- Как просмотреть нагрузку на процессор в Linux
- Команда ps
- Команда top
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Загрузка ЦПУ в Linux — насколько варит ваш котелок
- Методы проверки
- Проверяем загрузку процессора с помощью команды top
- Немного более модный способ: htop
- Прочие способы проверки степени загрузки ЦПУ
- Как настроить оповещения о слишком высокой нагрузке на процессор
- Заключение
- CPU Load: когда начинать волноваться?
- Аналогия транспортного потока
- Так Вы говорите, 1.00 — идеальное значание load average?
- Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
- Многоядерность vs. многопроцессорность
- Сведем все вместе
- Примечания переводчика
Как просмотреть нагрузку на процессор в Linux
В Linux потребление ресурсов CPU, с сортировкой по наибольшей загрузке, можно посмотреть при помощи двух команд: ps и top.
Важный нюанс: Значение в столбце «CPU» в обоих командах считается от загрузки одного ядра процессора. Таким образом сумма процентов на многоядерных машинах будет больше 100%. К примеру для четырехядерного процессора суммарный процент потребления всех процессов не может превышать 400%.
Рассмотрим каждую из команд подробней.
Команда ps
Для запуска введите в консоли ОС команду:
Пример вывода команды:
Важными столбцами являются:
- USER Пользователь, от имени которого работает процесс
- PID Идентификатор процесса
- %CPU Процент загрузки ядра
Согласно данному выводу можно понять, что экземпляр программы dd с PID=31712 практически полностью использует одно ядро процессора.
Команда top
Также загрузку процессора можно посмотреть в интерактивном режиме при помощи команды top. Для запуска введите в консоли ОС команду:
Пример вывода команды:
Важными столбцами являются:
- USER Пользователь, от имени которого работает процесс
- PID Идентификатор процесса
- %CPU Процент загрузки ядра
Согласно данному выводу видно, что два процесса браузера Chromium используют по 40% возможностей одного из ядер процессора.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Загрузка ЦПУ в Linux — насколько варит ваш котелок
Понимать состояние ваших серверов с точки зрения их загрузки и производительности — крайне важная задача. В этой статье мы опишем несколько самых популярных методов для проверки и мониторинга загрузки ЦПУ на Linux хосте.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps


Методы проверки
Проверяем загрузку процессора с помощью команды top
Отличным способом проверки загрузки является команда top. Вывод этой команды выглядит достаточно сложным, зато если вы в нем разберетесь, то точно сможете понять какие процессы занимают большую часть ваших вычислительных мощностей.
