File следует четвёрка или пятёрка.
<> — это квантификатор. Он указывает количество повторений символа. Если вписать Fil<5>e, то это будет означать поиск файла Fillllle. Можно вписать две цифры через запятую — это будет означать количество повторений ОТ первой цифры ДО второй. Если вписать <6,>, это будет означать «не менее 6 повторов», а если <,11>— то «не более 11».
Собственно, привычные вам знаки ? и * — это принятые сокращения квантификаторов. Вместо <0,>употребляется звёздочка, вместо <0,1>— знак вопроса. Кстати, запомните ещё одно принятое сокращение: + обозначает квантификатор <1,>.
Если вы думаете, что это всё, то глубоко ошибаетесь. Мы не станем грузить вас такими областями знаний, как атомарная группировка или группировка без обратной связи. Пора заняться командой grep.
Это мощный фильтр результатов. Как правило, команда grep применяется в связке с другими командами, выход которых она фильтрует.
Возьмём простой пример — у нас есть папка Files, в которой 50000 файлов, среди них есть 10 нужных нам — в их имени есть слово Table. Как вывести только их список, не загромождая экран всеми остальными? Очень просто — запустить команду ls, приклеив к ней фильтр.
вывела бы нам все 50000 файлов. А вот
покажет нам только нужные.
Как видите, «склеивание» команд осуществляется через конвейер — символ | . Он означает, что выход первой команды сразу переадресуется второй.
Синтаксис у grep следующий:
grep [параметры] [маска фильтрации]
Параметров немало, они есть почти на каждую букву алфавита:
-a — воспринимает бинарные файлы как текст.
-B — показывает вам не только отфильтрованную строку, но и некоторое число (-B 5) предшествующих. Параметр пригодится при поиске внутри текста.
-С — то же самое, только указывается число строк после совпадения.
-e — принудительно заставляет воспринимать всё, что написано далее, как регулярное выражение
-E — то же самое, только Терминал станет интерпретировать расширенное регулярное выражение, поддерживающее значительно большее число сокращений.
-f — берёт маску из файла по указанному пути.
-H — для каждого совпадения выводится имя файла.
-i — игнорирует различия в регистре между объектами поиска и маской.
-m — ограничивает число результатов поиска (-m 20).
-n — нумерует каждую строку с результатами.
-o — показывать не всю совпадающую строку, а только отдельный фрагмент.
-s — отключает сообщения об ошибках.
-U — принудительно рассматривает файлы как бинарные.
-v — инвертирует маску фильтрации.
-Z — выводит результаты фильтрации сплошным массивом, без пробелов и переносов.
На этом знакомство с командой grep можно считать законченным. Помните про неё: она позволяет сделать общение с Терминалом намного удобнее.
В следующей статье мы поговорим об атрибутах объектов и их изменении.
Источник
Regex for Mac OS X Tutorial
by Hwee-Boon Yar — Get free updates of new posts here
Regular expressions or regex (also referred to as regexp) is a way to write a string of text that will serve as a pattern to match another string (or strings). Regex is terse and well supported by many tools including popular programming languages such as Javascript, Java, Perl, Ruby and Python, as well as shell tools such as sed and text editors such as TextMate, vi and Emacs.
There are many ways which regex can be useful, including input validation, extracting strings from text, and search and replacing of text.
Table of Contents
Input Validation
Regex is incredibly handy when you want to perform validation of input from HTML forms. For example, you might want to parse emails with expressions such as
Matching Text
You can match prices such as $1.99 with
How to build and test a regular expression using Regex for Mac OS X
We’ll take matching prices as an example of building a regex and testing it with Regex for Mac OS X (free trial). Here’s a few steps to do it.
