- Настраиваем NAT в Linux
- Быстрый роутинг и NAT в Linux
- Немного истории
- IPTables
- NFTables
- Конфигурация
- Результаты
- Настройка интернет-шлюза с NAT и Port Forwarding на CentOS 7
- Схема локальной сети со шлюзом доступа в Интернет, типы NAT
- Настройка Source NAT: доступ из локальной сети в Интернет
- Настройка Destination NAT и port forwarding: доступ из Интернета в локальную сеть
- Анализ логов сетевых подключений NAT в Linux
Настраиваем NAT в Linux
 В интернете куча статей, которые рассказывают, как же настроить страшные iptables, что бы раздать интернет по средствам NAT с одного компьютера на другой. У меня появилась такая потребность, в тот момент, когда на основном ПК стояла kubuntu 10.10, на втором WinXP. А по большому счету, все равно какая вторая ОС. Первый раз, написав эту статью, меня посетило чувство неудовлетворенности. Настроил NAT, но DNS и IP на машинах клиентах пришлось писать вручную. А это не по «одмински»! И вот я переписал статью. И так! Нам понадобятся небольшие знания работы с консолью, базовые понятия, что такое iptables. Все еще интересно? Прошу под спойлер…
В интернете куча статей, которые рассказывают, как же настроить страшные iptables, что бы раздать интернет по средствам NAT с одного компьютера на другой. У меня появилась такая потребность, в тот момент, когда на основном ПК стояла kubuntu 10.10, на втором WinXP. А по большому счету, все равно какая вторая ОС. Первый раз, написав эту статью, меня посетило чувство неудовлетворенности. Настроил NAT, но DNS и IP на машинах клиентах пришлось писать вручную. А это не по «одмински»! И вот я переписал статью. И так! Нам понадобятся небольшие знания работы с консолью, базовые понятия, что такое iptables. Все еще интересно? Прошу под спойлер…
Находим там интерфейс смотрящий в локальную сеть(eth0), и настраиваем его на необходимый IP. Я взял 11.1.1.1,получилось вот так:
Я подразумеваю, что интернет у вас уже работает, а значит, интерфейс eth1 уже настроен. Можем теперь поставить на машине-клиенте IP 11.1.1.2, маску 255.0.0.0 и перезапустить сетевые интерфейсы на сервере командой:
Теперь, настроим правила для iptables:
Потом открываем для редактирования файл /etc/sysctl.conf. Добавляем следующие строчки:
Вуаля. Шлюз готов к работе! Проведем тест работы NAT. Перезапускаем сетевые интерфейсы командой:
После этого на той машине, где мы ставили IP и сеть работала, поставим в настройках сетевой карты DNS адреса серверов. Можно провайдера, можно например OpenDNS: 207.68.222.222 и 207.68.220.220. После пытаемся зайти на любой сайт, и желательно не на один. Если все работает — считай пол работы сделано. У iptables есть, на мой взгляд, полезная вещь — после перезапуска системы — правила обнуляются. Что бы этого не произошло, нужно сохранить их:
Осталось дописать команду скрипт загрузки сетевых интерфейсов, которая будет подгружать наши настройки iptables. Выглядит она вот так:
Собственно на этом я прошлый раз и остановился. Но ведь наш сервер — далеко не полноценный роутер. Нужно вручную вписывать IP-шники и DNS. А вдруг DNS поменяется, прийдеть снова настраивать? Поэтому я решил продолжить.