Команда состоит всего из трех букв: top
У вас откроется окно в терминале, которое будет отображать запущенные сервисы в реальном времени, долю системных ресурсов, которую эти сервисы потребляют, общую сводку по загрузке CPU и т.д
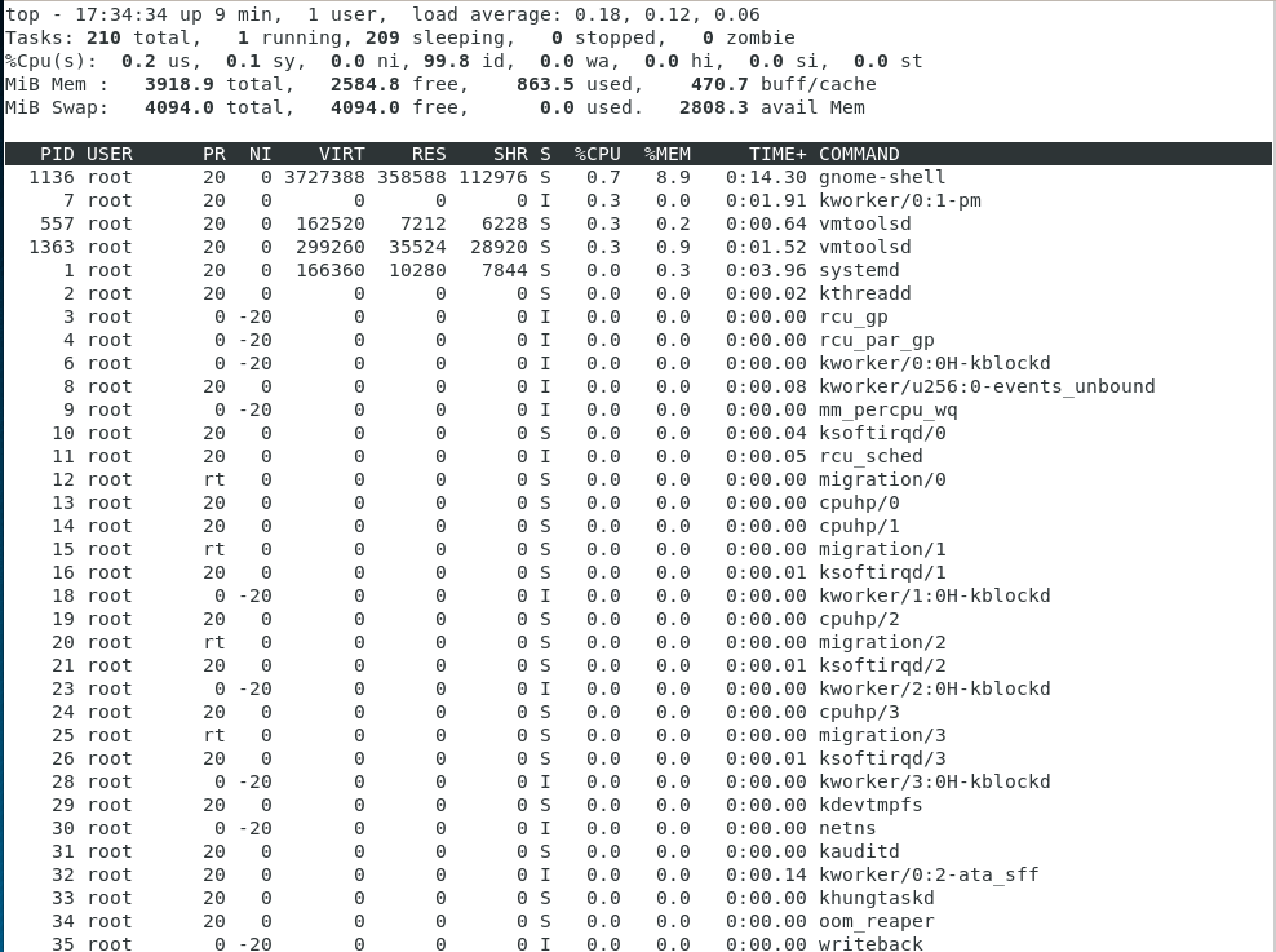
Будем идти по порядку: первая строчка отображает системное время, аптайм, количество активных пользовательских сессий и среднюю загруженность системы. Средняя загруженность для нас особенно важна, т.к дает понимание о среднем проценте утилизации ресурсов за некоторые промежутки времени.
Три числа показывают среднюю загрузку: за 1, 5 и 15 минут соответственно. Считайте, что эти числа — это процентная загрузка, т.е 0.2 означает 20%, а 1.00 — стопроцентную загрузку. Это звучит и выглядит достаточно логично, но иногда там могут проскакивать странные значения — вроде 2.50. Это происходит из-за того, что этот показатель не прямое значение загрузки процессора, а нечто вроде общего количества «работы», которое ваша система пытается выполнить. К примеру, значение 2.50 означает, что текущая загрузка равна 250% и ваша система на 150% перегружена.
Вторая строчка достаточна понятна и просто показывает количество задач, запущенных в системе и их текущий статус.
Третья строчка позволит вам отследить загрузку ЦПУ с подробной статистикой. Но здесь нужно сделать некоторые комментарии:
- us: процент времени, когда ЦПУ был загружен и которое было затрачено на user space (созданные/запущенные пользователем процессы)
- sy: процент времени, когда ЦПУ был загружен и которое было затрачено на на kernel (системные процессы)
- ni: процент времени, когда ЦПУ был загружен и которое было затрачено на приоритезированные пользовательские процессы (системные процессы)
- id: процент времени, когда ЦПУ не был загружен
- wa: процент времени, когда ЦПУ ожидал отклика от устройств ввода — вывода (к примеру, ожидание завершения записи информации на диск)
- hi: процент времени, когда ЦПУ получал аппаратные прерывания (например, от сетевого адаптера)
- si: процент времени, когда ЦПУ получал программные прерывания (например, от какого-то приложения адаптера)
- st: сколько процентов было «украдено» виртуальной машиной — в случае, если гипервизору понадобилось увеличить собственные ресурсы
Следующие две строчки показывают сколько занято/свободно оперативно памяти и файла подкачки, и не так релевантны относительно задачи проверки нагрузки на процессор. Под информацией о памяти вы увидите список процессов и процент ЦПУ, который они тратят.
Также вы можете нажимать на кнопку t, чтобы прокручивать между различными вариантами вывода информации и использовать кнопку q для выхода из top
Немного более модный способ: htop
Существует более удобная утилита под названием htop, которая предоставляет достаточно удобный интерфейс с красивым форматированием. Установка утилиты экстремально проста:
Для Ubuntu и Debian:
sudo apt-get install htop
Для CentOS и Red Hat:
yum install htop
dnf install htop
После установки просто введите команду ниже:

Как видно на скриншоте, htop гораздо лучше подходит для простой проверки степени загрузки процессора. Выход также осуществляется кнопкой q
Прочие способы проверки степени загрузки ЦПУ
Есть еще несколько полезных утилит, и одна из них (а точнее целый набор) называется sysstat.
Установка для Ubuntu и Debian:
sudo apt-get install sysstat
Установка для CentOS и Red Hat:
yum install sysstat
Как только вы установите systat, вы сможете выполнить команду mpstat — опять же, практически тот же вывод, что и у top, но в гораздо лаконичнее.

Следующая утилита в этом пакете это sar. Она наиболее полезна, если вы ее вводите вместе с каким-нибудь числом, например 6. Это определяет временной интервал, через который команда sar будет выводить информацию о загрузке ЦПУ.

К примеру, проверяем загрузку ЦПУ каждые 6 секунд:
Если же вы хотите остановить вывод после нескольких итераций, например 10, добавьте еще одно число:
Так вы также увидите средние значения за 10 выводов.
Как настроить оповещения о слишком высокой нагрузке на процессор
Одним из самых правильных способов является написание простого bash скрипта, который будет отправлять вам алерты о слишком высокой степени утилизации системных ресурсов.
Скрипт будет использовать обработчик sed и среднюю загрузку от команды sar. Как только нагрузка на сервер будет превышать 85%, администратор будет получать письмо на электронную почту. Соответственно, значения в скрипте можно изменить под ваши требования — к примеру поменять тайминги, выводить алерт в консоль, отправлять оповещения в лог и т.д.
Естественно, для выполнения этого скрипта нужно будет запустить его по крону:
Для ежеминутного запуска введите:
Заключение
Соответственно, лучшим способом будет комбинировать эти способы — например использовать htop при отладке и экспериментах, а для постоянного контроля держать запущенным скрипт.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена
Источник
CPU Load: когда начинать волноваться?
Данная заметка является переводом статьи из блога компании Scout. В статье дается простое и наглядное объяснение такого понятия, как load average . Статья ориентирована на начинающих Linux-администраторов, но, возможно, будет полезна и более опытным админам. Заинтересовавшимся добро пожаловать под кат.
Вероятно, Вы уже знакомы с понятием load average . Load average — это три числа, отображаемые при выполнении команд top и uptime . Выглядят они примерно так:
Большинство интуитивно понимают, что эти три числа обозначают средние значения загрузки процессора на прогрессивно увеличивающихся временных промежутках (одна, пять и пятнадцать минут) и чем меньше их значения — тем лучше. Большие числа свидетельствуют о слишком большой нагрузке на сервер. Но какие значения считать предельными? Какие значения являются «плохими», а какие — «хорошими»? Когда Вам следует просто волноваться о занчениях средней загрузки, а когда следует бросать другие дела и решать проблему так быстро, как это возможно?
Для начала, давайте разберемся, что же означает load average . Рассмотрим простейший случай: предположим, что у нас в наличии один сервер с одноядерным процессором.
Аналогия транспортного потока
Одноядерный процессор похож на дорогу с одной полосой движения. Представьте себе, что Вы управяете движением машин по мосту. Иногда, Ваш мост загружен настолько сильно, что машинам приходится ждать в очереди чтобы проехать по нему. Вы хотите дать людям понять, как долго им придется ждать чтобы перебраться на другую сторону реки. Хорошим способом сделать это будет показать как много машин ждут в очереди в конкретный момент времени. Если машин в очереди нет, подъезжающие водители будут знать, что они сразу смогут проехать по мосту. В противном случае, они будут понимать, что придется ждать своей очереди.
