Что каждый программист должен знать о памяти.
Часть 4: Поддержка устройств NUMA
Прим.ред.: Напомним, что NUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется её расположением по отношению к процессору.
В разделе 2 мы видели, что на некоторых машинах, стоимость доступа к конкретным областям физической памяти различается в зависимости от того, откуда происходит доступ. Для этого типа устройств требуется особое внимание со стороны операционной системы и приложений. Мы начнем с некоторых особенностей устройств NUMA, а затем рассмотрим некоторые средства поддержки, предлагаемые в ядре Linux для устройств NUMA.
5.1 Аппаратные устройства NUMA
Использование архитектуры с неравномерным доступом к памяти становятся все более и более распространенным явлением. В простейшем случае архитектуры NUMA процессор может иметь локальную память (смотрите рис.2.3), доступ к которой дешевле, чем доступ к этой локальной памяти из других процессоров. Различие в стоимости для данного типа системы NUMA невысокая, то есть показатель NUMA является низким.
Архитектура NUMA используется также, и в особенности, в больших машинах. Мы описали проблемы получения доступа к одной и той же памяти из различных процессоров. С точки зрения аппаратных средств, все процессоры будут использовать один и тот же северный мост (без учета на данный момент узлов NUMA для машин AMD Opteron, у которых есть свои собственные проблемы). Это делает северный мост одним из самых узких мест, поскольку весь трафик с памятью проходит через него. В больших машинах можно, конечно, вместо северного моста использовать специальные аппаратные средства, но, если используемые чипы памяти не имеют несколько портов, то есть они не могут использоваться из нескольких шин, то узкие места все еще остаются. Многопортовая память является сложной и дорогой для производства и эксплуатации и, поэтому, почти не используется.
Следующим шагом по сложности является использование модели AMD, в которой механизм взаимодействия (Hypertransport, в случае AMD, технология, лицензированная фирмой Digital) предоставляет доступ процессорам, которые не имеют непосредственного доступа к памяти. Для того, чтобы диаметр (т.е., максимальное расстояние между любыми двумя узлами) не увеличивался произвольным образом, размер структур, которые могут формироваться таким образом, должен быть ограничен.
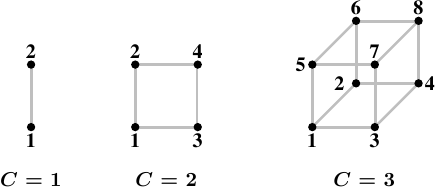
Рис 5.1: Гиперкубы
Наилучшей топологией для узлов является гиперкуб, в котором количество узлов ограничено 2 C , где С — количество интерфейсов взаимных соединений, которое есть в каждом узле. Гиперкубы для всех систем с числом процессоров, равным 2n, имеют маленький диаметр. На рис.5.1 показаны первые три гиперкуба. Каждый гиперкуб имеет диаметр С, что является абсолютным минимумом. В первом поколении процессоров Opteron фирмы AMD было по три гипертранспортных соединения на процессор. По крайней мере, к одному из соединений должен быть подключен южный мост, а это означает, что в настоящее время эффективно и без всяких ухищрений можно реализовать гиперкуб с C = 2. Объявлено, что в следующем поколении соединений будет четыре, благодаря чему удастся реализовать гиперкуб с C = 3.
Однако, это не означает, что нельзя поддерживать работу большего количества процессоров. Есть компании, которые разработали сборки, позволяющие использовать наборы с большим количеством процессоров (например, Horus фирмы Newisys). Но эти сборки имеют большой показатель NUMA и при определенном количестве процессоров они становятся неэффективными.
Следующий шаг состоит в подключении групп процессоров и реализация совместно используемой памяти для каждого процессора из группы. Для всех таких систем требуются специализированные аппаратные средства и такие системы не являются изделиями широкого спроса. Такие конструкции имеют несколько уровней сложности. Системой, которая все еще достаточно похожа на машину широкого спроса, является машина IBM X445 и аналогичные машины. Их можно купить как обычные машины, имеющие размер 4U, 8 каналов и процессорами x86 и x86-64. Две такие машины (а с некоторого момента и четыре такие машины) можно объединить для работы в виде одной машины с совместно используемой памятью. Используемые соединения имеют большой показатель NUMA, что должно учитываться как операционной системой, так и приложением.
