Настройка DHCP на одном сервере для 7 VLAN
 Cisco Packet Tracer настройка роли DHCP на отдельном сервере в ЛВС с VLAN
Cisco Packet Tracer настройка роли DHCP на отдельном сервере в ЛВС с VLAN
Доброго утра, товарищи! Прошу оказать содействие в решение вопроса по настройке DHCP на отдельном.
Сложная настройка коммутатора DHCP-Relay для разных vlan
Добрый день, подскажите с настройкой коммутатора, схема такая. Есть комутатор Циско 2960 на нем 2.
VLAN на базе двух коммутаторов, настройка DHCP (Cisco Packet Tracer)
Добрый день. Нужна помощь по настройке, а точнее найти ошибку в настройке. Мною выполняется.
Настройка DHCP на сервере Win 2003.
Есть сеть из 25 машин( Win xp ) и 2 сервака ( Win 2000) и (Win 2003). На серваке с 2003 нужно.
Да, на Win сервере ничего кроме добавления Scope делать не нужно.
Вот один из примеров — коммутаторы Cisco, MS Windows DHCP и 6 VLAN`ов:
Добавлено через 3 минуты
+ здесь показано, как добавлять Области (Scope):
и первым делом сказано:
Под фразой «layer-3 switch» у меня «межсетевой экран-роутер» Dfl-860e, это как бы логично что сначала делаем вланы а потом уже к ним dhcp сервер) на цисках я помню это ip helper address а в терминологии сетей это dhcp relay
Добавлено через 19 минут
Еще вопрос, настраивая вланы на роутере, я не потеряю доступ к самому роутеру? и по какому адресу к нему подключаться для конфига потом?
Потеряете. Именно для этого и предназначена VLAN-технология — отключать для сетевого администратора доступ к обслуживаемому оборудованию.
А если серьёзно — вы являясь сетевым администратором (dhcp, межсетевой экран-роутер Dfl-860e) узнали о VLAN, решили их использовать, запланировали «7 вланов» и теперь спрашиваете, а будет ли это работать? Я вам отвечу да (у меня всё работает), после чего вы неизвестно что настроите и положите всю рабочую сеть. Странный подход.
Чтобы «не потерять доступ к самому роутеру» и всё работало, как надо:
DHCP сервер на нескольких VLAN
Под термином “клиент” будем понимать зону ответственности за совокупность сетевых устройств.
Требуется обеспечить доступ для нескольких сотен клиентов к неким общим ресурсам в таком режиме, чтобы:
- Каждый клиент не видел трафик остальных клиентов.
- Неисправности одного клиента (broadcast-storm, конфликты IP-адресов, не санкционированные DHCP-сервера клиента и т.п.) не должны влиять на работу как других клиентов, так и всей системы в целом.
- Каждый клиент не должен напрямую получать доступ к ресурсам других клиентов (хотя, как специальный случай, можно предусмотреть и разрешение данного трафика, но с его централизованным контролем и/или управлением ).
- Клиенты должны иметь возможность получения доступа к общим внешним ресурсам (которыми могут быть как отдельные сервера, так и сеть Интернет в целом).
- Общие ресурсы должны также иметь возможность доступа к ресурсам клиентов (конечно при условии, что известен общему ресурсу известен IP-адрес ресурса клиента).
- Адресное пространство для клиентов выделяется централизованно и его администрирование не должно быть чрезмерно сложным.
В качестве примеров практического применения можно назвать изоляцию локальных сетей отделов в крупной организации, организацию VoIP-связи или доступа в сеть Интернет для нескольких независимых потребителей и т.п.
