- Тонкая настройка сетевого стека Linux (размер буферов) для повышения производительности сети
- Как настроить эти значения
- Тюнинг сетевого стека Linux для ленивых
- Чего нужно добиться?
- Рекомендации по подбору железа
- «Господи, я не хочу в этом разбираться!»
- network-top
- rss-ladder
- autorps
- server-info
- Прочие утилиты
- Господи, я хочу в этом разбираться!
- Обычные кейсы
- Пример 1. Максимально простой.
- Пример 2. Чуть сложнее.
- Необычные кейсы
- Потери пакетов в Linux, сетевой стек, его тюнинг и мониторинг, netutils-linux
- Как работает сетевой стек
- Коротко
- Подробнее — путь пакета из кабеля в приложение:
- Выводы
- Как подбирать аппаратное обеспечение
- Мониторинг и тюнинг сетевого стека
- Мониторинг
- network-top
- Стандартный top
- server-info
- Тюнинг
- maximize-cpu-freq
- rss-ladder
- rx-buffers-increase
- autorps
- Настройка драйверов сетевых карт для работы в FORWARD/Bridge-режимах
- Примеры
- 1. Максимально простой
- Пример 2. Чуть сложнее
- Необычные примеры
- Блог Олега Стрижеченко
Тонкая настройка сетевого стека Linux (размер буферов) для повышения производительности сети
У меня два сервера, расположенных в двух разных центрах обработки данных. Оба сервера имеют дело с множеством одновременных передач больших файлов. Но производительность сети очень низкая для больших файлов, и снижение производительности происходит с большими файлами. Как мне настроить TCP под Linux, чтобы решить эту проблему?
По умолчанию сетевой стек Linux не настроен для высокоскоростной передачи больших файлов по каналам WAN. Это сделано для экономии ресурсов памяти. Вы можете легко настроить сетевой стек Linux, увеличив размер сетевых буферов для высокоскоростных сетей, которые соединяют серверные системы для обработки большего количества сетевых пакетов.
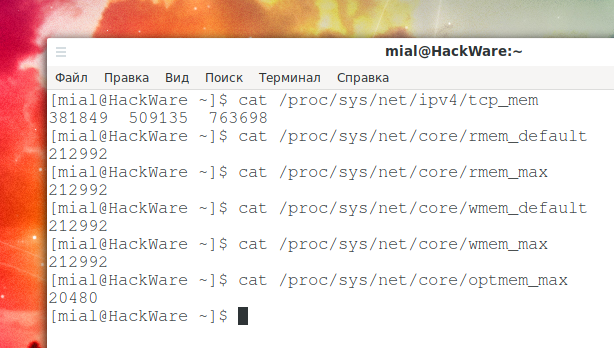
Максимальный размер буфера TCP в Linux по умолчанию слишком мал. Память TCP рассчитывается автоматически на основе системной памяти; вы можете найти фактические значения, введя следующие команды:
Объём для принимающей памяти сокета по умолчанию и максимальный:
По умолчанию и максимальный объём памяти для сокета отправки:
Максимальный объём опциональных буферов памяти:
Как настроить эти значения
Внимание: значение по умолчанию для rmem_max и wmem_max составляет около 208 КБ в большинстве дистрибутивов Linux, что может быть достаточно для сетевой среды общего назначения с низкой задержкой или для таких приложений, как DNS/веб-сервер. Однако, если задержка велика, размер по умолчанию может быть слишком маленьким. Обратите внимание, что следующие настройки увеличивают использование памяти на вашем сервере.
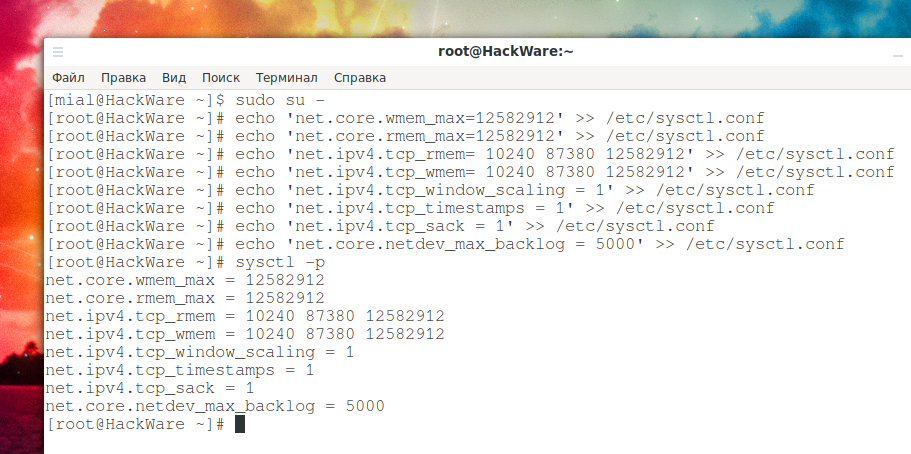
Установите максимальный размер буфера отправки (wmem) ОС и размер буфера приёма (rmem) равным 12 МБ для очередей по всем протоколам. Другими словами, установите объём памяти, который выделяется для каждого сокета TCP, когда он открывается или создаётся при передаче файлов:
Вам также необходимо установить минимальный размер, начальный размер и максимальный размер в байтах:
Включите масштабирование окна, которое может быть опцией увеличения окна передачи:
Включите отметки времени, как определено в RFC1323:
Включить выбор подтверждений:
По умолчанию TCP сохраняет различные метрики соединения в кэше маршрута при закрытии соединения, так что соединения, установленные в ближайшем будущем, могут использовать их для установки начальных условий. Обычно это увеличивает общую производительность, но иногда может вызывать снижение производительности. Если установлено, TCP не будет кэшировать метрики при закрытии соединений.