4. Поднимим DNS и DHCP сервер. Есть простой и удобный вариант. Называется пакет dnsmasq. Работает демоном. Устанавливаем:
Теперь нужно отредактировать конфиг. Я предпочитаю бекапить стандартный, и потом создавать новый с нуля. Бекапим конфиг:
Теперь создаем новый конфиг, открывая его для редактирования:
Нам нужно будет вписать все 2 строчки, все остальное сервер сделает сам. Первая строка разрешает серверу принимать DNS запросы из локальной сети, а вторая описывает диапазон выдаваемых адресов, сетевую маску и время жизни IP адреса соотвественно:
А вот теперь осталось только перезапустить «сеть» и сам демон:
Источник
Быстрый роутинг и NAT в Linux
Немного истории
Тема исчерпания адресного пространства IPv4 уже не нова. В какой-то момент в RIPE появились очереди ожидания (waiting list), затем возникли биржи, на которых торговали блоками адресов и заключались сделки по их аренде. Постепенно операторы связи начали предоставлять услуги доступа в Интернет с помощью трансляции адресов и портов. Кто-то не успел получить достаточно адресов, чтобы выдать «белый» адрес каждому абоненту, а кто-то начал экономить средства, отказавшись от покупки адресов на вторичном рынке. Производители сетевого оборудования поддержали эту идею, т.к. этот функционал обычно требует дополнительных модулей расширения или лицензий. Например, у Juniper в линейке маршрутизаторов MX (кроме последних MX104 и MX204) выполнять NAPT можно на отдельной сервисной карте MS-MIC, на Cisco ASR1k требуется лицензия СGN license, на Cisco ASR9k — отдельный модуль A9K-ISM-100 и лицензия A9K-CGN-LIC к нему. В общем, удовольствие стоит немалых денег.
IPTables
Задача выполнения NAT не требует специализированных вычислительных ресурсов, ее в состоянии решать процессоры общего назначения, которые установлены, например, в любом домашнем роутере. В масштабах оператора связи эту задачу можно решить используя commodity серверы под управлением FreeBSD (ipfw/pf) или GNU/Linux (iptables). Рассматривать FreeBSD не будем, т.к. я довольно давно отказался от использования этой ОС, так что остановимся на GNU/Linux.
Включить трансляцию адресов совсем не сложно. Для начала необходимо прописать правило в iptables в таблицу nat:
Операционная система загрузит модуль nf_conntrack, который будет следить за всеми активными соединениями и выполнять необходимые преобразования. Тут есть несколько тонкостей. Во-первых, поскольку речь идет о NAT в масштабах оператора связи, то необходимо подкрутить timeout’ы, потому что со значениями по умолчанию размер таблицы трансляций достаточно быстро вырастет до катастрофических значений. Ниже пример настроек, которые я использовал на своих серверах:
И во-вторых, поскольку по умолчанию размер таблицы трансляций не рассчитан на работу в условиях оператора связи, его необходимо увеличить:
Также необходимо увеличить и количество buckets для хэш-таблицы, хранящей все трансляции (это опция модуля nf_conntrack):
После этих нехитрых манипуляций получается вполне работающая конструкция, которая может транслировать большое количество клиентских адресов в пул внешних. Однако, производительность этого решения оставляет желать лучшего. В своих первых попытках использования GNU/Linux для NAT (примерно 2013 год) я смог получить производительность около 7Gbit/s при 0.8Mpps на один сервер (Xeon E5-1650v2). С того времени в сетевом стеке ядра GNU/Linux было сделано много различных оптимизаций, производительность одного сервера на том же железе выросла практически до 18-19 Gbit/s при 1.8-1.9 Mpps (это были предельные значения), но потребность в объеме трафика, обрабатываемого одним сервером, росла намного быстрее. В итоге были выработаны схемы балансировки нагрузки на разные серверы, но всё это увеличило сложность настройки, обслуживания и поддержания качества предоставляемых услуг.
NFTables
Сейчас модным направлением в программном «перекладывании пакетиков» является использование DPDK и XDP. На эту тему написана куча статей, сделано много разных выступлений, появляются коммерческие продукты (например, СКАТ от VasExperts). Но в условиях ограниченных ресурсов программистов у операторов связи, пилить самостоятельно какое-нибудь «поделие» на базе этих фреймворков довольно проблематично. Эксплуатировать такое решение в дальнейшем будет намного сложнее, в частности, придется разрабатывать инструменты диагностики. Например, штатный tcpdump с DPDK просто так не заработает, да и пакеты, отправленные назад в провода с помощью XDP, он не «увидит». На фоне всех разговоров про новые технологии вывода форвардинга пакетов в user-space, незамеченными остались доклады и статьи Pablo Neira Ayuso, меинтейнера iptables, про разработку flow offloading в nftables. Давайте рассмотрим этот механизм подробнее.