Итак, Управляющий Мостом, какую систему обозначений Вы будете использовать? Как насчет такой:
- 0.00 означает, что на мосту нет ни одной машины. Фактически, значения от 0.00 до 1.00 означают отсутствие очереди. Подъезжающая машина может воспользоваться мостом без ожидания;
- 1.00 означает, что на мосту находится как раз столько автомобилей, сколько он может вместить. Все еще идет хорошо, но, в случае увеличения потока машин, возможны проблемы;
- Значения, превышающие 1.00 означают наличие очереди на въезде. Насколько большой? Например, значение 2.00 показывает, что в очереди стоит столько же автомобилей, сколько движется по мосту. 3.00 означает, что мост полностью занят и в очереди ожидает в два раза больше машин, чем он может вместить. И так далее.
 load average = 1.00 load average = 0.50 load average = 1.70
load average = 1.00 load average = 0.50 load average = 1.70
Вот базовое значение загрузки процессора. «Машины» обрабатываются с использованием промежутков процессорного времени («пересекают мост»), либо ставятся в очередь. В Unix это называется длина очереди выполнения: количество всех процессов, выполняемых в данный момент времени, плюс количество процессов, ожидающих в очереди.
Вам, как управляющему мостом, хотелось бы, чтобы машины-процессы никогда не ждали в очереди. Таким образом, предпочтительно, чтобы загрузки процессора была всегда ниже 1.00. Периодически возможны всплески трафика, когда загрузка будет превышать 1.00, но если она постоянно превышает данное значение — это повод начать волноваться.
Так Вы говорите, 1.00 — идеальное значание load average?
Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
У Вас четырехпроцессорная система? Все в порядке, если load average равен 3.00.
В мультипроцессорных системах загрузка вычисляется относительно количества доступных процессорных ядер. 100% загрузка обозначается числом 1.00 для одноядерной машины, числом 2.00 для двуядерной, 4.00 для четырехъядерной и т.д.
Если вернуться к нашей аналогии с мостом, 1.00 означает «одну полностью загруженную полосу движения». Если на мосту всего одна полоса, 1.00 означает, что мост загружен на 100%, если же в наличии две полосы, он загружен всего на 50%.
То же самое с процессорами. 1.00 означает 100% загрузки одноядерного процессора. 2.00 — 100% загрузки двуядерного и т.д.
Многоядерность vs. многопроцессорность
Сведем все вместе
Давайте посмотрим на средние значения загрузки с помощью команды uptime :
Здесь представлены показатели для системы с четырехъядерным процессором и мы видим, что имеется большой запас по нагрузке. Я даже не буду задумываться о ней, пока load average не превысит 3.70.
Какое среднее значение мне следует контролировать? Для одной, пяти или 15 минут?
Количество ядер важно для правильно понимания load average. Как мне его узнать?
Команда cat /proc/cpuinfo выводит информацию обо всех процессорах в вашей системе. Чтобы узнать количество ядер, «скормите» ее вывод утилите grep :
Примечания переводчика
Выше представлен перевод самой статьи. Также много интересной информации можно почерпнуть из комментариев к ней. Так, один из комментаторов говорит о том, что не для каждой системы важно иметь запас по производтельности и не допускать значения загрузки выше 0.70 — иногда нам нужно чтобы сервер работал «на всю катушку» и в таких случаях load average = 1.00 — то, что доктор прописал.
Хабраюзер dukelion добавил в комментариях ценное замечание, что в некоторых сценариях, для достижения максимального КПД «железа», стоит держать значение load average несколько выше 1.00 в ущерб эффективности работы каждого отдельного процесса.
Хабраюзер enemo в комментариях добавил замечание о том, что высокий показатель load average может быть вызван большим количеством процессов, выполняющих в данный момент операции чтения/записи. То есть, load average > 1.00 на одноядерной машине не всегда говорит о том, что в Вашей системе отсутствует запас по загрузке процессора. Требуется более внимательное изучение причин такого показателя. Кстати, это хорошая тема для нового поста на Хабре 🙂
Источник



