- Анализ загруженности оборудования для Windows
- Сбор информации по загруженности оборудования
- Настройка сборка данных в Performance Monitor (Windows Server 2012 R2)
- Анализ сохраненного замера
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Курс по сетям
- Пошаговый ввод в домен Windows 10
- Основные команды cmd в Windows
- Поднимаем контроллер домена на Windows 2008 R2
- Установка и настройка диспетчера ресурсов файлового сервера (File Server Resource Manager) в Windows Server 2016
- Пошаговый ввод в домен Windows 10
- Как восстанавливать файлы в Microsoft Windows File Recovery
- Конвертация виртуальных машин Hyper-V во 2-е поколение
- Новый монитор производительности для Windows Server
- Мониторинг на продукционных серверах
- Краткое содержание:
- Общие сведения
- Контроль подключений
- Контроль потребления памяти
- Контроль устойчивости системы
- Гибкие оповещения
- Использование ЦКК для агрегации своих данных
- Пример настройки сбора данных по загруженности оборудования с помощью PowerShell (3.0 или 4.0) для Windows серверов с агрегацией данных в ЦКК.
- Серверный технологический журнал
- Клиентский технологический журнал
- Разбор технологического журнала
Анализ загруженности оборудования для Windows
Для своевременного обнаружения узких мест в оборудовании необходимо проводить постоянный мониторинг загруженности всех основных аппаратных компонентов системы. К ним в первую очередь относятся:
- Все рабочие сервера кластера 1С:Предприятия
- Сервер СУБД
- Клиентские рабочие станции, работающие под большой нагрузкой
Для каждого из этих компьютеров необходимо настроить сбор информации по загруженности оборудования.
Сбор информации по загруженности оборудования
Во время работы системы рекомендуется осуществлять постоянный мониторинг и запись основных показателей загруженности оборудования. Для этого можно использовать разные средства, в данной статье будет рассказано, как это можно сделать с помощью Performance Monitor, входящего в состав операционной системы Windows, и ЦКК – Центра контроля качества, типовой конфигурации, входящая в Корпоративный инструментальный пакет.
Настройка сборка данных в Performance Monitor (Windows Server 2012 R2)
Для запуска Performance Monitor выберите соответствующий пункт меню раздела Administrative Tools контрольной панели Windows.
Добавьте в список наборов счетчиков (Data Collector Sets) новый набор (User Defined – пользовательский):

Настройка будет осуществляться вручную – в диалоговом окне нужно выбрать соответствующий пункт и нажать «Далее»:
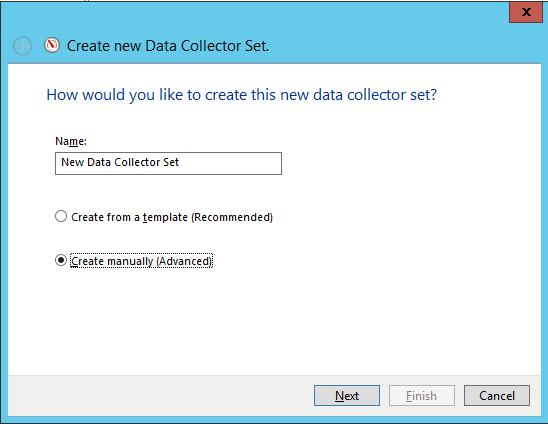
Выберите, какие именно данные будут собираться. Нас интересуют Счетчики производительности:
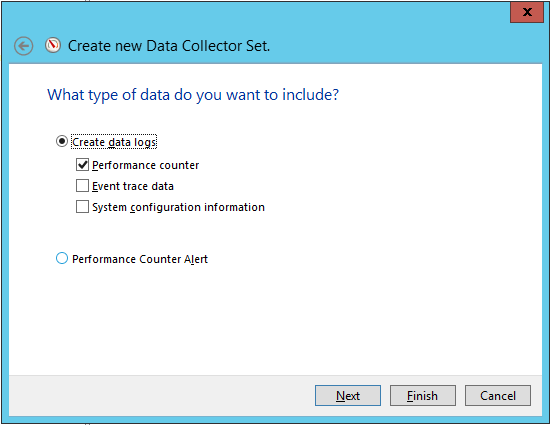
На следующем шаге выбираются сами счетчики, которые будут входить в набор.

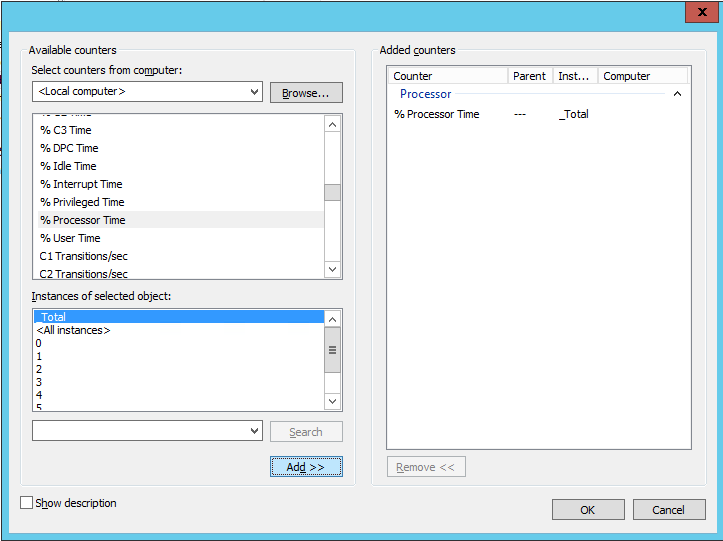
Мы рекомендуем в обязательном порядке собирать данные по следующим счетчикам:
«\Processor(_Total)\Interrupts/sec»
«\LogicalDisk(_Total)\% Free Space»
«\Memory\Available Mbytes»
«\PhysicalDisk(_Total)\Avg. Disk Queue Length»
«\PhysicalDisk(_Total)\Avg. Disk Sec/Read»
«\PhysicalDisk(_Total)\Avg. Disk Sec/Write»
«\Processor(_Total)\% Idle Time»
«\Processor(_Total)\% Processor Time»
«\Processor(_Total)\% User Time»
«\System\Context Switches/sec»
«\System\File Read Bytes/sec»
«\System\Context Switches/sec»
«\System\File Read Bytes/sec»
«\System\File Write Bytes/sec»
«\System\Processes»
«\System\Processor Queue Length»
«\System\Threads»
Состав счетчиков может меняться в зависимости от роли компьютера. Например, для сервера приложений 1С:Предприятие к перечисленным выше стоит добавить показатели работы процессов 1с:Предприятие:
«\Process(«1cv8*»)\% Processor Time»
«\Process(«1cv8*»)\Private Bytes»
«\Process(«1cv8*»)\Virtual Bytes»
«\Process(«ragent*»)\% Processor Time»
«\Process(«ragent*»)\Private Bytes»
«\Process(«ragent*»)\Virtual Bytes»
«\Process(«rphost*»)\% Processor Time»
«\Process(«rphost*»)\Private Bytes»
«\Process(«rphost*»)\Virtual Bytes»
«\Process(«rmngr*»)\% Processor Time»
«\Process(«rmngr*»)\Private Bytes»
«\Process(«rmngr*»)\Virtual Bytes»
Обратите внимание, что имена счетчиков могут незначительно отличаться в зависимости от версии вашей операционной системы
Рекомендуемая частота получения значений для рабочей системы – один раз в 15 секунд. В нагрузочных тестах рекомендуем собирать счетчики чаще, например, один раз в 1 секунду, т.к. длительность каждого непрерывного нагрузочного теста обычно не превышает десятка часов, а анализировать более детальные данные удобнее.По окончании выбора нажмите «Далее», укажите директорию хранения логов, при необходимости – пользователя, от имени которого будет запускаться процесс сборщика, и сохраните набор.
Откройте для дальнейшего редактирования его свойства (например, кликнув по нему в списке двойным щелчком мыши):

Можно выбрать формат файла логирования: бинарный удобен, если планируется анализировать графические данные, CSV – если планируется как-либо программно обрабатывать данные. В данном примере выбран бинарный.
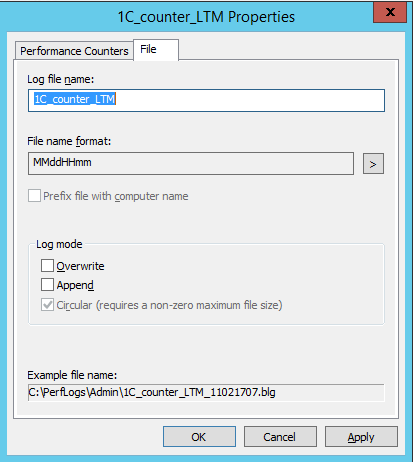
На закладке «Files» можно настроить шаблон имени файлов и режим записи. Для сохраненного набора также можно настроить расписание и задать ограничения и условия окончания сбора.