1. Come up with examples of the string you want to match against, typing them into the sample area. So you would have
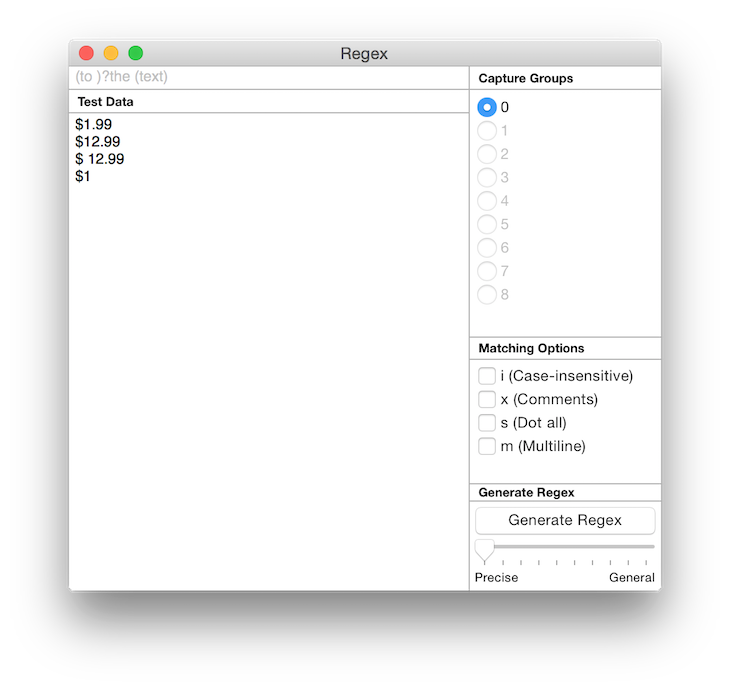
2. Come up with a regex and try to match them to the first example and modify the regex to also work with each example as you work down the list. To match a $ we need to escape it with a preceding \ so we start with
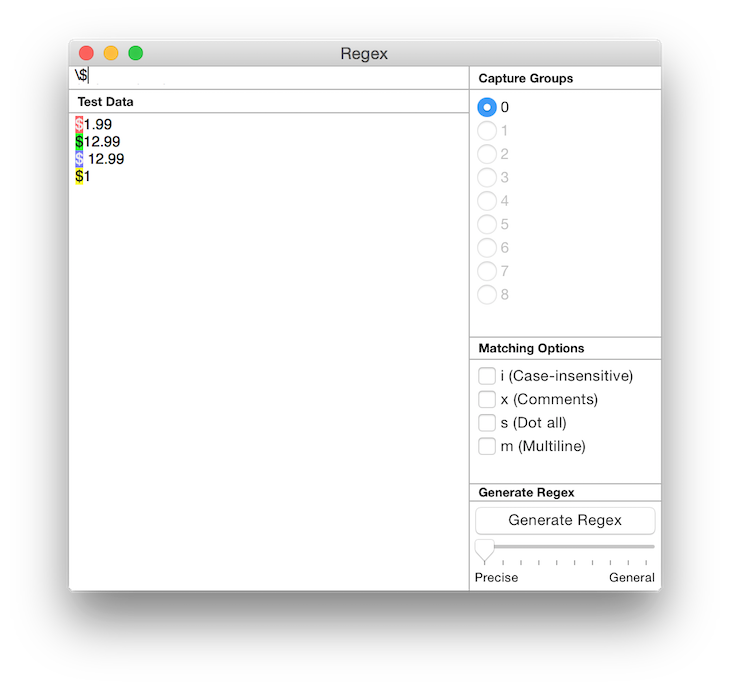
3. \d matches a digit, so let’s match $1 with
4. We want to match the . in $1. remembering that . has to be escaped with a preceding \ too. (Otherwise . matches any character)
5. Matching $1.99 we then have. This now matches the first example
