- Как преобразовать документ формата PDF в текстовый файл в терминале Linux
- Cага о пакетном конвертировании pdf в text
- pdftotext
- Acrobat Reader
- pdfedit
- How to Convert PDF to Text on Linux
- 2 Methods to Convert PDF to Text on Linux
- Method 1: Use an eBook Application
- Method 2: Use Terminal Commands
- How to Convert PDF to Text on Windows and Mac
Как преобразовать документ формата PDF в текстовый файл в терминале Linux
Оригинал: How to Convert a PDF File to Editable Text Using the Command Line in Linux
Автор: Lori Kaufman
Дата публикации: 9 ноября 2015 г.
Перевод: А.Панин
Дата перевода: 7 октября 2016 г.
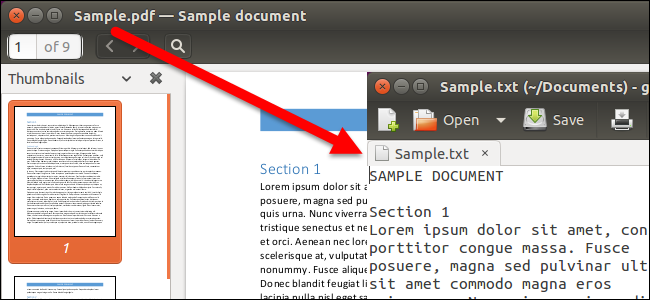
Существует множество причин, по которым вам может понадобиться преобразовать документ формата PDF в текстовый файл. Возможно, вам нужно изменить старый документ и вас есть лишь его версия в формате PDF. Преобразование файлов PDF в ОС Windows не представляет каких-либо сложностей, но что делать в том случае, если вы используете Linux?
Не беспокойтесь, я продемонстрирую простую и рабочую методику преобразования файлов PDF в текстовые файлы с помощью утилиты с интерфейсом командной строки с именем pdftotext из пакета утилит «poppler-utils» . Эта утилита может быть уже установлена в вашей системе. Для проверки ее наличия в системе следует в первую очередь воспользоваться сочетанием клавиш «Ctrl+Alt+T» для открытия окна эмулятора терминала. Далее следует ввести следующую команду после приглашения командной оболочки и нажать клавишу «Enter» .
Примечание: если в статье написано, что нужно ввести какую-либо команду, причем сама команда помещена в кавычки, следует вводить ее без кавычек за исключением тех случаев, когда в статье четко указано обратное.
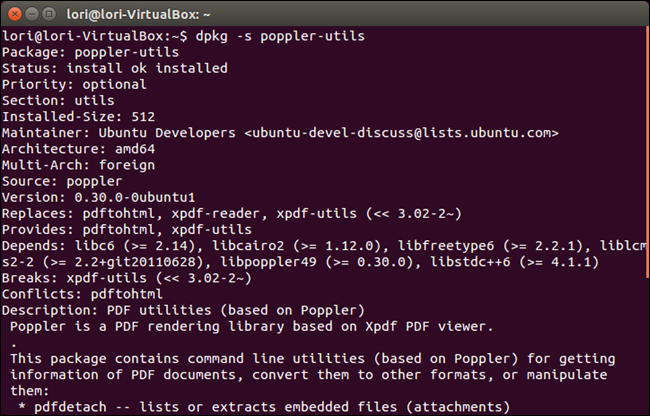
Если утилита pdftotext не установлена, следует ввести следующую команду после приглашения командной оболочки и нажать клавишу «Enter» :
После соответствующего запроса следует ввести свой пароль и нажать клавишу «Enter» :

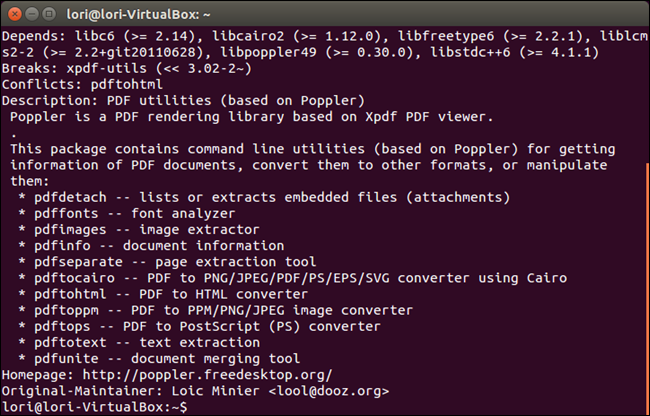
В установленном пакете poppler-utils имеется множество других инструментов для преобразования документов формата PDF в различные форматы, осуществления манипуляций с файлами PDF и извлечения информации из этих файлов.
