- Solid state drive/NVMe
- Contents
- Installation
- Management
- SMART
- Secure erase
- Firmware update
- Generic
- Intel
- Kingston
- Performance
- Sector size
- Discards
- Airflow
- Testing
- Power Saving (APST)
- Troubleshooting
- Controller failure due to broken APST support
- SPDK: ускорение работы с NVMe-дисками
- Зачем нужен NVMe-драйвер, работающий в пользовательском пространстве Linux?
- Предварительные требования и сборка SPDK
- ▍Сборка DPDK (для Linux)
- ▍Сборка SPDK (для Linux)
- ▍Настройка системы перед запуском SPDK-приложения
- Приложение-пример «Hello World»
- ▍Настройка
- ▍Чтение/запись данных
- Другие примеры, включённые в SPDK
- Выводы
Solid state drive/NVMe
NVM Express (NVMe) is a specification for accessing SSDs attached through the PCI Express bus. As a logical device interface, NVM Express has been designed from the ground up, capitalizing on the low latency and parallelism of PCI Express SSDs, and mirroring the parallelism of contemporary CPUs, platforms and applications.
Contents
Installation
The Linux NVMe driver is natively included in the kernel since version 3.3. NVMe devices should show up under /dev/nvme* .
Extra userspace NVMe tools can be found in nvme-cli or nvme-cli-git AUR .
See Solid State Drives for supported filesystems, maximizing performance, minimizing disk reads/writes, etc.
Management
List all the NVMe SSDs attached with name, serial number, size, LBA format and serial:
List information about a drive and features it supports in a human-friendly way:
List information about a namespace and features it supports:
Output the NVMe error log page:
Delete a namespace:
Create a new namespace, e.g creating a smaller size namespace to overprovision an SSD for improved endurance, performance, and latency:
See nvme help and nvme(1) for a list of all commands along with a terse description.
SMART
Output the NVMe SMART log page for health status, temp, endurance, and more:
NVMe support was added to smartmontools in version 6.5 (available since May 2016 in the official repositories).
Currently implemented features (as taken from the wiki):
- Basic information about controller name, firmware, capacity ( smartctl -i )
- Controller and namespace capabilities ( smartctl -c )
- SMART overall-health self-assessment test result and warnings ( smartctl -H )
- NVMe SMART attributes ( smartctl -A )
- NVMe error log ( smartctl -l error[,NUM] )
- Ability to fetch any nvme log ( smartctl -l nvmelog,N,SIZE )
- The smartd daemon tracks health ( -H ), error count ( -l error ) and temperature ( -W DIFF,INFO,CRIT )
See S.M.A.R.T. and the official wiki entry for more information, and see this article for contextual information about the output.
Secure erase
Firmware update
Generic
Firmware can be managed using nvme-cli . To display available slots and check whether Slot 1 is read only:
Download and commit firmware to specified slot. In the example below, firmware is first committed without activation ( -a 0 ). Next, an existing image is activated ( -a 2 ). Refer to the NVMe specification for details on firmware commit action values.
Finally reset the controller to load the new firmware
Intel
«The Intel® Memory and Storage Tool (Intel® MAS) is a drive management tool for Intel® SSDs and Intel® Optane™ Memory devices, supported on Windows*, Linux*, and ESXi*. [. ] Use this tool to manage PCIe*-/NVMe*- and SATA-based Client and Datacenter Intel® SSD devices and update to the latest firmware.»[2]
Install intel-mas-cli-tool AUR and check whether your drive has an update available:
If so, execute the load command as follows:
Kingston
Kingston does not provide separate firmware downloads on their website, instead referring users to a Windows only utility. Firmware files appear to use a predictable naming scheme based on the firmware revision:
Performance
Sector size
Discards
Discards are disabled by default on typical setups that use ext4 and LVM, but other file systems might need discards to be disabled explicitly.