Основная идея заключается в том, что если роутер пропустил пакеты одной сессии в обе стороны потока (TCP сессия перешла в состояние ESTABLISHED), то нет необходимости пропускать последующие пакеты этой сессии через все правила firewall, т.к. все эти проверки всё равно закончатся передачей пакета далее в роутинг. Да и собственно выбор маршрута выполнять не надо — мы уже знаем в какой интерфейс и какому хосту надо переслать пакеты пределах этой сессии. Остается только сохранить эту информацию и использовать ее для маршрутизации на ранней стадии обработки пакета. При выполнении NAT необходимо дополнительно сохранить информацию об изменениях адресов и портов, преобразованных модулем nf_conntrack. Да, конечно, в этом случае перестают работать различные полисеры и другие информационно-статистические правила в iptables, но в рамках задачи отдельного стоящего NAT или, например, бордера — это не так уж важно, потому что сервисы распределены по устройствам.
Конфигурация
Чтобы воспользоваться этой функцией нам надо:
- Использовать свежее ядро. Несмотря на то, что сам функционал появился еще в ядре 4.16, довольно долго он было очень «сырой» и регулярно вызывал kernel panic. Стабилизировалось всё примерно в декабре 2019 года, когда вышли LTS ядра 4.19.90 и 5.4.5.
- Переписать правила iptables в формат nftables, используя достаточно свежую версию nftables. Точно работает в версии 0.9.0
Если с первым пунктом всё в принципе понятно, главное не забыть включить модуль в конфигурацию при сборке (CONFIG_NFT_FLOW_OFFLOAD=m), то второй пункт требует пояснений. Правила nftables описываются совсем не так, как в iptables. Документация раскрывает практически все моменты, также есть специальные конверторы правил из iptables в nftables. Поэтому я приведу только пример настройки NAT и flow offload. Небольшая легенда для примера: , — это сетевые интерфейсы, через которые проходит трафик, реально их может быть больше двух.
— начальный и конечный адрес диапазона «белых» адресов.
Конфигурация NAT очень проста:
С flow offload немного сложнее, но вполне понятно:
Вот, собственно, и вся настройка. Теперь весь TCP/UDP трафик будет попадать в таблицу fastnat и обрабатываться намного быстрее.
Результаты
Чтобы стало понятно, насколько это «намного быстрее», я приложу скриншот нагрузки на два реальных сервера, с одинаковой начинкой (Xeon E5-1650v2), одинаково настроенных, использующих одно и тоже ядро Linux, но выполняющих NAT в iptables (NAT4) и в nftables (NAT5).

На скриншоте нет графика пакетов в секунду, но в профиле нагрузки этих серверов средний размер пакета в районе 800 байт, поэтому значения доходят до 1.5Mpps. Как видно, запас производительности у сервера с nftables огромный. На текущий момент этот сервер обрабатывает до 30Gbit/s при 3Mpps и явно способен упереться в физическое ограничение сети 40Gbps, имея при этом свободные ресурсы CPU.
Надеюсь, этот материал будет полезен сетевым инженерам, пытающимся улучшить производительность своих серверов.
Источник
Настройка интернет-шлюза с NAT и Port Forwarding на CentOS 7
В этой статье мы рассмотрим процесс организации и настройки простого интернет-шлюза на базе CentOS 7.x. Данный шлюз позволит пользователям из локальной сети выходить в Интернет, а также получать доступ к серверам или компьютерам во внутренней сети снаружи. Для организации маршрутизации и пересылки пакетов мы будем использовать технологию NAT на базе межсетевого экрана iptables. Также рассмотрим, как вести и анализировать логи подключений на интернет-шлюзе при доступе внешних пользователей в локальную сеть.