На другом конце спектра находятся машины, такие как Altix фирмы SGI, которые специально предназначены для подключения друг к другу. Механизм соединения NUMA, реализованный SGI, очень быстрый и имеет более низкую латентность; оба этих свойства очень важны при высокопроизводительных вычислениях (high-performance computing — HPC), особенно в случаях, когда используются интерфейсы Message Passing Interfaces (MPI). Недостатком является, конечно, то, что такая сложность и специализация стоят очень дорого. С их помощью можно получить достаточно низкий коэффициент NUMA, но с тем числом процессоров, которые могут быть в этих машинах (а это — несколько тысяч), а также из-за ограниченных возможностей соединений, показатель NUMA фактически является динамическим и, в зависимости от нагрузки, может достичь неприемлемых уровней.
Наиболее часто используются решения, в которых с помощью высокоскоростных соединений создается кластер из широко распространенных машин. Но они не являются системами NUMA, у них нет общего адресного пространства и, следовательно, они не попадают в какую-нибудь из категорий, которые здесь обсуждаются.
Источник
What is NUMA?В¶
This question can be answered from a couple of perspectives: the hardware view and the Linux software view.
From the hardware perspective, a NUMA system is a computer platform that comprises multiple components or assemblies each of which may contain 0 or more CPUs, local memory, and/or IO buses. For brevity and to disambiguate the hardware view of these physical components/assemblies from the software abstraction thereof, we’ll call the components/assemblies вЂcells’ in this document.
Each of the вЂcells’ may be viewed as an SMP [symmetric multi-processor] subset of the system–although some components necessary for a stand-alone SMP system may not be populated on any given cell. The cells of the NUMA system are connected together with some sort of system interconnect–e.g., a crossbar or point-to-point link are common types of NUMA system interconnects. Both of these types of interconnects can be aggregated to create NUMA platforms with cells at multiple distances from other cells.
For Linux, the NUMA platforms of interest are primarily what is known as Cache Coherent NUMA or ccNUMA systems. With ccNUMA systems, all memory is visible to and accessible from any CPU attached to any cell and cache coherency is handled in hardware by the processor caches and/or the system interconnect.
Memory access time and effective memory bandwidth varies depending on how far away the cell containing the CPU or IO bus making the memory access is from the cell containing the target memory. For example, access to memory by CPUs attached to the same cell will experience faster access times and higher bandwidths than accesses to memory on other, remote cells. NUMA platforms can have cells at multiple remote distances from any given cell.
Platform vendors don’t build NUMA systems just to make software developers’ lives interesting. Rather, this architecture is a means to provide scalable memory bandwidth. However, to achieve scalable memory bandwidth, system and application software must arrange for a large majority of the memory references [cache misses] to be to “local” memory–memory on the same cell, if any–or to the closest cell with memory.
This leads to the Linux software view of a NUMA system:
Linux divides the system’s hardware resources into multiple software abstractions called “nodes”. Linux maps the nodes onto the physical cells of the hardware platform, abstracting away some of the details for some architectures. As with physical cells, software nodes may contain 0 or more CPUs, memory and/or IO buses. And, again, memory accesses to memory on “closer” nodes–nodes that map to closer cells–will generally experience faster access times and higher effective bandwidth than accesses to more remote cells.
For some architectures, such as x86, Linux will “hide” any node representing a physical cell that has no memory attached, and reassign any CPUs attached to that cell to a node representing a cell that does have memory. Thus, on these architectures, one cannot assume that all CPUs that Linux associates with a given node will see the same local memory access times and bandwidth.
In addition, for some architectures, again x86 is an example, Linux supports the emulation of additional nodes. For NUMA emulation, linux will carve up the existing nodes–or the system memory for non-NUMA platforms–into multiple nodes. Each emulated node will manage a fraction of the underlying cells’ physical memory. NUMA emluation is useful for testing NUMA kernel and application features on non-NUMA platforms, and as a sort of memory resource management mechanism when used together with cpusets. [see CPUSETS ]
For each node with memory, Linux constructs an independent memory management subsystem, complete with its own free page lists, in-use page lists, usage statistics and locks to mediate access. In addition, Linux constructs for each memory zone [one or more of DMA, DMA32, NORMAL, HIGH_MEMORY, MOVABLE], an ordered “zonelist”. A zonelist specifies the zones/nodes to visit when a selected zone/node cannot satisfy the allocation request. This situation, when a zone has no available memory to satisfy a request, is called “overflow” or “fallback”.