Следующая команда позволяет преобразовать файл PDF в текстовый файл. Воспользуйтесь сочетанием клавиш «Ctrl+Alt+T» для открытия окна эмулятора терминала, введите следующую команду после приглашения командной оболочки и нажмите клавишу «Enter» .
Вам придется заменить указанные пути к файлам на пути к оригинальному файлу формата PDF и результирующему текстовому файлу соответственно. Кроме того, вам придется изменить приведенные имена файлов на имена ваших файлов.

Созданный утилитой текстовый файл может быть открыт таким же образом, как и любой другой текстовый файл в Linux.
Результирующий текст будет содержать символы новых строк в тех местах, в которых их не должно быть. Это объясняется тем, что символы новых строк вставляются после каждой строки текста в файле PDF.
Вы можете сохранить оригинальное форматирование вашего документа PDF (заголовки, примечания, разделение на страницы и.т.д.) в результирующем файле с помощью флага «-layout» :

Если вы хотите осуществить преобразование диапазона страниц файла PDF, вам придется использовать флаги «-f» и «-l» (это «L» в нижнем регистре) для указания номеров первой и последней страниц из диапазона для преобразования:

Для преобразования файла PDF, зашифрованного с использованием пароля владельца, следует использовать флаг «-opw» (первым символом является буква «O» в нижнем регистре, а не цифра 0):
Замените строку «пароль» на пароль, с помощью которого был защищен оригинальный файл PDF. Убедитесь в том, что вы используете одинарные, а не двойные кавычки для выделения пароля.

Если же файл PDF зашифрован с использованием пароля пользователя, следует использовать флаг «-upw» вместо «-opw» . Остальная часть команды не должна изменяться.

Вы также можете указать набор символов новой строки, который будет использоваться в результирующем текстовом файле. Это особенно полезно в том случае, если вы планируете открывать этот файл в другой операционной системе, такой, как Windows или Mac OS, Для этой цели следует использовать флаг «-eol» (вторым символом является буква «O» в нижнем регистре, а не цифра 0), после которого должен следовать символ пробела и идентификатор выбранного набора символов новой строки ( «unix» , «dos» или «mac» ).

Примечание: если вы не укажите имя результирующего текстового файла, утилита pdftotext автоматически использует имя файла PDF, заменив его расширение на «.txt» . Например, имя файла «file.pdf» будет преобразовано в «file.txt» . Если вместо имени текстового файла использовать «-» , результирующий текст будет отправлен в стандартный поток вывода утилиты, что означает, что текст будет выводиться в окно эмулятора терминала и не будет сохраняться в текстовом файле.
Для закрытия окна эмулятора терминала следует нажать на кнопку «X» в его левом верхнем углу.
Для получения дополнительной информации об утилите pdftotext следует ввести команду «man page pdftotext» после приглашения командной оболочки в окне эмулятора терминала и нажать клавишу «Enter» .
Источник
Cага о пакетном конвертировании pdf в text
В прошлом году была заказана, как казалось на первый взгляд, простая работа: создать систему пакетной обработки файлов — содержащих 12-ти колоночную таблицу, данные из которой экспортировать в БД. Все бы ничего — да вот файлы оказались документами в pdf, а заказчик утверждал что другого формата для обработки предоставить никак не может.