6. Since we can match a repeating pattern with <>, let us use it here to make it clear that there is exactly 2 ending digits. And we are now done with the first example
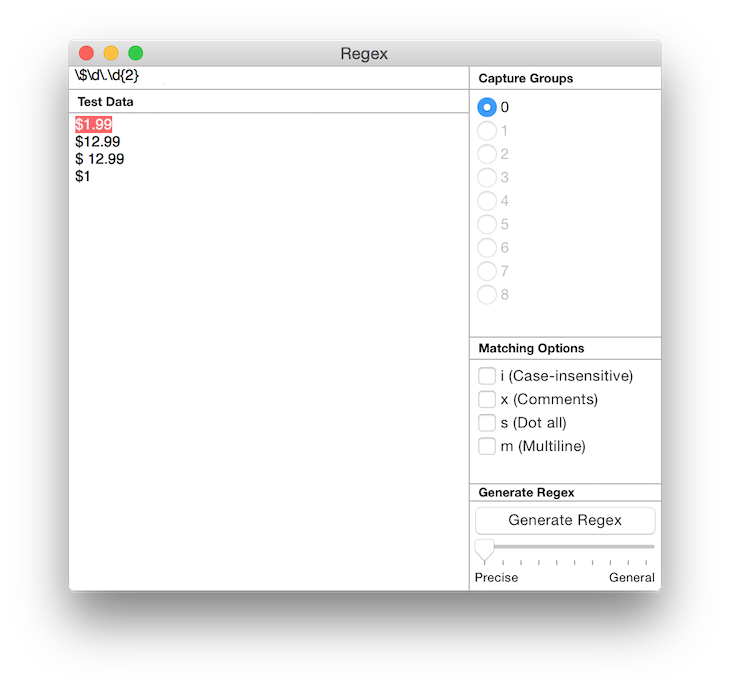
7. In the 2nd example, we observe that the dollar value can sometimes be more than 1 digit. So let’s use the + quantifier to indicate we want 1 or more repeats. This expression matches both examples
8. For the 3rd example, we notice there can be an optional space between the $ and first digit. We’ll make use of \s as a whitespace matching character as well as the ? quantifier to indicate it is optional.
9. And finally, we notice that the cents part (.99) is optional too. So let’s make it so with
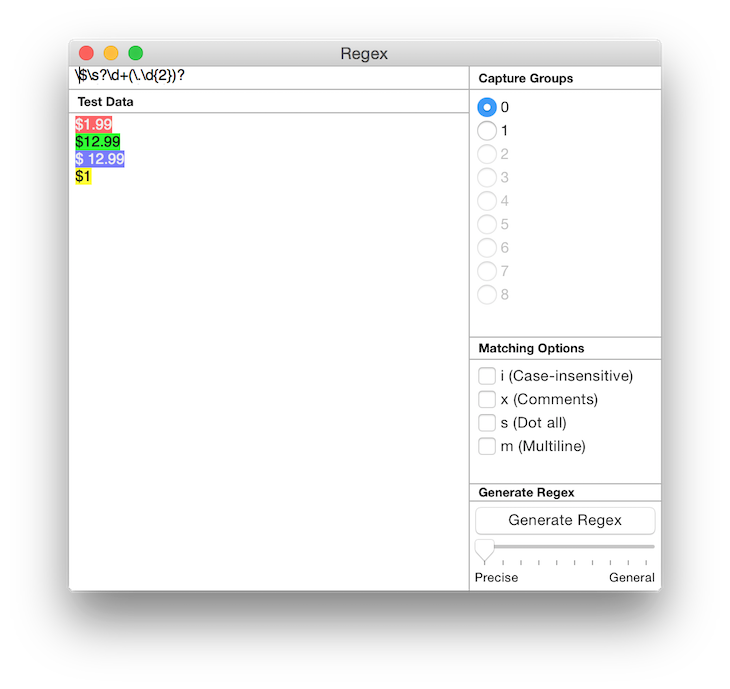
And this matches every one of the examples above.
10. Let’s extend this example further. Perhaps you want to also match the dollar value in the price. We can do
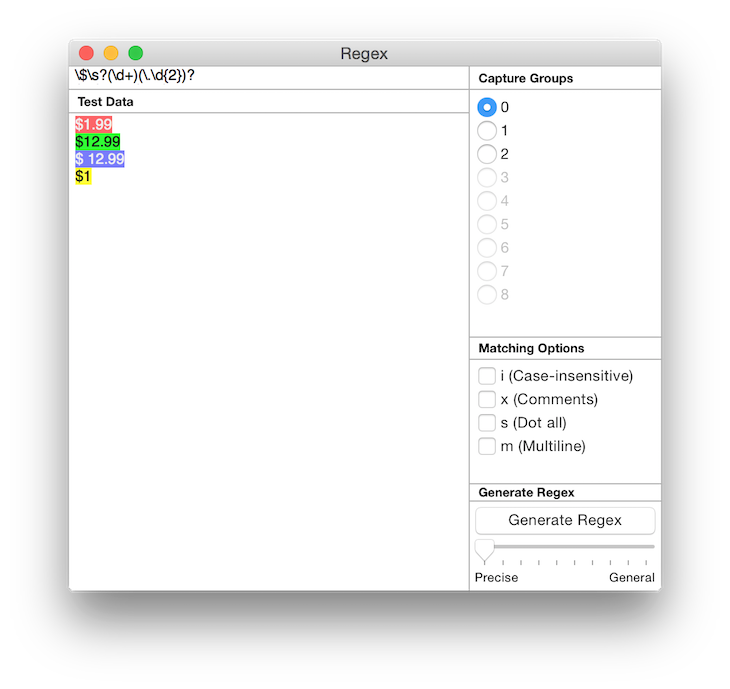
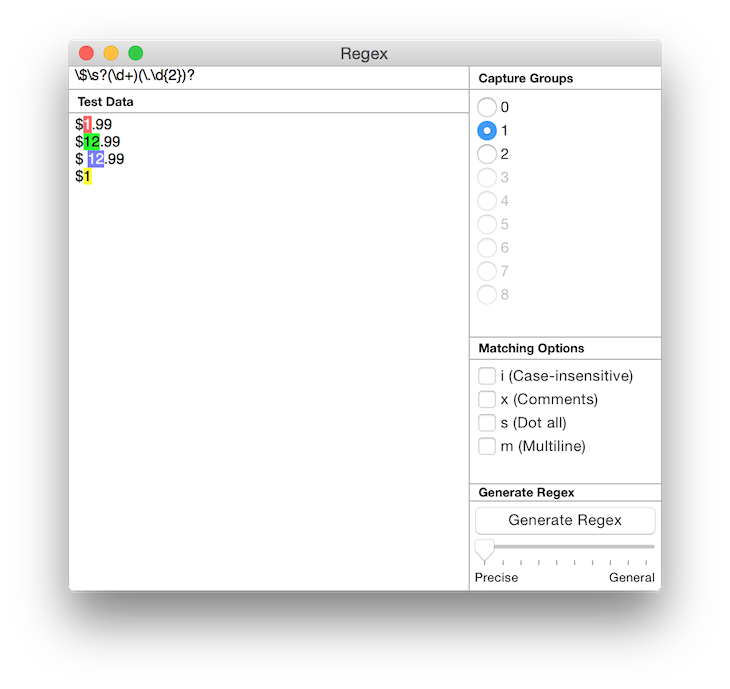
Notice that under Capture Group on the right, the radio buttons for 1 and 2 are now available? Press on 1. The dollar value will now be highlighted in the sample text area instead of the entire price. If you press 2, it will highlight the cents value. This is because capture group 0 refers to the string matching the entire expression, and capture groups 1, 2 and onwards refer to the string matching each parenthesis () group counting from the left.
There are additional features of regular expressions that can help with otherwise difficult to write expressions.
Positive Lookahead
Positive Lookahead forces a pattern to match only if it is followed by another pattern. i.e. the lookahead pattern is the suffix. Eg, given the source text:
This will have 3 matches for «aa», the indices [0,2], [2,4], [4,6].
What if you only want to match the «aa» that is followed by «111»? The following regex will match only index [4,6]:
Note that this is different from the following which will match the index [4,9].
Negative Lookahead
Negative Lookahead forces a pattern to match only if it is not followed by another pattern. E.g given the same source text:
What if you want to match both the «aa» that is not followed by «111»? The following regex will do it, using negative lookahead:
Positive Lookbehind
Positive Lookbehind works like Positive Lookahead, except the lookbehind expression is the prefix instead of the suffix. Given the same source text:
The following will match «111» and not «222»:
Negative Lookbehind
Similarly, Negative Lookbehinds matches only if the prefix doesn’t match.