Because some nodes contain multiple zones containing different types of memory, Linux must decide whether to order the zonelists such that allocations fall back to the same zone type on a different node, or to a different zone type on the same node. This is an important consideration because some zones, such as DMA or DMA32, represent relatively scarce resources. Linux chooses a default Node ordered zonelist. This means it tries to fallback to other zones from the same node before using remote nodes which are ordered by NUMA distance.
By default, Linux will attempt to satisfy memory allocation requests from the node to which the CPU that executes the request is assigned. Specifically, Linux will attempt to allocate from the first node in the appropriate zonelist for the node where the request originates. This is called “local allocation.” If the “local” node cannot satisfy the request, the kernel will examine other nodes’ zones in the selected zonelist looking for the first zone in the list that can satisfy the request.
Local allocation will tend to keep subsequent access to the allocated memory “local” to the underlying physical resources and off the system interconnect– as long as the task on whose behalf the kernel allocated some memory does not later migrate away from that memory. The Linux scheduler is aware of the NUMA topology of the platform–embodied in the “scheduling domains” data structures [see Scheduler Domains ]–and the scheduler attempts to minimize task migration to distant scheduling domains. However, the scheduler does not take a task’s NUMA footprint into account directly. Thus, under sufficient imbalance, tasks can migrate between nodes, remote from their initial node and kernel data structures.
System administrators can restrict the CPUs and nodes’ memories that a non- privileged user can specify in the scheduling or NUMA commands and functions using control groups and CPUsets. [see CPUSETS ]
On architectures that do not hide memoryless nodes, Linux will include only zones [nodes] with memory in the zonelists. This means that for a memoryless node the “local memory node”–the node of the first zone in CPU’s node’s zonelist–will not be the node itself. Rather, it will be the node that the kernel selected as the nearest node with memory when it built the zonelists. So, default, local allocations will succeed with the kernel supplying the closest available memory. This is a consequence of the same mechanism that allows such allocations to fallback to other nearby nodes when a node that does contain memory overflows.
Some kernel allocations do not want or cannot tolerate this allocation fallback behavior. Rather they want to be sure they get memory from the specified node or get notified that the node has no free memory. This is usually the case when a subsystem allocates per CPU memory resources, for example.
A typical model for making such an allocation is to obtain the node id of the node to which the “current CPU” is attached using one of the kernel’s numa_node_id() or CPU_to_node() functions and then request memory from only the node id returned. When such an allocation fails, the requesting subsystem may revert to its own fallback path. The slab kernel memory allocator is an example of this. Or, the subsystem may choose to disable or not to enable itself on allocation failure. The kernel profiling subsystem is an example of this.
If the architecture supports–does not hide–memoryless nodes, then CPUs attached to memoryless nodes would always incur the fallback path overhead or some subsystems would fail to initialize if they attempted to allocated memory exclusively from a node without memory. To support such architectures transparently, kernel subsystems can use the numa_mem_id() or cpu_to_mem() function to locate the “local memory node” for the calling or specified CPU. Again, this is the same node from which default, local page allocations will be attempted.
© Copyright The kernel development community.
Источник
О правильном использовании памяти в NUMA-системах под управлением ОС Linux
Недавно в нашем блоге появилась статья о NUMA-системах, и я хотел бы продолжить тему, поделившись своим опытом работы в Linux. Сегодня я расскажу о том, что бывает, если неправильно использовать память в NUMA и как диагностировать такую проблему с помощью счётчиков производительности.
Итак, начнем с простого примера:

Это простой тест, который в цикле суммирует элементы массива. Запустим его в несколько потоков на двухсокетном сервере, у которого в каждый сокет установлен четырехядерный процессор. Ниже приведен график, на котором мы видим времена выполнения программы в зависимости от числа потоков:
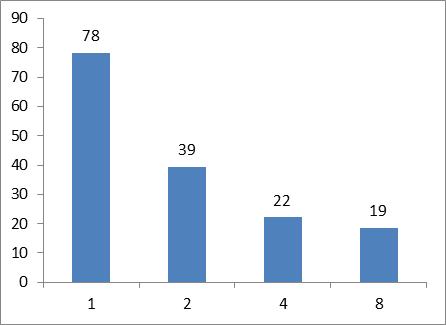
Мы видим, что время выполнения на восьми потоках всего в 1.16 раза короче чем на четырех потоках, хотя при переходе с двух на четыре потока прирост производительности заметно выше. Теперь сделаем простую трансформацию кода: добавим директиву распараллеливания перед инициализацией массива:

И соберем еще раз времена выполнения:
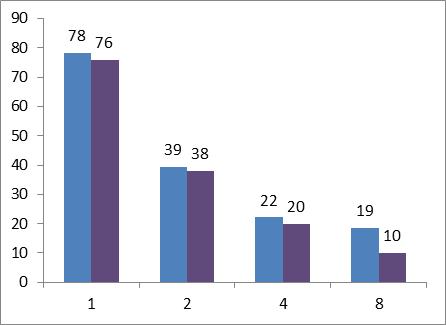
И вот, на восьми потоках произошло улучшение производительности почти в 2 раза. Таким образом, наше приложение практически линейно масштабируется на всём диапазоне потоков.