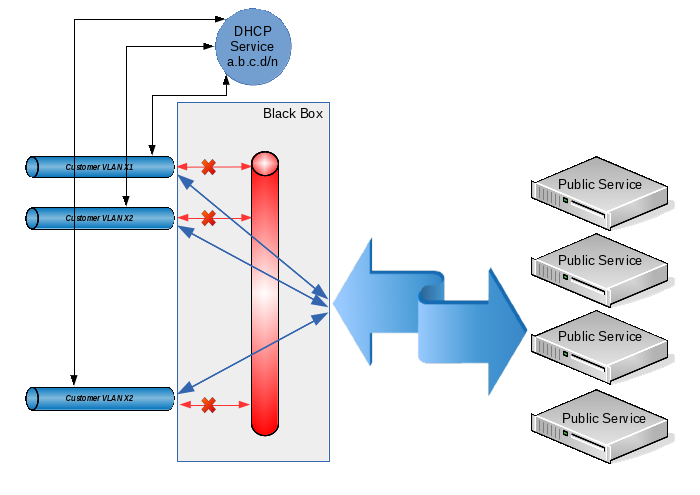
Условия 1 и 2 достигаются выделением каждому клиенту собственного VLAN. Условия 3-5 можно выполнить путем объединения клиентских VLAN с запретом прямой передачи трафика между ними. В некоторых источниках эта технология называется “private VLAN”, в некоторых “port isolation”, а смысл ее такой: из каждого клиентского VLAN можно беспрепятственно попасть в некий общий VLAN (и, соответственно, обратно), но вот между клиентскими VLAN передача трафика запрещена. Ну а для выполнения условия 6 выделим для всех клиентов общее адресное пространство вида 10.12.8.0/23, а конкретные IP-адреса будем выдавать по запросу при помощи DHCP.
Таким образом, при появлении у клиента нового устройства адрес для него будет выдан автоматически (и у нас не будет проблем из-за того, что один клиент может использовать для своих нужд единицы IP-адресов, а другому потребуются их десятки или сотни), а при добавлении нового клиента мы просто создадим еще один VLAN и добавим его в нашу общую группу. Даже если из-за большого количества клиентских устройств первоначально выделенное нами адресное пространство будет исчерпано, то мы всегда сможем его расширить, изменив настройки всего в двух местах (на DHCP-сервере и на интерфейсе, который объединяет все клиентские VLAN).
Технически описанное выше решение можно реализовать только аппаратными средствами на коммутаторах уровня L3 или программно-аппаратными средствами на коммутаторах уровня L2 (лишь бы они понимали 802.1q) и каком-либо компьютере с linux-подобной операционной системой. Так как у меня уже был сервер (являющийся, к тому же, целевым для клиентов), то логично было бы остановиться на аппаратно-программном варианте.
Итак, программируем коммутатор таким образом, чтобы на каждом клиентском VLAN был один физический порт коммутатора в “access mode”, и один общий порт в режиме 802.1q (к этому порту будет подключаться наш сервер). Подробно технология настройки не расписывается, т.к. она достаточно тривиальна и зависит от конкретной модели используемого коммутатора.
Далее приступаем к созданию конфигурации для сервера. Пусть физический интерфейс, который подключается к порту 802.1q коммутатора, имеет имя eth0. Для моей конкретной задачи понадобилось 200 клиентских VLAN с VLAN ID от 600 до 799 включительно, так что будем их создавать:
Общая настройка видов имен VLAN-интерфейсов. Я хочу, чтобы имена VLAN-интерфейсов имели вид “vlanXXX”, где XXX — VLAN ID:
Непосредственно создаем VLAN на базе интерфейса eth0:
Создаем бридж, в который будем объединять созданные vlan:
Объединяем созданные интерфейсы в бридж:
Теперь прописываем на интерфейс br1 адрес, который будет выступать для всех наших клиентов в качестве шлюза по умолчанию:
И запрещаем трафик между клиентскими VLAN средствами ebtables:
(в данном случае используется таблица ebtables ‘filter’, запрещающая передачу трафика между интерфейсами, входящими в бридж в виде логических портов). Если все-таки необходимо разрешить возможность передачи трафика между клиентами под нашим контролем (см. п. 3 техзадания), то вместо вышеприведенного правила устанавливаем следующие:
Здесь мы работаем с таблицей ‘broute’. В ней не стандартные действия для целей ACCEPT и DROP. Цель ACCEPT разрешает форвардинг трафика с заданными условиями (т.е. трафик передается на уровне L2), а цель DROP запрещает форвардинг трафика и обеспечивает его передачу на роутинг (и, соответственно, мы сможем им управлять посредством iptables). Однако т.к. все адреса принадлежат одной IP-подсети но могут находиться в разных клиентских VLAN, на интерфейсе br1 необходимо будет разрешить arp proxy:
Замечу, что у меня не не стояло задачи пропуска трафика между клиентами, поэтому описанное выше расширение чисто умозрительное и на практике не проверялось!