Образец того самого pdf-а — в файле сохранена структура, но подчищены все данные.
Чтож, несмотря на предупреждения знающих людей, а предупреждали они ой как не зря — я за работу взялся и пережил вот такое приключение:
Начался поиск софта для пакетной обработки pdf файлов. Работа производилась на linux — потому первым претендентом оказалась программа из пакета poppler — pdftotext, которую чаще всего в этих целях и используют.
pdftotext
функция легко вызывается из командной строки, и имеет следующий вид:
$ pdftotext ваш.pdf ваш.txt
Но вот результат конвертирования оказался весьма странным:
Выписка из реестра
сделок
по итогам торгов
ЗАО «Санкт — Петербургская
Международная
Товарно — сырьевая Биржа»
Дата торгов: 01/01/1900
Секция: Секция «Нефтепродукты» ЗАО «СПбМТСБ»
Участник: ООО
Код участника:000000000000
Наименование и код клиента: ОАО / 000000000000
Код инструмента: 0000000001
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Hомер
сделки
Покупка/ Цена сделки(за Количество
продажа¹
одну тонну)
лотов
Итого по 0000000001
и так далее…
Мало того: вывод еще менялся от файла к файлу — конечно в таком виде невозможно было написать парсер для выдергивания данных из таблиц.
Потому на горизонте возник второй, на сей раз проприетарный кандидат: Adobe Acrobat Reader for linux.
Acrobat Reader
В данном случае решил, для начала, испытать его возможность «File — Save as Text» в графическом режиме, не сильно углубляясь в командную строку. Как потом выяснилось, правильно сделал — результаты конвертирования моих pdf и в данной программе, не внушали оптимизма:
Код участника:
Секция:
Код инструмента:
Код инструмента:
000000000000
ООО
0000000001
0000000002
00,000,000.11 00,000.12
0,000,000.21 0,000.22
01-12
02-12
03-12
04-12
ЗАО «Санкт — Петербургская
Международная
Товарно — сырьевая Биржа»
Выписка из реестра
сделок
по итогам торгов
Дата торгов: 01/01/1900
Форма СЭТ-ВРС
Наименование и код клиента: ОАО / 000000000000
Участник:
Секция «Нефтепродукты» ЗАО «СПбМТСБ»
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Код
трейдера
Время
сделки Объем сделки
Hомер
сделки
Hомер заявки
Итого по 0000000001
Описание инструмента: Дизельно топливо зимнее З-0.2-35.
Код
трейдера
Время
сделки Объем сделки
Hомер
сделки
Hомер заявки
Итого по 0000000002
и так далее…
Парсить такой вывод, тоже не очень хотелось.
Третьим и, как выяснилось, последним кандидатом оказался pdfedit.
pdfedit
Во всех репозиториях он представлен графической программой с возможностью выполнения скриптов из командной строки. Так же как у Acrobat Reader — первый запуск конвертирования pdf в text произвел из графического окружения «файл — сохранить как текст», результат сильно порадовал:
Получился очень корректный вывод — парсить который легко и приятно. Но не тут то было, путь к завершению эпопеи оказался тернист. Вызвать функцию «сохранить как текст» из командной строки, в стандартно собранном pdfedit, было невозможно:
вывод консольного хелпа давал две утилиты, никак не связанные с конвертированием в текст. Дальнейшее изучение документации на wiki привело к готовому скрипту конвертирования savealltext.qs, но беда в том, что он должен был исполнятся из графического меню. В результате пришлось подробно изучать матчасть:
«Курение» уже этого материала + поэтапный разбор представленного в стандартной сборке консольного скрипта /usr/share/pdfedit/delinearize.qs — привело меня к созданию своего savealltext.qs:
будучи помещенным в каталог /usr/share/pdfedit/, скрипт вызывается из командной строки и производит требуемое конвертирование:
$pdfedit -console savealltext ваш.pdf ваш.txt
Вроде бы все отлично, но подводные камни продолжали всплывать: выяснилось что pdfedit, в консольном режиме, забирает текст с области по умолчанию 612×792 pixels — в разрешении 72 dpi это соответствует А4 листу альбомной ориентации. Поворачивать область сканирования программа никак не хотела, несмотря на присутствие в коде соответствующих инструкций с патча rotate_text_fix.patch.
