- Записная книжка ежа
- Мониторинг за час: influxdb, telegraf, grafana
- Предусловия
- Установка и настройка InfluxDB
- Установка и настройка Telegraf
- Установка и настройка Grafana
- Ansible-playbook для быстрого деплоя
- Grafana: инструмент для удобной визуализации метрик мониторинга
- Метрики мониторинга, которых тысячи
- Grafana — все метрики мониторинга в одном месте
- Grafana позволяет получать данные мониторинга в удобном виде
- Мониторинг GPU на серверах Windows ( TICK + Grafana + костыли )
Записная книжка ежа
Мониторинг за час: influxdb, telegraf, grafana
В этом посте описаны установка и настройка связки технологий, позволяющих быстро и достаточно просто получить работающий сервис мониторинга.
telegraf — агент по сбору данных
InfluxDB — база, предназначенная для хранения временных рядов (time series)
Grafana — для отображения метрик
В заключении приведен скрипт на ansible, позволяющий развернуть все это легким движением руки.
Предусловия
Все дальнейшие действия выполняются на машине с установленным CentOS7/Red Hat 7.
На сайте influxdata — разработчика InfluxDB и Telegraf представлена следующая схема:
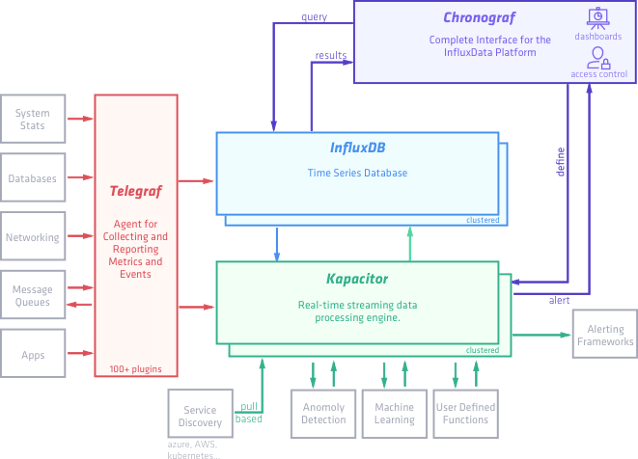
Называют они этот стек технологий TICK stack — по первым буквам (Telegraf, Influxdb, Chronograf, Kapacitor).
В рамках этого поста мы упрощаем эту схему и она принимает следующий вид:
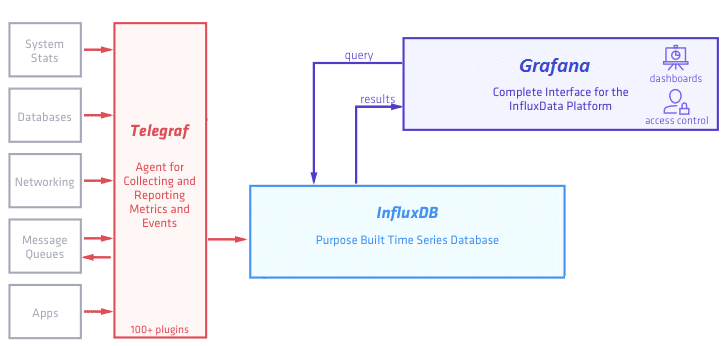
Во-первых мы пока убираем Kapacitor — движок для real-time обработки получаемых данных — его рассмотрим отдельно.
Во-вторых вместо предлагаемого influxdata дашборда Chronograf будем использовать более мощную и гибкую Grafana (хотя это по большому счету — дело вкуса).
Установка и настройка InfluxDB
Начнем с базы, в которой будут храниться результаты наших измерений.
Добавим репозиторий в менеджер пакетов YUM:
Установим influxdb и запустим сервис:
Чтобы сервис работал после перезагрузки машины, введем команду:
Проверяем, что все прошло хорошо, выполнив в консоли команду:
Создадим нашу первую базу командой:
Посмотрим что получилось:
Видим список:отать с базой, ее сначала нужно выбрать — для этого выполняем команду:
Попробуем добавить в базу значения. В документации указан такой формат:
В рамках статьи мы рассматриваем общий случай добавления измерений, очень подробный рассказ о всех возможных форматах команды — в документации здесь.