Осталось только настроить сервер DHCP и поселить его на интерфейс br1. Эта операция также тривиальна, поэтому в рамках данной статьи не описывается.
Ну что, все работает? А вот как бы не так:
Здесь все нормально: получили один broadcast запрос DHCPDISCOVER, ответили одним broadcast-ответом DHCPOFFER.
А теперь давайте посмотрим, что происходит на физическом интерфейсе:
Что произошло? Да все, как мы сконфигурировали:
- DHCPDISCOVER был получен с VLAN 603;
- запрос был передан через интерфейс br1 нашему серверу DHCP;
- сервер в ответ на него передал на интерфейс br1 ответ DHCPOFFER;
- интерфейс br1 размножил этот ответ (т.к. он, по стандарту DHCP, является broadcast как по уровню L3, так и по уровню L2) по всем клиентским VLAN.
Мало того, что мы засветили всем клиентам MAC/IP адреса одного из них, так еще и вдобавок получили не хилый broadcast storm на физический коммутатор. Кстати, от такого шторма у некоторых коммутаторов просто едет крыша: работающий у нас QTECH не только не смог пропустить broadcast на все заявленные 200 клиентских VLAN (т.е. конечный клиент с произвольной вероятностью либо получал свой адрес от DHCP сервера, либо не дожидался от него вообще никакого ответа), но и даже забыл таблицу известных ему MAC-адресов (во всяком случае в консоли он показывал только один MAC-адрес для всех портов). А вот коммутатор ASOTEL справлялся с такой нагрузкой и клиенты могли получить адреса от нашего DHCP-сервера.
Ну ладно, будем исправлять ситуацию. Надо заставить сервер посылать broadcast только в тот VLAN, от которого пришел первоначальный запрос, а не размножать его по всем доступным местам.
Модуля трекинга DHCP broadcast-ов я не нашел. Как выяснилось позднее, он бы в данном случае все равно не помог, т.к. broadcast-ответ DHCP-сервером формируется при помощи системного вызова
socket(PF_PACKET, SOCK_DGRAM, htons(ETH_P_IP))
который не проходит ни через одну из таблиц ebtables или iptables. Т.е. если входящие broadcast отловить еще можно, то вот ответы передаются драйверу минуя стек протоколов. И это логично: если уж мы сами формируем ethernet-заголовок, то какой смысл дополнительно обрабатывать его средствами ядра?
Ладно, попробуем повесить на каждый клиентский VLAN по DHCP Relay Agent и уже запросы от него передавать на обработку DHCP серверу. Однако оказалось, что Relay Agent не отлавливает запросы от интерфейсов, входящих в бридж (ну это тоже, наверное, логично). Стоило убрать интерфейс из бриджа, как Relay Agent начинал вылавливать запросы, передавать их серверу и отсылать ответы обратно в тот VLAN, в который нужно. При повторном добавлении VLAN в бридж работоспособность агента опять нарушалась и DHCP становился недоступным для клиентов.
“Ну ладно!” — сказали суровые сибирские мужики. Будем делать все по-взрослому.