Итак, давайте разберемся, что же произошло? Каким образом простое распараллеливание цикла инициализации привело к почти двукратному приросту? Рассмотрим устройство двухпроцессорного сервера с поддержкой NUMA:

За каждым четырёхядерным процессором закреплен определенный объем физической памяти, с которым он общается через интегрированный контроллер памяти и шину данных. Такая связка процессор + память называется узел или нода (node). В NUMA-системах (Non Uniform Memory Access) доступ в память чужой ноды занимает намного больше времени, чем доступ в память своей ноды. Когда приложение в первый раз обращается к памяти, то происходит закрепление виртуальных страниц памяти за физическими. Но в NUMA-системах под управлением ОС Linux у этого процесса есть своя специфика: физические страницы, за которыми будут закреплены виртуальные, выделяются на той ноде, с которой произошло первое обращение. Это так называемый “first-touch policy”. Т.е. если с первой ноды произошло обращение к какой либо памяти, то виртуальные страницы этой памяти будут отображаться на физические, которые тоже будут выделены на первой ноде. Поэтому здесь важно правильно инициализировать данные, ведь от того как данные закрепятся за нодами будет зависеть производительность приложения. Если говорить о первом примере, то весь массив был проинициализирован на одной ноде, что привело к закреплению всех данных за первой нодой, после чего половина этого массива была считана другой нодой, а это и привело к ухудшению производительности.
Внимательный читатель должен был уже задаться вопросом «А разве выделение памяти через malloc не является первым доступом?». Конкретно в этом случае – нет. Дело вот в чем: при выделении больших блоков памяти в Linux, функция glibc malloc (а также calloc и realloc) по умолчанию вызывает сервисную функцию ядра mmap. Эта сервисная функция делает лишь отметки о количестве выделенной памяти, но физическое выделение происходит только при первом доступе к ним. Этот механизм реализуется через прерывания (exceptions) Page-Fault и Copy-On-Write, а также через маппирование на «нулевую» страницу (“zero” page). Кому интересны детали, могут почитать книгу «Understanding the Linux Kernel». А вообще, возможна ситуация, когда функция glibc calloc выполнит первый доступ к памяти для того, чтобы её «занулить». Но опять же, такое произойдет, если calloc решит вернуть пользователю ранее освобожденную память на куче (heap), а такая память уже будет существовать на физических страницах. Поэтому во избежании лишних головоломок рекомендуется использовать так называемые NUMA-aware менеджеры памяти (например TCMalloc), но это уже другая тема.
А теперь давайте ответим на главный вопрос этой статьи: «Как узнать правильно ли приложение работает с памятью в NUMA-системе?». Этот вопрос будет для нас всегда самым первым и главным при адаптации приложений для серверов с поддержкой NUMA, независимо от операционной системы.
Для ответа на этот вопрос нам понадобится VTune Amplifier, который умеет считать события для двух счётчиков производительности (performance counters): OFFCORE_RESPONSE_0.ANY_REQUEST.LOCAL_DRAM и OFFCORE_RESPONSE_0.ANY_REQUEST.REMOTE_DRAM. Первый счётчик считает количество всех запросов, данные для которых были найдены в оперативной памяти своей ноды, а второй – в памяти чужой ноды. Можно на всякий случай еще собрать счётчики для КЭШ’а: OFFCORE_RESPONSE_0.ANY_REQUEST.LOCAL_CACHE и OFFCORE_RESPONSE_0.ANY_REQUEST.REMOTE_CACHE. Вдруг окажется что данные находятся не в памяти, а в КЭШ’е процессора на чужой ноде?