После этого смотрим какие измерения стали доступны:
Документация обещает нам SQL-like синтаксис, пробуем:
На что обращаем внимание: колонка time в таблице сформировалась автоматически — время мы указали только в первом случае, в остальных — добавилось текущее. Каждый тег стал «колонкой» в табличном представлении, результат измерения попал в колонку value.
Новые теги могут добавляться с любого момента, например так:
Используя SQL-like синтаксис легко можем получить выборку по квартире:
И даже посчитать среднюю температуру по больнице:
Также можно добавлять данные через REST API:
И читать данные через REST API в формате JSON:
На этом краткое знакомство с базой InfluxDB можно закончить, очень много подробной информации при необходимости можно найти в документации. А мы пойдем дальше.
Установка и настройка Telegraf
Telegraf — агент для сбора данных, у него есть множество плагинов как для ввода так и для вывода. Yum-репозиторий influxdata мы уже добавили в самом начале, так что сразу установим telegraf.
Далее надо сгенерировать конфигурационный файл. Для этого наберем команду:
Команда означает следующее: ув. телеграф, будь добр — создай нам конфигурационный файл telegraf.conf, в котором задействуй плагины ввода данных cpu, mem и exec (их вообще очень много, можно хоть данные с сервера minecraft собирать), вывода данных — influxdb (можно еще в grafite, elasticsearch и много куда еще).
Встроенные плагины cpu и mem отвечают за сбор данных об активности процессора и памяти соответственно. А вот плагин exec — предоставляет возможность использовать для сбора данных произвольные скрипты.
В сгенерированном файле видим следующее:
В output plugins -> influxdb указываем/изменяем данные для подключения к базе:
Cмотрим пример настроек плагина exec для сбора данных произвольным скриптом:
Попробуем написать свой такой скрипт:
Задача у скрипта простая — пробуем найти в процессах [k]araf.main.Main ([k] — взято в скобки специально, таким образом мы исключим из вывода сам grep), если выходной код 0 — то выводим строку с данными для influxdb.
Добавляем метрику process_status с тегами host и proc и значением working равным 0 или 1 в зависимости от результата проверки.
Сохраняем этот скрипт как /opt/telegraf/check_karaf.sh и редактируем конфиг:
Кладем полученный конфиг в /etc/telegraf/telegraf.conf и запускаем сервис:
Посмотрим в базе — появились ли данные:
Данные пишутся, на этом с telegraf пока закончим, выполнив напоследок следующую команду, чтобы сервис telegraf запускался после каждой перезагрузки:
Установка и настройка Grafana
Почти готово — осталось настроить дашборд для отображения собранных метрик.
Установим и запустим Grafana:
По умолчанию grafana запустится на порту 3000. Идем браузером на http://host:3000/login, видим окно:

Авторизуемся, используя стандартные логин и пароль: admin / admin.
Если чуда не произошло и на порту 3000 искомого веб-интерфейса мы не увидели, смотрим логи в /var/log/grafana.
В интерфесе первым делом настраиваем источник данных (datasources — add datasource):
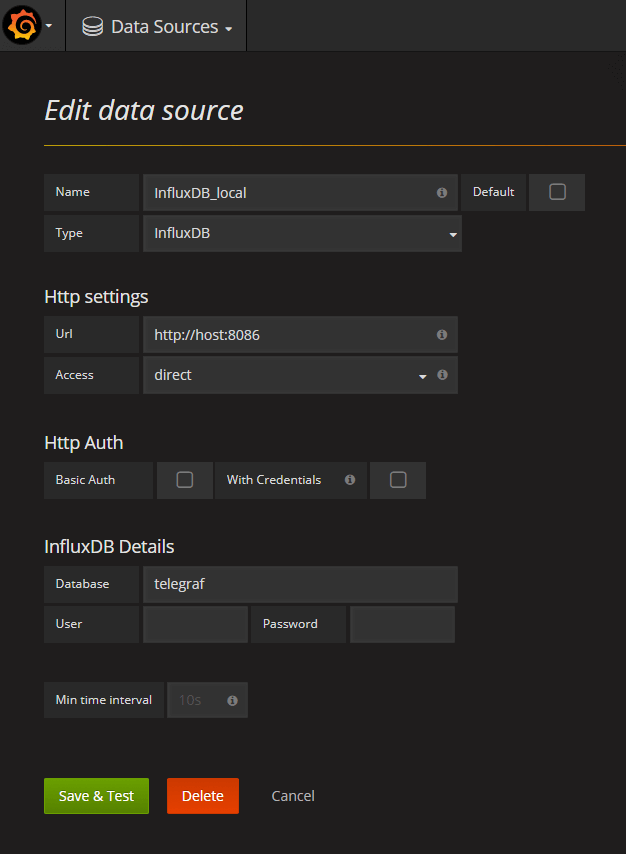
Далее создаем свой первый дашборд и следуя подсказкам интерфейса конструируем запрос, например так:
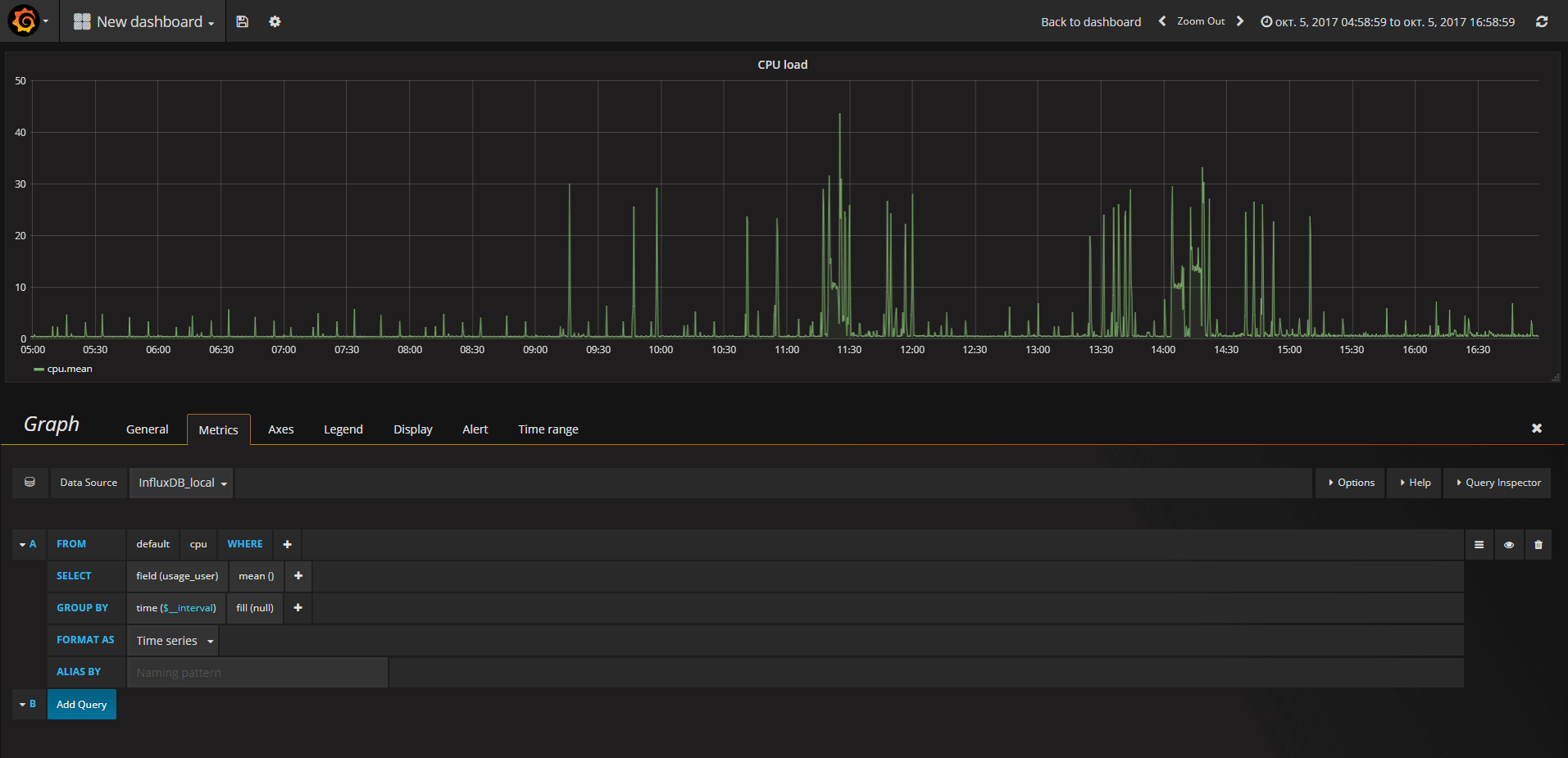
Дальнейший процесс носит скорее творческий, чем технический характер. По большому счету можно и не знать синтаксис SQL, а ориентироваться на настройки, предоставляемые интерфейсом Grafana.