Поиски определения этой триклятой «дефолтной области» завели меня в исходный код проекта, к файлу: src/kernel/displayparams.h — вот ведь, нашли куда засунуть!
static const int DEFAULT_PAGE_RX = 612; /**
Заменил оба значения на 1584 точек (что соответствует половине ватмана в том же разрешении) и прересобрал проект.
На этом, можно сказать, мучения закончились — pdf-ки обрабатывались из терминала, во всю свою А4-ую дущу альбомной ориентации.
По результатам своих мучений сделал правила для сборки пакетов pdfedit с savealltext для ArchLinux и выложил в AUR:
pdfedit релиз
pdfedit версия из csv
Скоро сказка сказывается, да не скоро дело делается — мне сильно не нравилось что pdfedit для запуска, даже в консольном режиме, требовал наличия в системе qt3:
$ pdfedit -console
pdfedit: error while loading shared libraries: libqt-mt.so.3: cannot open shared object file: No such file or directory
Что привело к рассмотрению ключей конфигурирования программы при сборке из исходников и тут был найден следующий рецепт:
configure —disable-gui —enable-pdfedit-core-dev —enable-tools
В результате бинарник графического pdfedit не собирается вовсе, зато создается целая куча полезных утилит, среди которых pdf_to_text — производящая необходимую мне конвертацию, применяя те же, что и скрипт savealltext.qs, алгоритмы:
$pdf_to_txt -file ваш.pdf >ваш.txt
Результаты такой сборки проекта, тоже превратил в PKGBUILD для ArchLinux и выложил в AUR.
Спасибо всем за консультации! Благодаря обсуждению было выявлено еще несколько интересных способов конвертирования pdf в text:
zeliboba предложил применить к pdftotext опцию -layout
$ pdftotext -layout ваш.pdf ваш.txt
Можно без преувеличивания сказать что, файлы проекта из статьи, такой способ конвертирует лучше чем pdfedit:
С другой стороны — не со всеми pdf-ами это правило срабатывает:
«Сегодня экспериментировал с различными pdf файлами, получилась что между pdfedit и pdftotext — все равно нет абсолютного чемпиона, скажем:
Pdftotext — лучше сконвертировал ряд вытянутых в горизонтальном направлении таблиц и одноколоночных журналов.
Pdfedit — лучше работал с многоколоночными журналами(например:linuxformat) и вертикально ориентированными таблицами.
Гдето обе программы показали одинаковый результат (например: журнал Цейнгауз).»
kornerz предложил конвертировать pdf в svg, при помощи inkscape — предварительно разделив pdf-файл на листы (как вариант при помощи pdftk)
Источник
How to Convert PDF to Text on Linux

Margarete Cotty
2021-08-24 09:14:14 • Filed to: Knowledge of PDF • Proven solutions
A convert PDF to text job on Linux is easy if you know a few tips and tricks in your particular distro, but what if you’re new to Linux and you need to get a PDF document converted to a text-based equivalent? Are there any Linux tools specifically designed for this? How about OCR modules — how do you get them for Linux? The answers to these questions all in this article, so read on to learn more about how to convert PDF to text in Linux.
2 Methods to Convert PDF to Text on Linux
Let’s look at a couple of ways to do this on a Linux desktop and the tools for those.
Method 1: Use an eBook Application
Essentially, what you want to do is convert a non-editable and possibly non-searchable PDF document and convert the content without actually changing the format. For this, you can use freeware or an open-source application like Calibre. It is available in most repos for Ubuntu, Mint, Fedora, and other popular distros. The correct syntax varies from one distribution to another, but your basic Terminal command should look something like this:
sudo apt install calibre
Once installed, you can follow the flow of the process from within the application. Here’s what it should look like:
- 1. Launch the application and click the Add Books button on the top left to import one or more scanned or non-editable PDF documents.