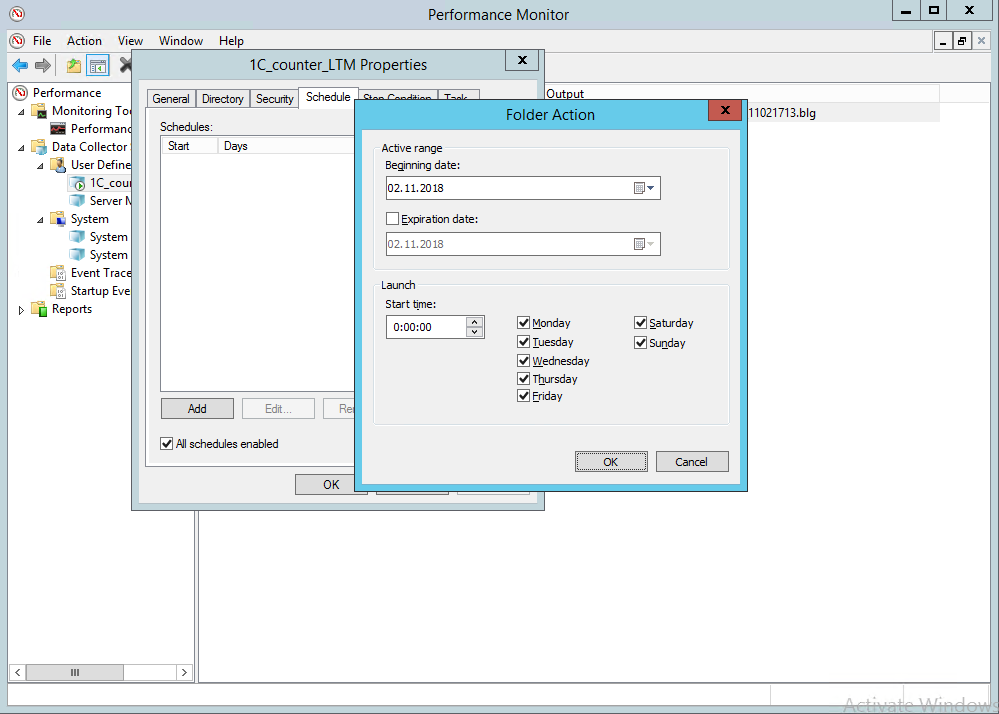
В данном случае замер не стартует автоматически, но на продуктивных площадках рекомендуется не забыть настроить планировщик задач на автозапуск выбранного счетчика, например, каждый час, если сбор данных ещё не запущен.
После сохранения можно запустить замер (при помощи кнопки Start контекстного меню).
Создать набор счетчиков Performance Monitor и управлять сбором данных можно не только интерактивно, но и при помощи консольной утилиты logman. Подробно работа с ней описана на сайте Microsoft https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/logman
Команда создания набора будет выглядеть так:
logman create counter 1C_counter -f bincirc -c «\Processor(_Total)\Interrupts/sec» «\LogicalDisk(_Total)\% Free Space» «\Memory\Available Mbytes» «\PhysicalDisk(_Total)\Avg. Disk Queue Length» «\PhysicalDisk(_Total)\Avg. Disk Sec/Read» «\PhysicalDisk(_Total)\Avg. Disk Sec/Write» «\Processor(_Total)\% Idle Time» «\Processor(_Total)\% Processor Time» «\Processor(_Total)\% User Time» «\System\Context Switches/sec» «\System\File Read Bytes/sec» «\System\Context Switches/sec» «\System\File Read Bytes/sec» «\System\File Write Bytes/sec» «\System\Processes» «\System\Processor Queue Length» «\System\Threads» -si 5 -v mmddhhmm
Анализ сохраненного замера
Для просмотра данных откройте бинарный файл замера .blg, по умолчанию Windows откроет такой тип при помощи Performance Monitor:
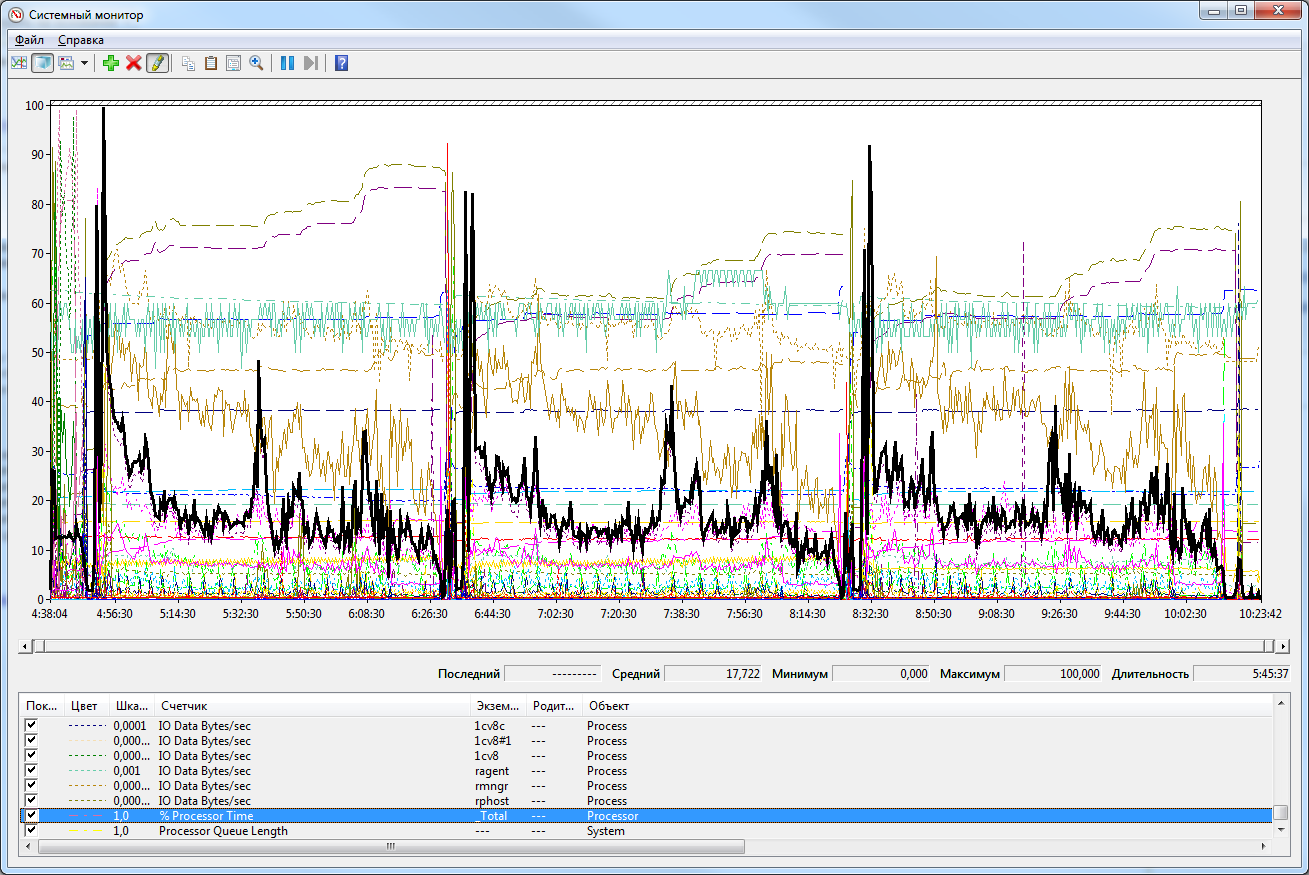
Выделить график, относящийся к конкретному счетчику, можно, встав на линию графика либо на строку счетчика в списке снизу. Для него при этом отобразятся среднее, минимальное, максимальное и последнее значение за период замера:

Интерес представляют, как правило, среднее значение и «пики» — максимум / минимум в зависимости от смысла счетчика.
Ниже в таблице приведены описания и предельные значения некоторых из них:
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Популярное и похожее
Курс по сетям

Пошаговый ввод в домен Windows 10
Основные команды cmd в Windows
Поднимаем контроллер домена на Windows 2008 R2
Установка и настройка диспетчера ресурсов файлового сервера (File Server Resource Manager) в Windows Server 2016
Пошаговый ввод в домен Windows 10
Как восстанавливать файлы в Microsoft Windows File Recovery
Конвертация виртуальных машин Hyper-V во 2-е поколение
Еженедельный дайджест
Новый монитор производительности для Windows Server
Windows Admin Center
3 минуты чтения
Если в прошлом вы работали с Windows Server, то почти наверняка использовали средство perfmon.exe или Монитор производительности Windows. Когда нужно выяснить, почему что-то работает медленно, нет более надежного или универсального источника истины, чем счетчики производительности Windows. Классический интерфейс за все время не очень изменялся. И даже в новой ОС Windows Server 2019 он еще присутствует и запускается из Средств администрирования или оснастки Server Manager.
Обучайся в Merion Academy
Пройди курс по сетевым технологиям
Начать
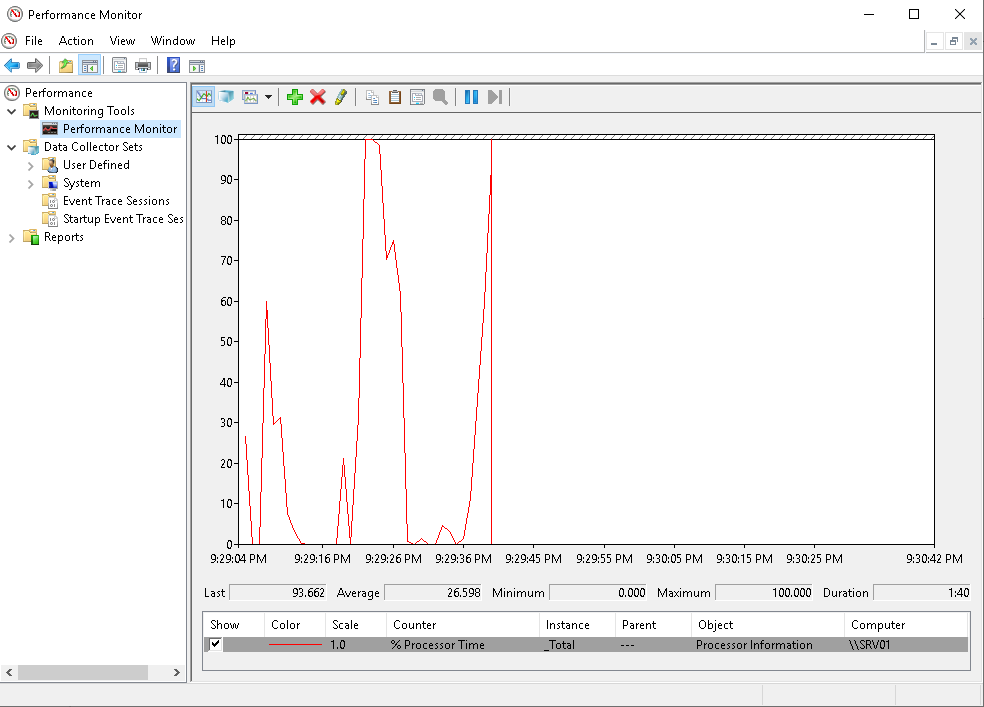
Perfmon в Windows — является оснасткой консоли управления (MMC), которая предоставляет средства для анализа производительности ОС. С ее помощью можно отслеживать производительность операционной системы и оборудования в режиме Real time. Настраивать данные, выборку счетчиков, которые требуется собирать в журналах, определять пиковые значения для предупреждений и автоматических действий, создавать отчеты и просматривать данные о производительности за прошлые периоды различными способами. Обладает классическим интерфейсом MMC консоли, которая на данный момент является устаревшим инструментом для использования.
В этой статье будет рассматриваться новый функционал Windows Performance Monitor. Его интерфейс интегрирован в веб-средство управления WAC (Центр администрирования Windows) который можно скачать отсюда. Обзор WAC есть в нашей базе знаний. На данный момент это предварительная версия, содержит в себе функции готовые к оценке и тестированию. При использовании расширения «Монитор производительности» в Центре администрирования Windows используются те же данные о производительности, что и для perfmon.
После подключения к серверу, основное окно Windows Admin Center открывается на вкладке Обзор, где видны основные характеристики сервера: процессор, версия ОС, ОЗУ, объем диска и другие характеристики. Также на этом этапе можно выключить/перезагрузить сервер. Здесь же можно включить дисковые метрики, включение которых может повлиять на общую производительность системы. О чем WAC и сообщит.
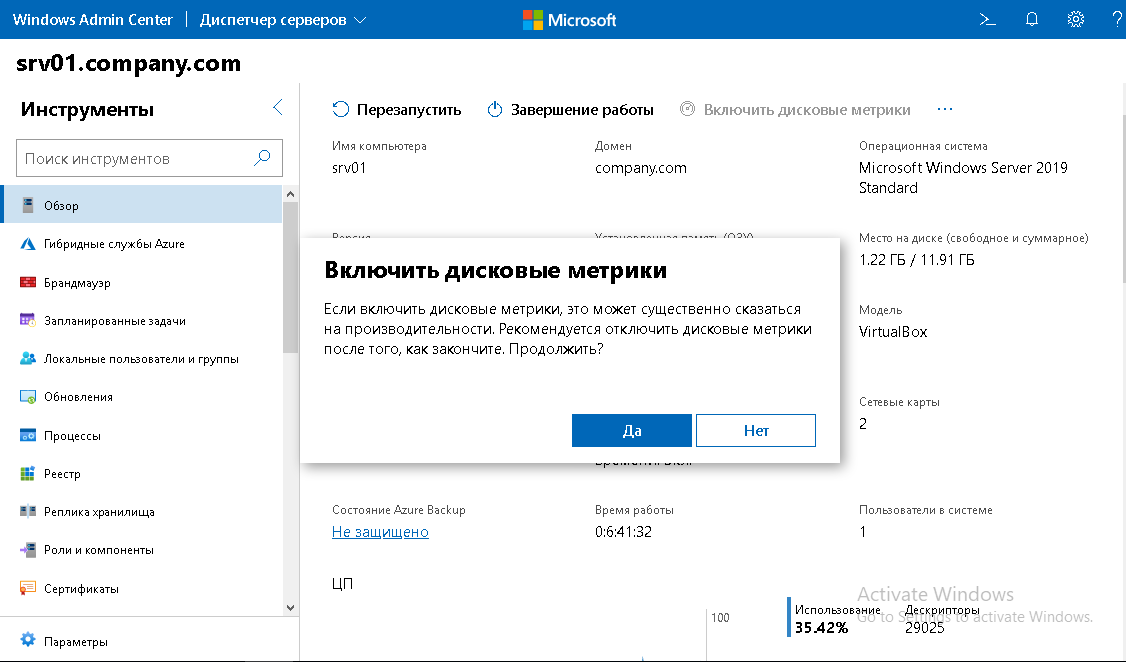
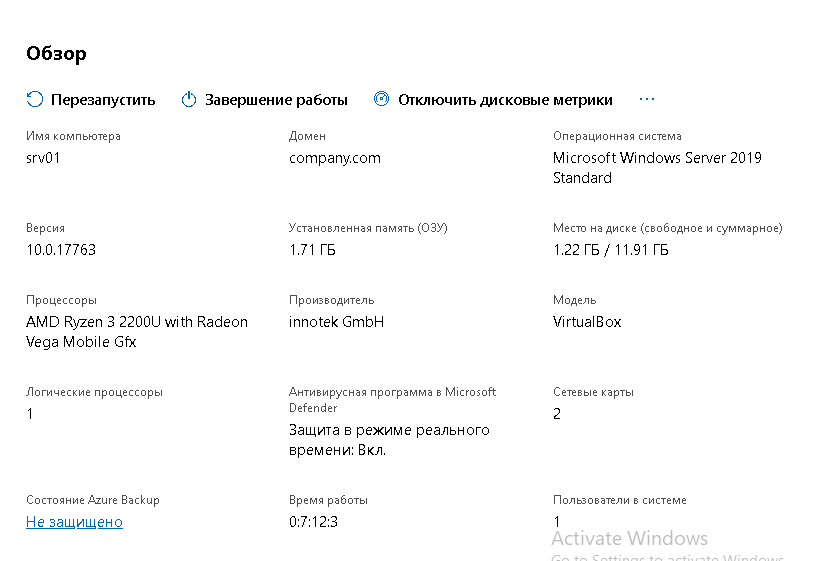
На главную страницу добавили возможность ввода в домен.
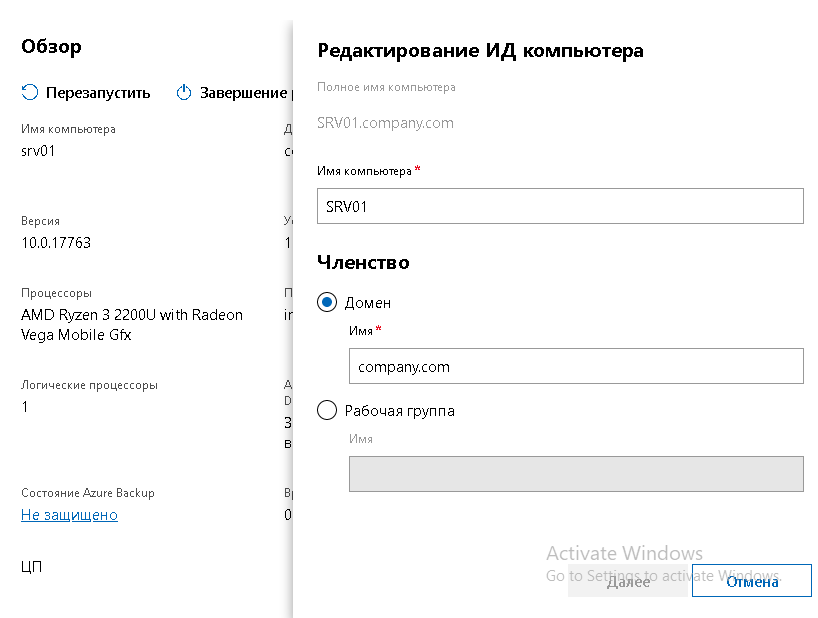
- Простое удаленное управление. Можно подключаться ко всем серверам семейства Windows Server. Для подключения Центр администрирования Windows, в фоновом режиме, использует удаленное подключение PowerShell.
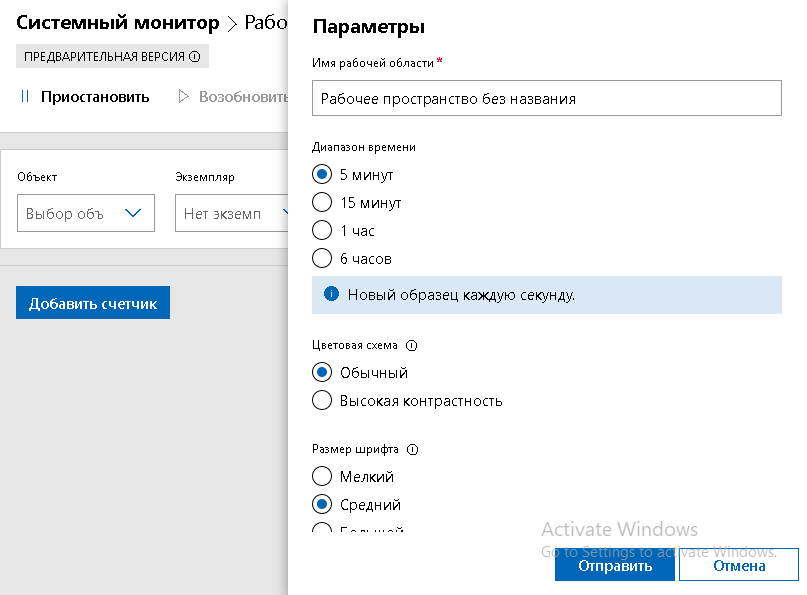
- Общий доступ к рабочему пространству. Возможность создавать рабочие области, которые можно сохранять и использовать на других системах. Области также можно экспортировать и импортировать в другие установки шлюза Центра администрирования. В Параметрах рабочего пространства можно указать Диапазон обновления, цветовую схему (обычную или высокую контрастность), размер шрифта.
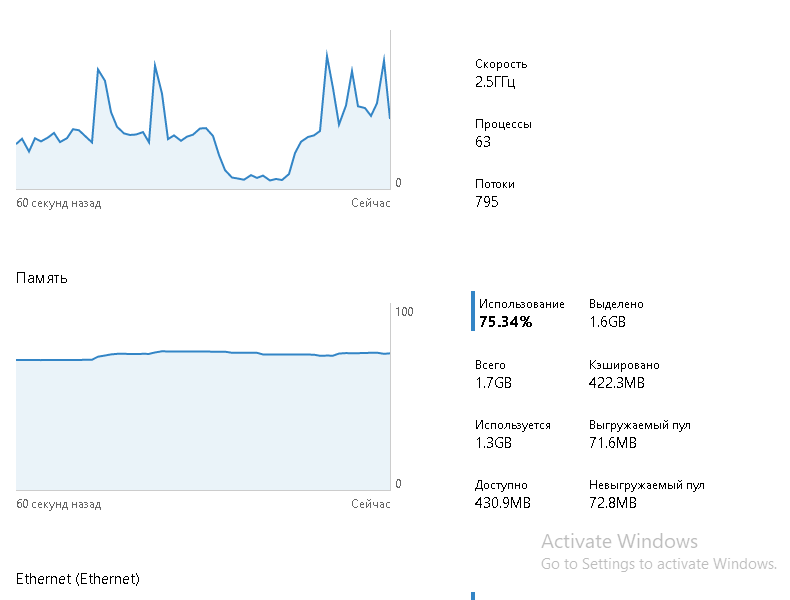
- Поиск и подсветка. Для начала нужно выбрать последовательно: Объект, Экземпляр и счетчик, затем тип графика. Существует очень большое количество счетчиков, но их можно легко искать, используя выпадающий список. Performance Monitor также выделяет другие полезные счетчики, которые имеет смысл мониторить, например, Read Bytes/sec и Write Bytes/sec. Для каждого параметры показывается подробное описание и подсказка.
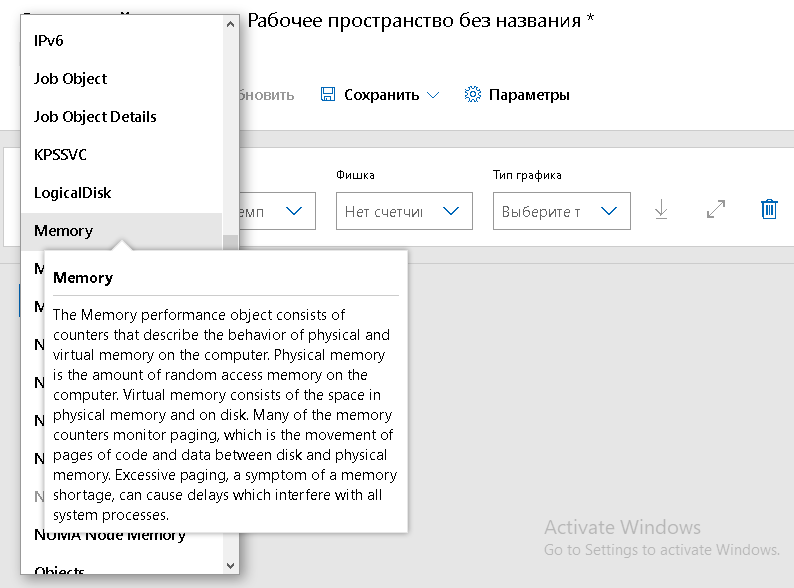
- Различные типы графиков. Можно использовать различные типы графиков, которые упрощают поиск и сравнение нужной информации в зависимости от сценария использования. Стандартный линейный график для просмотра одного или нескольких счетчиков с течением времени. График отчета будет содержать в себе табличные данные. Минимум-максимум покажет соответствующие результаты, а если выгрузить в таблицу Excel, можно использовать фильтр, и найти, например, средние значения.
Так как Windows Admin Center является новым инструментом удаленного управления, он и его компоненты еще будут развиваться и дополняться, в том числе и функционал Windows Performance Monitor.
Мониторинг на продукционных серверах
Краткое содержание:
Общие сведения
ЦКК – Центр контроля качества, типовая конфигурация, входящая в Корпоративный инструментальный пакет.
ЦКК умеет собирать, агрегировать информацию и вовремя оповещать обо всех важных событиях в работе вашей системы.
Настройка всех контрольных процедур происходит на рабочем столе конфигурации.

Рис.1 ЦКК Рабочий стол
Общая настройка ЦКК возможна в мастере настроек основных параметров (раздел Настройки).

Рис.2 ЦКК Мастер настроек основных параметров
В разделе Мониторинг вы сможете
- Просмотреть динамику показателей по контрольным процедурам, которые уже были настроены
- Поделиться настроенной статистикой (быстро показать, на что вы смотрите) с коллегой
- Создать новые оповещения (условия, при которых ЦКК должен будет отправить вам sms или e-mail)
- Просмотреть журнал оповещений

Рис.3 ЦКК Мониторинг
В разделе Сервис вы сможете получить подробную аналитику по данным, которые собираются в ЦКК.

Рис.4 ЦКК Сервис
Для минимальной настройки ЦКК рекомендуется настроить несколько основных контрольных процедур:
- Контроль подключений
- Контроль производительности
- Контроль потребления памяти
- Контроль устойчивости системы
Настройка каждой из указанных процедур не должна занимать более 5-10 минут.
Настройка всех контрольных процедур в ЦКК желательна, т.к. в этом случае вы сможете в полной мере использовать существующую функциональность ЦКК.
Не все контрольные процедуры имеет смысл настраивать на продукционных серверах (например, Контроль нагрузочных тестов).
К настройке других контрольных процедур следует подходить очень внимательно (например, Анализ вызовов кластера 1С), т.к. при настройке таких контрольных процедур будет настраиваться технологический журнал. Если вы не уверены, не изменяйте значения по умолчанию, т.к. в зависимости от нагрузки на рабочую систему может собираться достаточно большой технологический журнал. После настройки контрольных процедур, связанных со сбором технологического журнала вы получите оповещение

Рис.5 ЦКК Включение технологического журнала
После нажатия на кнопку «Продолжить» необходимо каждый раз в течение некоторого времени (от часа до нескольких часов) периодически наблюдать за объемом собираемых данных и объемом информационной базы ЦКК. Безусловно, если вы настраиваете технологический журнал в ручную, такое требование также должно выполняться.
Ниже приводится описание минимального объема механизмов ЦКК, который вы можете использоваться при эксплуатации внедрения. Целью это статьи не является подробное документирование всех возможностей конфигурации Центр контроля качества.
Контроль подключений
Рекомендуем начать с настройки контроля подключений.

Рис.6 ЦКК Контроль подключений
Задачи контроля подключений:
- Контролировать возможность войти в информационную базу в любой момент времени
- Оповестить при невозможности войти в информационную базу
- Собирать статистику доступности информационной базы
Минимальная настройка заключается в
- Простановке флага «Оповещать о восстановлении»
- Простановке флага «Оповещать о сбое»
- Указании группы ответственных лиц, которые будут получать оповещения
- Выборе способа подключения (например, web-сервис)
- Указании URL, логина и пароля
Подробная инструкция по использованию web-сервиса находится на закладке Рекомендации на форме настройки Контроля подключений.
Если в случае сбоя вы хотите получать оповещения, например, каждые N секунд (в течение которых информационная база недоступна), вы можете добавить параметры оповещения при сбое.
После настройки контрольной процедуры не забудьте проверить в разделе Настройки \ Зоны ответственности

Рис.7 ЦКК Зоны ответственности
состав группы ответственных лиц, которую вы указали при настройке Контроля подключений.
Для работы контрольной процедуры Контроль производительности требуется, чтобы в контролируемую информационную базу была встроена подсистема оценки производительности из инструмента под названием «1С:Библиотека стандартных подсистем 8.2» (БСП), имеющего версию 2.1.2.23 или более позднюю. На момент написания статьи выпущена версия БСП 2.2.

Рис.8 ЦКК Контроль производительности
Для настройки контрольной процедуры необходимо указать
- группу ответственных лиц, которые будут получать оповещения (настройка оповещений для этой процедуры не является необходимой)
- каталог файлов оценки производительности, в который настроена выгрузка файлов из контролируемой информационной базы.
Экспорт файлов в указанный каталог настраивается в обработке ОценкаПроизводительности, входящей в комплект подсистемы БСП ОценкаПроизводительности.

Рис.9 БСП ОценкаПроизводительности Экспорт замеров производительности
Контроль потребления памяти
Контроль памяти — это контрольная процедура ЦКК, благодаря которой можно оперативно обнаруживать случаи превышения заданного порогового значения оперативной памяти, занятой рабочими процессами сервера. Дополнительным плюсом работы контрольной процедуры является сохранение в ЦКК информации о работе сеансов в контролируемом кластере серверов. По характеру изменения числа сеансов можно очень точно сказать о нарушениях в работе системы (например, резкое падение числа сеансов в тот момент, когда не запланировано никаких регламентных работ). Таким образом, число сеансов является важным индикатором работы системы.

Рис.10 ЦКК Контроль потребления памяти
Для настройки контрольной процедуры необходимо указать
- объект контроля – кластер серверов
- оповестить о сбое (задача: Устранить причины превышения порога потребления памяти)
- группу ответственных лиц, которые будут получать оповещения
- период автоматического удаления подробной информации о сеансах (рекомендуется не указывать более 240 часов, т.к. это будет приводить к росту базы ЦКК)
Контроль устойчивости системы
Контрольная процедура Контроль устойчивости системы предназначена для
- настройки сбора дампов процессов в случае их аварийных завершений
- автоматического разбора, сохранения статистики, архивации и перемещения дампов процессов с продукционных серверов
- настройки сбора минимального необходимого технологического журнала для последующего анализа аварийных завершений процессов кластера
- оповещения группы ответственных о аварийных завершениях процессов с и без образования дампа памяти.

Рис.11 ЦКК Контроль устойчивости системы
Для настройки контрольной процедуры необходимо указать
- объект контроля – рабочий сервер
- оповещения о сбое (рекомендуется выбрать как минимум два оповещения по аварийным завершениям процессов: с образованием дампа памяти и без образования дампа)
- сетевой и локальный каталог настройки технологического журнала
- сетевой и локальный путь к каталогу сохранения дампов
- каталог временных файлов (необходим для архивации дампов)
- каталог, в который будут экспортироваться дампы.
По умолчанию экспортируются все уникальные (имеют одинаковые имя, версию и смещение) дампы, однако в настройках каждого дампа можно включить свойство «Сохранять все файлы дампов», в этом случае экспортироваться будут все файлы дампов.
Гибкие оповещения
В разделе Мониторинг имеется возможность настраивать гибкие оповещения по любому набору условий, наложенных на выбранные показатели.

Рис.12 ЦКК Оповещения
Гибкость заключается в том, что вы самостоятельно можете указывать условия срабатывания оповещений по sms и/или e-mail.
Например, мы знаем, что информационная база в некоторой организации эксплуатируется 24/7. Это означает, что в системе всегда должны быть пользователи. Допустим, информационная база доступна, но по каким-то причинам пользователи не могут в ней работать, их сеансы завершаются. Хочется, как можно раньше узнать о том, что сеансов пользователей в системе крайне мало (что может свидетельствовать о сбое).
Другой пример: у вас есть 1000 клиентских лицензий. Сервис лицензирования кластера серверов 1С раздает лицензии. Хочется узнать, когда число сеансов приблизится к критичному, например, 950, таким образом иметь запас времени на принятие решения о необходимости активации дополнительных лицензий.
Обе указанные задачи (и многие другие) решаются достаточно простой настройкой. Требуется выбрать нужный показатель (например, Число сеансов), указать условие сравнения, пороговое значение, назначить период проверки и получателей.

Рис.13 ЦКК Показатель оповещения
Условия можно накладывать на показатель, рассчитанный за выбранный период в прошлом (т.е. отслеживать отклонения), так и указывать его абсолютное значение.
Внимание!
Все оповещения работают по уже собранным данным в ЦКК. Это обозначает, что для корректной работы оповещений необходимы работающие контрольные процедуры. Если контрольная процедура Контроль потребления памяти НЕ настроена, оповещения по числу сеансов работать НЕ будет.
Использование ЦКК для агрегации своих данных
ЦКК имеет встроенный web-сервис InputStatistics, который предназначен для того чтобы принимать данные от внешних источников, уникальных для вашей системы (для которых может и не существовать пока специализированной контрольной процедуры).
В конфигурацию ЦКК включена тестовая обработка ТестInputStatistics, предназначенная для того чтобы показать, как можно использовать реализованный web-сервис.
На вход принимается строка в формате
Например, могут быть следующие входные данные:
- Группа.123
- Группа.Подгруппа.234
- Группа.Подгруппа2.345
- Организация.Подразделение.ПлощадкаСерверов.СерверСУБД.AvgDiskQueueLength.7
Уровни вложенности иерархии разделяются точкой ‘.’. Значение (число) всегда идёт после последней точки в строке. ЦКК автоматически сгруппирует значения в соответствие с заданной на входе иерархией. Значения могут храниться в разрезе узлов деревьев и листов.
Посмотреть полученную статистику можно в разделе Мониторинг, выбрав показатель «Счетчики»

Рис.14 Настройка счетчика в мониторинге
Т.к. данные на графиках в разделе Мониторинга отображаются за выбранный период, каждая точка на графике представляет собой некоторый агрегат. Для корректного отображения данных необходимо выбрать, как будут сворачиваться данные за выбранный период. Можно выбрать
- Просуммировать
- Посчитать среднее
- Показать количество вызовов web-сервиса в случае с переданной ему иерархией счетчиков
По выбранным счетчикам вы также можете настроить гибкие оповещения и получать e-mail и/либо sms, в случае отклонения выбранного счетчика (либо группы счетчиков) от заданной величины.
Пример настройки сбора данных по загруженности оборудования с помощью PowerShell (3.0 или 4.0) для Windows серверов с агрегацией данных в ЦКК.
- Копируем файл скрипта srv_perf.ps1 и файл настройки srv_perf.xml на сервер, с которого (!) будет осуществляться контроль.
- Добавляем на все контролируемые (!) серверы пользователя, от имени которого будем получать необходимые данные. Пусть пользователь будет «QMC_WS».
- Добавляем пользователя «QMC_WS» в группу Performance Monitor Users на всех контролируемых серверах
- Открываем с контролирующего сервера файл настройки srv_perf.xml.
- Если контролируемые серверы не являются серверами СУБД с установленным и используемым MS SQL Server (т.е. являются рабочими серверами 1С), тогда удаляем все счетчики, которые находятся между
Копировать в буфер обмена
Все указанные счетчики должны нормально собираться с помощью Performance Monitor. Если какие-то счетчики называются по-другому, замените их.
Обратите внимание! В файле настройки указаны счетчики для логических дисков C, D и E. Если таких дисков у вас нет, замените эти строки, либо удалите выбранные счетчики.
Перечисляем все серверы, как указано в скрипте в примере для сервера —
указываем путь до опубликованного веб-сервиса в ЦКК. Пусть требуется аутентификация для подключения к веб-сервису. Для этого, пусть пользователь будет “QMC”, а его пароль “QMC123”
- Сохраняем отредактированный файл srv_perf.xml
- Запускаем один раз скрипт из PowerShell
Указываем один раз логин и пароль (например, “”, “123”)
Убеждаемся, что рядом со скриптом появился файл wsInputStatistics.xml с сохраненными данными аутентификации, привязанными к серверу.
## need one time to create password file wsInputStatistics.xml. If changed user profile or file deleted we need uncomment line below & run script interactly
$cred = Get-Credential | EXPORT-CLIXML $cred_xml_path
Ставим комментарий на вторую строку. Должно получиться так:
##$cred = Get-Credential | EXPORT-CLIXML $cred_xml_path
- Сохраняем файл.
- Создаем задачу в Task Scheduler от имени пользователя «QMC_WS», созданного в пункте 2. В задаче запускаем указанный скрипт по расписанию, например, раз в минуту.
На контролирующем сервере пользователь «QMC_WS» должен обладать соответствующими правами (на запуск скриптов PowerShell).
то всегда будет создаваться журнал, путь к которому указан в файле srv_perf.xm
то при безошибочной работе журнал создаваться не должен.
- Убедитесь, что в ЦКК в течение 5 минут появились нужные данные. Это можно проверить, если зайти в раздел Мониторинг, добавить счетчик «Счетчики» и указать нужный счетчик.
Имеет смысл всегда настраивать хотя бы минимальный технологический журнал для отслеживания качества работы системы. При этом хорошей практикой будет настройка минимального журнала на всех серверах (тестовых, подготовительных, продукционных и серверах разработки). Сбор минимального технологического журнала является практически бесплатной возможностью всегда отвечать на вопрос: «А что же именно произошло?»
Настройка сбора технологического журнала производится в файле logcfg.xml
О расположении файла можно подробно прочитать в статье.
Структура файла logcfg.xml также подробно описана в статье.
При любой настройке технологического журнала следует всегда контролировать рост объема вашего журнала в течение некоторого времени.
Серверный технологический журнал
Настройка минимального технологического журнала может выглядеть следующим образом:
Такой технологический журнал будет
- Включать запись дампов от аварийных завершений всех процессов кластера. Объем дампов будет минимальным (type=»0″) и не будет содержать дополнительных сегментов данных и памяти процесса.
- Содержать все исключения, которые были сгенерированы процессами технологической платформы (не из кода на встроенном языке!). Не все такие исключения являются ошибкой или явной проблемой. Однако их наличие должно обратить внимание администратора (эксплуататора) площадки серверов на то, что возможно наблюдается какая-либо проблема.
Зачем нужен такой журнал:
- Вы можете оценить стабильность работы системы – число аварийных завершений процессов. При этом если в имени файла дампа совпадает имя процесса, версия и смещение (rphost_8.3.4.437_01234567), то, скорее всего, такие аварийные завершения были вызваны одной и той же причиной.
- Причину аварийных завершений процессов вы сможете узнать из технологического журнала. Имя файла дампа, сгенерированное технологического платформой, всегда заканчивается на PID процесса. Проще всего найти нужный файл технологического журнала так:
- находим файл с именем процесса и PID (например, rphost_1234),
- затем открываем последний (в хронологическом порядке) файл.
- В конце этого файла обязательно будет событие EXCP, в котором может быть указан стек кода на встроенном языке, при выполнении которого и произошло аварийное завершение работы процесса.
- Можно оценить общее число исключений и сгруппировать их по типам (описанию в свойстве Descr) для того чтобы оценить, на что стоит обратить наибольшее внимание.
- Можно оценить общее число ошибок параллельной работы (ошибок блокировок и взаимоблокировок). Все такие ошибки обязательно записываются в технологический журнал. Тексты ошибок блокировок, которые возникли на уровне СУБД, могут отличаться в зависимости от используемой СУБД, её локализации и версии. В любом случае ВСЕ ошибки, которые произошли на уровне СУБД будет «подписаны» соответствующим образом (например, » Microsoft OLE DB Provider for SQL Server «).
Ошибки блокировок на уровне технологической платформы всегда будут записаны в технологический журнал и будут иметь вид (текст в поле Descr будет включать в себя):
- «Превышено максимальное время ожидания предоставления блокировки» — для таймаутов на управляемых блокировках,
- «Неустранимый конфликт блокировок» — для взаимоблокировок на управляемых блокировках.
Такого (минимального) технологического журнала не достаточно для того чтобы расследовать возникшие ошибки. Для расследования ошибок необходимо использовать ЦУП или более подробный технологический журнал.
В предложенной настройке технологический журнал будет собираться в директорию C:\LOGS\All
Следует помнить, что НЕ должно быть никаких посторонних файлов в директории ALL и в директориях журналов процессов, которые создаст технологическая платформа. В противном случае технологические журналы записываться не будут. Будьте особенно осторожны при настройке технологический журналов, т.к. технологическая платформа никак не сообщит о том, что настройка выполнена некорректно. В худшем случае не будут записываться никакие технологические журналы на этом сервере. По этой причине рекомендуется всегда после настройки технологического журнала ждать одну минуту (за это время все процессы кластера серверов гарантированно перечитают конфигурационных файл технологического журнала) и убедиться, что технологический журнал собран и ведется в соответствии с вашими ожиданиями.
На всех продукционных площадках предлагается по умолчанию всегда настраивать следующий технологический журнал.
Такая настройка позволяет собирать минимальный объем информации, на основании которого можно расследовать до 80% проблем, возникающих при работе технологической платформы. В случае крайне нестабильной работы системы будет занимать много места директория с дампами процессов ( C:\DUMPS ), т.к. в данном случае будут записываться полные снимки процессов в момент их аварийного завершения. В случае нестабильной работы рекомендуется настроить автоматический разбор дампов из такой директории, например, с помощью контрольной процедуру «Контроль устойчивости» в ЦКК. Директория с технологическим журналом (C:\LOGS\All) при нормальной работе не должна превышать пары сотен Mb за сутки (Конечно же, всё зависит от вашей нагрузки и конфигурации системы. Нужно учитывать, что оценка может оказаться очень грубой и некорректной). Т.к. по истечении заданного времени (history=»28″) «старый» технологический журнал будет автоматически удаляться технологической платформой (для того чтобы избежать забивания журналами дискового пространства) рекомендуется настроить автоматическое копирование (например, раз в сутки) всех журналов со сжатием (например, в zip) на другой ресурс с помощью планировщика операционной системы. Таким образом, вы будете иметь журналы за любой момент работы системы.
Полезным может оказаться технологический журнал, в который будут попадать все длительные события. Настройка такого технологического журнала может выглядеть так.
Файл настройки приведен для версии технологической платформы 8.3, в фильтре по полю Durationus указано время 20 секунд (в микросекундах). Все события, которые попадают в такой журнал (при нормальной работе системы такой журнал должен быть скромных размеров) должны быть предметом рассмотрения, в первую очередь события SDBL со свойством Func=CommitTransaction. Такие события будут иметь длительность внешней (вложенные транзакции технологической платформой не поддерживаются) транзакции. Если транзакция длится более 20 секунд (скорее всего, в рамках транзакции будут установлены транзакционные блокировки на какие-либо ресурсы), она может стать «виновником» ошибок блокировок. Также внимание стоит уделить длительным запросам.
Для расследования ошибок на управляемых блокировках необходим технологический журнал вида
Следует обратить внимание, что журнал может быть большого объема, а длительность его ротации в примере указана равной 4 часам.
Ниже приведен пример того, как можно провести расследование ошибок управляемых блокировок (на примере управляемых взаимоблокировок).
Для того чтобы воспроизвести и расследовать простейшую взаимоблокировку, необходимо выполнить следующие шаги. (Просьба учитывать, что это «учебный пример», не пишите так в своих конфигурациях…)
1. Создаем конфигурацию с регистром сведений РегистрСведений1. Регистр независимый, непериодический.
2. Делаем обработку, в которой есть две команды
СделатьПаузу() — метод, реализованный в типовой конфигурации КИП:ТестЦентр, который предназначен для паузы, принимает параметр в мс.
3. Настраиваем технологический журнал
4. Запускаем двух клиентов, первый выполняет первую команду, второй — вторую.
Получаем ошибку взаимоблокировки на управляемых блокировках. Смотрим в собранный технологический журнал.
10:58.515038-3,TLOCK,4,process=rphost,p:processName=test_lock3,t:clientID=41,t:applicationName=1CV8C,t:computerName=MOROZOV-AN,t:connectID=16,SessionID=8,AppID=1CV8C,Regions=InfoRg10.DIMS,Locks=’InfoRg10.DIMS Shared Fld11=»Test1″ Fld12=»Test2″‘,WaitConnections=,Context=’Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ПервыйУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 19 : НаборЗаписейРегистрСведений1.Прочитать();’ 11:00.496028-3,TLOCK,4,process=rphost,p:processName=test_lock3,t:clientID=45,t:applicationName=1CV8,t:computerName=MOROZOV-AN,t:connectID=17,SessionID=10,Usr=DefUser,Regions=InfoRg10.DIMS,Locks=’InfoRg10.DIMS Shared Fld11=»Test1″ Fld12=»Test2″‘,WaitConnections=,Context=’Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ВторойУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 50 : НаборЗаписейРегистрСведений1.Прочитать();’ 11:05.519001-0,TDEADLOCK,5,process=rphost,p:processName=test_lock3,t:clientID=45,t:applicationName=1CV8,t:computerName=MOROZOV-AN,t:connectID=17,SessionID=10,Usr=DefUser,DeadlockConnectionIntersections=’17 16InfoRg10.DIMS Exclusive Fld11=»Test1″ Fld12=»Test2″,16 17 InfoRg10.DIMS Exclusive Fld11=»Test1″ Fld12=»Test2″‘,Context=’Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ВторойУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 58 : НаборЗаписейРегистрСведений1.Записать();’ 11:05.519003-16002,TLOCK,4,process=rphost,p:processName=test_lock3,t:clientID=45,t:applicationName=1CV8,t:computerName=MOROZOV-AN,t:connectID=17,SessionID=10,Usr=DefUser,Regions=InfoRg10.DIMS,Locks=’InfoRg10.DIMS Exclusive Fld11=»Test1″ Fld12=»Test2″‘,WaitConnections=16,Context=’Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ВторойУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 58 : НаборЗаписейРегистрСведений1.Записать();’ 11:05.519024-1997023,TLOCK,4,process=rphost,p:processName=test_lock3,t:clientID=41,t:applicationName=1CV8C,t:computerName=MOROZOV-AN,t:connectID=16,SessionID=8,AppID=1CV8C,Regions=InfoRg10.DIMS,Locks=’InfoRg10.DIMS Exclusive Fld11=»Test1″ Fld12=»Test2″‘,WaitConnections=17,Context=’Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ПервыйУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 26 : НаборЗаписейРегистрСведений1.Записать();’
5. Находим событие TDEADLOCK и выписываем свойства поля
DeadlockConnectionIntersections=’ 17 16 InfoRg10.DIMS Exclusive Fld11=»Test1″ Fld12=»Test2″, 16 17 InfoRg10.DIMS Exclusive Fld11=»Test1″ Fld12=»Test2″‘
Видим, что ошибка произошла на регистре сведений InfoRg10 при попытке установить исключительную управляемую блокировку на поля Fld11=»Test1″ Fld12=»Test2″ 16 и 17 — это номера t:connectID участников взаимоблокировки. До события TDEADLOCKуказаны события TLOCK участников 16 и 17. Например,
10:58.515038-3,TLOCK,4,process=rphost,p:processName=test_lock3,t:clientID=41,t:applicationName=1CV8C,t:computerName=MOROZOV-AN,t:connectID=16,SessionID=8,AppID=1CV8C,Regions=InfoRg10.DIMS,Locks=’InfoRg10.DIMS Shared Fld11=»Test1″ Fld12=»Test2″‘,WaitConnections=,Context=’Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ПервыйУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 19 : НаборЗаписейРегистрСведений1.Прочитать();’
установил разделяемую управляемую блокировку на поля регистра сведений
Locks=’InfoRg10.DIMS Shared Fld11=»Test1″ Fld12=»Test2″‘
Эту операцию первый участник выполнил из
Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ПервыйУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 19 : НаборЗаписейРегистрСведений1.Прочитать();
Управляемая блокировка (разделяемая или исключительная) снимается только в конце внешней транзакции.
При чтении набора записей технологическая платформа сама устанавливает разделяемую управляемую блокировку.
При записи набора записей технологическая платформа сама устанавливает исключительную управляемую блокировку.
Собственно, блокировка при записи
11:05.519024-1997023,TLOCK,4,process=rphost,p:processName=test_lock3,t:clientID=41,t:applicationName=1CV8C,t:computerName=MOROZOV-AN,t:connectID=16,SessionID=8,AppID=1CV8C,Regions=InfoRg10.DIMS,Locks=’InfoRg10.DIMS Exclusive Fld11=»Test1″ Fld12=»Test2″‘,WaitConnections=17,Context=’Форма.Вызов : ОбщаяФорма.РабочийСтол.Модуль.ПервыйУчастникНаСервере ОбщаяФорма.РабочийСтол.Форма : 26 : НаборЗаписейРегистрСведений1.Записать();’
Мы видим, что установить он её не смог и ждал в течение 1997023 микросекунд участника WaitConnections=17 т.е. с номером
Это же симметрично сделал второй участник взаимоблокировки.
Таким образом, мы по технологическому журналу полностью выяснили, что именно и как именно произошло.
6. В статье указан этот сценарий в разделе «Повышение уровня блокировки ресурса в рамках одной транзакции».
Для того чтобы вылечить эту ошибку в коде конфигурации, нужно, чтобы блокировка в транзакции изначально осуществлялась с максимальным необходимым уровнем изоляции . Т.е. нам необходимо установить управляемую исключительную блокировку перед чтением набора записей.
Для расследования причин неоптимальной работы запросов может оказаться полезным следующий технологический журнал (пример сделан для сервера СУБД MS SQL Server).
В примере настроены планы запросов (
). Не смотря на то, что сбор планов включается на СУБД для всех баз, планы будут записываться только для тех событий, которые удовлетворяют указанным фильтрам. Рекомендуем всегда настраивать как можно более тонко фильтрацию. В этом случае ваш журнал не будет значительного объема, а его разбор будет удобным. В примере приведена настройка фильтрации по информационной базе (MyInfoBase) и по пользователю (Василий).
Типичные причины неоптимальной работы запросов и методы оптимизации указаны в статье.
Клиентский технологический журнал
Наиболее распространенной задачей, в которой требуется настройка клиентского технологического журнала, является расследование длительного входа в систему. Для того чтобы расследовать, что именно пытается делать клиентского приложение (например, какую форму открывает?) нужен клиентский технологический журнал. Пример настройки полного клиентского технологического журнала ниже.
Рекомендуется в общем случае настраивать полный технологический журнал для анализа работы клиентских приложений. Такой журнал не будет большого объема (в виду того, что клиентское приложение одно, выполняет действий значительно меньше, чем сервер).
Внимание! Не настраивайте такой журнал на рабочем сервере.
В общем случае не рекомендуется запускать клиентские приложения на продукционных серверах.
Разбор технологического журнала
Ниже приводится пример, как можно разбирать технологический журнал. В этом примере подготовлен такой учебный шаблон, который позволит минимальными трудозатратами получить необходимый результат. Возможно, этот учебный шаблон не будет самым оптимальным (в виду своей общности).
В случае если разбираем технологический журнал на Windows сервере, возможно использовать специально ПО, например, cygwin.
Не забываем установить пакеты perl. Далее примеры приведены для сценария, в котором мы уже находимся в директории, в которой лежат директории с журналами процессов кластера.

рис.15 Директория с технологическими журналами процессов кластера
Например, мы хотим получить группировку по полю Descr всех событий EXCP только по процессам rphost.
Вывод в виде таблицы с колонками
cat rphost*/*.log | perl descr.pl | sort | uniq -c | sort -rn >> result.txt
#!/usr/bin/perl
use strict;
my $event;
my %actions = (
‘EXCP’ => [
< 'action' =>sub <
my ($event) =@_;
my ($garbage, $context) = split /Descr=’/, $event;
my ($descr, $garbage) = split /’/, $context;
$descr =
print «EXCP Descr $descr\n» if $descr; >, >, ],);
while (<>) <
$event=process_event($event) if /^\d\d:\d\d\.\d+/;
$event .= $_; >
sub process_event($) <
my ($event) = @_;
return unless $event;
foreach my $event_type ( keys %actions ) <
next unless $event =
Например, мы хотим получить суммарную длительность событий DBMSSQL и SDBL с группировкой по последней строке стека на встроенном языке.
Вывод в виде таблицы с колонками:
!/usr/bin/perl
use strict;
my $event;
my %actions = (
‘DBMSSQL’ => [
<
‘action’ => sub <
my ($event) =@_;
my ($date, $garbage) = split /,DBMSSQL/, $event;
$date =
my ($garbage, $context) = split /Context=’/, $event;
if ($context =
/\n/) <
my @mlc = split /\n/, $context;
$context = $mlc[$#mlc];
>
$context =
s/;’/;/g;
print «$date-$context\n» if $context;
>,
>,
],
‘SDBL’ => [
<
‘action’ => sub <
my ($event) =@_;
my ($date, $garbage) = split /,SDBL/, $event;
$date =
s/\d\d:\d\d\.\d+-//g;
my ($garbage, $context) = split /Context=’/, $event;
if ($context =
/\n/) <
my @mlc = split /\n/, $context;
$context = $mlc[$#mlc];
>
$context =
s/;’/;/g;
print «$date-$context\n» if $context;
>,
>,
],
);
print «\n»;
while (<>) <
$event=process_event($event) if /^\d\d:\d\d\.\d+/;
$event .= $_;
>
sub process_event($) <
my ($event) = @_;
return unless $event;
foreach my $event_type ( keys %actions ) <
next unless $event =
Приведенный скрипт в качестве контекста указывает последнюю строку из стека вызова на встроенном языке. В случае, когда возникает необходимость получить группировку по первой строке стека на встроенном языке, достаточно строки
Предположим, что мы хотим получить суммарную длительность ожиданий на управляемых блокировках. В этом случае query.pl изменится на tlock.pl
#!/usr/bin/perl
use strict;
my $event;
my %actions = (
‘TLOCK’ => [
<
‘action’ => sub <
my ($event) =@_;
my ($date, $garbage) = split /,TLOCK/, $event;
$date =
s/\d\d:\d\d\.\d+-//g;
my ($garbage, $region) = split /Regions=/, $event;
my ($region, $garbage) = split /,Locks=’/, $region;
print «$date-$region\n» if $region;
>,
>,
],
);
while (<>) <
$event=process_event($event) if /^\d\d:\d\d\.\d+/;
$event .= $_;
>
sub process_event($) <
my ($event) = @_;
return unless $event;
foreach my $event_type ( keys %actions ) <
next unless $event =
И так, как вы видите, скрипт сделан так, что он очень легко модифицируется под конкретную задачу. Если идея показалась вам интересной, предлагается ознакомиться с книгой «Регулярные выражения» автора Джеффри Фридл .
Настройка сбора данных Performance Monitor необходима для оценки загруженности оборудования серверов приложений. Следует обратить внимание, что должен быть настроен сбор данных со всех серверов продукционной площадки.
Необходимо убедиться, что собираются данные по всем следующим счетчикам:
«\Memory(_Total)\Available Mbytes»
«\Process(«1cv8*»)\% Processor Time»
«\Process(«1cv8*»)\Private Bytes»
«\Process(«1cv8*»)\Virtual Bytes»
«\Process(«ragent*»)\% Processor Time»
«\Process(«ragent*»)\Private Bytes»
«\Process(«ragent*»)\Virtual Bytes»
«\Process(«rphost*»)\% Processor Time»
«\Process(«rphost*»)\Private Bytes»
«\Process(«rphost*»)\Virtual Bytes»
«\Process(«rmngr*»)\% Processor Time»
«\Process(«rmngr*»)\Private Bytes»
«\Process(«rmngr*»)\Virtual Bytes»
«\LogicalDisk(_Total)\Free Megabytes»
«\Processor(_Total)\% Processor Time»
«\Memory(_Total)\Pages/sec» «\System(_Total)\Processor Queue Length»
«\PhysicalDisk(_Total)\Avg. Disk Queue Length»
«\PhysicalDisk(*)\Avg. Disk Queue Length»
«\PhysicalDisk(*)\Avg. Disk Bytes/Read»
«\PhysicalDisk(*)\Avg. Disk Bytes/Write»
«\Network Interface(*)\Bytes Total/sec»
Добавить (настроить) такой набор счетчиков Performance Monitor можно командой
logman create counter 1C_counter -f bincirc -c «\Memory(_Total)\Available Mbytes» «\Process(«1cv8*»)\%% Processor Time» «\Process(«1cv8*»)\Private Bytes» «\Process(«1cv8*»)\Virtual Bytes» «\Process(«ragent*»)\%% Processor Time» «\Process(«ragent*»)\Private Bytes» «\Process(«ragent*»)\Virtual Bytes» «\Process(«rphost*»)\%% Processor Time» «\Process(«rphost*»)\Private Bytes» «\Process(«rphost*»)\Virtual Bytes» «\Process(«rmngr*»)\%% Processor Time» «\Process(«rmngr*»)\Private Bytes» «\Process(«rmngr*»)\Virtual Bytes» «\LogicalDisk(_Total)\Free Megabytes» «\Processor(_Total)\%% Processor Time» «\Memory(_Total)\Pages/sec» «\System(_Total)\Processor Queue Length» «\PhysicalDisk(_Total)\Avg. Disk Queue Length» «\PhysicalDisk(*)\Avg. Disk Queue Length» «\PhysicalDisk(*)\Avg. Disk Bytes/Read» «\PhysicalDisk(*)\Avg. Disk Bytes/Write» «\Network Interface(*)\Bytes Total/sec» -si 5 -v mmddhhmm
Внимание!
Имена счетчиков могут незначительно отличаться в зависимости от версии вашей операционной системы.Данные будут собираться каждые 5 секунд.
Рекомендуется также не забыть настроить планировщик задач на автозапуск выбранного счетчика, например, каждый час, если сбор данных ещё не запущен. Это нужно на те случаи, в которых возникает необходимость перезапускать продукционные серверы. Обычно в такие моменты о включении сбора данных Performance Monitor вспоминают в последнюю очередь.
О том, как проводить анализ загруженности оборудования по собираемым счетчикам, указано в статье.
Исходные файлы находятся в каталоге \1CITS\EXE\Scalability\i8105809