Intel, as one device manufacturer, recommends not to enable discards at the file system level, but suggests the periodic TRIM method, or apply fstrim manually.[3]
Airflow
NVMe SSDs are known to be affected by high operating temperatures and will throttle performance over certain thresholds.[4]
Testing
Raw device performance tests can be run with hdparm :
Power Saving (APST)
To check NVMe power states, install nvme-cli or nvme-cli-git AUR , and run nvme get-feature /dev/nvme7 -f 0x0c -H :
When APST is enabled the output should contain «Autonomous Power State Transition Enable (APSTE): Enabled» and there should be non-zero entries in the table below indicating the idle time before transitioning into each of the available states.
If APST is enabled but no non-zero states appear in the table, the latencies might be too high for any states to be enabled by default. The output of nvme id-ctrl /dev/nvme2 (as the root user) should show the available non-operational power states of the NVME controller. If the total latency of any state (enlat + xlat) is greater than 25000 (25ms) you must pass a value at least that high as parameter default_ps_max_latency_us for the nvme_core kernel module. This should enable APST and make the table in nvme get-feature (as the root user) show the entries.
Troubleshooting
Controller failure due to broken APST support
Some NVMe devices may exhibit issues related to power saving (APST). This is a known issue for Kingston A2000 [5] as of firmware S5Z42105 and has previously been reported on Samsung NVMe drives (Linux v4.10) [6][7]
A failure renders the device unusable until system reset, with kernel logs similar to:
As a workaround, add the kernel parameter nvme_core.default_ps_max_latency_us=0 to completely disable APST, or set a custom threshold to disable specific states.
 This article or section is out of date.
This article or section is out of date.
Источник
SPDK: ускорение работы с NVMe-дисками
SPDK (Storage Performance Developer Kit) – это набор инструментов и библиотек с открытым исходным кодом, которые призваны содействовать разработке высокопроизводительных масштабируемых приложений, ориентированных на взаимодействие с дисковыми накопителями. В этом материале мы сосредоточимся на имеющемся в SPDK NVMe-драйвере, работающем в пользовательском пространстве Linux, а также рассмотрим реализацию приложения-примера «Hello World» на платформе Intel.

В наших экспериментах задействован сервер на чипсете Intel C610 (степпинг C1, системная шина QPI, 9.6 ГТ/с) с двумя сокетами, в котором установлены 12-ядерные процессоры Intel Xeon E5-2697 (тактовая частота – 2.7 ГГц, 24 логических ядра в режиме HT). Конфигурация ОЗУ – 8×8 Гб (Samsung M393B1G73BH0 DDR3 1866). В системе имеется твердотельный накопитель Intel SSD DC P3700 Series. В качестве ОС использована CentOS 7.2.1511 (ядро 3.10.0).
Зачем нужен NVMe-драйвер, работающий в пользовательском пространстве Linux?
Исторически сложилось так, что дисковые накопители на порядки медленнее других компонентов компьютерных систем, таких, как оперативная память и процессор. Это означает, что операционная система и процессор вынуждены взаимодействовать с дисками, используя механизм прерываний. Например, сеанс подобного взаимодействия может выглядеть так:
- Выполняется запрос к ОС на чтение данных с диска.
- Драйвер обрабатывает этот запрос и связывается с аппаратным обеспечением.
- Пластина диска раскручивается.
- Головка чтения-записи перемещается к нужному участку пластины, готовясь начать считывать данные.
- Данные считываются и записываются в буфер.
- Генерируется прерывание, которое уведомляет процессор о том, что данные готовы к использованию в системе.
- И, наконец, производится чтение данных из буфера.
Модель прерываний создаёт дополнительную нагрузку на систему. Однако обычно эта нагрузка была значительно меньше, чем задержки, характерные для обычных жёстких дисков. В результате на эту дополнительную нагрузку не обращали особого внимания, так как она не могла заметно снизить эффективность работы подсистем хранения данных.
В наши дни SSD-диски и технологии следующего поколения, например, хранилища 3D XPoint, работают значительно быстрее традиционных HDD. В результате узкое место подсистем хранения данных, которым раньше являлось аппаратное обеспечение, переместилось в сферу программных механизмов. Теперь, как можно видеть на нижеприведённом рисунке, задержки, которые вносят в процесс работы с накопителями прерывания и операционная система, в сравнении со скоростью отклика накопителей, выглядят весьма значительными.