- 2. When you see the PDFs in the list below the Calibre toolbar, select the file(s) you want to convert to text and hit the Convert Books option at the top.
- 3. Choose the format of the output file to TXT in the conversion window and hit OK to convert.
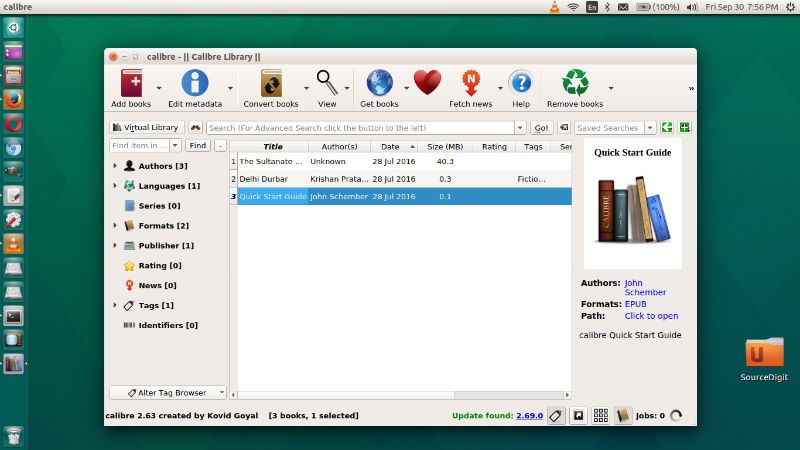
You can now open the file in any text editor and make changes or edit the content the way you want. This does not retain the format of the original but it’s a fairly authentic copy of the non-editable file. The original PDF document will be unchanged, so you can save the new version with a slightly different name like Doc1_OCR, Doc2_OCR, and so on.
Method 2: Use Terminal Commands
On the other hand, if you’re at an expert level on your Linux machine, you can try the command line way of converting PDF to text. For this, you can use something like pdftotext. It’s part of the Poppler package but the name might vary based on which distro you’re using. The first step is to install it, and you can do it with the following commands:
1. First, type the following in Terminal and hit «Enter»
sudo apt install poppler-utils [Works for Debian, Mint, Ubuntu, etc.]
2. The next command is the one for conversion, and it should look like this:
pdftotext -layout source.pdf target.txt [Source is the original PDF and Target is the final output]
To execute the above command, the Terminal prompt needs to be in the same folder location as your source PDF file. Alternatively, you can define a file path before the source and target file names within the command.
3. Hit Enter to run the command on the entire PDF document. To convert just a single range of pages within the document, modify the syntax to match the one shown below:
pdftotext -layout -f M -l N source.pdf target.txt [where M is the first page and N is the last one to be converted.]
How to Convert PDF to Text on Windows and Mac
Now you know how to convert PDF to text in Linux, how about Windows or Mac? Do you know how to do the same thing on these OS platforms? If not, read on to learn about a unique and robust utility to do the same job in operating systems other than Linux.
PDFelement is a cross-platform PDF editor with desktop and mobile applications for PDF management. They’re a lightweight family of PDF tools that are incredibly powerful and versatile. More importantly, they’re far more affordable than some of the other premium options that rule the market today. For that reason, PDFelement is quickly becoming the de facto PDF editor for businesses that can’t afford expensive alternatives. In addition, it boasts these features:

- Full editing capability for all PDF text, images, links, media, and other objects.
- Comprehensive markup tools to annotate PDFs.
- Strong security features for redaction, watermarking, encryption, and digital signing.
- Advanced batch processes for conversion and OCR tasks.
- Fully-integrated forms management: create interactive forms, convert from non-editable PDF forms, access a large template library, extract data from forms and PDFs in bulk, etc.
- Robust вЂto and from PDF’ conversion capability with very wide file-type support.
- More accurate and faster than many premium PDF editors.
