- Онлайн “школа” сетевых технологий NetSkills
- Linux для начинающих или чему может научить девушка?
- Символы Unicode: о чём должен знать каждый разработчик
- Введение в кодировку
- Краткая история кодировки
- Проблемы с ASCII
- Что такое кодовые страницы ASCII?
- Безумие какое-то.
- Так появился Unicode
- Unicode Transform Protocol (UTF)
- Что такое UTF-8 и как она работает?
- Напоследок про UTF
- Это всё?
- Заключение
Онлайн “школа” сетевых технологий NetSkills
Здравствуйте, коллеги! Хотел бы сообщить, что “школа” NetSkills продолжает свое развитие. Сам проект изначально just for fun, поэтому слово “школа” употребляется исключительно с кавычками. 
На текущий момент на канале YouTube уже почти 10 тысяч подписчиков и их количество непрерывно растет.
Совсем недавно был завершен очередной курс по основам GNS3 и теперь в “школе” NetSkills есть весь необходимый минимум для обучения молодых специалистов сетевым технологиям, а именно:
1.“Курс молодого бойца” — это курс по программному симулятору Cisco Packet Tracer, где мы вкратце рассматриваем основы сетевых технологий.
2.“Основы GNS3” — этот курс позволяет расширить наши возможности при обучении, получив полный функционал различных эмулируемых устройств. Если вы освоили данный материал, это существенный плюс в вашей профессиональной карьере.
3.Архитектура корпоративных сетей — это пособие для начинающих сетевых инженеров, желающих познакомиться с основами построения корпоративных сетей. В книге рассмотрены иерархическая модель и основные модули корпоративной сети, их расположение в сети, а так же основные методы защиты. Данное пособие отлично подойдет для системных инженеров, которые нуждаются в стандартизации применяемых сетевых решений.
4.Так же в блоге blog.netskills.ru постоянно публикуются различные IT — новости, обзоры и полезные материалы.
Данные материалы можно смело применять для обучения молодых специалистов.
А теперь хотелось бы провести некий анализ проделанной работы по последнему курсу “Основы GNS3”.
Небольшая статистика курса:
1. Всего в курсе получилось 13 уроков, не считая Введение и Заключение. Уроки вошедшие в курс:
•Установка на Windows
•Установка на Linux
•Базовая настройка. Добавление образов Cisco
•Простейшая сеть
•Добавление хоста в сеть. Virtual PC Simulator
•Коммутатор в GNS3
•L3 коммутатор (Router + EtherSwitch module)
•Добавление хоста VirtualBox
•Добавление хоста VMware Workstation
•Добавление своего компьютера в сеть GNS3
•Подключение GNS3 к реальной сети
•Cisco ASA + ASDM
•Wireshark
2. Посмотрели данный курс 9 тысяч человек.
3. Записывался курс 5 месяцев. Опять же, дольше чем мне хотелось бы…
Теперь поговорим о выявленных проблемах и недостатках GNS3. К сожалению тут есть что рассказать.
1. Первое, что меня расстроило, это отсутствие возможности эмулировать Cisco PIX. Да, это очень старая версия и сейчас уже есть Cisco ASA, но у pix-a свои достоинства. PIX требует меньше ресурсов (обычно хватает 512mb памяти), у него схожий с Cisco ASA функционал и синтаксис команд. Но самое главное — он гораздо стабильнее и это факт. К сожалению больше gns3 не поддерживает это устройство.
2. Второе — ужасные проблемы с Cisco ASA. В своё время я перешёл на gns3 только из-за Асы. Тогда у gns3 была версия 0.8.7, если не ошибаюсь. ASA работала с некоторыми ошибками, но в целом можно было пользоваться. Сейчас у gns3 доступна версия 1.4 и работать с Асой стало практически невозможно. Процесс запуска похож на знаменитый танец с бубном. Я нашёл в интернете около пяти инструкций по запуску и ни один способ не даёт 100 процентной гарантии работы. Причём на одном компьютере может работать первый способ, на другом компьютере — только второй. Смена версии qemu, создание flash памяти, запуск под linux-ом, ограничение загрузки процессора, все это приходится проверять методом научного тыка, т.к. нет никакой закономерности.