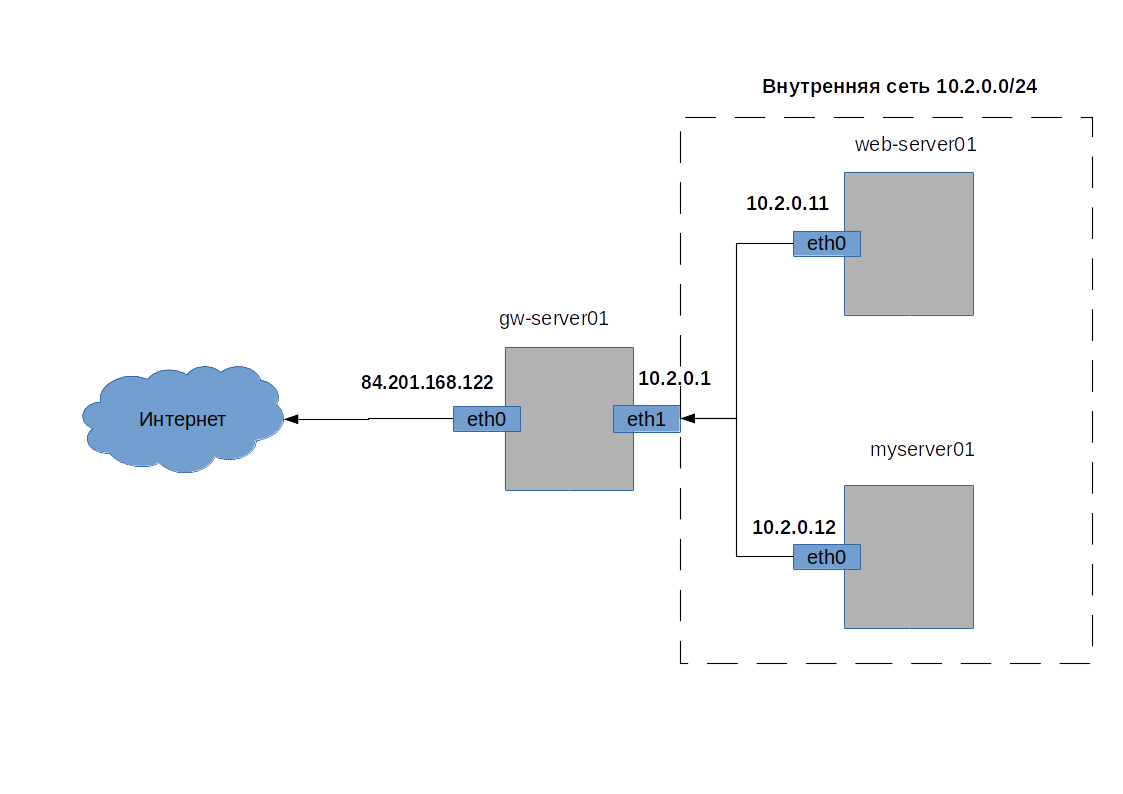
Схема локальной сети со шлюзом доступа в Интернет, типы NAT
NAT (Network Address Translation) – трансляция IP адресов, это механизм, позволяющий подменять адрес источника и назначения в заголовке IP пакетов, при их прохождении через маршрутизатор, т.е. между разными сетями.
Настраивать NAT будем между внутренней сетью с адресацией 10.2.0.0/24 и внешней сетью Интернет, двух видов:
- source NAT – это подмена IP адреса источника, в нашем случае, для организации выхода в Интернет через один публичный IP адрес нескольких клиентов.
- destination NAT — подмена IP адреса назначения, в нашем случае, для обеспечения доступа из внешней сети Интернет через публичный IP адрес к серверам внутренней сети.