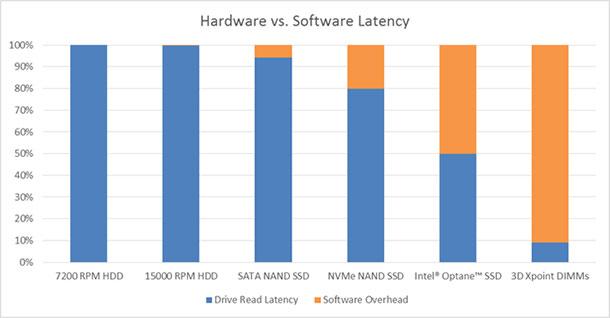
SSD-накопители и системы хранения данных на базе технологии 3D XPoint работают значительно быстрее чем традиционные HDD. В результате теперь узким местом подсистем хранения данных стало ПО
Драйвер NVMe, который работает в пользовательском пространстве Linux, решает «проблему прерываний». Вместо ожидания сообщения о завершении операции, он опрашивает устройство хранения данных в ходе чтения или записи. Кроме того, и это очень важно, драйвер NVMe работает внутри пользовательского пространства. Это значит, что приложения могут напрямую взаимодействовать с NVMe-устройством, минуя ядро Linux. Одно из преимуществ такого подхода – избавление от системных вызовов, требующих переключения контекста. Это приводит к дополнительной нагрузке на систему. Архитектура NVMe не предусматривает блокировок, это направлено на то, чтобы не использовать механизмы процессора для синхронизации данных между потоками. Тот же подход предусматривает и параллельное исполнение команд ввода-вывода.
Сравнивая NVMe-драйвер пользовательского пространства из SPDK с подходом, предусматривающим использование ядра Linux, можно обнаружить, что при использовании NVMe-драйвера задержки, вызванные дополнительной нагрузкой на систему, снижаются примерно в 10 раз.

Задержки, в наносекундах, вызываемые при использовании для работы с накопителями механизмов ядра Linux и SPDK
SPDK может, используя одно ядро процессора, обслуживать 8 твердотельных накопителей NVMe, что даёт более 3.5 миллиона IOPs.

Изменение производительности операций ввода-вывода при работе с разным количеством SSD-накопителей с помощью механизмов уровня ядра Linux и SPDK
Предварительные требования и сборка SPDK
SPDK поддерживает работу в таких ОС, как Fedora, CentOS, Ubuntu, Debian, FreeBSD. Полный список пакетов, необходимых для работы SPDK, можно найти здесь.
Прежде чем собирать SPDK, необходимо установить DPDK (Data Plane Development Kit), так как SPDK полагается на возможности по управлению памятью и по работе с очередями, которые уже есть в DPDK. DPDK – зрелая библиотека, которую обычно используют для обработки сетевых пакетов. Она отлично оптимизирована для управления памятью и быстрой работы с очередями данных.
Исходный код SPDK можно клонировать из GitHub-репозитория такой командой:
▍Сборка DPDK (для Linux)
▍Сборка SPDK (для Linux)
После того, как собранный DPDK находится в папке SPDK, нам нужно вернуться к этой директории и собрать SPDK, передав make путь к DPDK.
▍Настройка системы перед запуском SPDK-приложения
Нижеприведённая команда позволяет включить использование больших страниц памяти (hugepages) и отвязать от драйверов ядра любые NVMe и I/OAT-устройства.
Использование больших страниц важно для производительности, так как они имеют размер 2 Мб. Это гораздо больше, чем стандартные страницы по 4 Кб. Благодаря увеличенному размеру страниц памяти уменьшается вероятность промаха в буфере ассоциативной трансляции (Translate Lookaside Buffer, TLB). TLB – это компонент внутри процессора, который отвечает за трансляцию виртуальных адресов в физические адреса памяти. Таким образом, работа со страницами большого размера ведёт к более эффективному использованию TLB.
Приложение-пример «Hello World»
В SPDK включено множество примеров, имеется здесь и качественная документация. Всё это позволяет быстро начать работу. Мы рассмотрим пример, в котором фразу «Hello World» сначала сохраняют на NVMe-устройстве, а потом считывают обратно в буфер.