The following will match «222» and not «111»:
Backreferences
Backreference is a placeholder for a previous match. This is useful where you have your target text surrounded by delimiting text. E.g. HTML tags (not that you should use Regular expressions for HTML as a matter of habit).
Given this source:
This will match the span tag and contents:
Notice the \1 backreference. \1 references to the first capture group, \2 for the 2nd and so on.
Additional Tip
If you need to use regular expressions in programming languages like Javascript, you will need to escape \ with an additional \ . For e.g. this expression
needs to be specified as the following in certain programming languages (including Javascript)
Regex for Mac OS X automatically does this escaping for you when you copy regex from the the app and automatically unescapes (removing double \) when you paste into the app.
Conclusion
This tutorial gives a simple introduction to building regular expressions using Regex for Mac OS X. You might have noticed that the price regex developed only matches $. What about pounds and other currencies? And you might find that the URL regex is overly simplistic. After working with regular expressions for some time, you will discover that they are very powerful and also needs to be used carefully. For example, see here for a much more accurate regex for matching URLs. It is very long and complex, making it hard to modify. For a good overview of regex, see the Wikipedia article for Regular Expression.
Interested in exploring regular expressions further? Check out the free trial of Regex for OS X:
Want more articles like this in your inbox? Join our newsletter to receive free email updates, tips and tricks related to iOS & OS X.
Источник
Регулярные выражения. Всё проще, чем кажется
Всем доброго времени суток. Сегодня хочу рассказать максимум о регулярных выражениях: что они из себя представляют, как их писать, для чего нужны и т.д.
Информации о регулярках много, они разбросаны по разным сайтам и я решил собрать всё, касательно регулярок, в одну статью. Ну что-ж, приступим поскорее к делу 🙂
Содержание
Что такое регулярка и с чем ее едят?
Где писать регулярки?
Самые простые регулярки
Специальные символы квантификаторов
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Регулярные выражения в разных языках программирования
Что такое регулярка и с чем ее едят?
Если по простому, регулярка- это некий шаблон, по которому фильтруется текст. Мы можем написать нужный нам шаблон (регулярку) и таким образом искать в тексте необходимые нам символы, слова и т.д. Также их используют, например, при заполнении поля E-mail на различных сайтах, т.е. создают шаблон по типу: someEmail@gmail.com. Это я взял как пример, не более. Теперь, разобравшись, что это, приступим к изучению. Обещаю, скучно не будет)
Где писать регулярки?
Регулярки мы можем писать как на специальных сайтах, так и используя какой-либо язык программирования. Синтаксис (правила написания регулярок) не привязан к какому-то отдельному языку программирования. Поэтому, изучив регулярные выражения, вы сможете пользоваться ими где захотите. Сначала, в рамках изучения, воспользуемся отличным сайтом, а как писать регулярные выражения в различных языках программирования, рассмотрим чуточку позже.
Сразу дам ссылку на сайт, чтобы вы могли уже писать вместе со мной https://www.regextester.com/
Коротко о том, как пользоваться сайтом. Сверху, в графе Regular Expression вы пишете само регулярное выражение, а под ним, в графе Test String вы пишете строку, которую вы хотите фильтровать. Если были найдены соответствия между регулярным выражением и текстом, в тексте эти соответствия будут помечены синим цветом, вы их сразу увидите, даже не сомневайтесь.
Самые простые регулярки
Перед тем, как писать регулярку, возьмем некоторый текст, чтобы мы не фильтровали пустоту. Допустим, у нас будет строка some text. И допустим мы хотим найти слово text. Для этого в саму регулярку мы должны написать просто слово text и он найдет его.
 Пример регулярки
Пример регулярки
Вот и всё, надеюсь вы поняли регулярные выражения, спасибо за внимание.
Шутка конечно, это далеко не всё. Например, мы можем написать одну букву t, и он найдет все буквы t в тексте.
Таким образом вы можете просто указывать какие-то символы, но нам не всегда даются конкретные символы, а нужно написать какой-то шаблон. Сейчас этим и займемся.
Квантификаторы
Понимаю, звучит страшно, но на деле все просто. Сейчас разберемся.
