- Использование Redis в Node.js
- Что такое Redis
- Типы данных Redis
- Redis и Node.js — Модуль Redis для Node.js
- Node.js, Redis и MongoDB
- Реализация
- Что я использую Redis For
- Что я использую Mongo For
- Проблема
- Кэширование базы данных MongoDB с помощью Redis
- Основная система
- Добавление кеша
- Политика кэширования
- Обновление кеша
- метрика
- Выводы
Использование Redis в Node.js
В предыдущем статье я рассказал, как можно установить Redis на операционную систему Linux. Сегодня я вкратце расскажу — что такое Redis, какие типы данных существует, как и где данные хранятся, будем выполнять базовые операции.
Что такое Redis
Redis — это высокопроизводительная key-value хранилище данных. Все данные хранятся в оперативной памяти. Также, по мере необходимости данные дублируются на физический носитель. После сбоев или перезагрузки сервера Redis читать данные с диска. Используя Redis, мы получаем хранилище данных, которые хранятся в оперативной памяти, и после сбоев или перезагрузки сервера мы не теряем эти данные.
Сохранение данных на физический диск можно настроить двумя способами:
- через определенный промежуток времени он сохранял данные на диск;
- после определенное количество атомарных изменений он сохранял данные на диск.
Redis обладает такими возможностями и механизмы, как журналирование, снимки, поддержка работы с такими данными, для каждого из которых существует свой набор команд, транзакции, неблокирующая master-slave репликация на несколько узлов, подтяжка использование нескольких БД, с возможностью атомарного переноса ключей между ними, Pipeline (отправка на выполнение набора команд и отложенное получение ответа).
Типы данных Redis
- Строки (String) — Базовый тип данных Redis. Строки в Redis бинарно-безопасны, могут использоваться так же как числа.
- Списки (List) — Классические списки строк, упорядоченные в порядке вставки, которая возможна как со стороны головы, так и со стороны хвоста списка.
- Множества (Set) — Множества строк в математическом понимании: не упорядочены, поддерживают операции вставки, проверки вхождения элемента, пересечения и разницы множеств.
- Хеш-таблицы (Hash) — Классические хеш-таблицы или ассоциативные массивы.
- Упорядоченные множества (Sorted Sets) — Упорядоченное множество отличается от обычного тем, что его элементы упорядочены по особому параметру «score».
Обычно стандартные key-value хранилищи позволяют работать только с ключами. Но Redis нарушает эти принципы. Для каждого типа содержимое у него своя логика работы и набор команд.
Redis и Node.js — Модуль Redis для Node.js
Для работы с Redis v Node.js нам нужно установить модуль redis:
А теперь, давайте подключаем модуль и начнем работу с ним.
После подключение модуля и создание redis-клиента мы выбрали базу данных — 0. Но в данном случае это лишний шаг, по умолчанию используется база 0.
После выбора базы данных можно работать с Redis — записать данные в базу, получить и удалить данные с базы.
С помощью метода set объекта client записать данные в виде «Ключ — Значение», а с помощью метода get мы получаем данные по ключу.
Также, мы можем удалить данные по ключу с помощью метода del:
Данный модуль поддерживает все команды Redis. Например, мы с помощью одной команды можем одновременно работать с множеством ключей и значение.
Node.js, Redis и MongoDB
В моем текущем проекте сочетаются общие концепции API RESTful и современный веб-сайт/длительный сеанс реального времени. Я использую mongoDB для хранения устойчивых данных, таких как пользователи, продукты и агрегированный социальный контент. Социальный контент в основном связан с сообщениями tumblr, твиттерными твитами и сообщениями facebook, которые скомпилированы в то, что я называю «криком».
Реализация
То, что я пытаюсь сделать, — это кричать «крики», основанные на том, сколько нравится или следует за сообщением, из общей суммы из всех используемых социальных медиа. Я хочу, чтобы данные изменялись во внешнем интерфейсе в качестве обновлений бэкэнд. Внутренняя часть вызывает все социальные медиа, основанные на проверке даты истечения срока действия данных. Сервер будет проверять наличие новых данных о событии, что запрос был сделан для данных. Запрос делается для данных каждый раз, когда клиент подключается, или каждый раз, когда кто-то публикует новый крик через мое приложение. Если за определенный период времени активность отсутствует, крик архивируется и обновляется каждый раз с запланированными заданиями. Я использую socket.io для отправки обновлений в реальном времени.