Создав dashboard, мы можем его экспортировать в json-формате и в дальнейшем загрузить на другом хосте. Мы будем активно использовать эту возможность при создании ansible-скрипта.
Еще один важный момент — понимание того, что все операции, которые могут быть совершены в Grafana через интерфейс, могут быть с таким же успехом выполнены через HTTP REST API. Подробная документация по HTTP API здесь.
Ansible-playbook для быстрого деплоя
Ansible — популярный инструмент для управления конфигурациями. В случае, когда надо выполнить описанные выше действия на большом количестве виртуалок, часть из которых периодически умирают и появляются новые, ansible может очень сильно облегчить жизнь.
Ниже привожу код playbook-а, выполняющего описанные в статье действия. Сразу оговорюсь — playbook приведен для примера и не является образцом аккуратности и правильности с т.з. лучших практик ansible. На практик, конечно, лучше выделить отдельные роли и вызывать их и т.д.
На первом шаге плейбука мы добавляем нужные репозитории и устанавливаем telegraf, influxdb, grafana. Далее на втором шаге конфигурируем telegraf, используя шаблон jinja2, затем запускаем все сервисы и создаем источник данных/импортируем дашборд в grafana, используя REST API.
На этом, наверное, можно закончить. Дочитавшим — котика 🙂
Grafana: инструмент для удобной визуализации метрик мониторинга
«Если результат от запуска IT-проекта нельзя измерить — то как понять, что вы запустили нужный проект?», — говорят грамотные управленцы и бизнесмены. И с ними не поспоришь. Сейчас мы разберемся с тем, что такое Grafana, как она помогает принимать решения и кому нужен этот инструмент.
Метрики мониторинга, которых тысячи
Любой мало-мальски вменяемый IT-проект — это разные метрики. Среднее число активных пользователей в сутки, количество регистраций в неделю, средний чек на клиента, количество активных юзеров, пользующихся новой фичей, — это примеры метрик, с которыми приходится каждый день иметь дело управленцам и владельцам бизнеса. Конечно, это далеко не полный список — крупная компания легко может собирать показатели по тысячам параметров.
Аналитики как раз те люди, которые извлекают из метрик пользу. Они смотрят на колонки цифр и формируют гипотезы и рекомендации по тому, куда и как бизнес должен двигаться дальше.
Эти ребята в основном занимаются математикой и статистикой. Некоторые из них в состоянии самостоятельно писать запросы в базы данных, но это не их основная специальность. А раньше дела обстояли еще хуже — почти никто из аналитиков не умел работать с СУБД.
Поэтому, чтобы обеспечить аналитический отдел топливом в виде метрик, приходилось отвлекать программистов от работы и просить их выгрузить нужные значения из таблиц СУБД. Конечно, это сильно затрудняло процесс.
В итоге появилась Grafana — универсальный инструмент мониторинга, с помощью которого аналитики и даже некоторые менеджеры смогли сами ходить в системы хранения метрик и извлекать все нужные данные. И даже строить сложные графики с учетом множества разных параметров.
Grafana — все метрики мониторинга в одном месте
Grafana — универсальная обертка для работы с аналитическими данными, которые хранятся в разных источниках. Она сама ничего не хранит и не собирает, а является лишь универсальным клиентом для систем хранения метрик. Например, с помощью нее можно ходить за цифрами как в традиционную базу PostgreSQL , так и в специализированные аналитические системы типа Prometheus или Influx.
Графану можно подключать к любому хранилищу статистических данных. Разные отделы компа н ии могут использовать разные СУБД и системы сбора статистики. Так вот, Grafana умеет работать с любой популярной системой хранения данных. Конечно, делает она это не сама — первоначальную настройку и подключение к СУБД выполняют администраторы. Но на этом их работа заканчивается — дальше аналитики могут самостоятельно строить свои запросы.
Системы хранения данных на рисунке выше — лишь малая часть того, куда Grafana может подключаться для отображения статистики. Если вам нужно что-то очень редкое — всегда можно найти и поставить дополнительные плагины. А их много — комьюнити вокруг инструмента очень активное и дружное.