Определим элементы сети (рисунок 1), между которыми будет организован NAT:
- gw-server – сервер шлюз, т.е. наш CentOS Linux сервер, который предоставляет доступ за пределы внутренней сети. У него два интерфейса, первый eth1(10.2.0.1) во внутренней сети, второй eth0(84.201.168.122) с публичным IP адресом и доступом в Интернет;
- web-server01 – веб сервер внутренней сети, IP адрес 10.2.0.11;
- my-server01 – личный сервер внутренней сети, IP адрес 10.2.0.12.
Настройка Source NAT: доступ из локальной сети в Интернет
При source NAT для серверов внешней сети, запросы от наших клиентов из внутренней сети будут выглядеть так, как будто с ними общается напрямую сервер шлюз — gw-server01.
В прошлой статье “Базовая настройка файервола Linux с помощью iptables” мы рассмотрели азы использования iptables. В этот раз, работать в iptables будем не только с таблицей filter, но и с таблицей nat. В отличие от таблицы для фильтрации трафика filter, таблица nat содержит следующие chains(цепочки):
- PREROUTING — в этой цепочке обрабатываются входящие IP пакеты, до их разделения на предназначенные для самого сервера или для передачи другому, т.е. до принятия решения о выборе маршрута для IP пакета;
- OUTPUT – цепочка предназначена для обработки IP пакетов, которые сгенерированы локально приложением на сервере. Локально сгенерированные IP пакеты не проходят цепочку PREROUTING;
- POSTROUTING — в этой цепочке обрабатываются все исходящие IP пакеты, уже после принятия решения о маршруте для IP пакета.
Отличаются и действия, выполняемые для IP пакетов, в этой таблице:
- MASQUERADE и SNAT— производит подмену IP адреса источника для исходящих пакетов. Отличием этих действий является то, что SNAT дает возможность задать конкретный IP адрес нового источника, а в случае MASQUERADE это происходит динамически;
- DNAT — производит подмену IP адреса назначения для входящих пакетов.
На рисунке 2 изображены этапы обработки IP пакета из внутренней сети на шлюзе gw-server01 при SNAT на iptables. IP адрес и порт назначения при этом остаются неизменными.
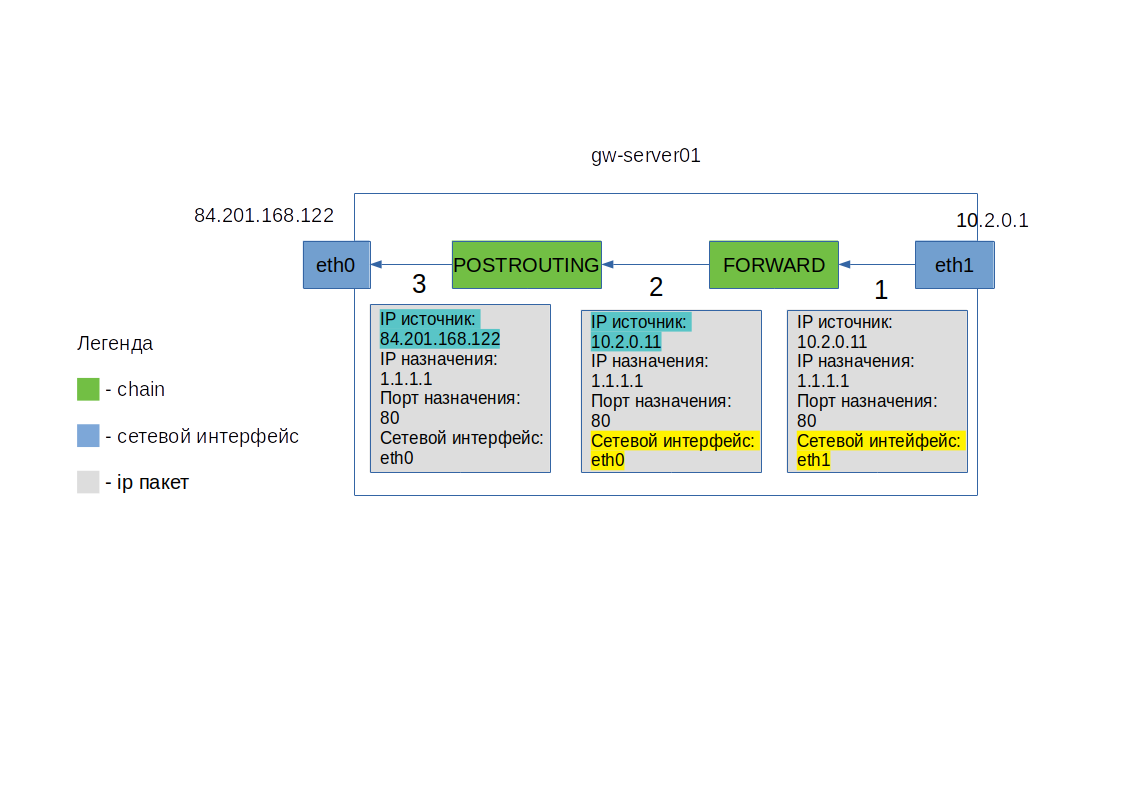 Рисунок 2
Рисунок 2
- IP пакет поступил на внутренний интерфейс eth1 сервера gw-server01. Так как IP назначения не принадлежит серверу gw-server01, IP пакет переходит к обработке цепочкой FORWARD.
- После прохождения цепочки FORWARD, для IP пакета определяется исходящий сетевой интерфейс, с которого он должен быть отправлен, это отмечено желтым цветом