Установите максимальное количество пакетов, помещаемых в очередь на стороне INPUT, когда интерфейс получает пакеты быстрее, чем ядро может их обработать.
Теперь перезагрузите изменения:
Используйте tcpdump для просмотра изменений для eth0:
Источник
Тюнинг сетевого стека Linux для ленивых
Сетевой стек Linux по умолчанию замечательно работает на десктопах. На серверах с нагрузкой чуть выше средней уже приходится разбираться как всё нужно правильно настраивать. На моей текущей работе этим приходится заниматься едва ли не в промышленных масштабах, так что без автоматизации никуда – объяснять каждому коллеге что и как устроено долго, а заставлять людей читать ≈300 страниц английского текста, перемешанного с кодом на C… Можно и нужно, но результаты будут не через час и не через день. Поэтому я попробовал накидать набор утилит для тюнинга сетевого стека и руководство по их использованию, не уходящее в специфические детали определённых задач, которое при этом остаётся достаточно компактным для того, чтобы его можно было прочитать меньше чем за час и вынести из него хоть какую-то пользу.
Чего нужно добиться?
Главная задача при тюнинге сетевого стека (не важно, какую роль выполняет сервер — роутер, анализатор трафика, веб-сервер, принимающий большие объёмы трафика) – равномерно распределить нагрузку по обработке пакетов между ядрами процессора. Желательно с учётом принадлежности CPU и сетевой карты к одной NUMA-ноде, а также не создавая при этом лишних перекидываний пакета между ядрами.
Перед главной задачей, выполняется первостепенная задача — подбор аппаратной части, само собой с учётом того, какие задачи лежат на сервере, откуда и сколько приходит и уходит трафика и т.д.
Рекомендации по подбору железа
Таким образом, если дано 2+ источника объёма трафика больше 2 Гбит/сек, то стоит задуматься о сервере с числом процессоров и NUMA-нод, а также числу сетевых карт (не портов), равных числу этих источников.
«Господи, я не хочу в этом разбираться!»
И не нужно. Я уже разобрался и, чтобы не тратить время на то, чтобы объяснять это коллегам, написал набор утилит — netutils-linux. Написаны на Python, проверены на версиях 2.6, 2.7, 3.4, 3.6.
network-top

Эта утилита нужна для оценки применённых настроек и отображает равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора) на ресурсы сервера, всевозможные ошибки обработки пакетов. Значения, превышающие пороговые подсвечиваются.
rss-ladder
Эта утилита распределяет прерывания сетевой карты на ядра выбранного физического процессора (по умолчанию на нулевой).
autorps
Эта утилита позволяет настроить распределение обработки пакетов между ядрами выбранного физического процессора (по умолчанию на нулевой). Если вы используете RSS, скорее всего вам эта утилита не потребуется. Типичный сценарий использования — многоядерный процессор и сетевые карты с одной очередью.
server-info
Данная утилита позволяет сделать две вещи:
- server-info show : посмотреть, что за железо вообще установлено на сервере. В целом похоже на велосипед, повторяющий lshw , но с акцентом на интересующие нас параметры.
- server-info rate : найти узкие места в аппаратном обеспечении сервера. В целом похоже на индекс производительности Windows, но опять же с акцентом на интересующие нас параметры. Оценка производится по шкале от 1 до 10.
Прочие утилиты
Господи, я хочу в этом разбираться!
Прочитайте статьи про:
Эти статьи вдохновили меня на написание этих утилит .
Также хорошую статью написали в блоге одноклассников 2 года назад.
Обычные кейсы
Но руководство по запуску утилит само по себе мало что говорит о том, как именно их нужно применять в зависимости от ситуации. Приведём несколько примеров.
Пример 1. Максимально простой.
- один процессор с 4 ядрами
- одна 1 Гбит/сек сетевая карта (eth0) с 4 combined очередями
- входящий объём трафика 600 Мбит/сек, исходящего нет.
- все очереди висят на CPU0, суммарно на нём ≈55000 прерываний и 350000 пакетов в секунду, из них около 200 пакетов/сек теряются сетевой картой. Остальные 3 ядра простаивают
- распределяем очереди между ядрами командой rss-ladder eth0
- увеличиваем ей буфер командой rx-buffers-increase eth0
Пример 2. Чуть сложнее.
- два процессора с 8 ядрами
- две NUMA-ноды
- Две двухпортовые 10 Гбит/сек сетевые карты (eth0, eth1, eth2, eth3), у каждого порта 16 очередей, все привязаны к node0, входящий объём трафика: 3 Гбит/сек на каждую
- 1 х 1 Гбит/сек сетевая карта, 4 очереди, привязана к node0, исходящий объём трафика: 100 Мбит/сек.
1 Переткнуть одну из 10 Гбит/сек сетевых карт в другой PCI-слот, привязанный к NUMA node1.