Grafana позволяет получать данные мониторинга в удобном виде
Графана умеет подключаться к хранилищу и выполнять там определенные запросы. Запросы конструируются аналитиками в специальном удобном интерфейсе, помогающем сосредоточиться именно на данных, а не на правильности написания запросов в СУБД. Полученные результаты Grafana показывает в доступном виде. Это могут быть как простые таблицы, так и графики, распределения и десятки других форматов отображения данных.
Запросы отрисовываются на графиках, в таблицах или выводятся напрямую в абсолютных значениях. Сами отображения можно группировать между собой и собирать в интерактивные дашборды.
Хочется все продуктовую аналитику на одном экране? Пожалуйста! Хочется сделать дашборд по результатам последней распродажи (количество клиентов, средний чек, выручка, время активности на сайте) — нет проблем: собираем запросы, выбираем отображения, группируем их все в дашборд.
Если вы работаете в техническом отделе, то для вас тоже есть всё, что нужно: нагрузка на сеть, загрузка серверов и место на диске — всё это легко достается на отдельный дашборд.
В Mail.ru Cloud Solutions Grafana входит во встроенную систему мониторинга кластеров Kubernetes , которые клиенты разворачивают в облаке. С ее помощью можно настроить мониторинг инфраструктуры и пользовательских приложений.
По сути — это швейцарский армейский нож аналитика, который может достать и отобразить любую информацию.
И самое главное — возможность легко пересечь на одном отображении данные из разных источников. Продажники пишут данные в PostgreSQL, а логистика — в Prometheus? Не проблема, всё можно вывести на одном графике.
Запросами и картинками дело не ограничивается — есть возможность поделиться дашбордом с участниками команды и вместе поработать над какими-то метриками. А еще можно настроить уведомления по разным метрикам. Упали продажи? Получите письмо с предупреждением!
Из минусов можно упомянуть только один — установка Grafana на сервер потребует определенных танцев с командной строкой. Но это легко лечится — хорошие облачные хостеры всегда предоставят вам готовый к использованию облачный сервер с уже готовым к работе инструментом. В маркетплейсе MCS можно в несколько кликов установить современную систему мониторинга на основе Grafana, Prometheus и Alertmanager.
Мониторинг GPU на серверах Windows ( TICK + Grafana + костыли )
В распоряжении у меня оказалось несколько серверов, на базе Windows, осуществляющих захват, кодирование и архивирование видео. Ключевой особенностью этой системы является то, что кодирование реализовано на базе Intel Quick Sync Video, т.е. на базе GPU.
При таком раскладе, мониторинг просто CPU, уже не является главным указателем состояния сервера, а для полной картины требуется отслеживать загрузку как CPU, так и GPU. Серверы работают в режиме real time, поэтому приходится иметь дело с потоками, а не файлами, это означает, что если GPU превысит максимальную нагрузку, возможны потери видео ( в случае файлов кодирование продолжится, со скоростью менее real time ), поэтому поглядывать за работой видеокарты необходимо.
Конечным результатом, приведенных ниже подпорок и костылей, являются графики построенные в Grafana:
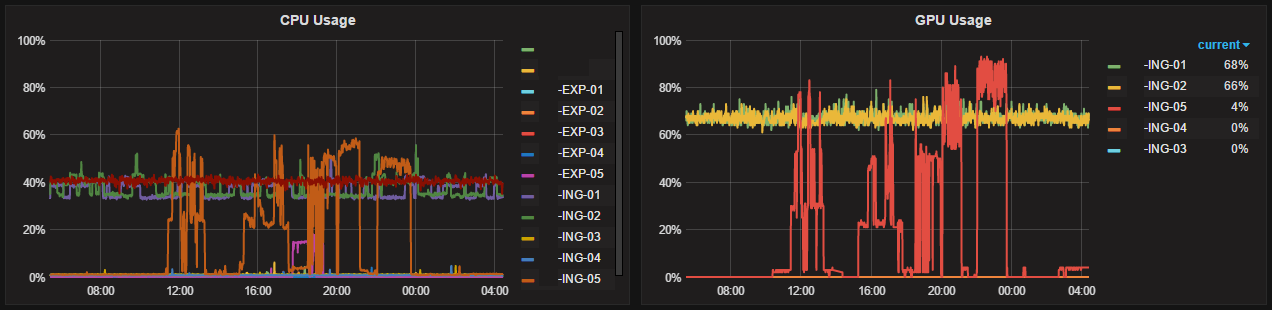
В данной статье рассматривается мониторинг на базе TICK ( telegraf, influxdb, chronograf, kapacitor) + Grafana, поэтому все настройки и вывод скриптов адаптированы именно под этот стек технологий, но, при некотором допиливании все приведенное ниже может быть перенесено и в другие системы мониторинга. Еще один нюанс — данная реализация сделана для Windows.