Итак, запустим наше приложение без распараллеливания инициализации на восемь потоков под VTune и посчитаем количество событий для указанных выше счетчиков:
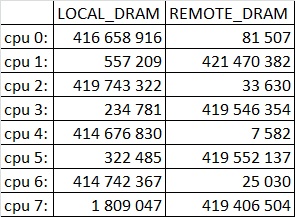
Мы видим, что поток, выполнявшийся на cpu 0, работал в основном со своей нодой. Хотя время от времени модуль vmlinux на этом ядре зачем-то заглядывал в чужие ноды. А вот поток на cpu 1, делал всё наоборот: только для 0.13% всех запросов данные нашлись в его собственной ноде. Здесь я должен пояснить, каким образом ядра закреплены за нодами. Ядра 0,2,4,6 принадлежат первой ноде, а ядра 1,3,5,7 – второй. Топологию можно узнать с помощью утилиты numactl:
numactl —hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6
node 0 size: 12277 MB
node 0 free: 10853 MB
node 1 cpus: 1 3 5 7
node 1 size: 12287 MB
node 1 free: 11386 MB
node distances:
node 0 1
0: 10 20
1: 20 10
Обратите внимание, что здесь перечислены логические номера, в реальности же ядра 0,2,4,6 принадлежат одному четырехядерному процессору, а ядра 1,3,5,7 – другому.
Теперь посмотрим на значение счетчиков для примера с параллельной инициализации:
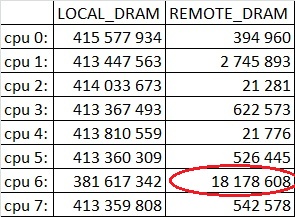
Картина почти идеальная, мы видим, что все ядра работают в основном со своими нодами. Обращения в чужие ноды, составляют не больше полпроцента от всех запросов, за исключением cpu 6. Это ядро примерно 4.5% всех запросов отправляет в чужую ноду. Т.к. обращение в чужую ноду занимает в 2 раза дольше времени чем в свою, то 4.5% таких запросов не сильно ухудшают производительность. Поэтому, можно сказать, что теперь приложение правильно работает с памятью.
Таким образом, используя эти счётчики вы всегда можете определить есть ли возможность ускорить приложение для NUMA-системы. На практике у меня были случаи когда правильная инициализация данных ускоряла приложения в 2 раза, причем в некоторых приложениях приходилось параллелить все циклы, немного ухудшая производительность для обычной SMP-системы.
Для тех, кому интересно, откуда берутся 4.5%, предлагаю пойти дальше. Процессор Nehalem и его потомки имеют богатый набор счётчиков для анализа активности системы памяти. Все эти счётчики начинаются с названия OFFCORE_RESPONSE. Может даже показаться, что их слишком много. Но если посмотреться внимательно, то можно заметить что все они являются комбинациями составных запросов и ответов. Каждый составной запрос или ответ состоит из базовых запросов и ответов, которые задаются битовой маской.
Ниже перечислены значения битовых масок для составных запросов и ответов:
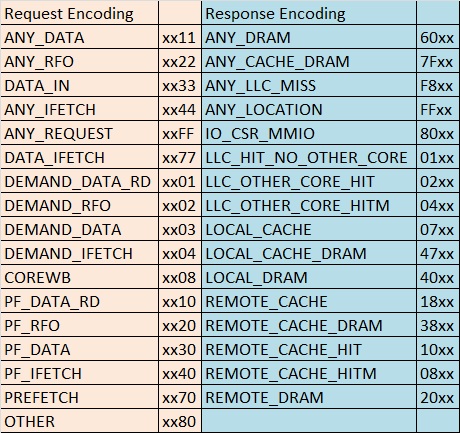
Вот так формируется счётчик OFFCORE_RESPONSE_0 в процессоре Nehalem:

Давайте разберем, например, наш счётчик OFFCORE_RESPONSE_0.ANY_REQUEST.REMOTE_DRAM. Он состоит из составного запроса ANY_REQUEST и составного ответа REMOTE_DRAM. Запрос ANY_REQUEST имеет значение xxFF, что означает отслеживание всех событий: от чтения данных «по требованию» (бит 0, Demand Data Rd в таблице) до префетчеров КЭШ’а инструкций (бит 6, PF Ifetch) и остальной «мелочи» (бит 7, OTHER). Ответ REMOTE_DRAM имеет значение 20xx, что означает отслеживание запросов, данные для которых нашлись только в памяти чужой ноды (бит 13 L3_MISS_REMOTE_DRAM). Всю информацию по этим счётчикам можно найти на сайте intel.com документ «Intel 64 and IA-32 Architectures Optimization Reference Manual», раздел «B.2.3.5 Measuring Core Memory Access Latency».