2 Уменьшить число combined очередей для 10гбитных портов до числа ядер одного физического процессора:
3 Распределить прерывания портов eth0, eth1 на ядра процессора, попадающие в NUMA node0, а портов eth2, eth3 на ядра процессора, попадающие в NUMA node1:
4 Увеличить eth0, eth1, eth2, eth3 RX-буферы:
Необычные кейсы
Не всегда всё идёт идеально:
- Встречались сетевые карты, теряющие пакеты (missed) в случае использования RSS на несколько ядер в одной NUMA-ноде. Решение странное, но рабочее — 6 RX-очередей привязаны к CPU0, в rps_cpus каждой очереди записана маска процессоров 111110, потери пропали.
- Встречались сетевые карты mellanox и intel (X710) продолжающие работать при прекратившемся росте счётчиков прерываний. Трафик в tcpdump имелся, нагрузка, создаваемая сетевыми картами висела на CPU0. Нормальная работа восстановилась после включения и выключения RPS. Почему — неизвестно.
- Некоторые SFP-модули для Intel 82599ES при обновлении драйвера (сборка ixgbe из исходников с sourceforge) «пропадают» из списка сетевых карт. При этом в lspci этот порт отображается, второй аналогичный порт работает, а в dmesg на оба порта одинаковые warning’и. Помогает флаг unsupported_sfp=1,1 при загрузке модуля ixgbe. По хорошему, однако, стоит купить supported sfp.
- Некоторые драйверы сетевых карт подстраивают число очередей только под равные степени двойки значения (что обидно на 6-ядерных процессорах).
Update: после публикации автор осознал, что люди используют не только RHEL-based дистрибутивы для сетевых задач, а тесты в debian на наборах данных, собранных в RHEL-based системах, не отлавливают кучу багов. Большое спасибо всем сообщившим о том, что что-то не работает в Ubuntu/Debian/Altlinux! Все баги исправлены в релизе 2.0.10
Update2. в комментариях упомянули то, что RPS всё же часто бывает полезен людям и я его недооцениваю. В принципе это так, поэтому в релизе 2.2.0 появилась значительно улучшенная версия утилиты autorps.
Источник
Потери пакетов в Linux, сетевой стек, его тюнинг и мониторинг, netutils-linux
Сетевой стек Linux по умолчанию замечательно работает на десктопах, но на серверах с нагрузкой чуть выше средней и настройками по умолчанию — уже не очень, в основном из-за неравномерного распределения нагрузки на процессор.
Как работает сетевой стек
Коротко
- Материнские платы могут поддерживать одновременную работу нескольких процессоров, у которых может быть несколько ядер, у которых может быть несколько потоков.
- Оперативная память, NUMA. При использовании нескольких процессоров, как правило, у каждого процессора есть “своя” и “чужая” память. Обе они доступны, но доступ в чужую — медленнее. Бывают архитектуры, в которых память не делится между процессорами на свою и чужую. Сочетание ядер процессора и памяти называется NUMA-нодой. Иногда сетевые карты тоже принадлежат к NUMA-ноде.
- Сетевые карты можно поделить по поддержке RSS (аппаратное масштабирование захвата пакетов). Серверные поддерживают, бюджетные и десктопные нет. Зачастую, несмотря на диапазон, указанный в smp_affinity_list у обработчика прерываний, прерывания обрабатываются только одним ядром (как правило CPU0). Все сетевые карты работают следующим образом:
- IRQ (top-half): сетевая карта пишет пакеты в свою внутреннюю память. В оперативной памяти той же NUMA-ноды, к которой привязана сетевая карта, под неё выделен кольцевой буфер. По прерыванию процессора сетевая карта копирует свою память в кольцевой буфер и делает пометку, что у неё есть пакеты, которые надо обработать. Кольцевых буферов может быть несколько и они могут обрабатываться параллельно.
- Softirq (bottom half): сетевой стек периодически проверяет пометки от сетевых карт о необходимости обработать пакеты. Пакеты из кольцевых буферов обрабатываются, проходят, файрволы, наты, сессии, доходят до приложения при необходимости. На этом уровне есть программный аналог аппаратных очередей, который уместен в случае с сетевыми картами с одной очередью.
- Cache locality. Если пакет обрабатывался на определённом CPU и попал в приложение, которое работает там же — это лучший случай, кэши работают максимально эффективно.
Подробнее — путь пакета из кабеля в приложение:
Сразу оговорю неточности: не прописано прохождение L2, который ethernet. С L1 как-то сразу в L3 прыгнул.
- Сетевая карта принимает сигнал.
- Сетевая карта через DMA копирует свою память с пакетом в оперативную память.
- IRQ
- После чего выполняет прерывание (IRQ, то, что видно в /proc/interrupts), которое оповестит ядро о том что пакет пришёл.
- Вызывается функция (IRQ handler), которую зарегистрировал драйвер сетевой карты при иниициализации.
- В контексте обработчика прерывания IRQ выполняется пометка того, что пакеты пора обрабатывать.
- NAPI
- napi_schedule() добавляет NAPI poll structure в poll_list для текущего ядра и выставляет бит “ПОРА ВЫПОЛНИТЬ SOFTIRQ”! Текущий CPU — CPU, на котором обработалась очередь в которую пришёл пакет.