В случае, если с видеокартами Nvidia все понятно, когда сразу после установки драйвера, на компьютере оказываются как консольная утилита nvidia-smi, так и подраздел Nvidia GPU в стандартном Perfomance Monitor, то в случае отслеживания работы Intel GPU все не так очевидно. Все утилиты, которые мне попадались ориентированы на работу в GUI, поэтому в данном месте появляется первый костыль — работу будет отслеживать утилита с GUI.
В настоящий момент, одним из лидеров среди программ такого рода является утилита GPU-Z, немаловажным является наличие логирования.
Настройка логирования в GPU-Z (галочка снизу):

На данном этапе появляется первая сложность — GPU-Z свой лог пишет в формате CSV, с минимальной частотой в 10 сек, что сказывается на объеме лог-файла, поэтому, если считывать файл построково или целиком периодически, то из-за бесконечного роста, работа с ним достаточно трудозатратна.
Второй костыль заключается в настройке ротации логов утилиты GPU-Z. Лог за одни сутки получается небольшого размера, и вполне может быть быстро обработан скриптом, поэтому целью ротации является небольшие файлы, хранящие информацию за сутки. GPU-Z всегда запускается с правами администратора, при автоматическом запуске это требует обхода встроенной в Windows защиты UAC, поэтому, для автоматизации запуска скрипта ротации применяется Windows Scheduler, с выставленной настройкой: Run with highest privileges.

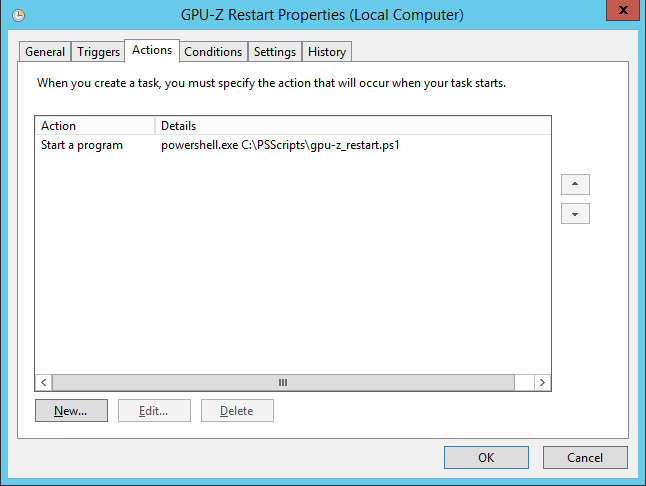
Windows Scheduler запускает скрипт, выполняющий последовательность действий:
1) завершить программу GPU-Z
2) переместить лог в архив
3) запустить утилиту свернутой в трей
Скрипт написан на PowerShell, и выглядит следующим образом:
Оказалось, что во время работы GPU-Z не финиширует лог, т.е. его можно считать тем же PowerShell-ом, а вот логпарсер telegraf не видит обновлений. К тому же утилита GPU-Z пишет лог слишком часто ( раз в 10 сек ) в моем случае, вполне достаточно сбора показаний раз в минуту. В этом месте появляется третий костыль — для передачи данных в telegraf был написан небольшой парсер, который выбирает последнюю строку из лога GPU-Z и отдает данные в telegraf в формате graphite.
Данный формат был выбран по той причине, что стандартный для telegraf формат influx не поддерживает подмену timestamp, мне же хочется видеть честный timestamp из лога, а не сгенерированный в момент считывания строки. В нижеследующем скрипте это учтено, а timestamp из лога преобразован в unix time, в соответствии формату graphite.
Скрипт снова на PowerShell:
Данный скрипт запускается самим telegraf-ом, с частотой раз в минуту, согласно следующему правилу:
В результате в системе TICK собираются данные, отражающие состояние GPU, на базе которых можно либо настраивать мониторинг, либо, как в данном случае делать графики, для анализа работы и аналитики.