- В конце IP пакет проходит цепочку POSTROUTING, в которой происходит подмена IP адреса источника, на IP адрес внешнего интерфейса eth0 сервера gw-server01
Приступим к настройке. Сначала нужно установить параметр ядра, который позволяет передавать пакеты между интерфейсами сервера. Для этого в файл /etc/sysctl.conf добавим переменную:
Чтобы применить изменения, выполним команду
sysctl -p /etc/sysctl.conf
здесь sysctl это команда, которая позволяет управлять параметрами ядра, ключ -p означает, что нужно считать параметры из файла.
Создадим правило в iptables, разрешающее передачу пакетов между внутренним (eth1) и внешним (eth0) интерфейсом:
iptables -A FORWARD -i eth1 -o eth0 -j ACCEPT
и разрешим передавать между интерфейсами пакеты, относящиеся к уже установленным соединениям.
iptables -A FORWARD -m state —state RELATED,ESTABLISHED -j ACCEPT
Предыдущие два правила имеет смысл создавать, только если для цепочки FORWARD по умолчанию установлена политика DROP:
iptables -P FORWARD DROP
iptables -t nat -A POSTROUTING -s 10.2.0.0/24 -o eth1 -j SNAT —to-source 84.201.168.122
- —to-source должен быть адресом на интерфейсе, с которого планируется выпускать во внешнюю сеть IP пакеты;
- -s 10.2.0.0/24 задано из расчета, что внутренняя сеть 10.2.0.0/24, но это необязательный параметр, если его не указать, ограничений на источник взаимодействия не будет.
Посмотрим получившуюся конфигурацию для таблицы filter и цепочки FORWARD (вывод обрезан):

и конфигурацию для таблицы nat и цепочки POSTROUTING (вывод обрезан):
iptables -t nat -L -n -v

Для проверки, что наш веб-сервер во внутренней сети получил доступ в Интернет, попробуем подключиться через telnet на адрес 1.1.1.1 (Cloudflare DNS) порт 80:
telnet 1.1.1.1 80

Вывод команды Connected 1.1.1.1, показывает, что подключение прошло успешно.
Настройка Destination NAT и port forwarding: доступ из Интернета в локальную сеть
Теперь рассмотрим обратную ситуацию. Мы хотим, чтобы клиенты снаружи имели возможность попадать на наш сайт во внутренней сети. А также нам нужно заходить на свой личный сервер (или рабочую станцию) из Интернета. Отличие этого случая не только в направлении взаимодействия, но еще и в том, что требуется перенаправить запросы на отдельные порты, 80(TCP) и 3389(TCP), при этом подменять сервер назначения и возможно, порт назначения. Эта техника называется port forwarding (проброс портов).