- ksoftirqd работающий на данном CPU видит выставленный бит.
- Выполняется функция run_ksoftirqd() , запущенная в бесконечном цикле.
- __do_softirq() вызывает функцию, прибитую к NET_RX прерыванию, то есть net_rx_action() . Исполняет её уже не драйвер, а тред ksoftirqd в ядре.
- SoftIRQ
- Контекст softirq — это то, что отображается как %si в выводе top , счётчики лежат в /proc/softirqs .
- net_rx_action в цикле проверяет NAPI poll_list на наличие NAPI структур.
- Проверяется, что budget и elapsed time не израсходованы и softirq не монополизировало ресурсы CPU.
- Вызывается poll-функция зарегистрированная драйвером при инициализации, для igb это igb_poll() . Её задача — извлекать пакеты из кольцевых буферов в оперативной памяти ( ethtool -g eth1 ) и передавать их дальше.
- GRO — Generic Receive Offloading, функция, которая помогает при приёме трафика, но бесполезная и небезопасная при маршрутизации.
- Если включено — выполняется napi_gro_receive() . При включении пакеты складываются в GRO list.
- Если отключено — пакеты попадают непосредственно в net_receive_skb()
- net_receive_skb() — место, где вызывается или не вызывается RPS, в зависимости от того, включен он или нет. Если включен:
- Пакет кладётся в бэклог с помощью enqueue_to_backlog() . Предположительно его размер регулируется в /proc/sys/net/core/netdev_max_backlog . Его можно рассматривать как дополнительный промежуточный RX-буфер, который существует для каждого ядра, даже если очередь у драйвера всего одна.
- Пакеты распределяются между доступными CPU (указанными в rps_cpus) для дальнейшей обработки.
- NAPI-структура добавляется в poll_list CPU, на который назначился пакет. В очередь ставится IPI (Inter-processor Interrupt), который вызовет ещё один SoftIRQ.
- В процессе работы ksoftirqd на назначенном CPU происходит то же что и выше, но poll-функция меняяется с igb_poll() , на process_backlog() . Последняя разгребает входящую очередь данного CPU.
- Пакет попадает в __net_receive_skb_core (или __netif_receive_core() или __netif_receive_skb_core() ), во время дальнейшей обработки пакет уже не будет покидать ядро, которое его обрабатывает.
- __net_receive_skb_core() имеет дело с структурой skbuff . Задача этой функции — доставлять пакеты к taps (PCAP является одним из них).
- Пакет закончил прохождение по L2.
- Пакет попадает выше по стеку на L3, для IPv4 это будет ip_rcv() .
- Дальше происходят netfilter, iptables и роутинг и всё такое.
- Пакет попадает выше по стеку на L4, в свой UDP/TCP-стек, например в udp_rcv()
- udp_rcv() кладёт пакет в очередь на отправку в сокет пользовательского пространства с помощью функции udp_queue_rcv_skb() .
- Перед тем как пакет попадёт в очередь к нему применяются BPF (Berkley Packet Filters), которые могут его отбросить.
Выводы
Перед главной задачей, выполняется первостепенная задача — подбор аппаратной части, само собой с учётом того, какие задачи лежат на сервере, откуда и сколько приходит и уходит трафика и т.д.
Есть два способа распределить нагрузку по обработке пакетов между ядрами процессора:
- RSS — назначить smp_affinity для каждой очереди сетевой карты.
- RPS (можно считать его программным аналогом RSS) — назначить rps_cpus для каждой очереди сетевой карты.
- Комбинирование RSS и RPS. Дополнительный буфер с одной стороны — снижает вероятность потери пакета при пиковой нагрузке, с другой стороны — увеличивает общее времени обработки и может за счёт этого увеличивать вероятность потерь. Для сетевых карт с несколькими очередями и равномерным распределением пакетов перенос пакета с ядра на ядро будет использовать драгоценный budget и снизит эффективность использования кэша процессора.
Как подбирать аппаратное обеспечение
- Процессоры
- Число процессоров:
- Однопроцессорный сервер эффективен, если трафик приходит только на одну сетевую карту, в том числе в её порты, если их несколько.
- Двухпроцессорный сервер эффективен, если есть больше двух источников трафика, с потоком более 2 Гбит/сек и они обрабатываются отдельными сетевыми картами (не портами).
- Число ядер:
- Не нужно больше ядер, чем максимальное суммарное количество очередей всех сетевых карт.
- Hyper-Threading: не помогает, если обработка пакетов — основной вид нагрузки на процессор. Оценивайте процессор по числу ядер, а не потоков.
- Число очередей сетевой карты: карты с одной очередью позволяют распределить нагрузку на обработку пакетов, но не на захват пакетов.
- Частота процессора: чем больше, тем лучше. Лучше начинать от 2.5GHz, 3.5GHz — уже неплохо.
- Объём кэша: чем больше, тем лучше. Отсутствие L3-кэша — показатель того что процессор старый и не поддерживает современные оптимизации.
- Число процессоров:
- Оперативная память: используйте DDR4-память с частотой равной максимальной поддерживаемой и процессором и материнской платой.
- Сетевые карты:
- Размер RX-буферов: чем он больше, тем лучше.