Прежде чем заняться кодом, стоит поговорить о том, как структурированы NVMe-устройства и привести пример того, как NVMe-драйвер будет использовать эти сведения для обнаружения устройств, записи данных и затем их чтения.
NVMe-устройство (называемое так же NVMe-контроллером) структурировано исходя из следующих соображений:
- В системе может присутствовать одно или несколько NVMe-устройств.
- Каждое NVMe-устройство состоит из некоторого количества пространств имён (оно может быть только одно в данном случае).
- Каждое пространство имён состоит из некоторого количества адресов логических блоков (Logical Block Addresses, LBA).
Теперь приступим к нашему пошаговому примеру.
▍Настройка
- Инициализируем слой абстракции окружения DPDK (Environment Abstraction Layer, EAL). В коде, приведённом ниже, -c – это битовая маска, которая служит для выбора ядер, на которых будет исполняться код. –n – это ID ядра, а —proc-type – это директория, где будет смонтирована файловая система hugetlbfs.
Создадим пул буфера запроса, который используется внутри SPDK для хранения данных каждого запроса ввода-вывода.
Проверим систему на наличие NVMe-устройств.
Перечислим NVMe-устройства, возвращая SPDK логическое значение, указывающее на то, нужно ли присоединить устройство.
Устройство присоединено. Теперь можно запросить данные о количестве пространств имён.
Перечислим пространства имён для того, чтобы получить сведения о них, например, такие как размер.
Создадим пару очередей (queue pair) ввода вывода для отправки пространству имён запроса на чтение/запись.
▍Чтение/запись данных
- Выделим буфер для данных, которые будут прочитаны/записаны.
Скопируем строку «Hello World» в буфер.
Отправим запрос на запись заданному пространству имён, предоставив пару очередей, указатель на буфер, индекс LBA, функцию обратного вызова, которая сработает после записи данных, и указатель на данные, которые должны быть переданы функции обратного вызова.
Функция обратного вызова, после завершения процесса записи, будет вызвана синхронно.
Отправим запрос на чтение заданному пространству имён, предоставив тот же набор служебных данных, который использовался для запроса на запись.
Функция обратного вызова, после завершения процесса чтения, будет вызвана синхронно.
Проверим флаг, который, который указывает на завершение операций чтения и записи. Если запрос всё ещё обрабатывается, мы можем проверить состояние заданной пары очередей. Хотя реальные операции чтения и записи данных выполняются асинхронно, функция spdk_nvme_qpair_process_completions проверяет ход работы и возвращает число завершённых запросов ввода-вывода, и, кроме того, вызывает функции обратного вызова, сигнализирующие о завершении процедур чтения и записи, описанные выше.
Освободим пару очередей и другие ресурсы перед выходом.
Вот полный код разобранного здесь примера, размещённый на GitHub. На сайте spdk.io можно найти документацию по API SPDK NVMe.
После запуска нашего «Hello World» должно быть выведено следующее:

Результаты работы примера «Hello World»
Другие примеры, включённые в SPDK
В SPDK включено множество примеров, которые призваны помочь программистам быстро разобраться с тем, как работает SPDK и начать разработку собственных проектов.
Вот, например, результаты работы примера perf, который тестирует производительность NVMe-диска.

Пример perf, тестирующий производительность NVMe-дисков
Разработчики, которым требуется доступ к сведениям о NVMe-дисках, таким, как функциональные возможности, атрибуты административного набора команд, атрибуты набора команд NVMe, данные об управлении питанием, сведения о техническом состоянии устройства, могут воспользоваться примером identify.

Пример identify, выводящий сведения о NVMe-диске
Выводы
Мы рассказали о том, как использовать SPDK и драйвер, работающий в пользовательском пространстве Linux, для работы с NVMe-дисками. Такой подход позволяет свести к минимуму дополнительные задержки, вызываемые применением механизмов ядра для доступа к устройствам хранения данных, что позволяет повысить скорость передачи данных между накопителем и системой.
Если вас интересует разработка высокопроизводительных приложений, работающих с дисковыми накопителями с использованием SPDK, здесь можно подписаться на рассылку SPDK. А вот и вот — полезные видеоматериалы.
Источник