Для того чтобы понять кто именно отправляет свои запросы в чужую ноду нужно разложить ANY_REQUEST на составные запросы: DEMAND_DATA_RD, DEMAND_RFO, DEMAND_IFETCH, COREWB, PF_DATA_RD, PF_RFO, PF_IFETCH, OTHER и собрать для них события по отдельности. Таким образом «виновник» был найден:
OFFCORE_RESPONSE_0.PREFETCH.REMOTE_DRAM
cpu 0: 6405
cpu 1: 597190
cpu 2: 2503
cpu 3: 229271
cpu 4: 2035
cpu 5: 190549
cpu 6: 19364266
cpu 7: 228027
Но почему prefetcher именно на 6 ядре заглядывал в чужую ноду, в то время как prefetcher’ы остальных ядер работали со своими нодами? Дело в том, что перед запуском примера с параллельной инициализацией, я дополнительно установил жесткую привязку потоков к ядрам следующим образом:
export KMP_AFFINITY=granularity=fine,proclist=[0,2,4,6,1,3,5,7],explicit,verbose
./a.out
OMP: Info #204: KMP_AFFINITY: decoding x2APIC ids.
OMP: Info #202: KMP_AFFINITY: Affinity capable, using global cpuid leaf 11 info
OMP: Info #154: KMP_AFFINITY: Initial OS proc set respected: <0,1,2,3,4,5,6,7>
OMP: Info #156: KMP_AFFINITY: 8 available OS procs
OMP: Info #157: KMP_AFFINITY: Uniform topology
OMP: Info #179: KMP_AFFINITY: 2 packages x 4 cores/pkg x 1 threads/core (8 total cores)
OMP: Info #206: KMP_AFFINITY: OS proc to physical thread map:
OMP: Info #171: KMP_AFFINITY: OS proc 0 maps to package 0 core 0
OMP: Info #171: KMP_AFFINITY: OS proc 4 maps to package 0 core 1
OMP: Info #171: KMP_AFFINITY: OS proc 2 maps to package 0 core 2
OMP: Info #171: KMP_AFFINITY: OS proc 6 maps to package 0 core 3
OMP: Info #171: KMP_AFFINITY: OS proc 1 maps to package 1 core 0
OMP: Info #171: KMP_AFFINITY: OS proc 5 maps to package 1 core 1
OMP: Info #171: KMP_AFFINITY: OS proc 3 maps to package 1 core 2
OMP: Info #171: KMP_AFFINITY: OS proc 7 maps to package 1 core 3
OMP: Info #147: KMP_AFFINITY: Internal thread 0 bound to OS proc set <0>
OMP: Info #147: KMP_AFFINITY: Internal thread 1 bound to OS proc set <2>
OMP: Info #147: KMP_AFFINITY: Internal thread 2 bound to OS proc set <4>
OMP: Info #147: KMP_AFFINITY: Internal thread 3 bound to OS proc set <6>
OMP: Info #147: KMP_AFFINITY: Internal thread 4 bound to OS proc set <1>
OMP: Info #147: KMP_AFFINITY: Internal thread 5 bound to OS proc set <3>
OMP: Info #147: KMP_AFFINITY: Internal thread 6 bound to OS proc set <5>
OMP: Info #147: KMP_AFFINITY: Internal thread 7 bound to OS proc set
Согласно этой привязке первые четыре потока работают на первой ноде, а вторые четыре потока – на второй. Отсюда видно, что 6-ое ядро – это последнее ядро принадлежащее первой ноде (0,2,4,6). Обычно prefetcher всегда пытается закачать память с упреждением, которая находится далеко впереди (или позади, зависит от направления, в котором программа обращается к памяти). В нашем случае prefetcher шестого ядра закачивал память, которая находилась впереди той, с которой в тот момент работал поток Internal thread 3. Вот здесь то и произошло обращение в чужую ноду, так как впереди стоящая память частично принадлежала первому ядру чужой ноды (1,3,5,7). А это и привело к появлению 4.5% обращений в чужую ноду.
Замечание: тестовая программа была собрана компилятором Intel с опцией –no-vec, чтобы получить скалярный код вместо векторного. Это было сделано с целью получения «красивых данных» для облегчения понимания теории.
Источник