- Максимальное число очередей: чем их больше, тем лучше. Некоторые (mellanox) сетевые карты поддерживают только число очередей равное степени двойки. Если у Вас 6-ядерный процессор — имеет смысл подобрать другую сетевую карту.
- Бракованные сетевые карты — вероятность мала, но иногда случается. Заменяем одну сетевую карту на точно такую же и всё замечательно.
- Драйвер: не рекомендую использовать десктопные карты (обычно D-Link, Realtek).
Мониторинг и тюнинг сетевого стека
Мониторинг можно условно поделить на
- краткосрочный — посмотреть как чувствует себя система прямо сейчас;
- долгосрочный — с алертами, вот это всё.
Заниматься тюнингом без краткосрочного мониторинга равноценно случайным действиям. Я разработал инструменты для такого мониторинга — netutils-linux, они протестированы и работают на версиях python 2.6, 2.7, 3.4, 3.6, 3.7 и, возможно на более новых. Изначально делал для технической поддержки, объяснять каждому такой объёмный материал — долго, сложно. Есть фраза “код — лучшая документация”, а моей целью было “инструменты вместо документации”.
При возникновении проблем — сообщайте о них на github, а лучше присылайте pull-request’ы.
Мониторинг
network-top
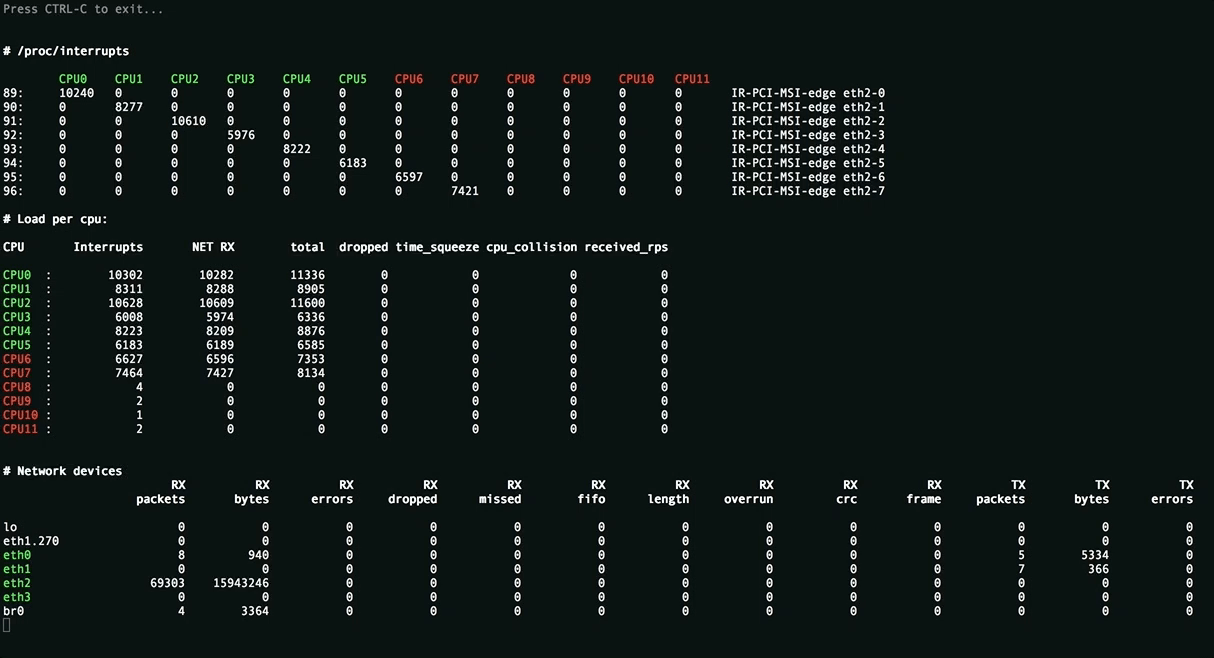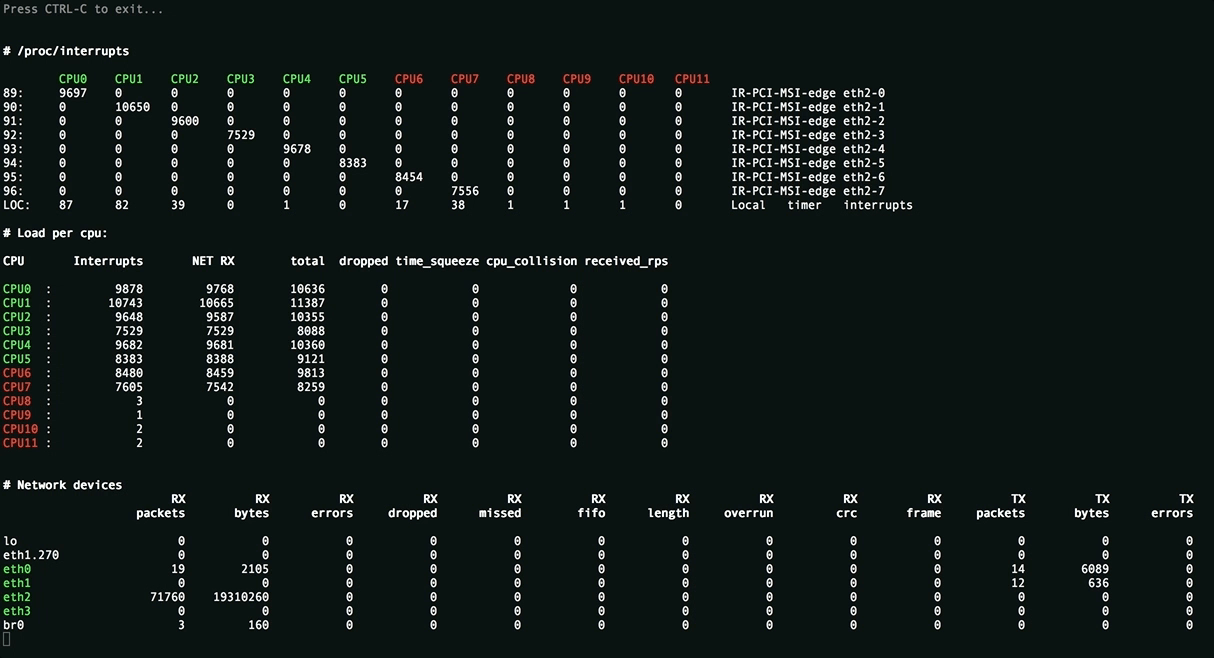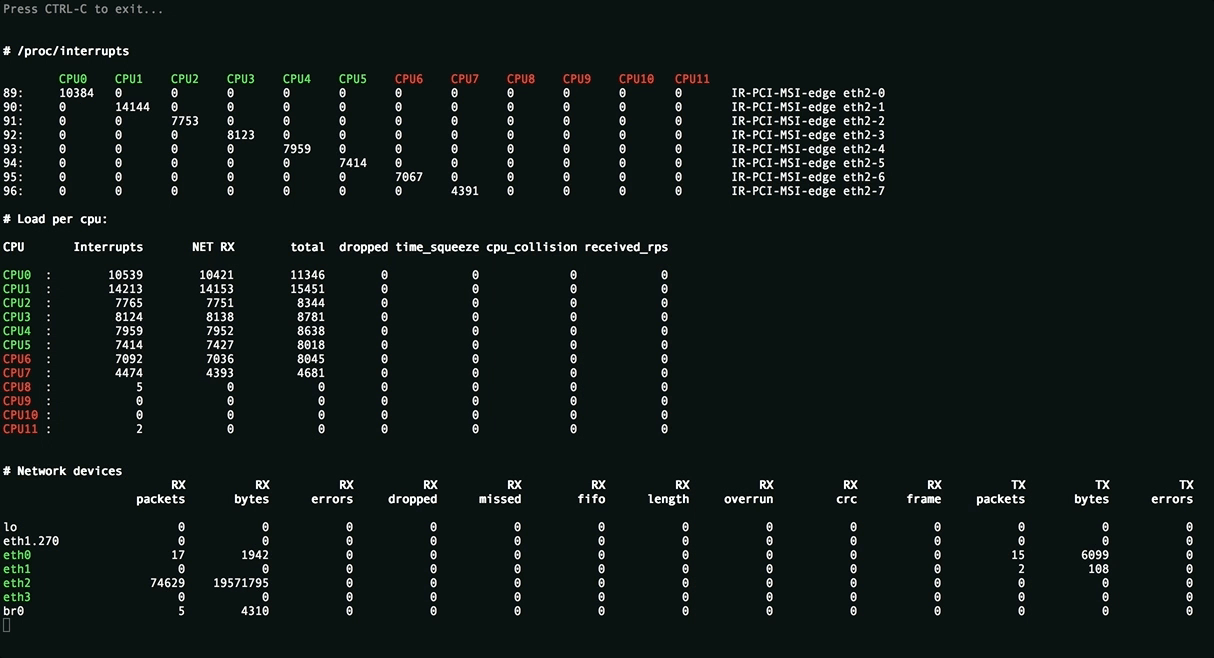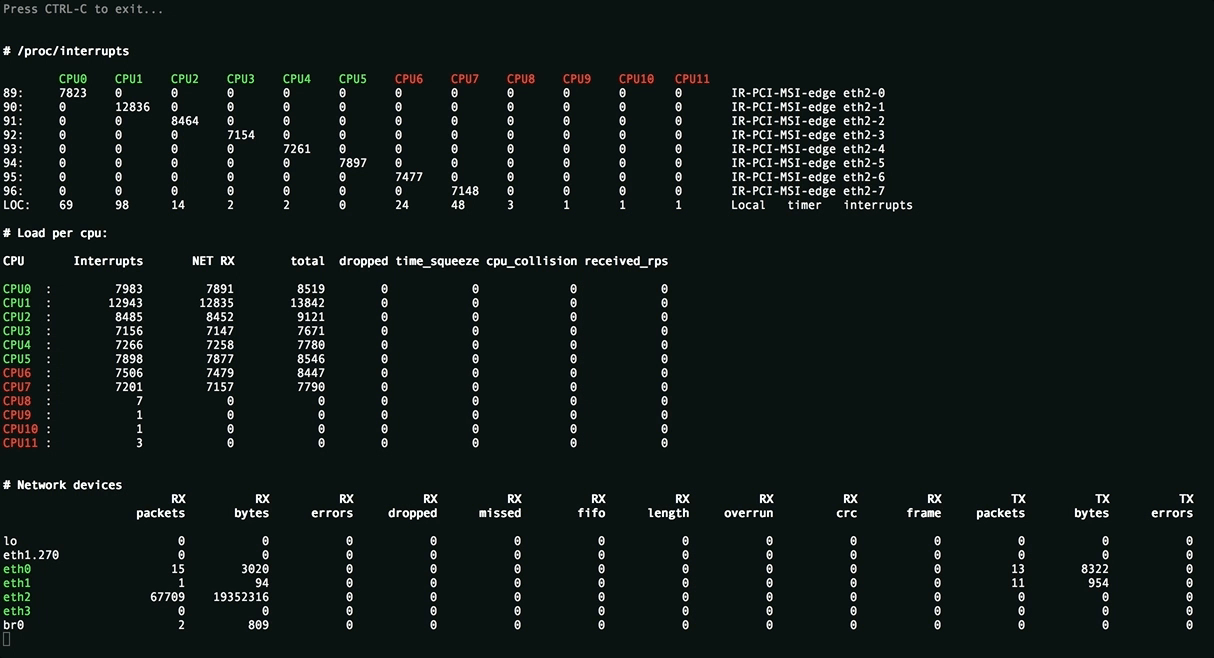
Эта утилита отображает полную картину процесса обработки пакетов. Вы увидите равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора и на сетевой интерфейс) на ресурсы сервера, ошибки обработки пакетов. Аномальные значения счётчиков подсвечиваются красным.