Для начала вспомним, что в современных linux-ядрах есть такие вкусности, как Virtual Ethernet Device (из них можно делать хорошие pipes для перегонки ethernet-трафика внутри нашего компьютера) и Network Namespace (средство для изоляции сетевого стека. В аппаратных маршрутизаторах это, обычно, называется VRF). В принципе для данной задачи можно обойтись исключительно Virtual Ethernet (veth), но для красоты решения (и упрощения связки DHCP Server — DHCP Relay Agent) будем использовать также и Network Namespace (netns).
После инициализации сети в linux по умолчанию имеется только один root netns, в котором находится единственная копия сетевого стека, таблицы маршрутизации, интерфейсы и т.п. В дальнейшем описании для определенности будем использовать следующую терминологию:
Network Namespace назовем “слоем” (layer);
root netns назовем слоем “backplate” (хотя в реальности этот netns имеет имя в виде пустой строки);
Идея у нас такая:
каждый клиентский VLAN добавляем в отдельный bridge, на интерфейс которого будем вешать DHCP Relay Agent. Через этот интерфейс клиенты смогут посылать broadcast-запросы агенту и принимать от него broadcast-ответы.
из каждого клиентского bridge сделаем ethernet pipe до нашего основного br1. Через связку “customer vlan”-”customer vlan bridge”-”virtual ethernet”-”br1” будет проходить полезный трафик между клиентским сервисом и общими внешними ресурсами.
Сам DHCP Relay Agent живет в одном экземпляре (он может слушать несколько клиентских интерфейсов) на специальном ethernet pipe, на другой стороне которого находится наш DHCP Server.
весь прикладной уровень (т.е. все, что не касается DHCP), расположим на уровне backplate;
все, что связано с DHCP Relay Agent, расположим на уровне с именем “relay”;
собственно сервер DHCP должен быть доступен как для DHCP Relay Agent (для обработки сообщений, распространяемых в виде broadcast и преобразуемых агентом в unicast и обратно), а также непосредственно для клиентов DHCP (для обработки специального случая: сообщения DHCPRELEASE, отправляемого unicast клиентом напрямую тому DHCP-серверу, который выдавал этот адрес).
С учетом данных требований сам DHCP-сервер расположим на уровне backplate на интерфейсе br1, но для предотвращения приема им broadcast-запросов от конечных клиентом на интерфейс будут наложены специальные фильтры.
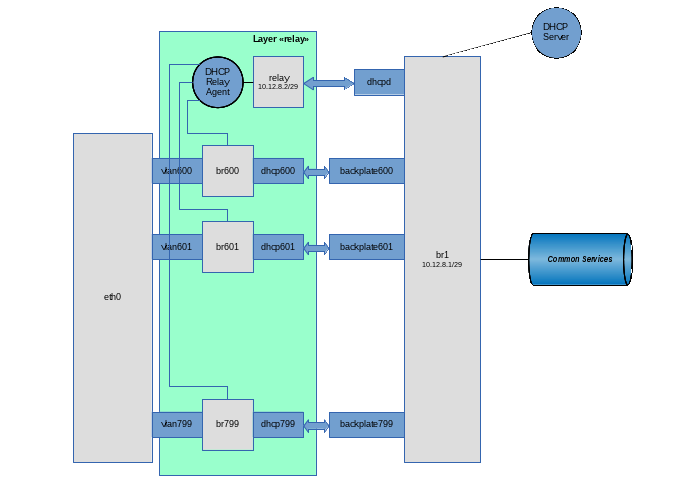
Ну, поехали… Создаем слой “relay”
Создаем на слое backplate виртуальный pipe, предназначенный для общения DHCP Relay Agent и DHCP Server:
Переносим хвост dhcpd (интерфейс, на котором будет работать Relay Agent) в слой relay:
Настраиваем в слое relay интерфейс dhcpd:
Создаем наш основной бридж br1:
Пусть этот бридж работает как умный коммутатор (т.е. хранит у себя таблицу MAC-адресов и выполняет форвардинг на конкретный порт в зависимости от наличия на нем целевого адреса). Для этого устанавливаем время обучения равным 30 секундам:
Ну и клиенты — личности своеобразные, вполне могут и кольца сотворить. Ежели кто этим и займется, то пусть страдает сам, не затрагивая при этом других. Т.е. запустим на нашем виртуальном коммутаторе STP:
Т.к. этот бридж является также шлюзом по умолчанию для клиентов, то повесим на него IP-адрес (вместе с сеткой) и поднимем непосредственно сам интерфейс:
Добавляем в бридж интерфейс, по которому DHCP сервер будет общаться с агентом:
Запрещаем трафик между клиентскими VLAN средствами ebtables:
Запрещаем обработку DHCP-сервером broadcast-запросов (они должны вылавливаться агентом и отсылаться серверу в виде unicast):
Для подстраховки разрешаем использование адреса, выделенного для DHCP Relay Agent только на интерфейсе с именем relay:
Ладно, последний мазок. Так как я категорически не доверяю клиентам, заставим ядро убеждаться в том, что приходящие от них IP-пакеты имеют source address вида 10.12.8.0/23 (а не, к примеру, 192.168.1.1). Для этого включаем на интерфейсе rp filter:
Физический интерфейс eth0 мы не будем переносить с backplate на слой relay (ну, допустим, нам надо будет повесить на него еще какие-то application VLANs, не имеющие отношения к данной схеме). Поэтому мы будем сначала создавать VLAN-интерфейсы на слое backplate, а потом переносить их в слой relay:
Общая настройка видов имен VLAN-интерфейсов. Я хочу, чтобы имена VLAN-интерфейсов имели вид “vlanXXX”, где XXX — VLAN ID:
Непосредственно создаем VLAN на базе интерфейса eth0:
Переносим созданный интерфейс vlan600 из слоя backplate в слой relay:
Поднимаем интерфейс vlan600, но уже в слое relay:
Создаем в слое relay бридж для данного клиентского VLAN (на который будем вешать DHCP Relay Agent).
Мы хотим, чтобы этот бридж работал в качестве хаба (т.е. выполнял бы трансляцию пакета сразу же после его получения, не используя период сбора информации о MAC-адресах). Для этого до момента добавления первого интерфейса в бридж устанавливаем его параметры:
Кроме того, STP на данном бридже нам явно не нужен:
Поднимаем интерфейс бриджа:
И добавляем в него клиентский VLAN:
Создаем на слое backplate (ну все равно он туда придет) ethernet pipe для связки клиентского бриджа br600 и нашего основного бриджа br1:
Переносим второй конец pipe в слой relay:
И добавляем этот конец трубы в бридж:
Ну и добавляем конец pipe, оставшийся в слое backplate, в бридж br1:
Повторяем в цикле операции создания клиентских VLAN в нужном количестве.
Теперь достаточно запустить сам DHCP сервер в слое backplate и DHCP Relay Agent в слое relay. В моем случае используется сборка из BusyBox, что в данном случае не критично. Использование ISC агента и сервера не должно вызвать больших затруднений.
Итак, запускаем агента. В качестве клиентских интерфейсов используются br600-br799, в качестве интерфейса для связи с DHCP-сервером используется интерфейс dhcpd, а сам DHCP сервер имеет адрес 10.12.8.1:
Ну и, наконец, запускаем DHCP сервер:
В файле /etc/udhcpd.conf единственная строчка, которая относится к данной схеме:
Все, теперь broadcast-запросы в пользовательском VLAN отлавливаются DHCP Relay Agent через соответствующий br-интерфейс, после чего запрос unicast-ом передается на серверу через интерфейс dhcpd. Сервер отсылает unicast-ответ через интерфейс relay, который агент получает из интерфейса dhcpd и транслирует broadcast-ом в исходный VLAN.
Клиенты стали получать адреса через DHCP, broadcast-storm исчез. И клиент может послать DHCPRELEASE непосредственно серверу на адрес 10.12.8.1
© Copiright 2015 by Vedga. Копирование текста на другие ресурсы без согласия автора запрещено.
Что посмотреть к этой статье:



