MSpeech
Программа для преобразования речи в текст и выполнения Windows-команд голосом
- Windows 10
- Windows 8.1
- Windows 8
- Windows 7
- Windows Vista
- Windows XP
Тип лицензии:
Условно-бесплатное




MSpeech — программа для распознавания голоса с последующим его преобразованием в текст или выполнением заданной пользователем команды. Кроме того, приложение может использоваться и в обратном направлении — для преобразования текста в голос.
MSpeech — условно-бесплатная программа с ограниченным функционалом (но имеется возможность бесплатно получить полнофункциональную версию). Подходит для компьютеров под управлением Windows XP, Vista, 7, 8, 8.1 и 10 (32 и 64 бит). Интерфейс программы выполнен на русском языке.
Как пользоваться программой MSpeech?
Для распознавания голоса программа MSpeech использует встроенный модуль Google Voice API (т.е. для работы приложения требуется доступ в интернет). В его задачу входит отправка записанного голосового сообщения на сервер Google, где оно обрабатывается (транскрибируется в текст) и отправляется обратно на пользовательский компьютер в виде текстового сообщения. Благодаря Google Voice API программа MSpeech способна распознавать более 50 языков, включая русский.
Для ввода звука (голоса) в приложении предусмотрен собственный звукозаписывающий модуль, которым можно управлять посредством горячих клавиш. Также через программу можно транскрибировать голос из ранее созданных аудиозаписей, но для этого придется внести соответствующие настройки в системные параметры Windows, отвечающие за управление микрофоном (нужно задействовать функцию «Прослушать с данного устройства» в свойствах микрофона).
Однако у Google Voice API есть недостаток — для работы с сервисом пользователю может потребоваться создать специальный ключ API (API key Google Speech), что можно сделать на одном из сайтов известного поисковика. Также у сервиса Google Voice API есть ограничение на бесплатное использование — общая продолжительность отправляемых звукозаписей не должно превышать 60 минут в месяц. За дальнейшее распознавание голоса требуется оформить платную подписку.
Функции MSpeech
Помимо основной функции по распознаванию голоса, в возможности программы MSpeech также входят:
- Возможность создания неограниченного количества голосовых команд. Всего их 5 категорий — запуск, закрытие и остановка процесса программ, запуск программ с параметрами командной строки, а также запуск функции преобразования текста в голос (синтез речи).
- Функция преобразования текста в голос имеет собственные настройки. Пользователь может выбрать одну из 5 систем синтеза речи, включая стандартную Microsoft SAPI, которая может работать без интернета. Все прочие системы — онлайн (сервисы от Google, Yandex, iSpeech и Nuance).
- Возможность передачи преобразованного из голоса текста в текстовые поля любых запущенных программ путем использования метода WM_SETTEXT +EM_REPLACESEL, WM_PASRE, WM_CHAR, WM_PASTE (MOD) или WM_COPYDATA (платная функция). Данный функционал предназначен, в первую очередь, для программистов с целью организации взаимодействия своих разрабатываемых программ с MSpeech.
- Автоматическая коррекция текста перед отправкой в поля ввода других программ (замена слов по словарю и изменение первых букв предложений на заглавные буквы). Это еще одна платная функция.
Как получить MSpeech без ограничений по функционалу?
Разработчик MSpeech на своем официальном сайте выложил исходный код своей программы на языке Delphi. Исходники можно скачать и самостоятельно скомпилировать в компиляторе «Delphi XE6» или более поздних версиях. Скомпилированная в итоге программа MSpeech не будет иметь функциональных ограничений (не относится к ограничениям сервиса Google Voice API).
Программы для перевода голоса в текст

Любой пользователь компьютера может столкнуться с ситуацией, когда необходимо голосом ввести какой-либо текст на компьютере. Помимо стандартных решений Windows, существуют сторонние приложения, позволяющие сделать это. Предлагаем рассмотреть лучшие из них.
MSpeech
Первым делом рассмотрим бесплатную утилиту MSpeech от независимого разработчика Михаила Григорьева, распространяющего свой продукт бесплатно с открытым исходным кодом. В основе решения лежит технология Google Voice API, предназначенная для распознавания человеческой речи и дальнейшего ее преобразования в текст. Распознанный текст вводится в специальное окно, откуда его можно легко перенести в другие приложения разными способами. Поддерживается порядка 50 различных языков, включая русский. Доступны горячие клавиши для удобной активации и завершения записи.
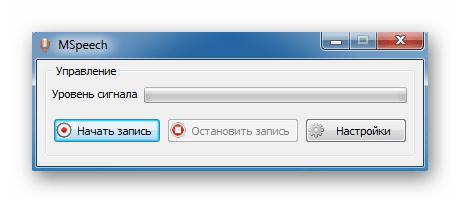
Предусмотрен простой текстовый редактор, в котором можно выполнить первичную коррекцию полученного текста: заменить определенные слова другими или изменить первые буквы предложений на прописные. В качестве источника звука можно использовать любое устройство, подключенное к компьютеру. Если их несколько, то MSpeech предложит выбрать подходящее. Меню программы поддерживает русский язык. Помимо этого, она совместима со следующими интерфейсами: Microsoft SAPI, Google Text-to-Speech, iSpeech Text-to-Speech, Yandex Text-to-Speech и др.
Lossplay
На очереди еще одно простое приложение для транскрибации, которое изначально создавалось командой разработчиков с разных стран. Сейчас в качестве создателя выступает один независимый программист, продолжающий развивать его. LossPlay можно использовать не только для перевода голоса в текст, но и в качестве обычного плеера для прослушивания музыки и других аудиофайлов. Решение поддерживает любое актуальное расширение от MP3 до WMA. Управление воспроизведением осуществляется с помощью настраиваемых горячих клавиш.
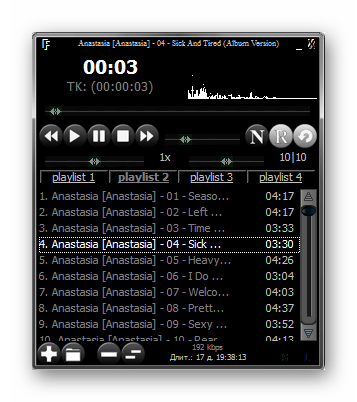
LossPlay оптимизирован для работы с текстовыми документами Microsoft Word. Распознаваемый текст вводится в программе без участия пользователя. Помимо этого, предусмотрена функция автоматической вставки тайм-кодов всех фраз. Интерфейс рассматриваемого решения представлен в виде привычного плеера с дополнительными функциями. При этом с меню справится даже начинающий пользователь. LossPlay распространяется на бесплатной основе на русском языке.
Transcriber-Pro
Transcriber-Pro — программа от российских разработчиков, предназначенная для ручной расшифровки аудио и видеофайлов в текст. Присутствует встроенный текстовый редактор со всеми необходимыми функциями для качественной транскрибации: вставка временных меток и дикторов, простая навигация по записи, коррекция без повторного прослушивания, формирование профессиональное стенограммы и др. Управление осуществляется с помощью настраиваемых горячих клавиш, что делает решение более удобным.
![]()
Рассматриваемое приложение позволяет работать в команде над одним проектом. Предусмотрена оперативная техническая поддержка для обладателей платной лицензии. Подписка оформляется на год. На официальном сайте можно ознакомиться с системными требованиями, посмотреть наглядный видеоролик по работе с Transcriber-Pro, а также увидеть подробное руководство пользователя.
Express Scribe
Express Scribe — многофункциональный инструмент для ручной расшифровки аудиозаписей, представленный в виде удобного плеера с дополнительными возможностями. В одном интерфейсе сосредоточен звуковой и текстовый модуль, что избавляет пользователя от необходимости переключаться между окнами. Среди примечательных особенностей стоит отметить возможность переключаться между звуковыми дорожками, переходить к конкретным ее частям, а также добавлять заметки с тайм-кодами.
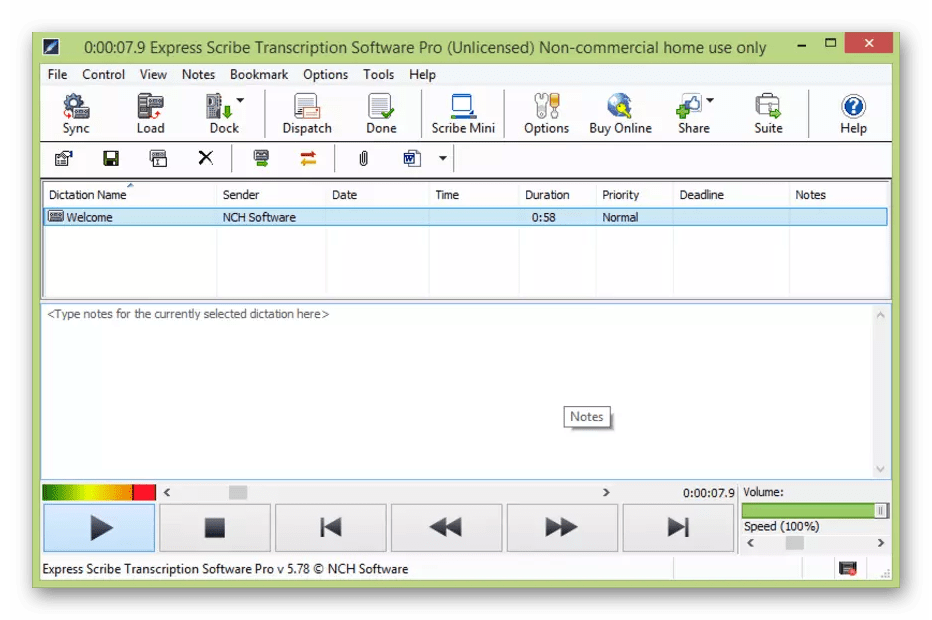
Для открытия файла можно использовать директорию компьютера, FTP-сервер, компакт-диск, электронное письмо или внешние накопители. Помимо этого, Express Scribe поддерживает портативное аудиозаписывающее оборудование. Рассматриваемое решение работает с огромным количеством звуковых форматов: WAV, MP3, WMA, VOX, AU, DSS и др. Поддерживаются расширения диктофонов Philips Digital Recorder, GSM 6.10, ALaw, DSP и т. д. Стоит отметить, что некоторые форматы недоступны в демо-версии, а русский язык здесь вообще не предусмотрен.
Voco — простая утилита для автоматического распознавания человеческой речи и преобразования в текст. Она работает в фоновом режиме, а соответствующий значок можно найти в трее. Микрофон запускается при нажатии комбинации горячих клавиш, после чего пользователь произносит нужные слова и уже через несколько секунд они появляются на экране. Благодаря совершенным алгоритмам система практически не ошибается, а скорость ее работы превышает опытных стенографистов.

Механизм Voco позволяет выставлять знаки препинания голосом и переводить курсор на новую строчку или абзац. Помимо этого, предусмотрена функция расшифровки аудио или видеофайла, но она доступна только в платной версии. Утилита имеет развивающийся словарный запас, который может пополнить любой пользователь. База уже насчитывает более 85 тысяч слов. Для получения демо-версии необходимо заполнить специальную анкету. Присутствует русская локализация.
Это были наиболее надежные и популярные средства для перевода голоса в текст. Одни из них работают в автоматическом режиме, где достаточно загрузить аудиофайл или воспользоваться микрофоном, другие же представляют собой лишь вспомогательный инструмент, значительно упрощающий ручную транскрибацию.
5 лучших программ для перевода речи в текст
Люди все чаще предпочитают совершать поисковые запросы с помощью голосовых команд. В том числе с помощью голосового поиска люди совершают покупки в интернете, а значит, продавцам надо учитывать привычки аудитории, тем более что это весьма привлекательный сегмент — совершеннолетние, обеспеченные люди с высшим образованием.
Поэтому, интегрируйте функцию распознавания голоса в свой веб-сайт или приложение, чтобы повысить эффективность маркетинговой кампании в интернете. Как это сделать? Просто используйте одно из множества доступных веб-API для преобразования речи в текст. Рассмотрим самые полезные из них, а вы решите, какие продукты лучше всего соответствуют вашим задачам и потребностям.
API преобразования речи в текст для коротких онлайн-поисков
Как правило, голосовые поисковые фразы — короткие и точные. Поэтому API голосового поиска для онлайн-приложений не должны быть настолько совершенными, и не надо принимать во внимание такие технические вопросы, как грамматика или синтаксис. Эти API, как правило, легче и быстрее загружаются.
1. Google Speech-To-Text

По сути, самый мощный интерфейс приложений на рынке из доступных для разработчиков. Был представлен в 2018 году. С каждым тестированием и обновлением продукт только улучшается. Благодаря чему Speech-To-Text API не только распознает речь с высоким уровнем точности, но и грамотности, с минимальным количеством ошибок пунктуации.
Google API подходит и для других целей, не только веб-поиска. Также с помощью этого решения можно настроить аудио для телефонных или видеозвонков. Также разработчики могут отмечать свои транскрибированные аудио или видео основными метаданными. Это позволит компании Google решать, какие функции наиболее полезны для программистов.
Стоит учитывать, что бесплатно транскрибировать аудио с использованием API от Google можно не дольше 60 минут. Если запись длиннее, расшифровка стоит $0,006 за 15 секунд.
Если необходимо транскрибировать видео, это будет стоить $0,006 за 15 секунд, если запись длится не более 60 минут. Для видео продолжительностью более одного часа это стоит $0,012 за каждые 15 секунд.
- Распознает более 120 языков.
- Несколько моделей машинного обучения для повышения точности.
- Автоматическое распознавание языка.
- Текстовая транскрибация.
- Правильное распознавание имен и названий.
- Конфиденциальность данных.
- Устранение шума в аудио.
- Платный продукт.
- Ограниченный пользовательский словарь.
2. Microsoft Cognitive Services

Еще один крупный игрок на рынке API распознавания голоса предлагает свой продукт. Главное отличие: API Microsoft Cognitive Services — это часть Microsoft Trust Services, где разработчики приложений могут найти надежные безопасные данные.
Главное отличие API речи от Microsoft — это функция идентификации говорящего. Похоже на распознавание лиц, но сканируется голос. Благодаря этой функции программное обеспечение приспосабливается к определенной манере и особенностям речи пользователя. Дополнительное преимущество — более расширенный пользовательский словарь, чем от Google.
Также Microsoft Cognitive Service может выполнять транскрибацию в реальном времени, и преобразовывать текст в речь. Еще это API можно использовать для анализа регистрационных записей в колл-центре при большом количестве звонков.
- Улучшенная защита данных с помощью алгоритмов распознавания голоса.
- Транскрибация и перевод в реальном времени.
- Адаптируемый словарь.
- Возможности преобразования текста в речь для естественных речевых шаблонов.
- Это API создавалось для общих целей, поэтому имеет ограничения.
- Микрослужбы полезны для решения отдельных проблем, но не подходят для более крупных проблем.
3. Dialogflow (бывшее название — API.AI, Speaktoit)

Еще один продукт от Google. Основное преимущество — это голосовое API учитывает контекст при анализе речи, что обеспечивает более точную транскрибацию. Это значит, что Dialogflow можно встраивать в различные устройства, которые слушают голосовые команды: смарт- гаджеты, телефоны, носимые устройства, автомобили, интеллектуальные колонки.
Dialogflow уже не первый год используется для машинного обучения, распознавания голоса, игр. Предыдущая версия, Api.AI, еще в 2014 году использовалась для поддержки виртуального голосового помощника Assistant.
Также в платформу Dialogflow встроены разные полезные аналитические функции, чтобы измерить показатели вовлеченности пользователя или время сеанса, характер использования или проблемы со временем ожидания информации.
Это API пока поддерживает только 14 языков, поэтому проигрывает многоязычным ПО, таким как Google Speech-To-Text или Microsoft Cognitive Services.
- Бесплатное и легкое в использовании.
- Легко настроить.
- Интегрируется с разнообразным программным обеспечением.
- Легко интегрируется с другими веб-сервисами.
- Можно совмещать с устройствами не от Google, такими как Alexa от Amazon.
- Не может обрабатывать математические функции.
- Невозможно создать интерактивные ссылки в текстовом поле.
- Не определяет поисковые намерения пользователей.
- Может предоставить только один веб-перехватчик.
API распознавания голоса для полноформатной и автономной обработки
4. IBM Watson

В эпоху интернета генерируются особо большие объемы данных, которые следует обрабатывать и анализировать. Не все эти данные будут достоверными и упорядоченными. Но для разработчиков API нужны пригодные для использования данные.
Искусственный интеллект от IBM Watson безупречно обрабатывает шаблоны на естественном языке и особенно эффективен в понимании контекста, опираясь на генерацию и оценку гипотез в своей формулировке ответа.
IBM Watson API подходит для большинства задач по транскрибации, благодаря способности различать несколько ораторов. Дополнительно можно установить несколько фильтров, чтобы устранять ненормативную лексику, добавить утвержденные слова и параметры форматирования для приложений по преобразованию речи в текст.
Разработчики могут выбрать среди различных интерфейсов от IBM Watson: интерфейс WebSocket, интерфейс HTTP REST и асинхронный интерфейс HTTP.
Если вы ищете API для распознавания речи, но не обладаете продвинутыми техническими навыками, то IBM Watson — отличный вариант с подробной документацией и полным справочным руководством. Это API для преобразования речи в текст легко настроить и сразу начать использовать.
IBM Watson — это не просто текстовый API, это полностью разработанная библиотека машинного обучения. И по мере использования продолжает учиться и развиваться. С помощью этого интерфейса можно исследовать больше данных — и быстрее, и не волноваться о сбоях и отказах в работе.
IBM Watson стоит недешево, но цена вполне оправданна, ведь это один из наиболее развитых API машинного обучения, быстро запускается и работает, а это значит, что нет потребности, нанимать лишних разработчиков или терпеть убытки из-за простоев.
- Обрабатывает неструктурированные данные.
- Помогает людям, а не заменяет их.
- Расширяет человеческие возможности.
- Повышает производительность, предоставляя соответствующие данные.
- Улучшает пользовательский опыт.
- Может обрабатывать большие объемы данных.
- Легко настроить и запустить.
- Не поддерживает напрямую структурированные данные.
- Дорогостоящий.
- Требуется техническое обслуживание.
- Поддерживает ограниченное количество языков.
- Долго внедрять.
- Чтобы полностью использовать ресурсы, требуется дополнительное обучение.
5. Speechmatics

Это простой в использовании облачный API для автоматических служб транскрибации. Поддерживает множество форматов файлов, а значит, может использоваться для автономной обработки файлов.
Speechmatics поддерживает широкий диапазон языков для тех разработчиков, которые не хотят ограничиваться только английским языком. И это очень точный API, с помощью которого распознавание речи осуществляется весьма качественно.
Не менее виртуозно Speechmatics API распознает голос, обрабатывая множество различных переменных — от уровней достоверности до примет выступающего. Поэтому Speechmatics — хороший выбор для приложений машинного обучения, ведь с каждой новой сессией происходит более основательное знакомство с говорящим.
Speechmatics признан одним из самых быстрых и надежных API для автоматической транскрибации, которые доступны для разработчиков. Поддерживает девять языков, включая различные варианты английского, в том числе британский и австралийский английский.
Небольшой недостаток: Speechmatics API подходит только для сайтов, если вы планировали разработать приложение, то этот интерфейс не подходит.
Во-вторых, каждый запрос стоит денег — 0,06 фунтов за 1 минуту обработанного аудио, но можно рассчитывать на скидки, если количество минут превышает 1000. Учитывайте эти затраты.
- Быстрый и точный.
- Простой в использовании.
- Поддерживает несколько языков, в том числе разные версии английского.
- Распознает несколько говорящих, в том числе голоса.
- Поддерживает разные форматы файлов.
- Хорошо справляется с шумовыми помехами в аудио.
- Легко интегрируется через REST API.
- Может использоваться для облачных служб транскрибации и частного применения.
- Нет интерфейса для приложений.
- Каждый запрос — платный.
Выводы
API для распознавания речи бывают разными — у каждого свои сильные и слабые стороны. Воспринимайте эти интерфейсы как набор инструментов, а не как готовый продукт. Например, если вам нужна транскрибация или декодирование искаженного звука, Google Speech-To-Text — отличный выбор. Если ваша цель — функции перевода и транскрибации в режиме реального времени, вероятно, стоит выбрать Microsoft Cognitive Services. Если вам нужно автоматически настраиваемое API распознавания голоса, может подойти Dialogflow. Если вы собираетесь работать с большими объемами неструктурированных данных, лучше всего выбрать IBM Watson. Если вам важно различать говорящих, или интегрировать API с дополнительным программным обеспечением, подумайте о Speechmatics.
Сначала разберитесь, для чего вы будете использовать продукт, и тогда определитесь, какой API подходит для ваших целей.
Конечно, эти перечисленные пять API — не единственные на рынке. Можно найти и другие интерфейсы для распознавания голоса, которые тоже заслуживают внимания. Например, поинтересуйтесь: AssemblyAI, Vocapia, речевой модуль от iFlyTek, UWP Speech Recognition от Microsoft, пакет ПО CMU Sphinx (с открытым исходным кодом) и не только.
Учитывая развитие ИИ, разработку виртуальных помощников, можно с уверенностью сказать, что голосовая интеграция никуда не денется. Технология распознавания речи станет частью нашей повседневной жизни.