Вверху отображаются источники прерываний, чтобы всё влезало на экран редкие прерывания скрыты. Имена ядер подсвечиваются в зависимости от принадлежности к NUMA-ноде или к процессору.
Посередине находится самое важное — распределение обработки пакетов по CPU:
- Interrupts. Суммарное число прерываний на ядро. Лучше держаться не более 10000 прерываний на 1GHz частоты ядра. В случае с hyperthreading — 5000. Настраивается утилитой rss-ladder .
- NET_RX. Число softirq на приём пакетов. Настраивается утилитой autorps .
- NET_TX. Число softirq на отправку пакетов. Настраивается утилитой autoxps .
- Total. Число обработанных данным ядром пакетов.
- Dropped. Число отброшенных в процессе обработки пакетов. Отбрасывание приводит медленной работе сети, хосты повторно отправляют пакеты, у них задержки, потери, люди жалуются в техподдержку.
- Time squuezed. Число пакетов, которым не хватило времени для обработки и их обработку отложили на следующий виток цикла. Повод задуматься о дополнительном тюнинге.
- CPU Collision. times that two cpus collided trying to get the device queue lock. Ни разу не видел на своей практике.
Внизу находится статистика по сетевым девайсам.
- rx-errors — общее число ошибок, обычно суммирует остальные. В какой именно счётчик попадает пакет зависит от драйвера сетевой карты.
- dropped , fifo , overrun — пакеты, не успевшие обработаться сетевым стеком
- missed — пакеты, не успевшие попасть в сетевой стек
- crc — прилетают битые пакеты. Часто бывает следствием высокой нагрузки на коммутатор.
- length — слишком большие пакеты, которые не влезают в MTU на сетевой карте. Лечится его увеличением: ip link set eth1 mtu 1540 . Постоянное решение для RHEL-based систем — прописать строчку MTU=1540 в файле конфигурации сетевой карты, например /etc/sysconfig/network-scripts/ifcfg-eth1 .
Флаги утилиты
- Задать список интересующих девайсов: —devices=eth1,eth2,eth3
- Отсеять девайсы регуляркой: —device-regex=’^eth’
- Сделать вывод менее подробным, спрятав все специфичные ошибки: —simple
- Убрать данные об отправке пакетов: —rx-only .
- Представление данных об объёме трафика можно менять ключами: —bits , —bytes , —kbits , —mbits .
- Показывать абсолютные значения: —no-delta-mode
Альтернативные способы получения этой информации:
Потери могут быть не только на Linux-сервере, но и на порту связанного с ним сетевого оборудования. О том, как это посмотреть можно узнать из документации производителя сетевого оборудования.
Стандартный top
server-info
Если приходится иметь дело с разношёрстными серверами, которые закупались разными людьми, полезно знать какое оборудование у них внутри и насколько оно подходит под текущие нагрузки. Утилита server-info именно для этого и предназначена. У неё два режима:
- —show — показать оборудование;
- —rate — оценить оборудование.
Вывод в YAML. Примеры:
и оценивать это железо по шкале от 1 до 10:
Вместо —server можно указать —subsystem , —device или вообще ничего, тогда оценка будет вестись по каждому параметру устройства в отдельности.
Тюнинг
maximize-cpu-freq
Плавающая частота процессора плохо сказывается для нагруженных сетевых серверов. Если процессор может работать на 3.5GHz — не надо экономить немного ватт ценой потерь пакетов. Утилита включает для cpu_freq_governour режим performance и устанавливает минимальную частоту всех ядер в значение максимально-доступной базовой. Узнать текущие значения можно командой:
Помимо плавающей частоты есть ещё одно но, которое может приводить к потерям: режим энергосбережения в UEFI/BIOS. Лучше его выключить, выбрав режим “производительность” (для этого потребуется перезагрузить сервер).
rss-ladder
Утилита автоматически распределяет прерывания “лесенкой” на ядрах локального процессора для сетевых карт с поддержкой нескольких очередей.
Если сетевых карт несколько, лучше выделить для каждой очереди каждой сетевой карты одно физическое ядро, ответственное только за неё. Если ядер не хватает — число очередей можно уменьшить с помощью ethtool, например: ethtool -L eth0 combined 2 или ethtool -L eth0 rx 2 в зависимости от типа очередей.
Для RSS по возможности используйте разные реальные ядра, допустим, дано:
- 1 процессор с гипертредингом
- 4 реальных ядра
- 8 виртуальных ядер
- 4 очереди сетевой карты, которые составляют 95% работы сервера
В зависимости от того как расположены ядра и потоки (узнать можно по выводу lscpu -e ), использовать 0, 2, 4 и 6 ядра будет эффективнее, чем 0, 1, 2 и 3.
rx-buffers-increase
Увеличивает RX-буфер сетевой карты. Чем больше буфер — тем больше пакетов за один тик сетевая карта сможет скопировать с помощью DMA в кольцевой буфер в RAM который уже будет обрабатываться процессором.
Для работы после перезагрузки в RHEL-based дистрибутивах (платформа Carbon, CentOS, Fedora итд) укажите в настройках интерфейса, например /etc/sysconfig/network-scripts/ifcfg-eth1 , строчку вида:
autorps
Утилита для распределения нагрузки на сетевых картах с одной очередью. Вычисляет и применяет маску процессоров для RPS, например:
Настройка драйверов сетевых карт для работы в FORWARD/Bridge-режимах
Опции General Receive Offload и Large Receive Offload в таких режимах могут приводить к паникам ядра Linux и их лучше отключать либо при компиляции драйвера, либо на ходу, если это поддерживается драйвером:
Примеры
1. Максимально простой
| Параметр | Значение |
|---|---|
| Число процессоров | 1 |
| Ядер | 4 |
| Число карт | 1 |
| Число очередей | 4 |
| Тип очередей | combined |
| Режим сетевой карты | 1 Гбит/сек |
| Объём входящего трафика | 600 Мбит/сек |
| Объём входящего трафика | 350000 пакетов/сек |
| Максимум прерываний на ядро в секунду | 55000 |
| Объём исходящего трафика | 0 Мбит/сек |
| Потери | 200 пакетов/сек |
| Детали | Все очереди висят на CPU0, остальные ядра простаивают |
Решение: распределяем очереди между ядрами и увеличиваем буфер:
| Параметр | Значение |
|---|---|
| Максимум прерываний на ядро в секунду | 15000 |
| Потери | 0 |
| Детали | Нагрузка равномерна |
Пример 2. Чуть сложнее
| Параметр | Значение |
|---|---|
| Число процессоров | 2 |
| Ядер у процессора | 8 |
| Число карт | 2 |
| Число портов у карт | 2 |
| Число очередей | 16 |
| Тип очередей | combined |
| Режим сетевых карт | 10 Гбит/сек |
| Объём входящего трафика | 3 Гбит/сек |
| Объём исходящего трафика | 100 Мбит/сек |
| Детали | Все 4 порта привязаны к одному процессору |
Одну из 10 Гбит/сек сетевых карт перемещаем в другой PCI-слот, привязанный к NUMA node1.
Уменьшаем число combined очередей на каждый порт до числа ядер одного физического процессора (временно, нужно делать это при перезагрузке) и распределить прерывания портов. Ядра будут выбраны автоматически, в зависимости от того к какой NUMA-ноде принадлежит сетевая карта. Увеличиваем сетевым картам RX-буферы:
Необычные примеры
Не всегда всё идёт идеально:
| Проблема | Решение |
|---|---|
| Сетевая карта теряет пакеты при использовании RSS. | 1 RX-очередь для захвата на CPU0, а обработка на остальных ядрах: autorps —cpus 1,2,3,4,5 eth0 |
| У сетевой карты несколько очередей, но 99% пакетов обрабатывается одной очередью | Причина в том, что у 99% трафика одинаковый хэш, такое бывает при использовании QinQ, Vlan, PPPoE и во время DDoS атак. Решений несколько: от DDoS защититься ранним DROP трафика, перенести агрегацию VLAN на другое оборудование, сменить сетевую карту, которая учитывает Vlan при вычислении хэша для RSS, попробовать использовать RPS |
| Сетевые карты intel X710 начала работать без прерываний, вся нагрузка висела на CPU0. | Нормальная работа восстановилась после включения и выключения RPS. Почему началось и закончилось — неизвестно. |
| Некоторые SFP-модули для Intel 82599ES при обновлении драйвера (сборка ixgbe из исходников с sourceforge) “пропадают” из списка сетевых карт и даже флаг unsupported_sfp=1 не помогает. При этом в lspci этот порт отображается, второй аналогичный порт работает, а в dmesg на оба порта одинаковые warning’и. | Не нашлось. |
| Некоторые драйверы сетевых карт работают с числом очередей только равным степени двойки | Замена сетевой карты или процессора. |
Блог Олега Стрижеченко
30% личного, 20% linux, 30% наблюдения за разработкой, 5% книги, 10% математика и статистика, 10% шуток
Источник