С помощью квантификаторов мы можем указывать сколько раз должен повторяться тот или иной символ (ну или группа символов). Ниже приведу список квантификаторов с пояснением, а дальше попрактикуемся с ними.
— символ повторяется ровно n раз
— символ повторяется в диапазоне от m до n раз
— символ повторяется минимум m раз (от m и более)
Теперь посмотрим на примерах. Допустим у нас есть строка s ss sss ssss. И мы хотим выбрать слово, где буква s повторяется ровно 3 раза. Для этого мы можем написать так: s — то есть пишем символ s, тем самым говоря, что хотим выбрать именно его, и рядом пишем <3>, говоря, что он должен повторяться ровно 3 раза. В результате будет найдено слово sss
Почему же он взял еще ssss? Он взял не совсем его, а лишь его часть, так как в нем тоже есть 3 буквы s подряд. Дело в том, что регулярка не будет учитывать, отдельное это слово или нет. Пробелы тоже идут как символы! Поэтому будет выбран любой фрагмент, которому соответствует 3 идущие подряд буквы s
Едем дальше, допустим мы хотим выбрать фрагмент, где символ s будет от одного до трех раз. Для этого мы можем написать s — опять же указываем s и пишем <1,3>, говоря, что нам нужно, чтобы этот символ повторялся от одного до трех раз.
Интересный момент получается, он выбрал все. Почему же? Ответ: та же ситуация, что и в прошлый раз. Он увидел ssss, взял 3 идущие подряд s вместе и еще одну s, которая рядом, ведь она тоже соответствует регулярку (а ведь мы помним, что мы указали диапазон от одного до трех раз)
Ну и напоследок, давайте напишем шаблон, где символ s будет повторяться минимум три раза. Для этого напишем следующее: s ( <3,>обозначает, что символ s будет повторяться от трех раз и до бесконечности).
Специальные символы квантификаторов
Есть уже готовые квантификаторы, которые обозначаются спец. символами. Вот они:
? (<0,1>) — символ повторяется 0 или 1 раз
* (<0,>) — символ повторяется от 0 раз и более
+ (<1,>) — символ повторяется от 1 и более раз
Давайте разбираться. Начнем со знака вопроса. Допустим у нас есть строка colour color и мы хотим найти либо colour, либо color. Мы можем написать так: colou?r.
Что произошло? Мы указали, что идет последовательность символов colo, потом написали u? (тоже самое, что и u<0,1>). Это значит, что символ u повторяется 0 или 1 раз (то есть либо его нет вовсе (он не повторяется, то есть повторяется 0 раз), либо он есть, но только один (повторяется один раз)). Ну а потом указали, что после должен идти символ r. Поэтому colour соответствует, так как буква u повторяется 1 раз, а color — так как u вообще отсутствует (повторяется 0 раз). Видите, все просто 🙂
Давайте изменим строку и напишем что-то по типу colouuuuur color. И допустим мы хотим указать, что u должен либо не быть, либо быть сколько угодно раз. Для этого мы можем написать colou*r.
То есть либо u у нас нет, либо повторяется много раз.
Символ + работает почти также, за исключением того, что символ должен повторяться минимум 1 раз. То есть в данном случае слово color не будет соответствовать, так как там u не присутствует (то есть повторяется 0 раз, а у нас символ должен повторяться минимум 1 раз)
Специальные символы
Теперь поговорим о специальных символах, которые используются в регулярках. Тут все очень просто, так что можете сильно не переживать. Скрины прикреплять буду здесь не везде (тогда статья разрастется до безумных размеров). Так что заранее прошу меня понять и простить и попробовать сами.
. — одиночный символ
[] — набор символов, например [A-Z] обозначает все символы от A до Z
^ — начало строки
$ — конец строки
\ — экранирование
\d — любая цифра
\D — все, кроме цифр
\s — пробелы
\S — все, кроме пробелов
\w — буква
\W — все, кроме букв
[^someSymbol] — отрицание символа, соответсвие всем символам, кроме выбранного
Поговорим об одиночном символе. Это значит, что будет выбираться любой символ, который повторяется только один раз. Например, вернемся к нашей строке Some text и выберем букву t, после которой идет любой символ. Для этого напишем t.