3. Баг с маршрутизаторами. Собрав и настроив схему с роутерами в какой-то момент можно обнаружить что трафик просто перестал ходить. Начинается долгий траблшутинг, но в итоге оказывается что нужно просто перезагрузить роутер. Ответ на вопрос “Почему происходят такие зависания?” я так и не нашёл.
4. Пропадание интерфейсов. Совсем недавно выявил эту проблему. Возникает она как в L3 коммутаторах, так и в Cisco ASA. В конфигурации устройства просто не видно интерфейсы. Для роутеров это решается подбором других образов ios. А для ASA добавлением еще одного интерфейса.
5. Про постоянно меняющийся портал GNS3 я говорить ничего не будут и так все понятно.
С одной стороны все перечисленные баги полезны, т.к. заставляют человека искать проблему, оттачивая навыки траблшутинга. Но ТАКОЕ количество “особенностей” программы просто тормозит работу. В итоге человек вместо обучения может провозиться с очередным багом несколько дней, отчаянно пытаясь поднять Cisco ASA и ASDM в GNS3. Здесь можно конечно возразить и уповать на кривость рук пользователя, однако проблемы слишком распространенные и их огромное кол-во. Портал gns3 просто пестрит ими, но разработчики как-будто не слышат и не видят ничего, продолжая штамповать релиз за релизом, чуть чуть изменяя интерфейс и добавляя рекламу.
Тем не менее, несмотря на все перечисленный недостатки, GNS3 все еще является самым популярным софтом для эмуляции сетей. У него:
1. Удобный и интуитивно понятный интерфейс. Тот же UnetLab, который на сегодня рассматривается как основной конкурент, имеет только web — интерфейс, что не совсем удобно и для многих — непривычно.
2. И второе — Бесплатность (в отличии от таких продуктов, как Cisco VIRL и Boson NetSim)
Думаю, на данный момент gns3 идеально подходит для небольших виртуальных сетей из двух-трех роутеров, когда вам надо быстро поднять макет, так сказать “на коленке”.
Однако, стоит так же отметить, что если GNS3 и дальше будет развиваться по той же стратегии, то UnetLab довольно быстро перехватит инициативу и догнать его будет уже очень трудно (конечно если проект продолжит развиваться).
Теперь хотелось бы поделиться планами.
Думаю всем понятно, что описанных выше курсов недостаточно для успешного начала IT карьеры. Поэтому на ближайшее будущее у школы NetSkills грандиозные планы, а именно:
1. Курс по основам Linux-а. Я глубоко убежден, что каждый уважающий себя сетевой инженер просто обязан уметь работать с Linux-подобными системами. Огромное кол-во сетевых устройств, таких как межсетевые экраны, системы предотвращения вторжений, VPN-шлюзы и даже коммутаторы, основаны на Linux-е. Особенно это актуально с текущей тенденцией по импортзамещению.
2. Курс по основам проектирования сетей. Очень важный на самом деле курс. В нем мы рассмотрим основные аспекты планирования и документирования сети. Хороший сетевой инженер это не только настройка, но и качественно документированная сеть! L2, L3 схемы, IP план, кабельный журнал, все это мы рассмотрим в рамках курса.
3. UNetLab. Этот курс совершенно необходим для желающих получить сертификат CCNP или CCIE. А для CCNA хватит и связки Cisco Packet Tracer + GNS3.
4. Руководство по подготовке к CCNA. В нем мы подробно рассмотрим, как успешно сдать экзамен №1 в мире сетевых технологий.
Есть еще некоторые идеи, но пока ничего конкретного. Вот такие планы на ближайшее будущее.
Что ж, вот на такой неоднозначной ноте мы закончим. Искренне надеюсь, что данный материал оказался для вас полезным. Жду вас на следующих курсах и до новых встреч!
Источник
Linux для начинающих или чему может научить девушка?
Приветствую, коллеги. Долгое время проект NetSkills был посвящен исключительно сетевым технологиям — Курс молодого бойца, Основы GNS, UNetLab. Однако от подписчиков все чаще звучал вопрос: “А что еще должен знать сетевой инженер или системный администратор?”. Тут можно привести большой список технологий/направлений и в итоге сделать вывод, что знать только сети — недостаточно! Совершенно очевидно, что для успешной карьеры нужно намного больше. Поэтому было принято решение расширить проект и для начала выпустить курс “Linux для начинающих”.
Немаловажная деталь, преподаватель — девушка, которая совсем недавно примкнула к проекту NetSkills. Чему же может научить девушка? Если вы заинтересовались, добро пожаловать под кат…
Цель курса – изучить основы администрирования операционных систем Linux. Материал по большей части практический и содержит минимальное количество теории. Курс подойдет как для начинающих системных администраторов, которые занимаются настройкой серверов компании, так и для сетевых инженеров, т.к. бОльшая часть сетевого оборудования работает под управлением Linux (особенно если учитывать тенденцию импортозамещения), поэтому навыки работы с этой системой им однозначно не помешают. Да и вообще, каждый уважающий себя ИТ-шник просто обязан обладать базовыми навыками работы с Linux системами. Ценность такого сотрудника сразу вырастает.
Для тех, кому лень читать выкладываю первый видео урок:
Весь курс будет разделен на две части: базовый и расширенный курс. В базовом курсе мы рассмотрим основные понятия, научимся производить первоначальную настройку сервера, а также настроим шлюз доступа в Интернет. В расширенном курсе мы рассмотрим, как развернуть серверную инфраструктуру компании на основе Linux.
В план базового курса вошли следующие темы:
1.Цели изучения операционной системы Linux, ее основные преимущества.
2.Создание виртуальных машин.
3.Установка операционной системы CentOS.
4.Структура файловой системы Linux.
5.Основные команды, необходимые для работы в консоли Linux (cd, ls, man, grep, find, cp, mv, rm и т.д.).
6.Настройка сети в CentOS. Утилиты Putty, WinSCP.
7.Основы безопасности. Заведение новых пользователей в системе.
8.Установка пакетов. Пакетный менеджер. Репозитории.
9.Файловый менеджер mc, текстовый редактор nano и сетевые утилиты (ifconfig, nslookup, arp, telnet).
10.Настройка шлюза доступа в Интернет. Iptables. NAT. DHCP.
Итак, зачем изучать линукс и каковы его преимущества? Полагаю, стоит начать с определения.
GNU/Linux – это семейство unix-подобных операционных систем, основанных на ядре Linux. ОС из этого семейства распространяются обычно бесплатно в виде так называемых дистрибутивов, содержащих помимо самой ОС еще и набор прикладного ПО (т.е. по сути сборка). Дистрибутивов Linux на сегодняшний день существует огромное количество, но почти все они являются потомками трех основных дистрибутивов: Debian, Slackware и Red Hat. Подробнее о GNU/Linux и дистрибутивах можно прочитать здесь и здесь.
Возможно, у кого-то возник вопрос: почему GNU/Linux, а не просто Linux. Все дело в том, что Linux – это всего лишь ядро, в то время как GNU/Linux – это операционная система. Однако, Linux’ом можно называть как ядро так и ОС – и так и так будет правильно.
Условно говоря, ОС состоит из двух частей: kernel space и user space. Kernel space это ядро, которое непосредственно взаимодействует с устройствами в системе, обслуживает их и производит настройку. В нашем случае – это ядро Linux, разработка которого началась в 1991 году Линусом Торвальдсом, являвшимся на тот момент студентом. Оно поддерживает многозадачность, динамические библиотеки, виртуальную память, отложенную загрузку, большинство сетевых протоколов и производительную систему управления памятью и распространяется по лицензии GNU GPL, т.е. свободно. Подробнее про само ядро и его «увлекательную» систему нумерации версий можно узнать здесь. Пользователи же работают в пространстве user space (пространстве приложений), а это в свою очередь файлы. Вообще говоря, все в Linux’е представлено файлами — настройки, сами приложения, даже процессы. Это очень удобно при настройке и когда пытаешься выяснить почему же все поломалось.
Дистрибутивы Linux распространяются в основном по лицензии GNU General Public License – лицензии на свободное программное обеспечение. Цель GNU GPL — предоставить пользователю права копировать, модифицировать и распространять (в том числе на коммерческой основе) программы, а также гарантировать, что и пользователи всех производных программ получат вышеперечисленные права.
Помимо выше указанных неоспоримых плюсов данной ОС, она обладает еще рядом особенностей:
1.Безопасность
2.Производительность
3.Надежность
4.Масштабируемость
5.Аппаратная совместимость
6.Не требуется импортозамещение
7.Зарплата Linux администраторов выше, чем у обычных администраторов
Благодаря выше перечисленным особенностям, Linux получил широкое распространение и используется во многих сферах: критические сервисы (скоростные поезда в Японии, CERN, системы контроля воздушного трафика), социальные сети, поисковые сервисы, а так же в мобильных телефонах, планшетах, ПК, банкоматах и автомобильной электронике.
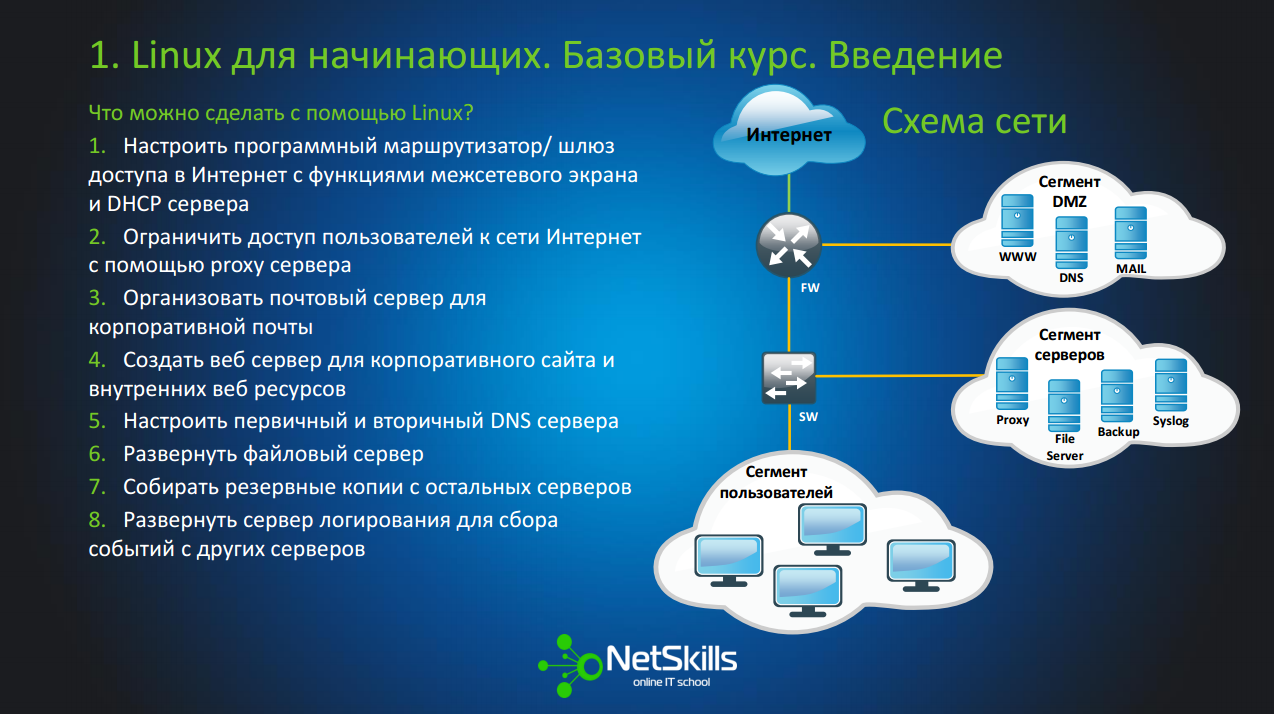
Вообще говоря, на основе Linux можно сделать много чего, но мы остановимся на более повседневных вещах. Предположим, в некоторой компании, где работает большое количество пользователей, нужно развернуть серверную инфраструктуру, т.е. пользователям нужно дать доступ в Интернет, запретить в рабочее время сидеть в социальных сетях, организовать корпоративную почту, файловый сервер, и т.д. Что мы можем сделать на основе Linux? На самом деле очень даже многое.
Мы можем:
1.Настроить программный маршрутизатор/ шлюз доступа в Интернет с функциями межсетевого экрана и DHCP сервера
2.Ограничить доступ пользователей к сети Интернет с помощью proxy сервера
3.Организовать почтовый сервер для корпоративной почты
4.Создать веб сервер для корпоративного сайта и внутренних веб ресурсов
6.Настроить первичный и вторичный DNS сервера
7.Развернуть файловый сервер
8.Собирать резервные копии с остальных серверов
9.Развернуть сервер логирования для сбора событий с других серверов
Такую схему мы и будем разворачивать в рамках данного курса.
Полагаю, на этом первый урок можно закончить.
Источник
Символы Unicode: о чём должен знать каждый разработчик

Если вы пишете международное приложение, использующее несколько языков, то вам нужно кое-что знать о кодировке. Она отвечает за то, как текст отображается на экране. Я вкратце расскажу об истории кодировки и о её стандартизации, а затем мы поговорим о её использовании. Затронем немного и теорию информатики.
Введение в кодировку
Компьютеры понимают лишь двоичные числа — нули и единицы, это их язык. Больше ничего. Одно число называется байтом, каждый байт состоит из восьми битов. То есть восемь нулей и единиц составляют один байт. Внутри компьютеров всё сводится к двоичности — языки программирования, движений мыши, нажатия клавиш и все слова на экране. Но если статья, которую вы читаете, раньше была набором нулей и единиц, то как двоичные числа превратились в текст? Давайте разберёмся.
Краткая история кодировки
На заре своего развития интернет был исключительно англоязычным. Его авторам и пользователям не нужно было заботиться о символах других языков, и все нужды полностью покрывала кодировка American Standard Code for Information Interchange (ASCII).
ASCII — это таблица сопоставления бинарных обозначений знакам алфавита. Когда компьютер получает такую запись:
то с помощью ASCII он преобразует её во фразу «Hello world».
Один байт (восемь бит) был достаточно велик, чтобы вместить в себя любую англоязычную букву, как и управляющие символы, часть из которых использовалась телепринтерами, так что в те годы они были полезны (сегодня уже не особо). К управляющим символам относился, например 7 (0111 в двоичном представлении), который заставлял компьютер издавать сигнал; 8 (1000 в двоичном представлении) — выводил последний напечатанный символ; или 12 (1100 в двоичном представлении) — стирал весь написанный на видеотерминале текст.
В те времена компьютеры считали 8 бит за один байт (так было не всегда), так что проблем не возникало. Мы могли хранить все управляющие символы, все числа и англоязычные буквы, и даже ещё оставалось место, поскольку один байт может кодировать 255 символов, а для ASCII нужно только 127. То есть неиспользованными оставалось ещё 128 позиций в кодировке.
Вот как выглядит таблица ASCII. Двоичными числами кодируются все строчные и прописные буквы от A до Z и числа от 0 до 9. Первые 32 позиции отведены для непечатаемых управляющих символов.
Проблемы с ASCII
Позиции со 128 по 255 были пустыми. Общественность задумалась, чем их заполнить. Но у всех были разные идеи. Американский национальный институт стандартов (American National Standards Institute, ANSI) формулирует стандарты для разных отраслей. Там утвердили позиции ASCII с 0 по 127. Их никто не оспаривал. Проблема была с остальными позициями.
Вот чем были заполнены позиции 128-255 в первых компьютерах IBM:
Какие-то загогулины, фоновые иконки, математические операторы и символы с диакретическим знаком вроде é. Но разработчики других компьютерных архитектур не поддержали инициативу. Всем хотелось внедрить свою собственную кодировку во второй половине ASCII.
Все эти различные концовки назвали кодовыми страницами.
Что такое кодовые страницы ASCII?
Здесь собрана коллекция из более чем 465 разных кодовых страниц! Существовали разные страницы даже в рамках какого-то одного языка, например, для греческого и китайского. Как можно было стандартизировать этот бардак? Или хотя бы заставить его работать между разными языками? Или между разными кодовыми страницами для одного языка? В языках, отличающихся от английского? У китайцев больше 100 000 иероглифов. ASCII даже не может всех их вместить, даже если бы решили отдать все пустые позиции под китайские символы.
Эта проблема даже получила название Mojibake (бнопня, кракозябры). Так говорят про искажённый текст, который получается при использовании некорректной кодировки. В переводе с японского mojibake означает «преобразование символов».
Пример бнопни (кракозябров).
Безумие какое-то.
Именно! Не было ни единого шанса надёжно преобразовывать данные. Интернет — это лишь монструозное соединение компьютеров по всему миру. Представьте, что все страны решили использовать собственные стандарты. Например, греческие компьютеры принимают только греческий язык, а английские отправляют только английский. Это как кричать в пустой пещере, тебя никто не услышит.
ASCII уже не удовлетворял жизненным требованиям. Для всемирного интернета нужно было создать что-то другое, либо пришлось бы иметь дело с сотнями кодовых страниц.
��� Если только ������ вы не хотели ��� бы ��� читать подобные параграфы. �֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
Так появился Unicode
Unicode расшифровывают как Universal Coded Character Set (UCS), и у него есть официальное обозначение ISO/IEC 10646. Но обычно все используют название Unicode.
Этот стандарт помог решить проблемы, возникавшие из-за кодировки и кодовых страниц. Он содержит множество кодовых пунктов (кодовых точек), присвоенных символам из языков и культур со всего мира. То есть Unicode — это набор символов. С его помощью можно сопоставить некую абстракцию с буквой, на которую мы хотим ссылаться. И так сделано для каждого символа, даже египетских иероглифов.
Кто-то проделал огромную работу, сопоставляя каждый символ во всех языках с уникальными кодами. Вот как это выглядит:
Префикс U+ говорит о том, что это стандарт Unicode, а число — это результат преобразования двоичных чисел. Стандарт использует шестнадцатеричную нотацию, которая является упрощённым представлением двоичных чисел. Здесь вы можете ввести в поле что угодно и посмотреть, как это будет преобразовано в Unicode. А здесь можно полюбоваться на все 143 859 кодовых пунктов.
Уточню на всякий случай: речь идёт о большом словаре кодовых пунктов, присвоенных всевозможным символам. Это очень большой набор символов, не более того.
Осталось добавить последний ингредиент.
Unicode Transform Protocol (UTF)
UTF — протокол кодирования кодовых пунктов в Unicode. Он прописан в стандарте и позволяет кодировать любой кодовый пункт. Однако существуют разные типы UTF. Они различаются количеством байтов, используемых для кодировки одного пункта. В UTF-8 используется один байт на пункт, в UTF-16 — два байта, в UTF-32 — четыре байта.
Но если у нас есть три разные кодировки, то как узнать, какая из них применяется в конкретном файле? Для этого используют маркер последовательности байтов (Byte Order Mark, BOM), который ещё называют сигнатурой кодировки (Encoding Signature). BOM — это двухбайтный маркер в начале файл, который говорит о том, какая именно кодировка тут применена.
В интернете чаще всего используют UTF-8, она также прописана как предпочтительная в стандарте HTML5, так что уделю ей больше всего внимания.
Этот график построен в 2012-м, UTF-8 становилась доминирующей кодировкой. И всё ещё ею является.
Что такое UTF-8 и как она работает?
UTF-8 кодирует с помощью одного байта каждый кодовый пункт Unicode с 0 по 127 (как в ASCII). То есть если вы писали программу с использованием ASCII, а ваши пользователи применяют UTF-8, они не заметят ничего необычного. Всё будет работать как задумано. Обратите внимание, как это важно. Нам нужно было сохранить обратную совместимость с ASCII в ходе массового внедрения UTF-8. И эта кодировка ничего не ломает.
Как следует из названия, кодовый пункт состоит из 8 битов (один байт). В Unicode есть символы, которые занимают несколько байтов (вплоть до 6). Это называют переменной длиной. В разных языках удельное количество байтов разное. В английском — 1, европейские языки (с латинским алфавитом), иврит и арабский представлены с помощью двух байтов на кодовый пункт. Для китайского, японского, корейского и других азиатских языков используют по три байта.
Если нужно, чтобы символ занимал больше одного байта, то применяется битовая комбинация, обозначающая переход — он говорит о том, что символ продолжается в нескольких следующих байтах.
И теперь мы, как по волшебству, пришли к соглашению, как закодировать шумерскую клинопись (Хабр её не отображает), а также значки emoji!
Подытожив сказанное: сначала читаем BOM, чтобы определить версию кодировки, затем преобразуем файл в кодовые пункты Unicode, а потом выводим на экран символы из набора Unicode.
Напоследок про UTF
Коды являются ключами. Если я отправлю ошибочную кодировку, вы не сможете ничего прочесть. Не забывайте об этом при отправке и получении данных. В наших повседневных инструментах это часто абстрагировано, но нам, программистам, важно понимать, что происходит под капотом.
Как нам задавать кодировку? Поскольку HTML пишется на английском, и почти все кодировки прекрасно работают с английским, мы можем указать кодировку в начале раздела .
Важно сделать это в самом начале , поскольку парсинг HTML может начаться заново, если в данный момент используется неправильная кодировка. Также узнать версию кодировки можно из заголовка Content-Type HTTP-запроса/ответа.
Если HTML-документ не содержит упоминания кодировки, спецификация HTML5 предлагает такое интересное решение, как BOM-сниффинг. С его помощью мы по маркеру порядка байтов (BOM) можем определить используемую кодировку.
Это всё?
Unicode ещё не завершён. Как и в случае с любым стандартом, мы что-то добавляем, убираем, предлагаем новое. Никакие спецификации нельзя назвать «завершёнными». Обычно в год бывает 1-2 релиза, найти их описание можно здесь.
Если вы дочитали до конца, то вы молодцы. Предлагаю сделать домашнюю работу. Посмотрите, как могут ломаться сайты при использовании неправильной кодировки. Я воспользовался этим расширением для Google Chrome, поменял кодировку и попытался открывать разные страницы. Информация была совершенно нечитаемой. Попробуйте сами, как выглядит бнопня. Это поможет понять, насколько важна кодировка.
Заключение
При написании этой статьи я узнал о Майкле Эверсоне. С 1993 года он предложил больше 200 изменений в Unicode, добавил в стандарт тысячи символов. По состоянию на 2003 год он считался самым продуктивным участником. Он один очень сильно повлиял на облик Unicode. Майкл — один из тех, кто сделал интернет таким, каким мы его сегодня знаем. Очень впечатляет.
Надеюсь, мне удалось показать вам, для чего нужны кодировки, какие проблемы они решают, и что происходит при их сбоях.
Источник