Steps for Converting PDF to Text in Windows and Mac:
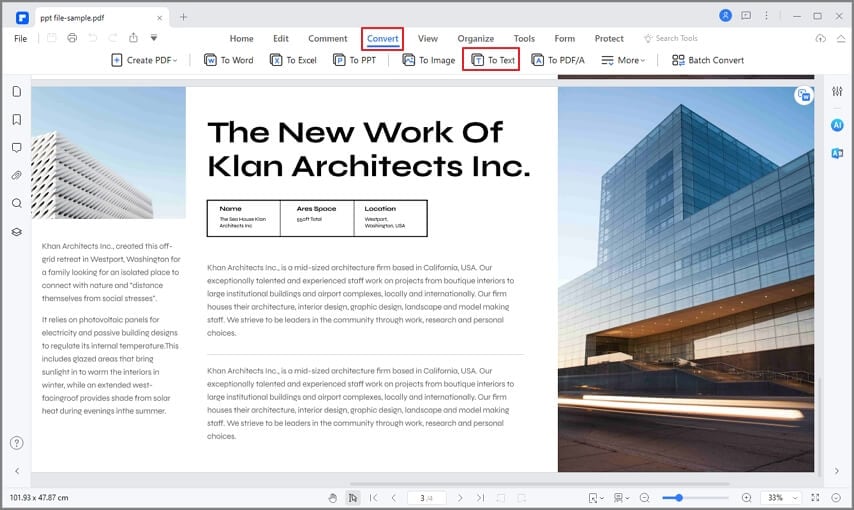
- 1. After launching PDFelement on your Windows PC, import the file by dragging it into the software window or just click on «File» в†’ «Open» and get it that way. Even when the PDF editor is closed, you can open a document by dragging its icon over the app’s icon.
- 2. If you click on the «Convert» tab option at the top, you’ll see a button in the toolbar right below it with the words «To Text» and an icon. The mouseover (tooltip) should say «Convert your PDF to text». Click on the button.
- 3. Specify your output folder and, if you need to, you can change the output file type on the «Save As» dialog box, too.
Mac (macOS versions including 10.15 Catalina):
PDFelement is equally intuitive on a Mac as it is in Windows. You might see a lot of UI differences between the two, but those features have been designed to work as closely as possible with the nuances of their platforms. The end result is a pretty native experience on any platform, including touchscreen-based iOS and Android devices and screens.
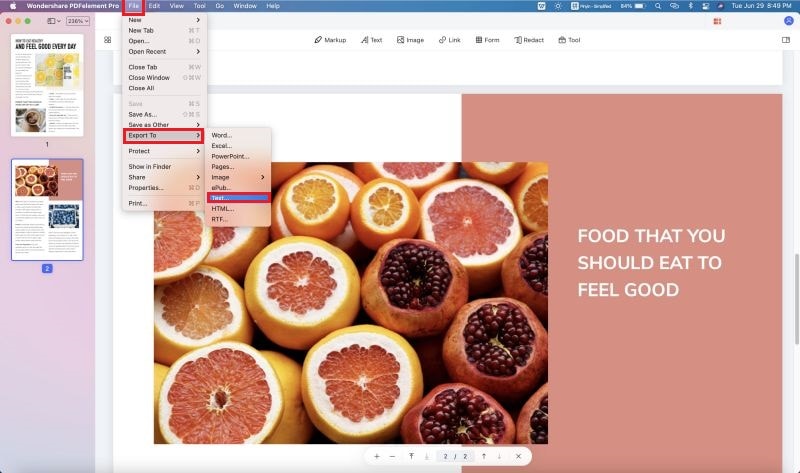
- 1. PDFelement for Mac has a distinctively Mac App feel to it as soon as you install and launch the application. You can open your PDF using the same methods as for Windows — drag-and-drop or using the «File» menu.
- 2. Again, in the «File» menu, you’ll see an option called «Export To», which opens another contextual menu. Select «Text» as your option and wait for the conversion to be completed.
Now you know all there is to know about how to convert PDF to Text on Linux, Windows, and Mac.
Источник