Выберется te, так как после t идет один любой символ (в данном случае е)
Едем дальше. Допустим, у нас есть строка Some text12345 и мы хотим выбрать все буквы (только буквы, числа нам не нужны). Для этого мы можем написать следующее [A-Z,a-z] . Что же это значит? Это значит, что мы указали, что мы хотим выбрать все символы в диапазоне от A до Z (это мы выбираем все заглавные буквы) и, затем, через запятую, мы говорим о том, что хотим выбрать все символы от a до z (здесь мы выбираем все строчные символы).
Теперь давайте возьмем слово test и выделим в нем первую букву t. Для этого мы можем написать ^t. То есть мы написали символ t и указали, что он должен находиться в самом начале строки. Важно поставить символ ^ перед нужным нам символом.
Теперь давайте сделаем наоборот и возьмем последнюю букву t. Для этого напишем t$. Важно, чтобы символ $ стоял после нужного нам символа.
Перейдем к экранированию. Звучит страшно, но на деле все проще простого. Например, в тексте some text. мы хотим выделить точку. Но ведь точка у нас уже зарезервирована как специальный символ (напоминаю, точка обозначает любой одиночный символ). И чтобы сделать так, чтобы точка на считалась как спец. символ мы можем написать \. и тем самым говоря, что точка у нас будет как обычный символ.
Теперь идут, простые вещи. \d у нас обозначает любую цифру. Например в тексте some text123, если написать \d у нас будут выделяться только цифры.
\D делает все наоборот: берутся все символы, кроме цифр. То есть, если написать \D будет браться все, кроме цифр (и пробелы, кстати, тоже).
\s берет все пробелы, которые есть в строке, а \S — наоборот, все, кроме пробелов.
\w берет буквы, а \W берет, все, кроме букв (в том числе и пробелы).
Теперь расскажу про еще одно применение символа ^. Его можно использовать как отрицание, тем самым исключая символ или группу символов. Например, в слове test мы хотим выбрать все, кроме буквы t и для этого мы можем написать так: [^t]
Именно в такой последовательности символ ^ будет обозначать отрицание.
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Давайте разберемся, что это такое. Lookahead или же опережающая проверка позволяет выбрать символ или группу символов, если после него идет идет какой-либо символ или группа символов. Lookbehind или же ретроспективная проверка позволяет выбрать символ или группу символов, если до них идет какой-то символ или группа символов.
lookahead — опережающая проверка — X(?=Y) — найти Х, при условии, что после него идет Y
негативная опрережающая проверка — Х(?!Y)
lookbehind — ретроспективная проверка — (?
Также мы можем сделать наоборот и выбрать символ s, если после него НЕ идет символ d. Для этого вместо знака равно мы должны поставить восклицательный знак (!), т.е. написать вот так: s(?!d)
Теперь поговорим о lookbehind. Допустим, у нас есть строка s ws ds ts es и мы хотим выбрать символ s, до которого будет символ d. Для этого мы можем написать так: (?
Почему же lookbehind подчеркивается красной линией? Дело в том, что lookbehind не всегда поддерживается и не везде такая регулярка будет работать. Нужно искать способ заменить этот lookbehind, но это зависит от поставленной задачи, поэтому нельзя сказать, как именно ее заменять. Будем надеяться, что в скором временем будет полная поддержка этой возможности.
Чтобы сделать наоборот, то есть выбрать все символы s, до которых НЕ будет идти символ d, нужно опять же поменять знак равно на восклицательный знак: (?
Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования. Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы
C#
Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку. В результате все сопоставления будут добавляться в коллекцию matches.
Java
Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.
JavaScript
Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Заключение
Итак, мы разобрали, что такое регулярные выражения, где они используются, как их писать и использовать в контексте языков программирования. Скажу сразу, написание регулярок приходит с опытом. Практикуйтесь, и я уверен: все у вас получится! А на этом я с вами прощаюсь. Спасибо за внимание и приятного всем дня)
Источник