Что я использую Redis For
Причина, по которой мне нужен Redis, — это сообщение на все мои серверы, когда один из них начинает запрашивать данные из источников в социальных сетях, поэтому я не сталкиваюсь с проблемой, когда все мои серверы по сути делают то же самое, когда задача должна быть только сделано один раз. Мне также нужно сообщать о моих других сервисах после внесения изменений. Для этих реализаций я в настоящее время использую Redis pub/sub. Поскольку я использую Redis, я также храню токены сеанса в redis и использую его как кеш.
Что я использую Mongo For
Я использую MongoDB для сохранения данных, и я настроил индексирование для настройки производительности специально для моего приложения.
Проблема
Моя проблема в том, что я чувствую, что мой стек слишком большой. Я чувствую, что использовать redis и монго можно убить. Должен ли я отключить redis и использовать систему MQ, а также сохранить сеансы и кеш в mongo и просто индексировать их для быстрого поиска? Если да, то какая система MQ подходит для моего приложения?
Должен ли я вырезать mongodb и использовать все redis? Будет ли это экономически выгодно для относительно больших сумм данных? Поскольку я буду хранить сотни тысяч (возможно, больше) криков (в основном, только URI), тысячи пользователей и сотни тысяч продуктов.
Кэширование базы данных MongoDB с помощью Redis
На сегодняшний день производительность является одним из наиболее важных показателей, которые необходимо оценивать при разработке веб-службы. Поддержание вовлеченности клиентов имеет решающее значение для любой компании, особенно для стартапов, и по этой причине чрезвычайно важно улучшить производительность и сократить время загрузки страницы.
При работе веб-сервера, который взаимодействует с базой данных, его операции могут стать узким местом. MongoDB здесь не исключение, и поскольку ваша база данных MongoDB расширяется, все может сильно замедлиться. Эта проблема может даже усугубиться, если сервер базы данных отсоединен от веб-сервера. В таких системах связь с базой данных может вызвать большие накладные расходы.
К счастью, вы можете использовать метод, называемый кэшированием, чтобы ускорить процесс. В этом руководстве мы познакомимся с этим методом и увидим, как вы можете использовать его для повышения производительности вашего веб-сервиса Node.js.
Кэширование — это стратегия, направленная на решение основной проблемы с хранилищем, которая означает: чем больше хранилище, тем медленнее будет и наоборот. В компьютере у вас есть жесткий диск, который большой, но также относительно медленный. Затем у вас есть оперативная память, которая быстрее, но меньше по своим возможностям хранения, и, наконец, регистры процессора, которые очень быстрые, но крошечные. Следующая диаграмма демонстрирует проблему с памятью:

Кеш — это компонент, который хранит недавно использованные данные в более быстрой системе хранения. Каждый раз, когда делается запрос на эти данные, они (с некоторой вероятностью) могут быть извлечены из более быстрой памяти. Основное предположение, лежащее в основе кэширования, заключается в том, что недавно прочитанные данные имеют больше шансов на повторное чтение. Таким образом, они должны храниться в более быстрой памяти, чтобы даже следующее чтение было быстрее.
Чтобы лучше понять эту концепцию, подумайте о группе людей, сидящих в библиотеке. Сама библиотека представляет собой огромную систему хранения, но там трудно найти некоторые книги. В нашем воображении библиотека представляет собой большой и медленный механизм хранения. Предположим, что эти люди, когда бы они ни находили книгу, читают ее, но не возвращают ее, так как они предпочитают держать ее на своих столах. У них такое поведение, потому что они уверены, что скоро они снова понадобятся, и имеет смысл держать эту книгу на столе, где она более доступна. В этом примере библиотека является основной системой хранения, а таблица — нашим кешем.
В этом руководстве мы создадим веб-сервис, который мы назовем «fastLibrary». Здесь мы реализуем концепцию кэширования для виртуальной библиотеки. MongoDB будет основной системой хранения, и мы создадим кеш с помощью Redis . Наш веб-сервер будет работать с Express.js . Если вы не знакомы с какой-либо из этих технологий, я рекомендую углубить эти темы перед началом обучения. Для наших целей я предлагаю вам прочитать эти статьи, опубликованные на SitePoint:
Основная система
В качестве первого шага мы создадим базовый веб-сервер, который хранит данные в MongoDB. Для этой демонстрации мы назовем ее «fastLibrary». Сервер будет иметь две основные операции:
- POST /book : эта конечная точка получит название, автора и содержание книги, а также создаст запись в базе данных.
- GET /book/:title : эта конечная точка получает заголовок и возвращает его содержимое. Мы предполагаем, что названия однозначно идентифицируют книги (таким образом, не будет двух книг с одинаковым названием). Конечно, лучшей альтернативой будет использование идентификатора. Однако для простоты мы просто будем использовать заголовок.
Это простая библиотечная система, но мы добавим более продвинутые возможности позже.
Теперь давайте создадим каталог, в котором будет жить приложение:
В этом руководстве предполагается, что у вас установлены Node.js и npm . Если вам нужно узнать, как их установить, вы можете взглянуть на этот ресурс .
Первый шаг — ввести следующую команду и ответить на вопросы, чтобы создать первоначальную структуру вашего нового проекта:
Затем мы должны установить Express и драйвер MongoDB и сохранить их как зависимости:
Теперь пришло время создать основной файл с именем index.js . Это файл, в котором мы будем выполнять большую часть нашей работы. Начните с создания простого приложения, подключив его к MongoDB и прослушивая порт 8000:
Убедитесь, что на вашем компьютере установлен MongoDB. Вы можете использовать следующую команду, чтобы запустить его:
После этого мы реализуем функцию, которая позволит сохранять текст для определенного ключа в базе данных. Функция просто возьмет ключ и текст и сохранит его в базе данных. Мы упаковываем функции MongoDB, чтобы позже добавить логику кеширования. Все функции базы данных будут храниться как отдельный модуль в файле с именем access.js :
Аналогично, мы реализуем функцию findText :
На данный момент мы можем поместить весь код в фактические конечные точки:
Добавление кеша
Пока что мы создали базовый библиотечный веб-сервис, но он не удивительно быстр. В этом разделе мы попытаемся оптимизировать findBookByTitle() результаты.
Чтобы лучше понять, как мы достигнем этой цели, давайте вернемся к нашему примеру людей, сидящих в традиционной библиотеке. Допустим, они хотят найти книгу с определенным названием. Прежде всего, они осмотрят стол, чтобы увидеть, принесли ли они его туда. Если они есть, это здорово! У них только что был кеш- поиск, то есть поиск элемента в кеше. Если они не нашли его, у них была ошибка в кэше , то есть они не нашли элемент в кэше. В случае отсутствия предмета им придется искать книгу в библиотеке. Когда они его найдут, они сохранят его на своем столе или вставят в кеш.
В нашем уроке мы будем использовать точно такой же алгоритм для функции findBookByTitle() . Когда спросят книгу с определенным названием, мы будем искать ее в кеше. Если не найден, мы будем искать его в главном хранилище, то есть в нашей базе данных MongoDB.
Изменений в функции saveBook() как она не влияет на кеш. Нам нужно изменить findBookByTitle() , который будет иметь следующий поток:
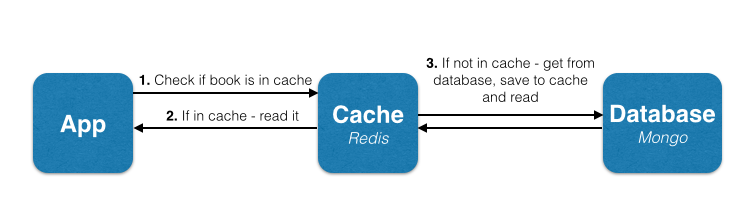
Прежде всего, мы должны установить клиент Node.js Redis. Это можно сделать через npm:
Если вам нужно установить Redis, вы можете узнать, как это сделать здесь . После этого запустите Redis локально на своей машине:
Теперь в верхней части файла index.js требуется и инициализируется клиент Redis:
Давайте теперь напишем функцию access.findBookByTitleCached() которая будет улучшенной версией того, что мы создали ранее. Функция будет следовать точной логике, которую мы только что ввели. Мы будем хранить данные каждой книги в базе данных Redis, и, когда мы запрашиваем книги по их названиям, мы будем использовать название каждой книги в качестве ключа к ее данным.
Мы также должны обновить конечную точку, чтобы вызвать соответствующую функцию:
Политика кэширования
Мы создали базовую систему, которая работает с Redis для кэширования всех результатов запроса из базы данных. Тем не менее, мы должны признать, что это не умная система. Он просто сохраняет каждый результат в кэш Redis и сохраняет его там. Таким образом, кэш будет медленно перегружать оперативную память компьютера, пока не заполнится.
Из-за этого ограничения памяти мы должны удалить некоторые элементы в кеше и сохранить только некоторые из них. В идеале, мы бы хотели, чтобы те, у кого больше шансов, могли только читать снова. Чтобы выбрать элементы, которые мы хотим удалить, мы должны установить своего рода политику кэширования. Удаление случайных элементов, вероятно, будет правильной политикой, но, очевидно, это будет не очень эффективно. Мы будем использовать одну из самых популярных политик: LRU (наименее недавно использованные). Эта политика удаляет элементы кэша, которые были (как следует из названия) наименее использованными в последнее время.