Сначала разрешим передачу пакетов с внешнего интерфейса (eth0) на внутренний (eth1) интерфейс:
iptables -A FORWARD -i eth0 -o eth1 -j ACCEPT
Это правило разрешает передавать IP пакеты между интерфейсами независимо от источника. Но можно отдельным правилом запретить подключение через NAT для отдельных IP адресов или подсетей:
iptables -I FORWARD 1 -o eth1 -s 167.71.67.136 -j DROP
Теперь перенаправим все соединения на порт 80 интерфейса внешней сети(eth0) на IP адрес веб сервера внутренней сети web-server01:
iptables -t nat -A PREROUTING -p tcp —dport 80 -i eth0 -j DNAT —to-destination 192.168.0.11
—to-destination — должен быть IP адресом, на который нужно заменить IP адрес назначения.
Для проверки, попробуем подключиться из сети Интернет через telnet на публичный IP адрес сервера gw-server на порт 80:
telnet 84.201.168.122 80
Результатом будет ответ веб сервера web-server01 из нашей внутренней сети:
Аналогично можно настроить доступ из интернета на свою рабочую станцию по RDP. Так как доступ по RDP будет нужен ограниченному количеству человек, безопасней будет использовать при подключении нестандартный порт, например 13389, а уже с него перенаправлять на порт 3389 сервера внутренней сети (либо изменить номер RDP порта на Windows компьютере). Измененный порт назначения указывается через двоеточие после IP адреса:
iptables -t nat -A PREROUTING -p tcp —dport 13389 -i eth0 -j DNAT —to-destination 192.168.0.12:3389
Для проверки, попробуем подключиться из сети Интернет через telnet (или командлет PowerShell Test-NetConnection) на публичный IP адрес сервера gw-server на порт 13389:
telnet 84.201.168.122 13389
В ответ получим пустой экран и курсор, это говорит о том, что соединение работает.
Анализ логов сетевых подключений NAT в Linux
Одним из моментов, для повышения уровня безопасности после настройки port forwarding на наш личный сервер из внешней сети, будет сборка и анализ логов внешний подключений. Ведь кроме нас, этим доступом может попробовать воспользоваться злоумышленник.
Сначала включим запись в лог файл /var/log/messages все попытки соединений на используемый нами нестандартный RDP порт:
iptables -I INPUT 1 -p tcp —dport 13389 -m state —state NEW -j LOG —log-prefix «NEW RDP SESSION»
Подключимся к нашему личному серверу, чтобы в логе появилась запись. Теперь отфильтруем все записи в лог файле, которые нам нужны:
cat /var/log/messages | grep «NEW RDP SESSION»
Читать такой лог не очень удобно, тем более каждый день. Поэтому, следующим шагом, автоматизируем анализ логов, чтобы регулярно получать отчеты, на основе нашего фильтра. Для этого воспользуемся утилитой Logwatch, ее установка через стандартный менеджер пакетов yum:
yum install logwatch
Сначала попробуем сгенерировать отчет вручную:
/usr/sbin/logwatch —detail low —service iptables —range today
- —service — задает конкретный сервис, сообщения от которого нужно анализировать, в нашем случае, только от iptables;
- —range — указывает период выборки данных, today – все события за сегодня;
- —detail — степень детализация отчета (high, med, low).
По умолчанию logwatch отобразит отчет на экран, получим примерно такой вывод:
Отчет работает, осталось выполнять его по расписанию, раз день и отправлять себе на email, для этого обновим команду и запишем ее в файл /etc/cron.daily/00logwatch:
/usr/sbin/logwatch —output mail —mailto test@gmail.com —detail low —service iptables —range yesterday
Здесь добавились опции:
—output — указывает способ вывода отчета, mail – отправить на почту;
—mailto — e-mail адрес получателя отчета.
Источник