К счастью для нас, в Redis реализован механизм LRU, поэтому нам не нужно беспокоиться о нем на уровне приложений. Для этого все, что нам нужно сделать, это настроить Redis для удаления элементов в режиме LRU. Для этого мы добавим два аргумента в команду запуска Redis. Первый ограничит объем памяти, который он может использовать (в этом примере мы выбрали 512 МБ), а второй скажет ему использовать политику LRU. Команда будет выглядеть так:
Обновление кеша
Одной из проблем, возникающих при кэшировании, является поддержание актуальности кэша при изменении данных. Например, давайте создадим конечную точку PUT /book/:title которая позволит нам обновить текст определенной книги. Для этого мы реализуем функцию access.updateBookByTitle(title) .
Естественно было бы просто обновить запись в основной базе данных, содержащей эту книгу. Но что, если предмет находится в кеше? В этом случае при следующем чтении мы получим попадание в кеш и прочитаем элемент из кеша. Но этот пункт будет не обновленной версией книги, что означает, что пользователь может не получить ее последнюю версию. Не все системы могут допустить эту неточность. Таким образом, мы обновим кеш новыми, обновленными данными.
В этом случае реализация функции обновления будет следующей:
И мы добавим соответствующую конечную точку:
Другой сценарий, на который стоит обратить внимание, заключается в следующем: у вас есть несколько отдельных кэшей для одной и той же базы данных. Это может произойти, например, когда у вас есть одна основная база данных и несколько компьютеров, на которых запущено приложение. Было бы здорово иметь кеш для каждой машины, так как это может предотвратить огромный трафик данных назад и вперед в базу данных. В этом случае необходимо будет создать механизм, обеспечивающий, чтобы обновления с одного компьютера влияли на все кэши. К сожалению, углубление этого сценария выходит за рамки данного руководства, но мы, вероятно, предложим несколько умных решений для решения проблемы, которую я поднял в одной из следующих статей.
метрика
Теперь, когда у нас есть хорошее работающее кэшированное приложение, пришло время насладиться плодами нашей работы и протестировать производительность нашего приложения. Для этого теста мы сначала вставили 1000 книг в библиотеку, а затем прочитали их случайным образом. Теперь мы измерим, как быстро время отклика сервера в кэшированном приложении по сравнению с некэшированным. В конце теста, это результаты. Я положил их в график:
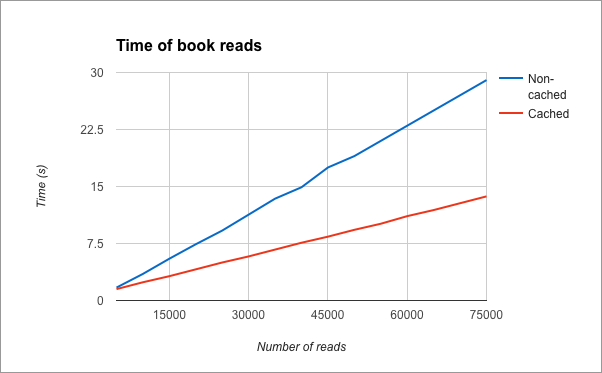
Выводы
В этом уроке я показал, как ускорить веб-сервер, подключенный к базе данных, путем кэширования данных, к которым он обращается. Хотя в этом руководстве используется Redis в качестве кэша, для этой цели можно использовать другие хранилища значений ключей. Примером другой популярной базы данных является Memcached . Я выбрал Redis в основном из-за его популярности, подробной документации и простоты использования.
Хотя кэширование значительно повышает производительность, оно подходит не для всех приложений. Вот некоторые соображения, о которых вы можете подумать, думая о кэшировании:
- Влияет ли чтение базы данных на ваши выступления? Вы должны сделать несколько тестов и посмотреть, если это ваша настоящая проблема
- Вы используете много разных ключей для запросов? В основной базе данных многие параметры могут использоваться для запроса коллекции. В кеше для запросов можно использовать только один ключ (либо один параметр, либо набор параметров). Кэширование всех возможных ключей может быть вредным. Попробуйте подумать, какие запросы используются чаще всего, и их следует кэшировать.
- Ваше приложение выполняет много обновлений базы данных? Хотя кэширование ускоряет чтение, оно также замедляет запись.
- Вы пытаетесь кешировать сложные запросы? Сложные запросы будут сложнее и менее эффективны для кеширования.
Наконец, стоит помнить эту идиому:
Преждевременная оптимизация является источником всего зла.
Это должно напомнить вам, что оптимизации имеют свое время и место. Надеюсь, вам понравился этот урок, и я с нетерпением жду ваших мыслей и комментариев.



